rdd实验——教师绩效考核
Posted 一 研 为定
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了rdd实验——教师绩效考核相关的知识,希望对你有一定的参考价值。
目录
6、根据绩效数据,平均分以上人数的前10%工资上浮20%,前10%-20%上浮10%。平均分以下,人数的后10%工资降低20%,后10%-20%降低10%。计算本月各个教师的工资
一、实验要求
1、统计各个教师已完成任务的总积分,并降序排列
2、统计各个任务的总积分,并降序排列
3、统计各个学校每个教师的平均工资,并降序排列
4、统计各个学校的积分情况,并降序排列
5、统计各个学校每个教师的平均分,并降序排列
6、根据绩效数据,平均分以上人数的前10%工资上浮20%,前10%-20%上浮10%。平均分以下,人数的后10%工资降低20%,后10%-20%降低10%。计算本月各个教师的工资
7、统计公司本月发放工资是多发还是少发,具体数值是多少。
二、实验数据
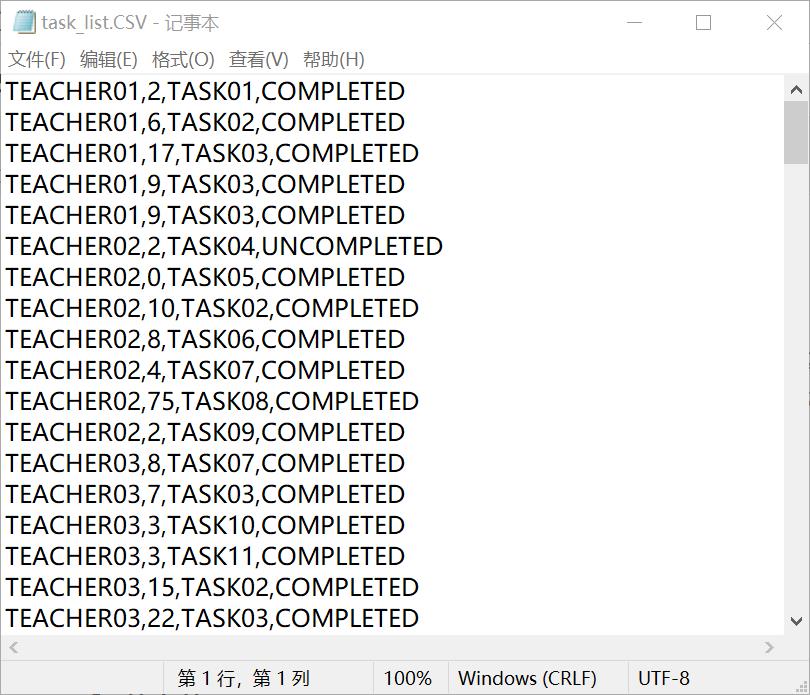
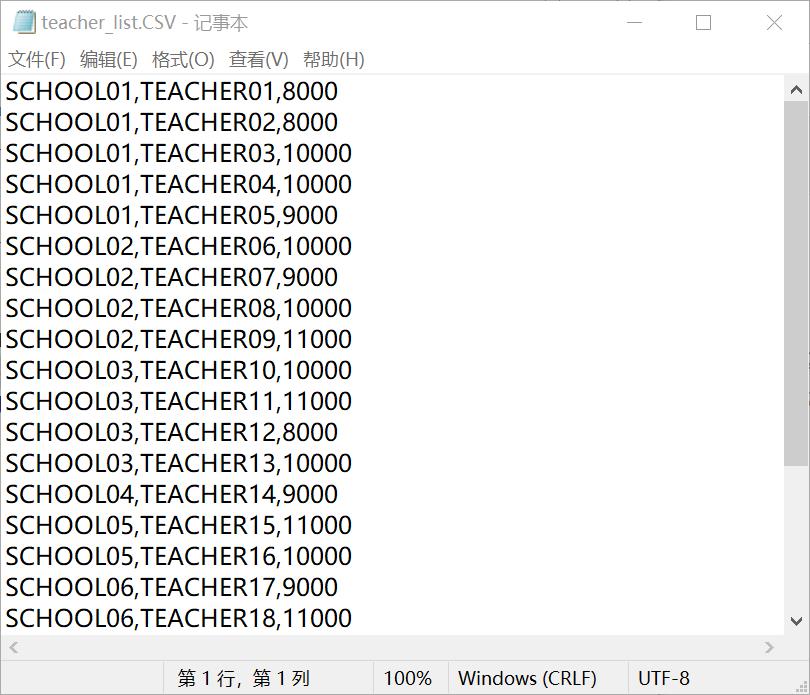
提供了两个csv文件,teacher_list.csv和task_list.csv,具体数据如下:
三、实验过程
数据预处理
首先观察数据,本次实验给了两个数据文件“task_list.CSV"和“teacher_list.csv”。其中,“task_list.csv”是任务表,包含了教师,积分,任务,完成情况(完成,审核通过;否则审核未通过);“teacher_list.csv”是教师表,包含了学校,教师,工资。
导入数据,并对数据进行整理。
发现导入后的数据是字符串数据,不是我们想要的,所以要通过切片,将字符串转列表,使用map方法。并使用filter()函数过滤序列,从一个完成情况这列中筛选出完成情况是”COMPLETED“的元素。
task = sc.textFile('/home/ubuntu/data/task_list.CSV')
teacher = sc.textFile('/home/ubuntu/data/teacher_list.CSV')
task.collect()
teacher.collect()
task_list = task.map(lambda x:x.split(','))
teacher_list = teacher.map(lambda x:x.split(','))
task_list.take(5)
teacher.take(5)
task_list = task_list.filter(lambda x:x[3]=='COMPLETED')1、统计各个教师已完成任务的总积分,并降序排列
(1)取出task_list中的前两列:教师,积分,并使用reduceByKey 进行分组求和.
(2)需要把上面字符串形式的积分,转成float形式再相加。
(3)对总积分降序排序(sortBy根据什么排都行,sortByKey是根据key来排)。
rdd11 = task_list.map(lambda x:(x[0],x[1]))
rdd11.take(1)
rdd12 = rdd11.reduceByKey(lambda x,y:x+y)
rdd12.collect()
rdd11=task_list.map(lambda x:(x[0],float(x[1])))
rdd12=rdd11.reduceByKey(lambda x,y:x+y)
rdd12.collect()
rdd13=rdd12.sortBy((lambda x:x[1]),ascending=False)
rdd13.collect()
2.统计各个任务的总积分,并降序排列
取task_list中的任务,积分,两列,并使用reduceByKey进行分组求和。
rdd21=task_list.map(lambda x:(x[2],float(x[1])))
rdd22=rdd21.reduceByKey(lambda x,y:x+y)
rdd22.collect()
rdd23=rdd22.sortBy((lambda x:x[1]),ascending=False)
rdd23.collect()3、统计各个学校每个教师的平均工资,并降序排列
- 从teacher_list 中拿出第一列和第三列,再分组求和,求出总工资从teacher_list 中拿出第一列和第三列,再分组求和,求出总工资
- 从teacher_list中使用countByKey计算教师数量,教师数量是根据相同的学校来确定的。
- 使用cal_vag函数,计算平均工资
- 对平均工资进行降序排序,使用sortByKey
rdd31=teacher_list.map(lambda x:(x[0],int(x[2])))
rdd31.take(2)
rdd32=rdd31.reduceByKey(lambda x,y:x+y)
rdd32.collect()
teacher_list.countByKey()
td=teacher_list.countByKey()
td.values()
def cal_avg(x):
school=x[0]
salary=x[1]
num=td[school]
return (salary/num,school)
rdd32.map(cal_avg).collect()
rdd32.map(cal_avg).sortByKey(ascending=False).collect()4、统计各个学校的积分情况,并降序排列
需要关联两个表,(教师,积分),(学校,教师),第一问算了各个教师的总积分,现在是把教师和学校关联起来。join是根据key来合并的,所以根据教师合并。
- 先提取出teacher_list中的第一列和第二列,即学校和教师;并使用第一问中rdd13,教师和总积分。
- 关联两个表,使用join,是根据教师合并的。
- 提取join后的第一列,对其进行加和,并按降序排列
rdd41=teacher_list.map(lambda x:(x[1],x[0]))
rdd41.take(1)
rdd42=rdd41.join(rdd13)
rdd42.take(1)
rdd43=rdd42.map(lambda x:x[1])
rdd43.take(1)
rdd44=rdd43.reduceByKey(lambda x,y:x+y)
rdd44.collect()
rdd45=rdd44.sortBy((lambda x:x[1]),ascending=False)
rdd45.collect()
5、统计各个学校每个教师的平均分,并降序排列
(1) 从teacher_list中拿出第一列和二列,(教师,学校),从task_list中拿出第一列和第二列,(教师,分数),使用join将两个表合在一起。
(2) 从新表中取出(学校,积分),使用reduceByKey求各个学校的总积分。
(3) 在teacher_list中计算每个学校的教师人数
(4) 对定义函数求各个学校每个教师的平均分,并按降序排列
rdd51=teacher_list.map(lambda x:(x[1],x[0]))
rdd51.take(2)
rdd52=task_list.map(lambda x:(x[0],float(x[1])))
rdd52.take(2)
rdd53=rdd51.join(rdd52)
rdd53.take(2)
rdd54=rdd53.map(lambda x:x[1])
rdd54.take(2)
rdd55=rdd54.reduceByKey(lambda x,y:x+y)
rdd55.collect()
td2=teacher_list.countByKey()
td2.values()
td2['SCHOOL02']
def score_avg(x):
school=x[0]
score=x[1]
num=td2[school]
return(score/num,school)
rdd55.map(score_avg).collect()
rdd55.map(score_avg).sortByKey(ascending=False).collect()
6、根据绩效数据,平均分以上人数的前10%工资上浮20%,前10%-20%上浮10%。平均分以下,人数的后10%工资降低20%,后10%-20%降低10%。计算本月各个教师的工资
- 计算平均分。总分/总人数
- 对积分求和total,teacher_list使用count求教师人数num
- 求平均分avg_score=total/num
- 对平均分进行过滤
rdd61 = rdd43.map(lambda x:x[1])
rdd61.collect()
from operator import add
rdd61.reduce(add)
total=rdd61.reduce(add)
num=teacher_list.count()
avg_score=total/num
avg_score
rdd62 = rdd13.filter(lambda x:x[1]>avg_score)
rdd62.take(2)
rdd63=rdd13.filter(lambda x:x[1]<avg_score)
rdd63.take(3)
rdd62.count()
rdd63.count()
rdd62.collect()
rdd62.take(1)[0][0]
rdd62.take(2)[1][0]
rdd63.collect()
rdd64=rdd63.sortBy(lambda x:x[1])
rdd64.collect()
rdd64.take(3)
teacher_list.filter(lambda x:x[1]=='TEACHER20').map(lambda x:(int(x[2])*1.2,x[1])).collect()
teacher_list.filter(lambda x:x[1]=='TEACHER19').map(lambda x:(int(x[2])*1.1,x[1])).collect()
teacher_list.filter(lambda x:x[1]=='TEACHER16').map(lambda x:(int(x[2])*0.8,x[1])).collect()
teacher_list.filter(lambda x:x[1]=='TEACHER22').map(lambda x:(int(x[2])*0.9,x[1])).collect()
teacher_list.filter(lambda x:x[1]=='TEACHER11').map(lambda x:(int(x[2])*0.9,x[1])).collect()通过观察,我们可以发现,平均分65.83之上的人数有11人,之下的有13人。平均分以上人数的前10%是TEACHER20,他的工资上浮20%,前10%-20%是TEACHER19,他的工资上浮10%;平均分以下,人数的后10%是TEACHER16,工资降低20%,后10%-20%是TEACHER22,TEACHER11,他们的工资降低10%。
调整后教师的工资分别为:
涨工资:TEACHER20 10800;TEACHER19 8800
降工资:TEACHER16 8000;TEACHER22 8100;TEACHER11 9900
7、统计公司本月发放工资是多发还是少发,具体数值是多少。
teacher = sc.textFile('/home/ubuntu/data/teacher_list.CSV')
teacher_list2 = teacher.map(lambda x:x.split(','))
teacher_list2.filter(lambda x:x[1]=='TEACHER20').collect()
teacher_list2.filter(lambda x:x[1]=='TEACHER19').collect()
teacher_list2.filter(lambda x:x[1]=='TEACHER16').collect()
teacher_list2.filter(lambda x:x[1]=='TEACHER22').collect()
teacher_list2.filter(lambda x:x[1]=='TEACHER11').collect()
用公司实发的工资-原来的工资
原来的工资:9000+8000+10000+9000+11000=47000
现在的工资:10800+8800+8000+8100+9900=45600
47000-45600=1400
即少发了1400元。
总结
以上就是今天要讲的内容,本文仅仅简单介绍了reduceByKey,sortBy,sortByKey,lambda,map,filer,countByKey等的使用,通过这些实际案例熟悉函数的使用方法。
以上是关于rdd实验——教师绩效考核的主要内容,如果未能解决你的问题,请参考以下文章