《大数据开发》数据类型+常用数据处理
Posted Steve_Abelieve
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《大数据开发》数据类型+常用数据处理相关的知识,希望对你有一定的参考价值。
数据类型
从结构划分

常见数据操作
- 均值操作:作用衡量这个系统的平均值,可以做两个系统的比较。缺点:对异常数据敏感
- 标准差操作:衡量这个系统的波动程度,可以做两个系统的比较。缺点:对异常数据敏感
- 变异系数操作:均值/方差,可以用于不同系统的比较。
- 切尾均值操作:作用衡量这个系统的平均值,可以做两个系统的比较,一定程度上解决数据异常。
异常检测
什么是异常(离群点):异常就是显著不同于这个系统的值,不属于该系统的范围。
1.系统异常:属于合理的,但是确实发生了。如这个人身高2.3m。
2.非系统异常:属于不合理的,由于登录错误造成的。100m。
异常对数据挖掘、分析的影响:如果不做异常处理,那么就会很大程度影响分析结果,导致错误的决策。专门有一个领域就是异常检测领域:作弊系统、垃圾邮件、黑客攻击、信用评分等。
数据变化
作用:
- 去量钢化。
- 在算法中使得梯度下降快速收敛。
- 使得计算距离不会出现大数吃小数的状态。
数据归一化:是将数据按比例缩放,使之落入一个小的特定区间。
数据log转化:通过log压缩,使得异常数据 不在那么异常。
z-score 标准化:将数据看成是正态分布,通过减去均值,除以标准差将数据转为标准正态分布。
算法练习
3西格玛准则异常识别
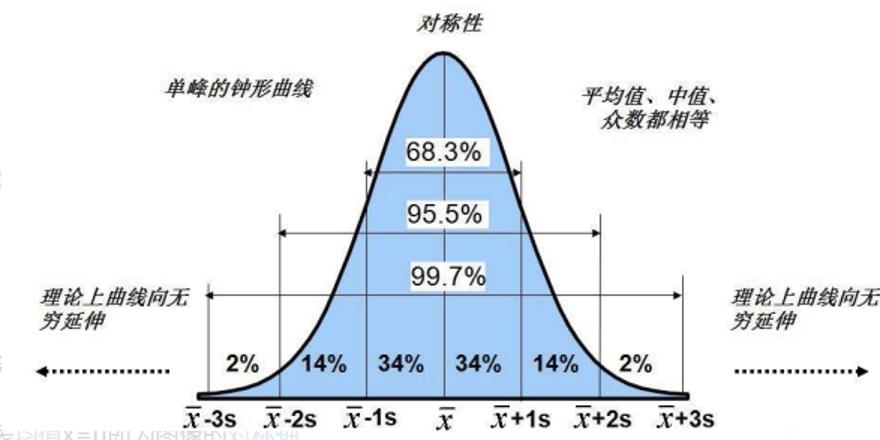
sigma原则:数值分布在(μ-σ,μ+σ)中的概率为0.6526;
2sigma原则:数值分布在(μ-2σ,μ+2σ)中的概率为0.9544;
3sigma原则:数值分布在(μ-3σ,μ+3σ)中的概率为0.9974;
其中在正态分布中σ代表标准差,μ代表均值x=μ即为图像的对称轴。
由于“小概率事件”和假设检验的基本思想 “小概率事件”通常指发生的概率小于5%的事件,认为在一次试验中该事件是几乎不可能发生的。
由此可见X落在(μ-3σ,μ+3σ)以外的概率小于千分之三,在实际问题中常认为相应的事件是不会发生的,基本上可以把区间(μ-3σ,μ+3σ)看作是随机变量X实际可能的取值区间,这称之为正态分布的“3σ”原则。
以上是关于《大数据开发》数据类型+常用数据处理的主要内容,如果未能解决你的问题,请参考以下文章