nodejs爬取博客园的博文
Posted 卡卡小狮子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了nodejs爬取博客园的博文相关的知识,希望对你有一定的参考价值。
其实写这篇文章,我是很忐忑的,因为爬取的内容就是博客园的,万一哪个顽皮的小伙伴拿去干坏事,我岂不成共犯了?
好了,进入主题。
首先,爬虫需要用到的模块有:
express
ejs
superagent (nodejs里一个非常方便的客户端请求代理模块)
cheerio (nodejs版的jQuery)
前台布局使用bootstrap
分页插件使用 twbsPagination.js
完整的爬虫代码,在我的github中可以下载。主要的逻辑代码在 router.js 中。
1. 爬取某个栏目第1页的数据
分析过程:
打开博客园的主页: http://www.cnblogs.com/
左侧导航栏里显示了所有栏目的分类信息,可以在开发者工具中获取查看这些信息.
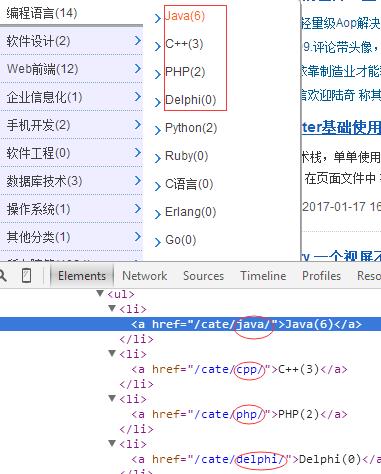
每个栏目的URL也很有规律,都是 www.cnblogs.com/cate/栏目名称。 根据这个URL就可以爬取某个栏目第1页的博文了~
下面贴出代码:
app.js (入口文件)
1 // 载入模块 2 var express = require(\'express\'); 3 var app = express(); 4 var router = require(\'./router/router\'); 5 6 // 设置模板引擎 7 app.set(\'view engine\', \'ejs\'); 8 9 // 静态资源中间件 10 app.use(express.static(\'./public\')); 11 12 // 博客园 13 app.get(\'/cnblogs\', router.cnblogs); 14 // 栏目 15 app.get(\'/cnblogs/cate/:cate/\', router.cnblogs_cate); 16 17 18 app.listen(1314, function(err){ 19 if(err) console.log(\'1314端口被占用\'); 20 });
router.js
var request = require(\'superagent\'); var cheerio = require(\'cheerio\'); // 栏目 var cate = [ \'java\', \'cpp\', \'php\', \'delphi\', \'python\', \'ruby\', \'web\', \'javascript\', \'jquery\', \'html5\' ]; // 显示页面 exports.cnblogs = function(req, res){ res.render(\'cnblogs\', { cate: cate }); }; // 爬取栏目数据 exports.cnblogs_cate = function(req, res){ // 栏目 var cate = req.params[\'cate\']; request .get(\'http://www.cnblogs.com/cate/\' + cate) .end(function(err, sres){ var $ = cheerio.load(sres.text); var article = []; $(\'.titlelnk\').each(function(index, ele){ var ele = $(ele); var href = ele.attr(\'href\'); // 博客链接 var title = ele.text(); // 博客内容 article.push({ href: href, title: title }); }); res.json({ title: cate, cnblogs: article }); }); };
cnblogs.ejs
只贴出核心代码
1 <div class="col-lg-6"> 2 <select class="form-control" id="cate"> 3 <option value="0">请选择分类</option> 4 <% for(var i=0; i<cate.length; i++){ %> 5 <option value="<%= cate[i]%>"><%= cate[i]%></option> 6 <% } %> 7 </select> 8 </div>
JS模板
<script type="text/template" id="cnblogs">
<ul class="list-group">
<li class="list-group-item">
<a href="{{= href}}" target="_blank">{{= title}}</a>
</ul>
</script>
Ajax请求
$(\'#cate\').on(\'change\', function(){ var cate = $(this).val(); if(cate == 0) return; $(\'.artic\').html(\'\'); $.ajax({ url: \'/cnblogs/cate/\' + cate, type: \'GET\', dataType: \'json\', success: function(data){ var cnblogs = data.cnblogs; for(var i=0; i<cnblogs.length; i++){ var compiled = _.template($(\'#cnblogs\').html()); var art = compiled(cnblogs[i]); $(\'.artic\').append(art); } } }); });
输入: http://localhost:1314/cnblogs/ ,可以看到, 成功获取javascript下第1页数据。
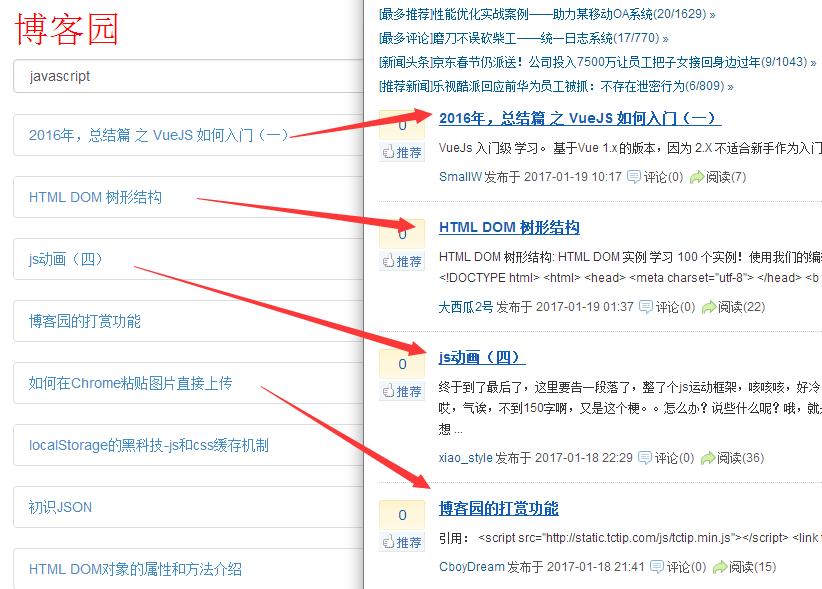
2. 分页功能
以 http://www.cnblogs.com/cate/javascript/ 为例:
首先,分页的数据是Ajax调用后端接口返回的。
chrome的开发者工具中,可以看到,分页时,会向服务器发送两个请求,
PostList.aspx 请求具体某页的数据.
load.aspx 返回分页字符串.

我们重点分析 PostList.aspx 这个接口:
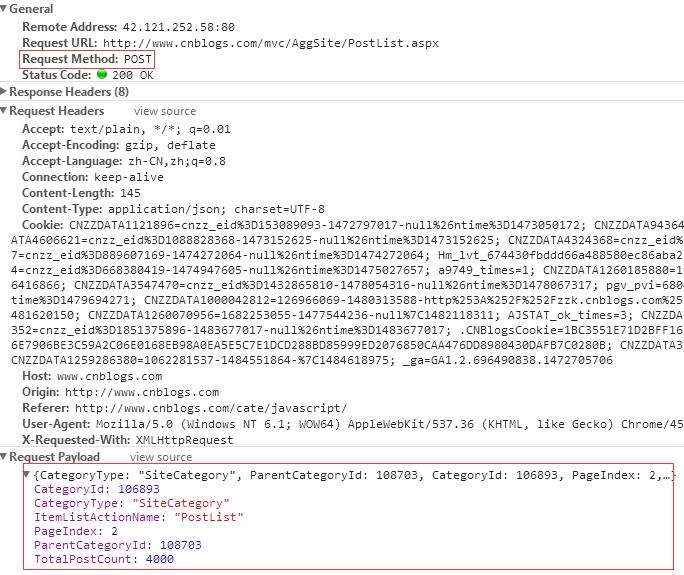
可以发现 请求方式是POST。
问题的重点是POST请求的数据是如何组装的?
分析源码,发现每个分页字符串都绑定了一个事件 -- aggSite.loadCategoryPostList()
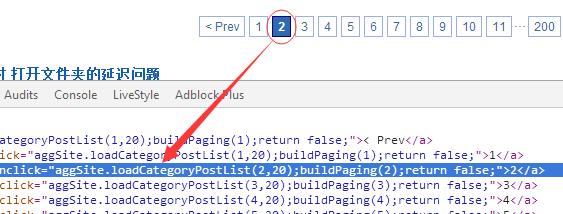
查看页面源码,发现这个函数定义在 aggsite.js 文件里.

也就是下面这个函数.
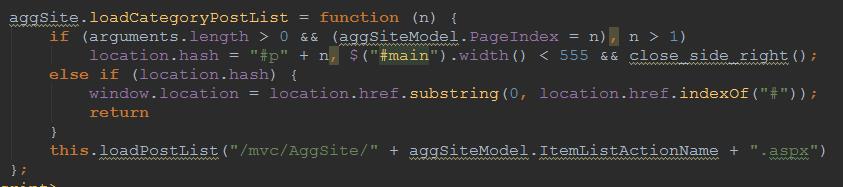
重点是这行代码, 使用Ajax向后端发送请求.
this.loadPostList("/mvc/AggSite/" + aggSiteModel.ItemListActionName + ".aspx").
分析loadPostList 函数,可以发现POST的数据是变量aggSiteModel的值.
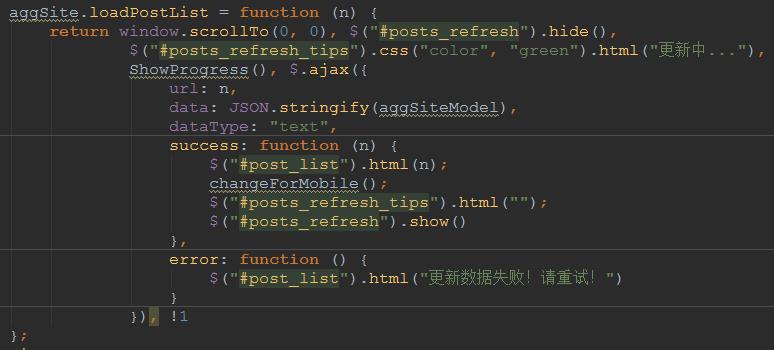
而 aggSiteModel 在页面中的定义:

至此前端的分析告一段落。 我们要做的,就是使用nodejs,模拟浏览器发送请求。
router.js
1 exports.cate_page = function(req, res){ 2 3 var cate = req.query.cate; 4 var page = req.query.page; 5 6 var url = \'http://www.cnblogs.com/cate/\' + cate; 7 8 request 9 .get(url) 10 .end(function(err, sres){ 11 12 // 构造POST请求的参数 13 var $ = cheerio.load(sres.text); 14 var post_data_str = $(\'#pager_bottom\').prev().html().trim(); 15 var post_data_obj = JSON.parse(post_data_str.slice(post_data_str.indexOf(\'=\')+2, -1)); 16 17 // 分页接口 18 var page_url = \'http://www.cnblogs.com/mvc/AggSite/PostList.aspx\'; 19 // 修改当前页 20 post_data_obj.PageIndex = page; 21 22 request 23 .post(page_url) 24 .set(\'origin\', \'http://www.cnblogs.com\') // 伪造来源 25 .set(\'referer\', \'http://www.cnblogs.com/cate/\'+cate+\'/\') // 伪造referer 26 .send(post_data_obj) // POST数据 27 .end(function(err, ssres){ 28 var article = []; 29 var $$ = cheerio.load(ssres.text); 30 $$(\'.titlelnk\').each(function(index, ele){ 31 var ele = $$(ele); 32 var href = ele.attr(\'href\'); 33 var title = ele.text(); 34 article.push({ 35 href: href, 36 title: title 37 }); 38 }); 39 res.json({ 40 title: cate, 41 cnblogs: article 42 }); 43 }); 44 }); 45 };
cate.ejs 分页代码
1 $(\'.pagination\').twbsPagination({ 2 totalPages: 20, // 默认显示20页 3 startPage: 1, 4 visiblePages: 5, 5 initiateStartPageClick: false, 6 first: \'首页\', 7 prev: \'上一页\', 8 next: \'下一页\', 9 last: \'尾页\', 10 onPageClick: function(evt, page){ 11 $.ajax({ 12 url: \'/cnblogs/cate_page?cate=\' + cate + \'&page=\' + page, 13 type: \'GET\', 14 dataType: \'json\', 15 success: function(data){ 16 $(\'.artic\').html(\'\'); 17 var cnblogs = data.cnblogs; 18 for(var i=0; i<cnblogs.length; i++){ 19 var compiled = _.template($(\'#cnblogs\').html()); 20 var art = compiled(cnblogs[i]); 21 $(\'.artic\').append(art); 22 } 23 } 24 }); 25 } 26 });
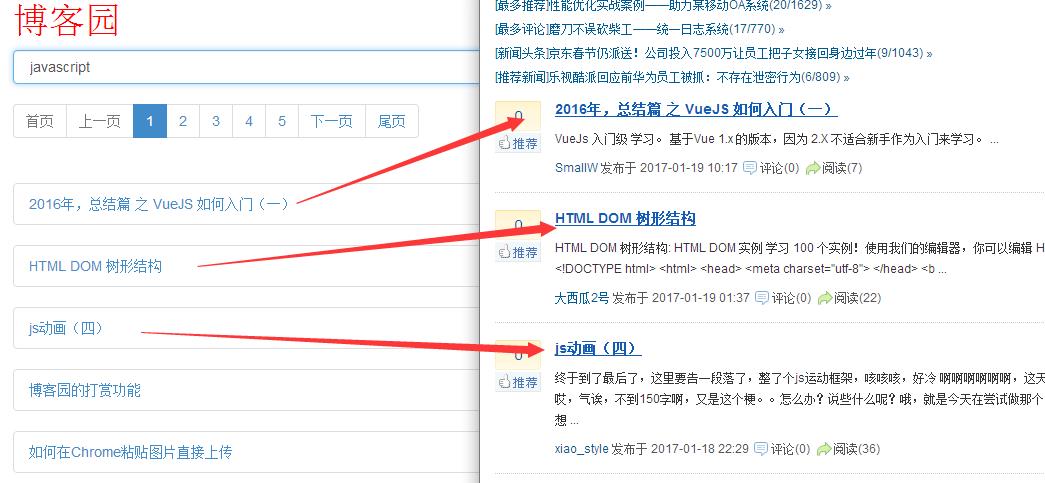
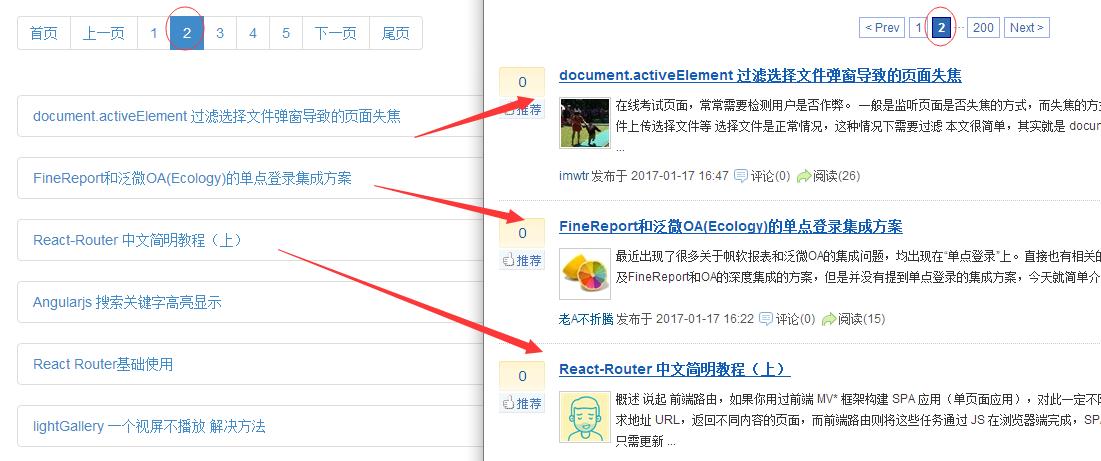
输入:http://localhost:1314/cnblogs/cate,可以看到:
javascript栏目第1页数据
第2页数据
后话
至此,一个简单的爬虫就完成了。 其实爬虫本身并不难,难点在于分析页面结构,和一些业务逻辑的处理。
完整的代码,我已经放在github上,欢迎starn(☆▽☆)。
由于是第一次写技术类的博客,文笔有限,才学疏浅,若有不正确的地方,欢迎广大博友指正。
参考资料:
以上是关于nodejs爬取博客园的博文的主要内容,如果未能解决你的问题,请参考以下文章