Keras框架认识
Posted Caaaaaan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Keras框架认识相关的知识,希望对你有一定的参考价值。
简介
Keras是TensorFlow的接口
MNIST Data: http://yann.lecun.com/exdb/mnist
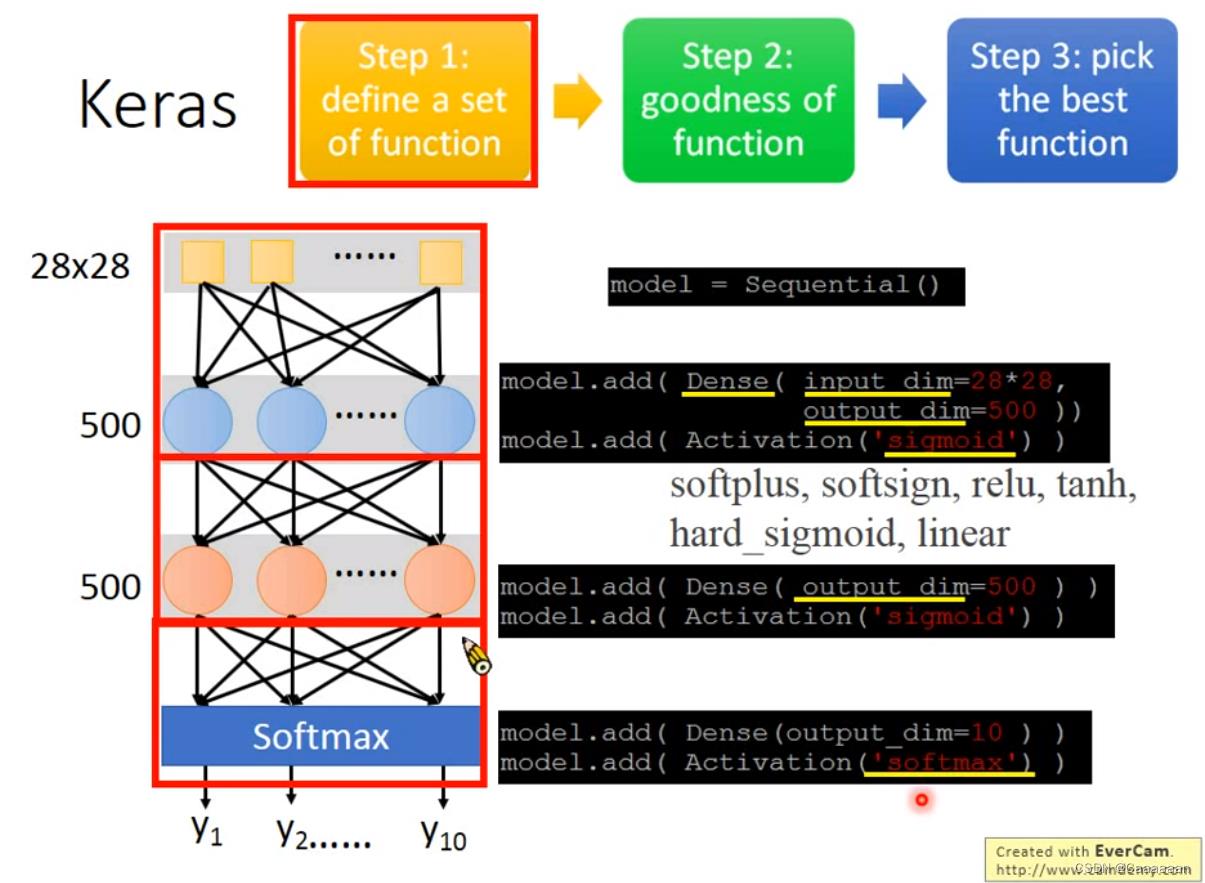
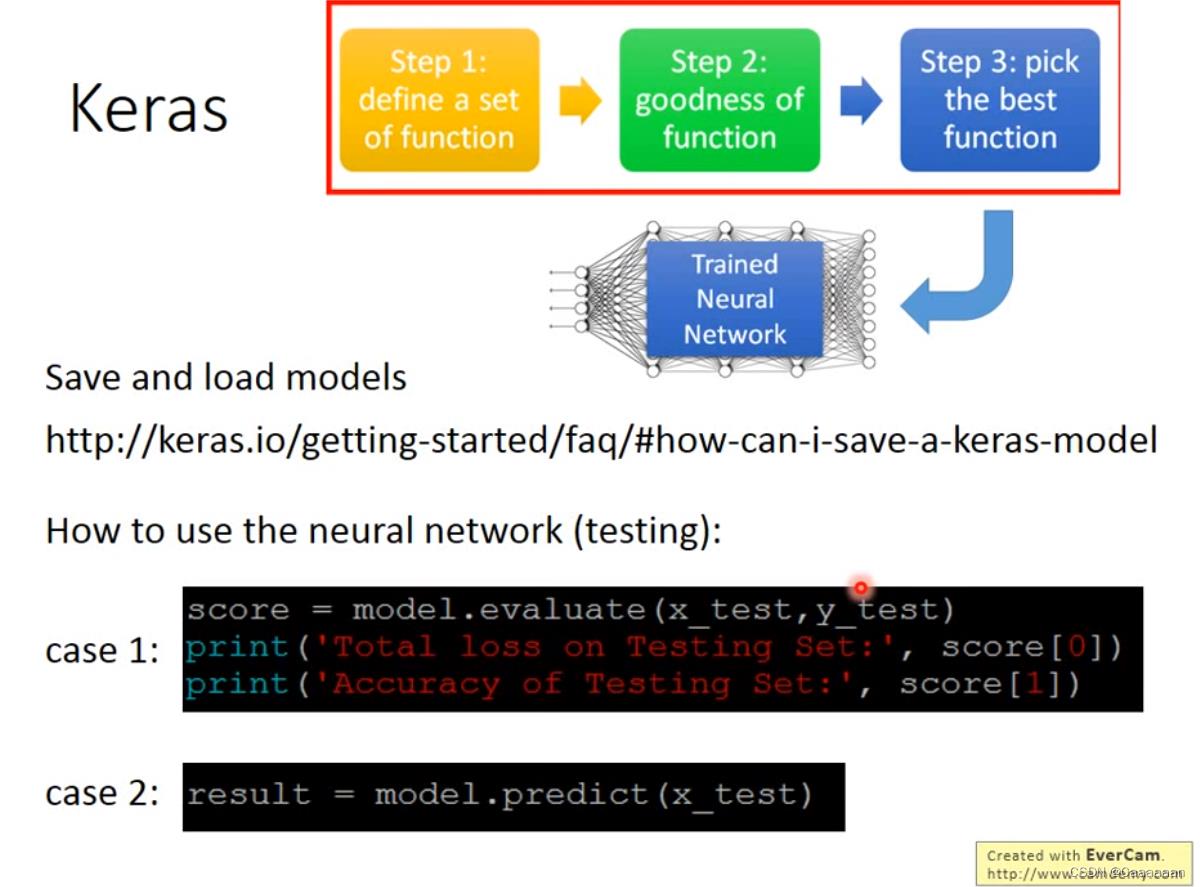
定义函数集合
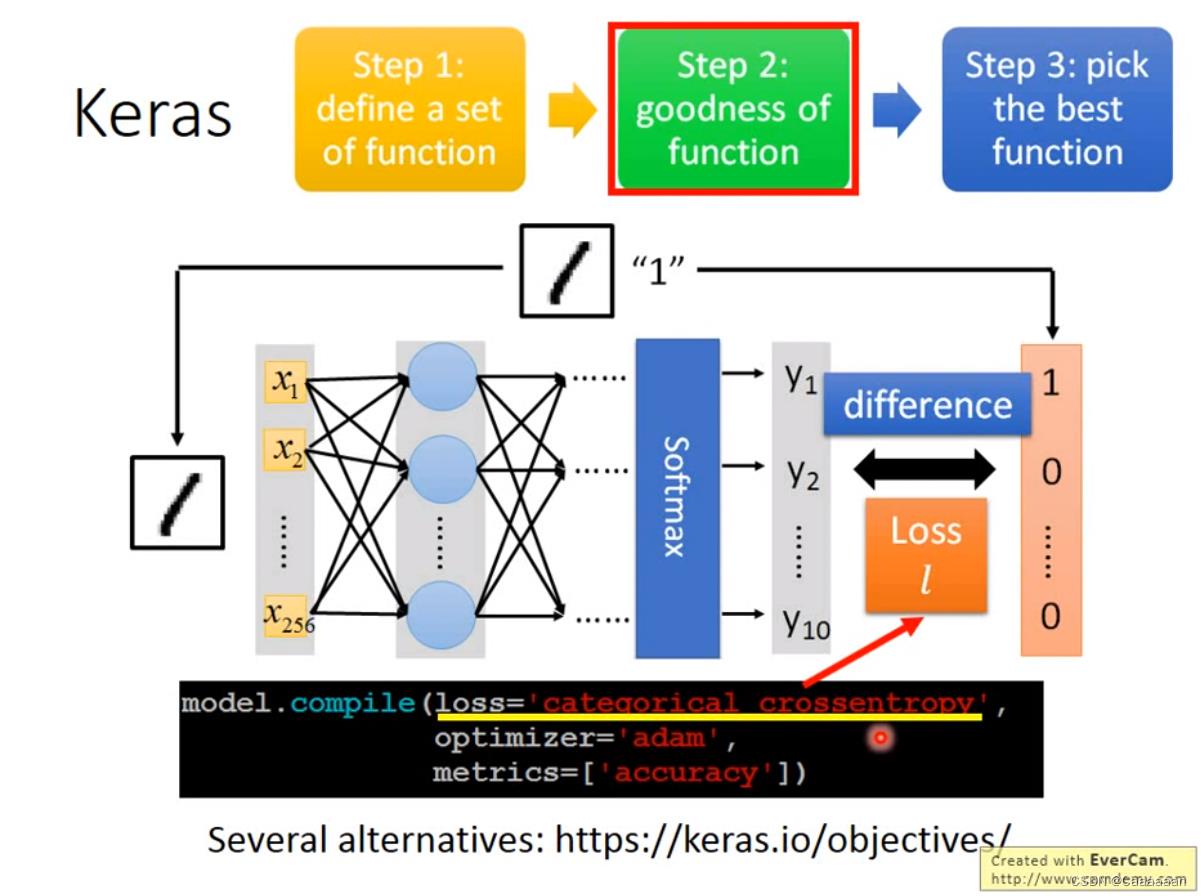
定义损失函数
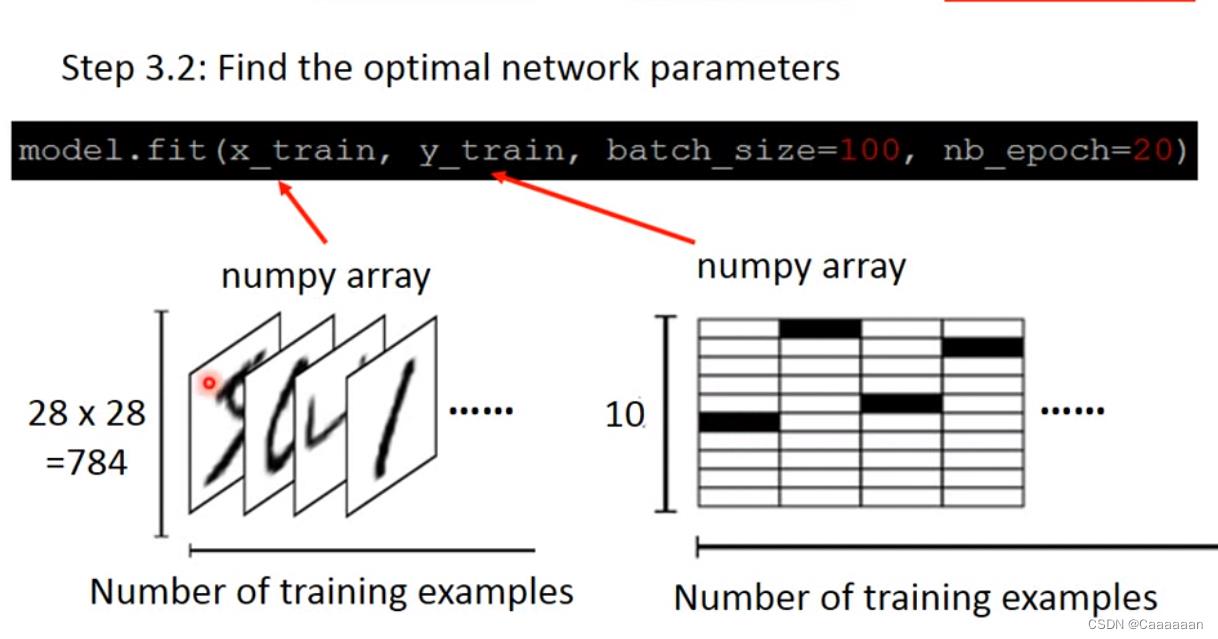
训练

- 处理训练样本和标签
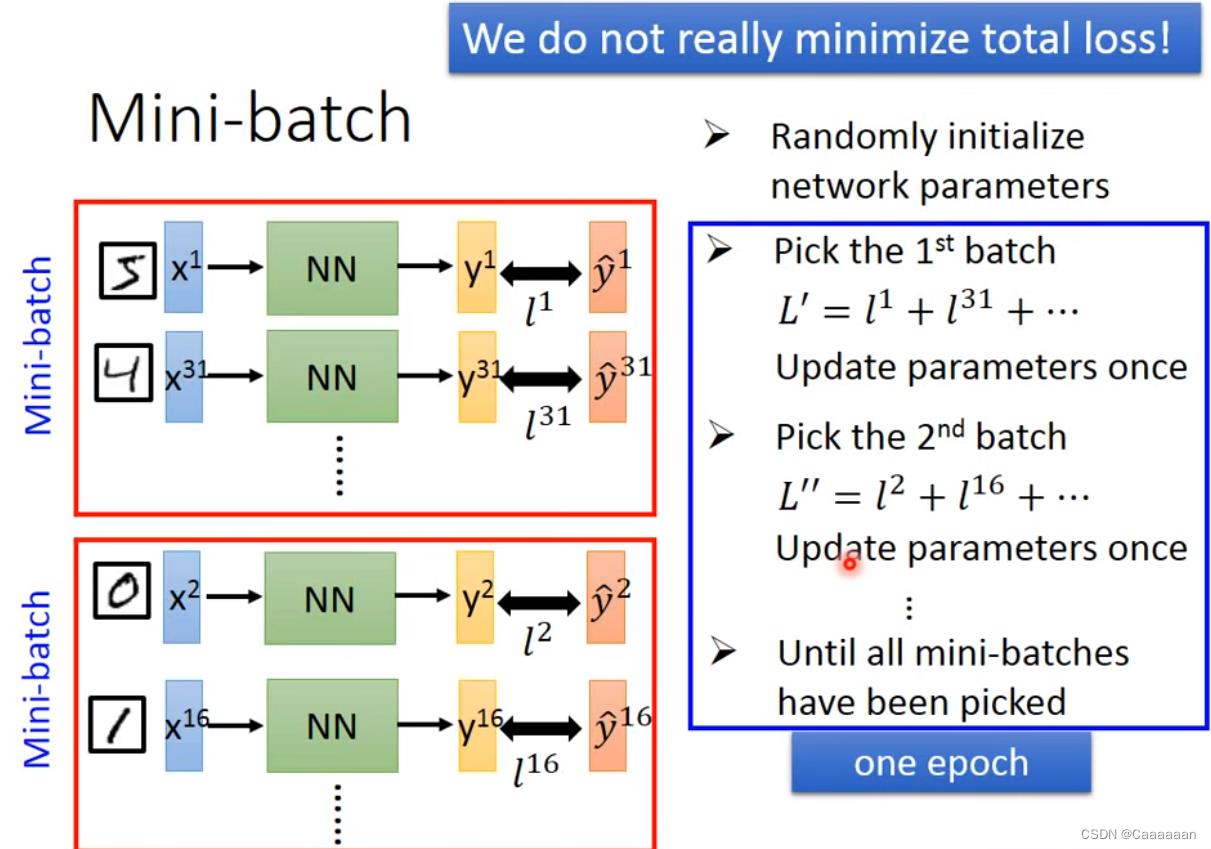
-
把Train Data训练成一个个batch,多少个batch—参数设置为batch_size()
每一个batch里面的样本是随机的
然后计算每个batch的Loss,每一个batch都会更新一遍参数
当所有batch都过了一轮之后,称为一个epoch
-
总共updata参数的次数=epoch*batch_size
-
当每个batch里面只有一个样本时,这个时候是随机梯度下降
详细回顾文章梯度下降法_Caaaaaan的博客-CSDN博客
-
好处就是——速度比较快,因为每一道一个样本就是Update一次参数
虽然每次方向是不稳定的,但天下武功,唯快不破
速度
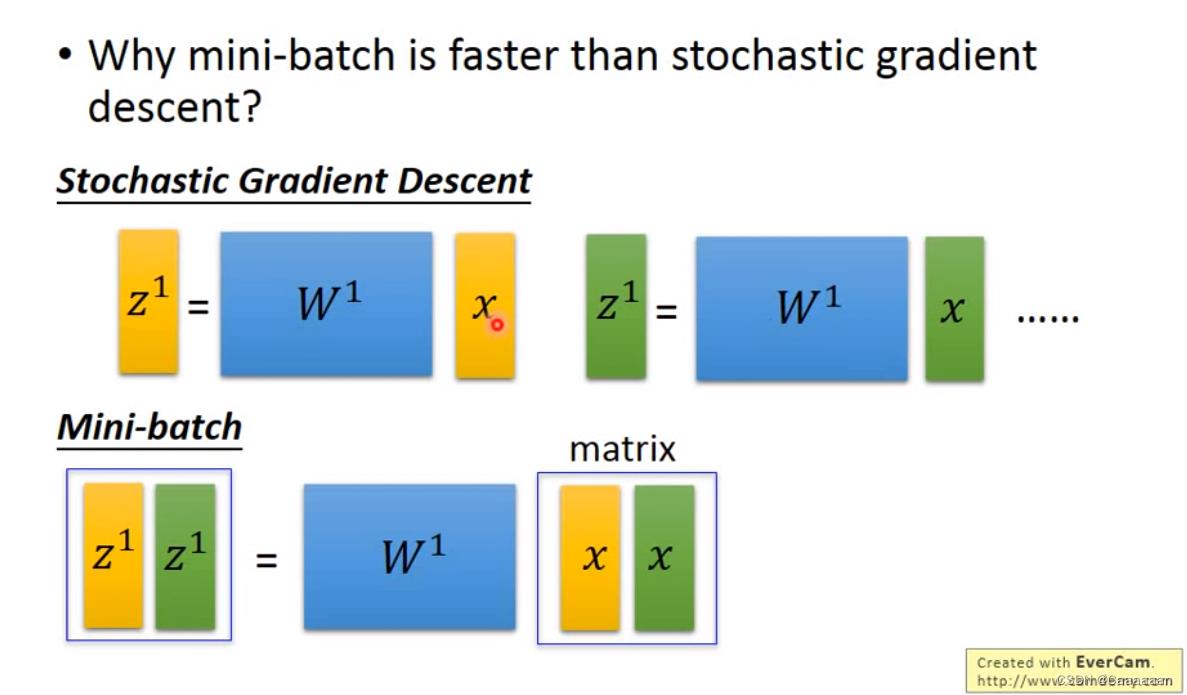
——为什么不直接用随机梯度下降,而需要使用mini_batch这种方法呢?
-
小的batch size意味着你在一次epoch里面更新更多次参数
但是在实作上,同样总量的数据集,batch size的设置不一样,所需要的时间也不一样——也就是完成一个epoch的时间不一样

-
然后你会发现,updates同样次数的参数,所需要的时间基本上是一样的
在batch size=10的时候,完成10次epoch,update50000次参数,最终时间所差无几
-
在时间差异甚微的时候,我们往往会更倾向于寻找batch size更大的一方
因为batch size更大的一方,update参数的方向更稳定
-
batch size比较大时,我们使用了GPU的并行计算
——那为什么batch size不设置成无穷大?
-
GPU能够同时考虑10个examples,其在一个epoch里,和考虑一个example的时间是一样的
-
但是GPU存在并行计算的极限,当你同时考虑一万个example的时候,它的时间并不会和考虑一个example的时间是一样的
——抛开硬件限制不谈
-
如果你的batch size特别大的时候,你的神经网络跑几下就卡住了,就会陷入到鞍点或者局部最小值中
-
因为在神经网络的error surface上面,它不是一个凸优化问题
它存在很多的坑坑洞洞,如果你今天的full的batch,就顺着total loss的梯度下降的方向走,就会没走几步就卡住了
-
而设置了mini batch,就等于引入了一些梯度方向的随机性,只要你的局部最优点不是特别深,你的鞍点不是特别麻烦的一个鞍点,你只要有一个随机性,就能跳出这个卡住的点
测试
Keras手写数字辨识示例
import numpy as np
from keras.models import Sequential
from keras.layers.core import Dense,Dropout,Activation
from keras.layers import Conv2D,MaxPooling2D,Flatten
from keras.optimizers import SGD,Adam
from keras.utils import np_utils
from keras.datasets import mnist
def load_data():
(x_train,y_train),(x_test,y_test)=mnist.load_data()
number=10000
x_train=x_train[0:number]
y_train=y_train[0:number]
x_train=x_train.reshape(number,28*28)
x_test=x_test.reshape(x_test.shape[0],28*28)
x_train=x_train.astype('float32')
x_test=x_test.astype('float32')
y_train=np_utils.to_categorical(y_train,10)
y_test=np_utils.to_categorical(y_test,10)
x_train=x_train
x_test=x_test
x_train /= 255
x_test /= 255
return (x_train,y_train),(x_test,y_test)
(x_train,y_train),(x_test,y_test)=load_data()
print(x_train.shape) #(10000,784)
print(y_train.shape) #(10000,10)
model=Sequential()
model.add(Dense(input_dim=28*28,units=500,activation='sigmoid'))
model.add(Dense(units=500,activation='sigmoid'))
model.add(Dense(units=10,activation='softmax'))
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
model.fit(x_train,y_train,batch_size=100,epochs=20)
result=model.evaluate(x_test,y_test)
print(result[0],result[1],sep='\\n');
以上是关于Keras框架认识的主要内容,如果未能解决你的问题,请参考以下文章