websocket 爬虫
Posted 九茶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了websocket 爬虫相关的知识,希望对你有一定的参考价值。
前言
有些网站为了追求数据的实时更新,很多时候会采用 websocket 的方式,例如股票交易数据、数据货币交易数据等。关于websocket的机制,网上不乏相关资料。但关于websocket的爬虫文章,还是比较少的。所以特地写此文章做个分享,希望对他人有所帮助。

正文
1、 首先要意识到,websocket和普通的HTTP请求有些不同。websocket的方式:用户浏览器(客户端)和对方网站(服务端)首先进行握手,握手成功即建立连接,可以理解为两者建立了私有通道。websocket是全双工的,客户端可以给服务端发消息,服务端也可以给客户端发消息。一般对交易网站来说,客户端在建立连接后会发送几个消息给服务端,告诉服务端要订阅哪些数据。之后服务端会不断地将新数据推送过来。在服务端推送数据的中途可能会给客户端发一个ping请求,客户端要给它返回pong消息,以检测连接是否正常(心跳检测)(有些网站会由客户端发ping)。
所以websocket爬虫的步骤:建立连接 -> 发送消息订阅数据 -> 不断接收数据 -> 定时回应心跳检测。
2.、对于python2.7的爬虫,有websocket模块可用,安装方式:pip install websocket-client。
3、 举个例子,选了一个国内可访问的比特币交易平台:www.bitforex.com 。
# encoding=utf-8
import websocket
if __name__ == '__main__':
ws = websocket.create_connection('wss://ws.bitforex.com/mkapi/coinGroup1/ws', timeout=10)
ws.send('["type": "subHq", "event": "trade", "param": "businessType": "coin-usdt-btc", "dType": 0, "size": 100]') # 订阅交易数据
for i in range(5):
content = ws.recv()
print content
ws.close()
4、有些网站传过来的不是字符串,而是二进制数据。例如[火币](https://www.huobi.com/btc_usdt/exchange/)、[okcoin](https://www.okcoin.com/market#product=btc_usd)等。 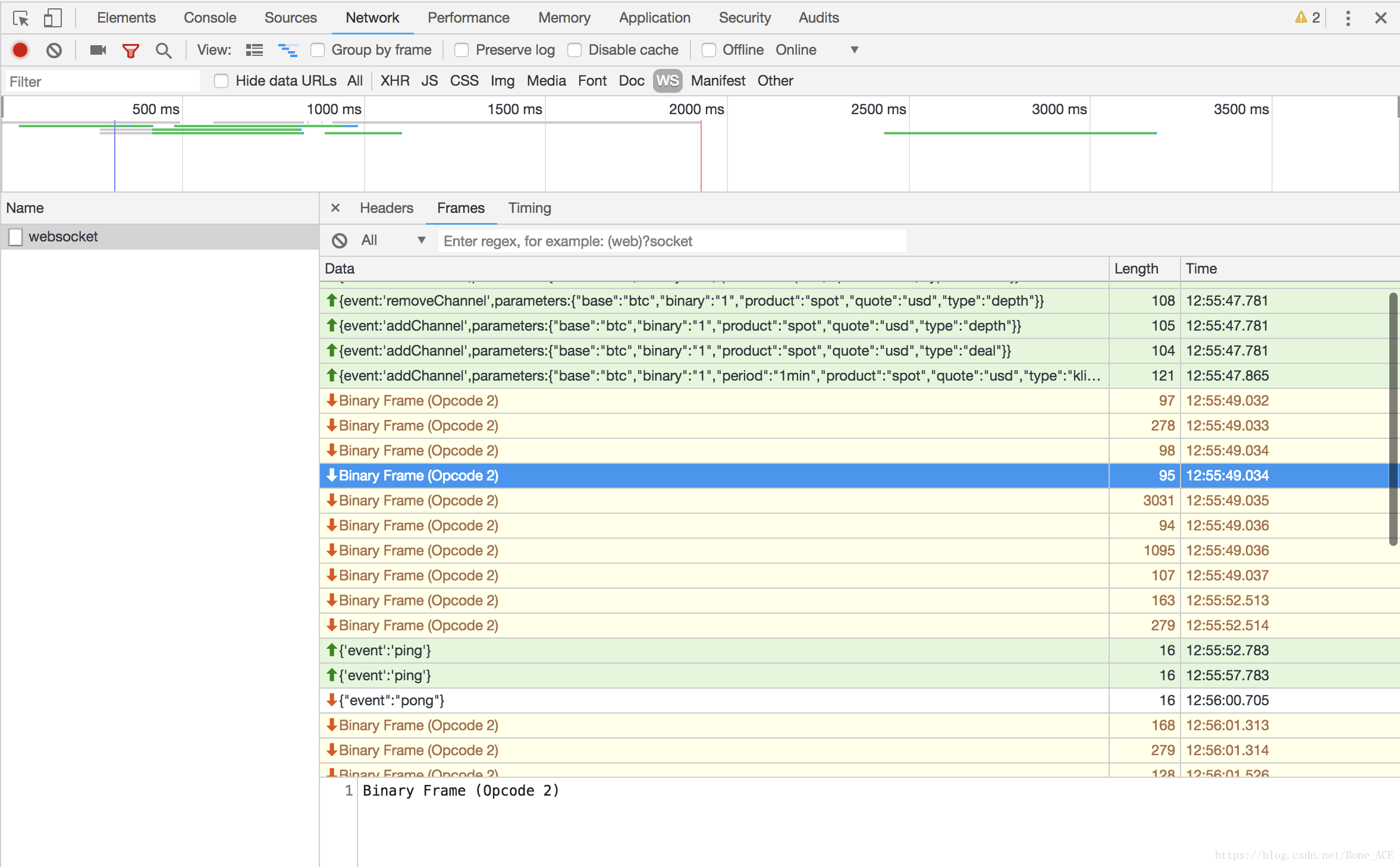 年少无知的我,竟然用struct、binascii等模块去转string,然而都失败了。网上各种搜索也无果。 后来用浏览器调试,定位到js代码里解析的地方。看了一下js代码,觉得应该是将二进制数据先转数字,对这组数字做了一些解密,然后将解密后的数组转字符,即是最后的明文字符串。准备用python重写,或者将js代码块抠出来用nodejs跑,发现难度有点大。 惆怅之际偶然发现,这websocket传过来的数据,其实只是压缩过后的二进制数据,坑爹呢这是!劳资忙活大半天,差点将用来解压缩的js代码重写了!也是够蠢,果然道行不够。 放代码,
# encoding=utf-8
import zlib
import websocket
def crawl_huobi_demo():
""" 抓取火币的数据 """
url = 'wss://www.huobi.pro/-/s/pro/ws'
ws = websocket.create_connection(url, timeout=10)
ws.send('"sub":"market.btcusdt.trade.detail"')
for i in range(5):
content_compress = ws.recv()
content = zlib.decompress(content_compress, 16+zlib.MAX_WBITS)
print content
ws.close()
def crawl_okcoin_demo():
""" 抓取okcoin的数据 """
url = 'wss://real.okcoin.com:10440/websocket'
ws = websocket.create_connection(url, timeout=10)
ws.send("""event:'addChannel',parameters:"base":"btc","binary":"1","product":"spot","quote":"usd","type":"depth"""")
for i in range(5):
content_compress = ws.recv()
content = zlib.decompress(content_compress, -zlib.MAX_WBITS)
print content
ws.close()
if __name__ == '__main__':
crawl_huobi_demo()
crawl_okcoin_demo()
5、”Read timed out”
我们使用ws.recv()拿数据,但是如果服务器长时间没有消息推送过来,这一步便会报timeout错误。一般来说,我们可以忽略这个timeout,没有影响。
以上是服务器消息推送太慢的情况,那如果服务器推送速度非常快呢。ws.recv()每次只能拿一条数据,拿到数据还要做处理,需要一定的时间。如果我正在处理的时候服务端又给我推了一条新消息,我会不会丢失这条新消息呢?经检测,并不会丢,消息会积压,等着你读取。
那,如果服务器消息推送的速度快于ws.recv()读取的速度,积压的数据是不是会越来越多?最后会怎样?实际上,心跳检测就起效了,服务端发了一个ping的消息,如果客户端不及时回应的话,服务端会把这个连接断开,不再推送。
事实上,我们写爬虫的时候就要尽量避免阻塞,接收到数据立马就丢到内存队列,让其他程序去做解析等处理,以保证websocket客户端能顺畅、及时地接收消息。
6、”Handshake status 429 Too Many Requests”
这个异常,是因为连接数太多了。例如bitmex,限制一个IP在一个小时内只能建立20条websocket连接,超过了,就报429。这就有点像403了,同样是对IP做的频率限制,但429的情况,过了这个时间就能恢复正常,而403的惩罚可能限制你几天不能访问,甚至永久禁止你访问。
知道了这个报错的原因,就制定应对对策吧:
- 既然对IP做的限制,那么最直接粗暴的:加代理。但加代理也是有代价的:出钱;增加延迟;更不稳定;等。特别是像数字货币交易平台,很多都是需要翻墙,那么你就需要用香港或者国外的代理,而且是长效的代理。
- 一般429针对的是websocket连接次数,那么我们可以尽量减少websocket连接数。假如我们要爬10个币种的数据,我们并不一定要建立10个websocket连接,我们可以将这10个币种数据的订阅请求放在一个通道里,在一个websocket通道里实现10个币的数据抓取。理论上一个网站只需要建立一个websocket连接就行了。(然而有些网站不采用订阅的方式,使用不同的URL,每个websocket只传输一种数据。更有些网站,例如bitmex,一次订阅就当成一次连接)
- 研究websocket断开的原因,尽量保证websocket连接长久稳定。例如及时响应心跳检测,不然断了又要做一次连接。
结语
今天先写这些,主要分享的是怎么爬websocket数据,怎么处理binary数据,以及一些异常处理。如果你遇到新的问题,或者有其他值得分享的知识点,都欢迎留言。
另外,如果你需要数字货币交易平台(例如币安、火币、okex、poloniex、bitmex、okcoin等)的爬虫或者数据,也可以找我。
题外话,预测者网卖这类数据,卖的也是挺开心的。
以上是关于websocket 爬虫的主要内容,如果未能解决你的问题,请参考以下文章