神经网络中的Softmax是如何更新参数的
Posted Maggie张张
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络中的Softmax是如何更新参数的相关的知识,希望对你有一定的参考价值。
本文将从两个方面阐述神经网络中的softmax是如何更新参数的。
第一部分:BP算法怎么更新参数?缺点是什么?
第二部分:用了softmax怎么更新参数?
一、BP算法用二次经验误差作为代价函数
我们已经知道,BP算法在前向传播中,在每一个功能节点上先是线性组合算得一个状态值,然后用Sigmoid转换成一个激活值,最后一层中把这个激活值o跟真是标签做差求平方,得到某个样本的二次经验误差,作为向前矫正参数的代价函数。
模型最终的目标就是要让所有训练样本的这个误差之和最小。
Loss=∑i=0nE(i)
而这个代价函数中, a(i) 是sigmoid函数的结果,而sigmoid函数的输入是某个神经元的权值向量 w 的函数,所以整个代价函数Loss其实是整个网络中每个功能单元拥有的权值向量

要想使得Loss最小,对
w
求偏导,就可以得到网络中的每一层每个神经元的参数的更新公式:
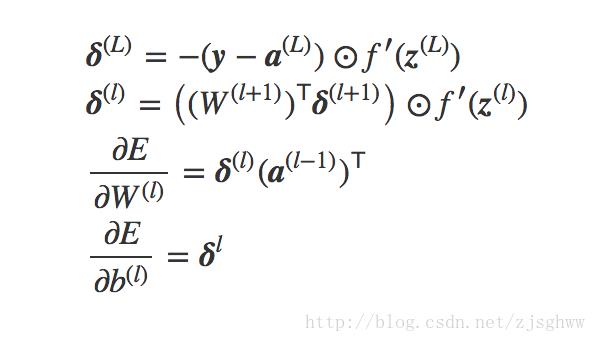
可以看到每一层误差后向传播时,跟激活函数的斜率
那么一个自然的想法就是:替换激活函数,比如ReLU函数,当自变量大于0时,斜率都是一个值,避免梯度消失。
还有一个想法:替换代价函数,改成交叉熵函数,它是Softmax更新参数的代价函数。
二、Softmax用交叉熵做损失函数更新网络参数
首先,Softmax是用于多分类的,常常用于神经网络最后一层作为多分类器,有多少个类别最后一层就有多少个神经元,每个样本的类别标签用one-hot编码,即:一个0/1串,长度是类别数,属于j类,就在第j个位置上标记1。例如,分5类,y是3,它的编码就是00100。
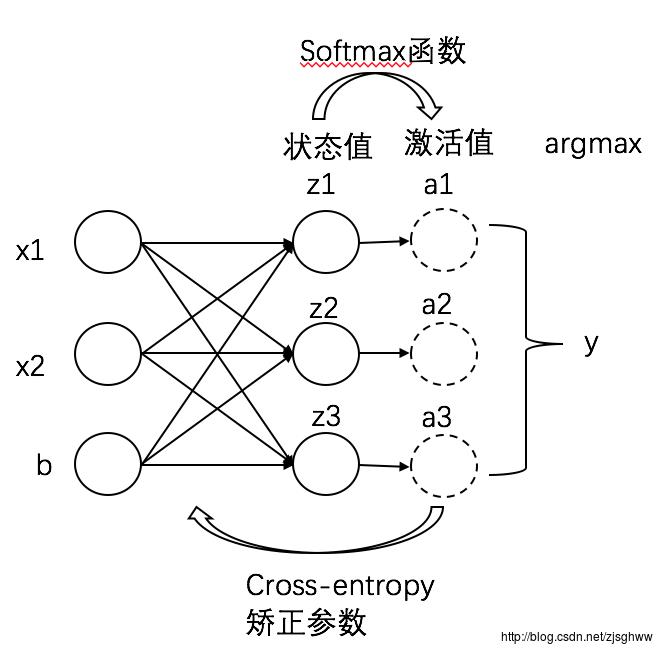
softmax函数:
假设某个样本在分类层的某个神经元上得到的状态值是z,那么它属于类别j的概率就可以通过Softmax公式得到,分母是本层所有神经元的 ez 之和(因为分类层有k个神经元,对应k个类别)。
定义每个样本的交叉熵是
−tlog(a)
,其中
t
是该样本的标签值(one-hot编码的),
对于整个训练样本,定义损失函数为:
交叉熵是用来衡量我们的预测的低效性。
其中,a是z的函数(softmax), z是w的函数,所以整个代价函数是w的函数,要想求最小就要对w求偏导,利用链式求导法则,具体看这里
结论就是:
当上层节点p=类别节点j时,
否则
w=w
这样,每个神经的权值向量的更新要么减1,要么不变,就不用受激活函数的制约了。
以上是关于神经网络中的Softmax是如何更新参数的的主要内容,如果未能解决你的问题,请参考以下文章