Java使用Java实现爬虫
Posted Do_GH
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java使用Java实现爬虫相关的知识,希望对你有一定的参考价值。
文章目录
使用Java实现爬虫
一、HttpClient实现模拟HTTP访问
1.1 HttpClient
HTTP 协议是 Internet 上使用得最多、最重要的协议之一,越来越多的 Java 应用程序需要直接通过 HTTP 协议来访问网络资源。虽然在 JDK 的 java net包中已经提供了访问 HTTP 协议的基本功能,但是对于大部分应用程序来说,JDK 库本身提供的功能还不够丰富和灵活。HttpClient 是 Apache Jakarta Common 下的子项目,用来提供高效的、最新的、功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议。HttpClient 已经应用在很多的项目中,比如 Apache Jakarta 上很著名的另外两个开源项目 Cactus 和 HTMLUnit 都使用了 HttpClient。Commons HttpClient项目现已终止,不再开发。 它已被Apache HttpComponents项目里的HttpClient和HttpCore模块取代,它们提供了更好的性能和更大的灵活性。
1.2 引入依赖
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>$httpclient.version</version>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>$jsoup.version</version>
</dependency>
向项目中引入HttpClient和Jsoup依赖。
Jsoup用于解析获取的html文本,可以像JS一样通过id和class获取元素。同时Jsoup也可访问页面。
1.3 创建简单的请求操作
1.3.1 创建实例
public void testLinked() throws Exception
// 创建HttpClient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
// 创建GET请求
HttpGet httpGet = new HttpGet("https://blog.csdn.net/weixin_43347659");
httpGet.setHeader("use-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36");
// 获取响应结果
CloseableHttpResponse response = httpClient.execute(httpGet);
if (response.getStatusLine().getStatusCode() == 200)
String html = EntityUtils.toString(response.getEntity(), "UTF-8");
System.out.println(html);
httpClient.close();
response.close();
HttpClient用于创建连接对象,如果请求方式为GET则可以创建HttpGet对象,若为POST请求可创建HttpPost对象,请求的参数为待访问的URL。
可以根据实际请求内容适当的增加header的内容。调用HttpClient的execute()方法发起请求,并创建一个CloseableHttpResponse响应对象,可以通过判断响应状态码确定请求的结果。
根据现在的一些防爬虫设置,可能需要在
header添加固定的请求内容,例如host、origin等内容区分人机,可根据实际情况设置。
1.3.2 Jsoup应用
@Test
public void testJsoup() throws Exception
// 创建HttpClient
CloseableHttpClient httpClient = HttpClients.createDefault();
// 创建GET请求
HttpGet httpGet = new HttpGet("https://www.cnblogs.com/sam-uncle/category/1469093.html");
httpGet.setHeader("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36");
// 获取响应
CloseableHttpResponse response = httpClient.execute(httpGet);
// 获取页面内容
if (response.getStatusLine().getStatusCode() == 200)
String html = EntityUtils.toString(response.getEntity(), "UTF-8");
// 创建Document对象
Document document = Jsoup.parse(html);
// 获取博客列表
Element blog = document.getElementsByClass("entrylist").first();
Elements blogList = blog.getElementsByClass("entrylistItem");
for (Element element : blogList)
Elements title = element.select("a[class='entrylistItemTitle'] span");
System.out.println(title.text());
response.close();
httpClient.close();
通过调用Jsoup的parse(String html)方法即可将原始的HTML页面解析为Document类,这样我们就能够通过getElementById(String attr)、getElementsByClass(String attr)、select(String classAttr)等方式获取页面中的标签元素。
Document类为org.jsoup.nodes.Document注意不要使用错类。
1.4 爬取过程中可能出现的问题
1.4.1 JS异步加载问题
随着前端技术的发展,在页面中应用AJAX、VUE和AngularJS等技术已经很普及,因此在使用HttpClient时会发现,响应的结果与页面不相同,或者响应的页面并没有所需的内容。
因此可以从其他的思路来实现,例如我们可以通过访问内部接口获取响应值,通过这种方法可以跳过对页面的分析,直接获取想要的结果。主要难点在于分析该内容调用的接口。
例如我们查看CSDN的博客页面,点击搜索框可看到CSDN会推送热门的搜索信息,但是如果查看当前页面的网页源码是无法搜索到该内容的。
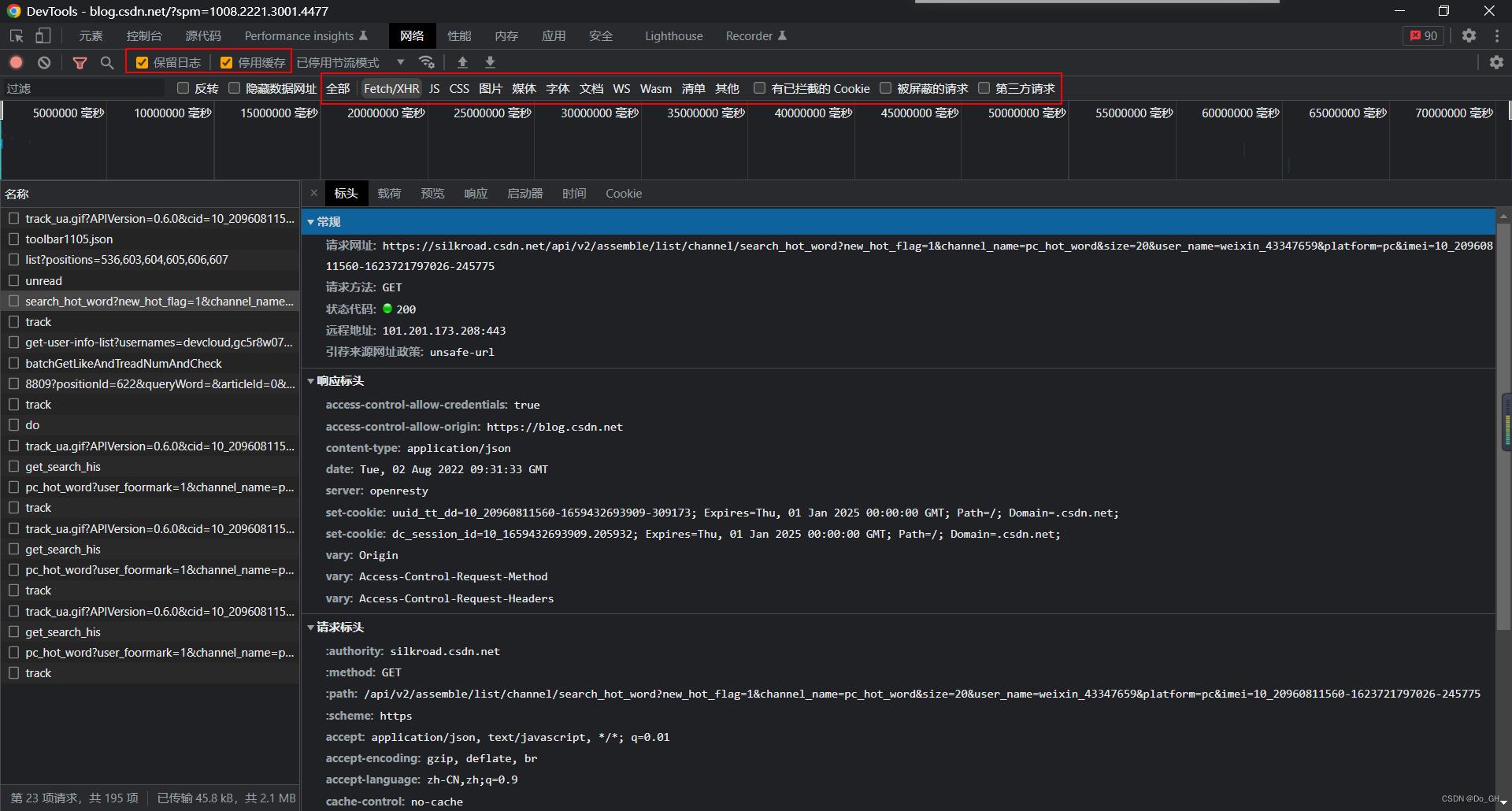
此时我们可以打开F12,查看页面的所有请求
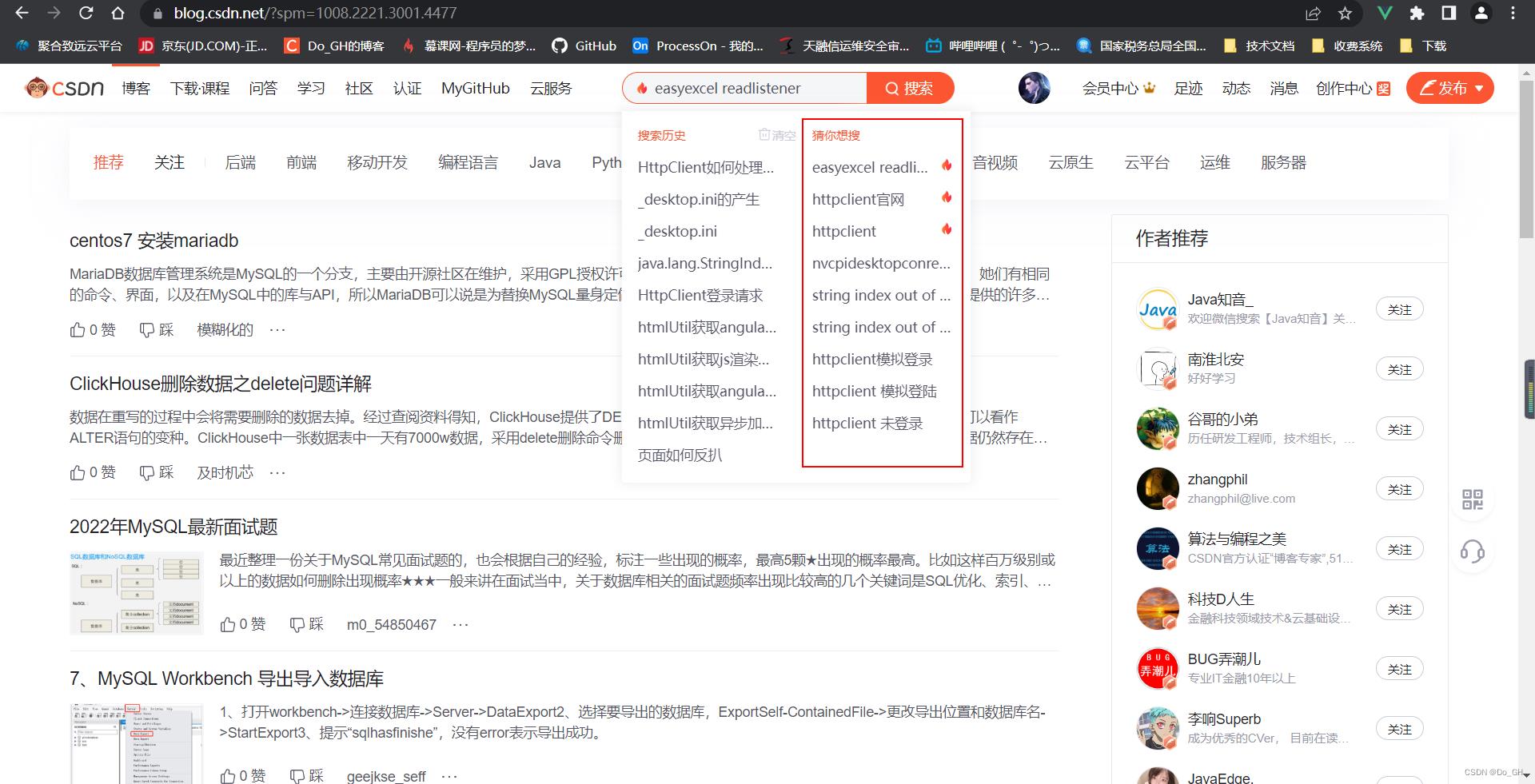
此时我们可以只选择Fetch/XHR查看页面所有调用的接口,从中找到正确的接口。根据实际请求中携带参数和header的信息,编写代码。
@Test
public void testApi()
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet("https://silkroad.csdn.net/api/v2/assemble/list/channel/search_hot_word?new_hot_flag=1&channel_name=pc_hot_word&size=20&user_name=weixin_43347659&platform=pc&imei=10_20960811560-1623721797026-245775");
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36");
httpGet.setHeader("Accept", "application/json, text/javascript, */*; q=0.01");
httpGet.setHeader("Content-Type", "application/json;charset=UTF-8");
httpGet.setHeader("Origin", "https://blog.csdn.net");
httpGet.setHeader("Accept-Encoding", "gzip, deflate, br");
try
CloseableHttpResponse response = httpClient.execute(httpGet);
if (response.getStatusLine().getStatusCode() == 200)
System.out.println(EntityUtils.toString(response.getEntity(), "UTF-8"));
catch (IOException e)
e.printStackTrace();
finally
response.close();
httpClient.close();
一般勾选保留日志和停用缓存已防止页面发生重定向时丢失以前的请求内容。
1.4.2 反爬技术的影响
具体可查看知乎贴做爬虫怎可不知反爬虫?如何做反反爬虫。
1.5 爬取需要登录的页面
当需要获取登录后的页面信息时,就绕不开Cookie的问题。在请求时携带正确的Cookie值可直接跳过登录操作。该问题可通过两种方案解决。
1.5.1 在header中直接携带Cookie
在设置请求头时,可以直接绑定Cookie值,该Cookie值可以通过实际访问时查看请求内容获取,示例:
@Test
public void testCookie() throws Exception
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet("https://mall.csdn.net/myorder?spm=1001.2014.3001.5137");
httpGet.setHeader("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36");
httpGet.setHeader("Cookie", "yourCookie");
CloseableHttpResponse response = httpClient.execute(httpGet);
if (response.getStatusLine().getStatusCode() == 200)
System.out.println("==============================开始打印页面==============================");
System.out.println(EntityUtils.toString(response.getEntity()));
System.out.println("==============================结束打印页面==============================");
httpClient.close();
response.close();
对于携带Cookie的方式登录存在一个问题,就是cookie存在有效期,当有效期过了之后就需要重新更换cookie,所以如果需要持续性的自动爬取数据,就存在很大弊端。
1.5.2 模拟登录自动获取Cookie
在发送请求时可以将登录信息添加到HttpPost中去尝试请求登录,如果登录成功,登录后的Cookie会保留在HttpClient中,再请求其他页面时则会跳过登录。
以CSDN的登录为例,通过F12查找登录接口,根据请求头信息,配置HttpPost
@Test
public void testLogin() throws Exception
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpPost httpPost = new HttpPost("https://passport.csdn.net/v1/register/pc/login/doLogin");
httpPost.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36");
httpPost.setHeader("Accept", "application/json, text/plain, */*");
httpPost.setHeader("Accept-Encoding", "gzip, deflate, br");
httpPost.setHeader("Accept-Language", "zh-CN,zh;q=0.9");
httpPost.setHeader("Content-Type", "application/json;charset=UTF-8");
httpPost.setHeader("Host", "passport.csdn.net");
httpPost.setHeader("Origin", "https://passport.csdn.net");
httpPost.setHeader("Referer", "https://passport.csdn.net/login?code=applets");
// 配置登录参数
List<NameValuePair> pairList = new ArrayList<NameValuePair>();
pairList.add(new BasicNameValuePair("loginType", "1"));
pairList.add(new BasicNameValuePair("pwdOrVerifyCode", "password"));
pairList.add(new BasicNameValuePair("uaToken", ""));
pairList.add(new BasicNameValuePair("userIdentification", "username"));
pairList.add(new BasicNameValuePair("webUmidToken", ""));
httpPost.setEntity(new UrlEncodedFormEntity(pairList, HTTP.UTF_8));
CloseableHttpResponse response = httpClient.execute(httpPost);
if (response.getStatusLine().getStatusCode() == 200)
System.out.println("登录成功");
// 这里要注销请求,否则会影响后续的请求
httpPost.abort();
HttpGet httpGet = new HttpGet("https://mall.csdn.net/myorder?spm=1001.2014.3001.5137");
httpGet.setHeader("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36");
CloseableHttpResponse response1 = httpClient.execute(httpGet);
if (response1.getStatusLine().getStatusCode() == 200)
System.out.println("==============================开始打印页面==============================");
System.out.println(EntityUtils.toString(response1.getEntity()));
System.out.println("==============================结束打印页面==============================");
response1.close();
response.close();
httpClient.close();
该案例为失败案例,由于登录方式多变,可能出现的验证码等人机校验,导致用户登录的难度加大,例如上述案例,直接访问登录接口后,会直接重定向到人机验证界面,导致无法正常登录。有些页面也存在在前端进行密码加密,导致无法获取正确的密码。
因此上述例子只是提供一个思路。
二、HtmlUtil实现JS异步加载页面
2.1 HtmlUtil
htmlunit 是一款开源的java 页面分析工具,读取页面后,可以有效的使用htmlunit分析页面上的内容。项目可以模拟浏览器运行,被誉为java浏览器的开源实现。是一个没有界面的浏览器,运行速度迅速。是junit的扩展之一。
2.2 引入依赖
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>$htmlutil.version</version>
</dependency>
2.3 创建简单的请求操作
2.3.1 创建实例
@Test
public void testLinked()
try (WebClient webClient = new WebClient(BrowserVersion.CHROME))
webClient.getOptions().setThrowExceptionOnScriptError(false);//当JS执行出错的时候是否抛出异常
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);//当HTTP的状态非200时是否抛出异常
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);//是否启用CSS
webClient.getOptions().setJavaScriptEnabled(true); //很重要,启用JS
webClient.setAjaxController(new NicelyResynchronizingAjaxController());//很重要,设置支持AJAX
//开始请求网站
HtmlPage loginPage = webClient.getPage("https://ent.sina.com.cn/film/");
webClient.waitForBackgroundJavaScript(30000);//该方法阻塞线程
System.out.println("=================开始打印页面=================");
System.out.println(loginPage.asXml());
System.out.println("=================结束打印页面=================");
catch (Exception e)
e.printStackTrace();
对webClient的配置很重要,尤其是setAjaxController()方法,使得模拟页面可以支持AJAX异步加载。
对于Vue和AngularJS渲染的页面HtmlUtil在其处理上也不是太好,加载JS也只能加载原始页面中包含的内容,
2.3.2 模拟浏览器操作
HtmlUtil可以创建一个无界面的浏览器,所以可以通过代码对文本框赋值和进行点击操作,完成一些简单的操作。示例:
@Test
public void testSearch()
WebClient webClient = new WebClient(BrowserVersion.CHROME);
// 设置当前的AJAX控制器
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
// 设置CSS支持
webClient.getOptions().setCssEnabled(false);
// 设置JavaScript是否启用
webClient.getOptions().setJavaScriptEnabled(true);
// 设置ActiveX是否启用
webClient.getOptions().setActiveXNative(false);
// 设置访问错误时是否抛出异常
webClient.getOptions().setThrowExceptionOnFailingStatusCode(true);
// 设置JS报错时是否抛出异常
webClient.getOptions().setThrowExceptionOnScriptError(false);
try
HtmlPage htmlPage = webClient.getPage("https://www.csdn.net/");
// 阻塞当前线程,直到指定时间后结束
webClient.waitForBackgroundJavaScript(10*1000);
// 获取搜索框
HtmlInput search = (HtmlInput) htmlPage.getByXPath("//*[@id=\\"toolbar-search-input\\"]").get(0);
search.setAttribute("value", "HtmlUtil用法");
// 点击搜索
HtmlButton button = (HtmlButton) htmlPage.getByXPath("//*[@id=\\"toolbar-search-button\\"]").get(0);
HtmlPage newHtmlPage = button.click();
System.out.println("=============打印页面=============");
System.out.println(newHtmlPage.asXml());
System.out.println("=============打印页面=============");
catch 以上是关于Java使用Java实现爬虫的主要内容,如果未能解决你的问题,请参考以下文章