基于paddlepaddle实现Mobilenet_v3复现
Posted 扬志九洲
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于paddlepaddle实现Mobilenet_v3复现相关的知识,希望对你有一定的参考价值。
基于paddlepaddle实现MobileNets_v1复现
基于paddlepaddle实现Mobilenet_v2复现
文章目录
一、介绍
Mobilenet_v3与Mobile_v2的不同点如下:
对原本的Inverted_residual_block添加了Squeeze-and-Excite结构来提高精度,Inverted_residual_block+Squeeze-and-Excite结构,如图一。
添加h-swish激活函数,提高了准确率,而h-swish和h-sigmoid相比于swish和sigmoid减少了计算量,比较如图二,h-swish计算公式如下:
h-swish[x] = x. R e L U 6 ( x + 3 ) 6 \\fracReLU6(x+3)6 6ReLU6(x+3)
引入了Efficient Last Stage,可以在不损失计算精度的基础上减小计算量,结构如图三。
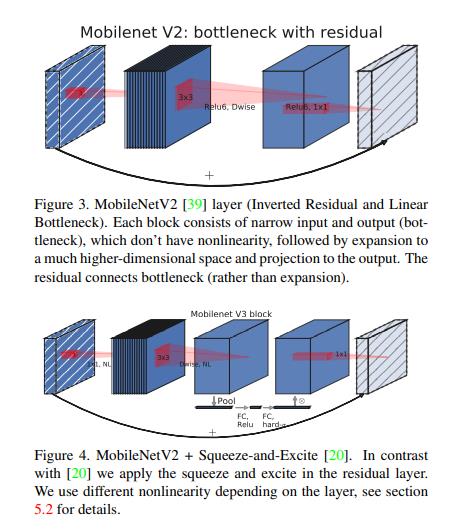
图一

图二

图三
二、整体网络架构
Large网络架构如图

Small网络架构如图

其中,input为进入网络的特征矩阵的大小,Operator含有kernel_size的大小信息。exp_size为在BottleNet模块中增加后的通道数,out为输出通道数,SE为是否有Squeeze-and-Excite结构,NL为激活函数种类,RE为ReLU6,HS为h-swish,s为stride,NBN表示无BatchNorm结构。
三、论文复现
1、导入工具包
import paddle
from paddle.nn import Conv2D, BatchNorm2D, ReLU6, Hardsigmoid, Hardswish, \\
AdaptiveAvgPool2D
import paddle.nn.functional as F
2、建立基础的代码运行块
class ConvBNLayer(paddle.nn.Layer):
def __init__(self, inchannels, outchannels, stride, kernelsize = 3, groups = 1, NL = "RE"):
super(ConvBNLayer, self).__init__()
self.NL = NL
padding = (kernelsize - 1) // 2
self.conv = Conv2D(
in_channels=inchannels,
out_channels=outchannels,
kernel_size=kernelsize,
stride=stride,
padding=padding,
groups=groups
)
self.bn = BatchNorm2D(outchannels)
self.relu = ReLU6()
self.Hsh = Hardswish()
def forward(self, inputs):
x = self.conv(inputs)
x = self.bn(x)
if self.NL == "RE":
x = self.relu(x)
if self.NL == "HS":
x = self.Hsh(x)
return x
3、建立无SE的结构
class Bc_Block(paddle.nn.Layer):
def __init__(self, inchannels, outchannels, kernel_size, exp_size, stride, NL):
super(Bc_Block, self).__init__()
self.stride = stride
self.layer0 = ConvBNLayer(
inchannels=inchannels,
outchannels=exp_size,
kernelsize=1,
stride=1,
NL=NL
)
self.layer1 = ConvBNLayer(
inchannels=exp_size,
outchannels=exp_size,
kernelsize=3,
stride=stride,
groups=exp_size,
NL=NL
)
self.conv0 = Conv2D(
in_channels=exp_size,
out_channels=outchannels,
kernel_size=1
)
self.bn0 = BatchNorm2D(outchannels)
self.conv1 = Conv2D(
in_channels=inchannels,
out_channels=outchannels,
kernel_size=1
)
self.bn1 = BatchNorm2D(outchannels)
def forward(self, inputs):
y = inputs
x = self.layer0(inputs)
x = self.layer1(x)
x = self.conv0(x)
x = self.bn0(x)
if self.stride == 2:
return x
if self.stride == 1:
y = self.conv1(inputs)
y = self.bn1(y)
return x+y
4、建立有SE的结构
class SE_Block(paddle.nn.Layer):
def __init__(self, inchannels, outchannels, kernel_size, exp_size, stride, NL):
super(SE_Block, self).__init__()
self.stride = stride
self.layer0 = ConvBNLayer(
inchannels=inchannels,
outchannels=exp_size,
kernelsize=1,
stride=1,
NL=NL
)
self.layer1 = ConvBNLayer(
inchannels=exp_size,
outchannels=exp_size,
kernelsize=3,
stride=stride,
groups=exp_size,
NL=NL
)
self.pooling = AdaptiveAvgPool2D(output_size=(1, 1))
self.linear0 = Conv2D(in_channels=exp_size, out_channels=int(exp_size*0.25), kernel_size=1)
self.linear1 = Conv2D(in_channels=int(exp_size*0.25), out_channels=exp_size, kernel_size=1)
self.relu = ReLU6()
self.Hs = Hardsigmoid()
self.conv0 = Conv2D(
in_channels=exp_size,
out_channels=outchannels,
kernel_size=1
)
self.bn0 = BatchNorm2D(outchannels)
self.conv1 = Conv2D(
in_channels=inchannels,
out_channels=outchannels,
kernel_size=1
)
self.bn1 = BatchNorm2D(outchannels)
def forward(self, inputs):
y = inputs
x = self.layer0(inputs)
x = self.layer1(x)
z = self.pooling(x)
z = self.linear0(z)
z = self.relu(z)
z = self.linear1(z)
z = self.Hs(z)
x = x*z
x = self.conv0(x)
x = self.bn0(x)
if self.stride == 2:
return x
if self.stride == 1:
y = self.conv1(inputs)
y = self.bn1(y)
return x+y
5、建立分类头
class Classifier_Head(paddle.nn.Layer):
def __init__(self, in_channels, hidden_channel, num_channel):
super(Classifier_Head, self).__init__()
self.pooling = AdaptiveAvgPool2D(output_size=(1, 1))
self.conv0 = Conv2D(
in_channels=in_channels,
out_channels=hidden_channel,
kernel_size=1
)
self.HS = Hardswish()
self.conv1 = Conv2D(
in_channels=hidden_channel,
out_channels=num_channel,
kernel_size=1
)
def forward(self, inputs):
x = self.pooling(inputs)
x = self.conv0(x)
x = self.HS(x)
x = self.conv1(x)
x = paddle.squeeze(x)
x = F.softmax(x)
return x
6、搭建MobileNetV3_Large架构
class MobileNetV3_Large(paddle.nn.Layer):
def __init__(self, num_channel):
super(MobileNetV3_Large, self).__init__()
block_setting=[
[3, 16, 16, False, "HS", 1],
[3, 64, 24, False, "RE", 2],
[3, 72, 24, False, "RE", 1],
[5, 72, 40, True, "RE", 2],
[5, 120, 40, True, "RE", 1],
[5, 120, 40, True, "RE", 1],
[3, 240, 80, False, "HS", 2],
[3, 200, 80, False, "HS", 1],
[3, 184, 80, False, "HS", 1],
[3, 184, 80, False, "HS", 1],
[3, 480, 112, True, "HS", 1],
[3, 672, 112, True, "HS", 1],
[5, 672, 160, True, "HS", 2],
[5, 960, 160, True, "HS", 1],
[2, 960, 160, True, "HS", 1]
]
self.feature = [
ConvBNLayer(
inchannels=3,
outchannels=16,
kernelsize=3,
stride=2,
NL="HS"
)
]
inchannels = 16
for k, exp_size, out, SE, NL, s in block_setting:
if SE:
self.feature.append(
SE_Block(
inchannels=inchannels,
outchannels=out,
kernel_size=k,
exp_size=exp_size,
stride=s,
NL=NL
)
)
inchannels=out
else:
self.feature.append(
Bc_Block(
inchannels=inchannels,
outchannels=out,
kernel_size=k,
exp_size=exp_size,
stride=s,
NL=NL
)
)
inchannels=out
self.feature.append(
ConvBNLayer(
inchannels=160,
outchannels=960,
kernelsize=1,
stride=1,
NL="HS"
)
)
self.head = Classifier_Head(
in_channels=960,
hidden_channel=1280,
num_channel=num_channel
)
def forward(self, x):
for layer in self.feature:
x = layer(x)
x = self.head(x)
return x
7、搭建MobileNetV3_Small架构
class MobileNetV3_Small(paddle.nn.Layer):
def __init__(self, num_channel):
super(MobileNetV3_Small, self).__init__()
block_setting=[
[3, 16, 16, True, "RE", 2],
[3, 72, 24, False, "RE", 2],
[3, 88, 24, False, "RE",1],
[5, 96, 40, True, "HS", 2],
[5, 240, 40, True, "HS", 1],
[5, 240, 40, True, "HS", 1],
[5, 120, 48, True, "HS", 1],
[5, 144, 48, True, "HS", 1],
[5, 288, 96, True, "HS", 2],
[5, 576, 96, True, "HS", 1],
[5, 576, 96, True, "HS", 1]
]
self.feature = [
ConvBNLayer(
inchannels=3,
outchannels=16,
kernelsize=3,
stride=2,
NL="HS"
)
]
inchannels = 16
for k, exp_size, out, SE, NL, s in block_setting:
if SE:
self.feature.append(
SE_Block(
inchannels=inchannels,
outchannels=out,
kernel_size=k,
exp_size=exp_size,
stride=s,
NL=NL
)
)
inchannels=out
else:
self.feature.append(
Bc_Block(
inchannels=inchannels,
outchannels=out,
kernel_size=k,
exp_size=exp_size,
stride=s,
NL=NL
)
)
inchannels=out
self.feature.append(
ConvBNLayer(
inchannels=96,
outchannels=576,
kernelsize=1,
stride=1,
NL="HS"
)
)
self.head = Classifier_Head(
in_channels=576,
hidden_channel=1024,
num_channel=num_channel
)
def forward(self, x):
for layer in self.feature:
x = layer(x)
x = self.head(x)
return x
四、查看网络结构
model = MobileNetV3_Small(num_channel=1000)
paddle.summary(model, (1, 3, 224, 224))
model = MobileNetV3_Large(num_channel=1000)
paddle.summary(model, (1, 3, 224, 224))
以上是关于基于paddlepaddle实现Mobilenet_v3复现的主要内容,如果未能解决你的问题,请参考以下文章