Mac M1芯片本地安装 hadoop 集群填坑之路
Posted 喵王叭
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mac M1芯片本地安装 hadoop 集群填坑之路相关的知识,希望对你有一定的参考价值。
文章目录
背景
学习一项技能的最好方式自然是理解+实践,在了解了 hadoop 的基本概念后我开始尝试在本地搭建一个集群环境用于进一步学习。
但是经过尝试后发现想在 MacOS 中搭建一个集群比我想象中困难得多,其中也有一部分原因是我对 macOS 系统不太熟悉,可谓是一坑未填一坑又起了。经过不懈努力终于搭建了一个基于 docker 的 hadoop 集群,故有此一文作记录和分享~
环境
macOS (version: 12.3, chip: Apple M1 Pro, memory: 16GB)
colima 0.4.5
docker 20.10.18
前置知识
这里简单介绍下 hadoop 的一些基本概念。
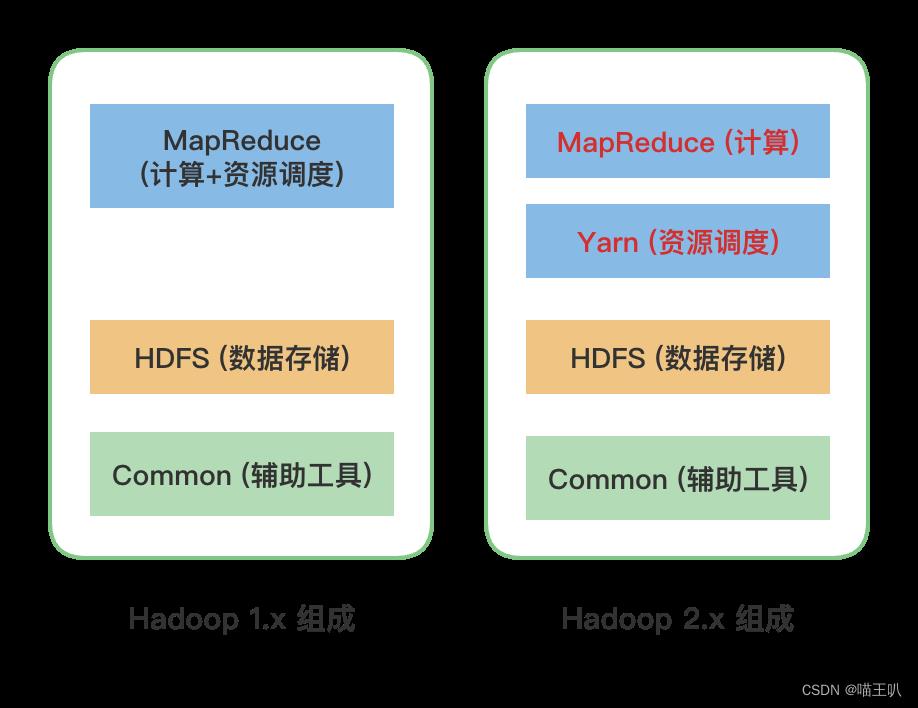
hadoop 的基本组成为 MapReduce、Yarn、HDFS 等组件。
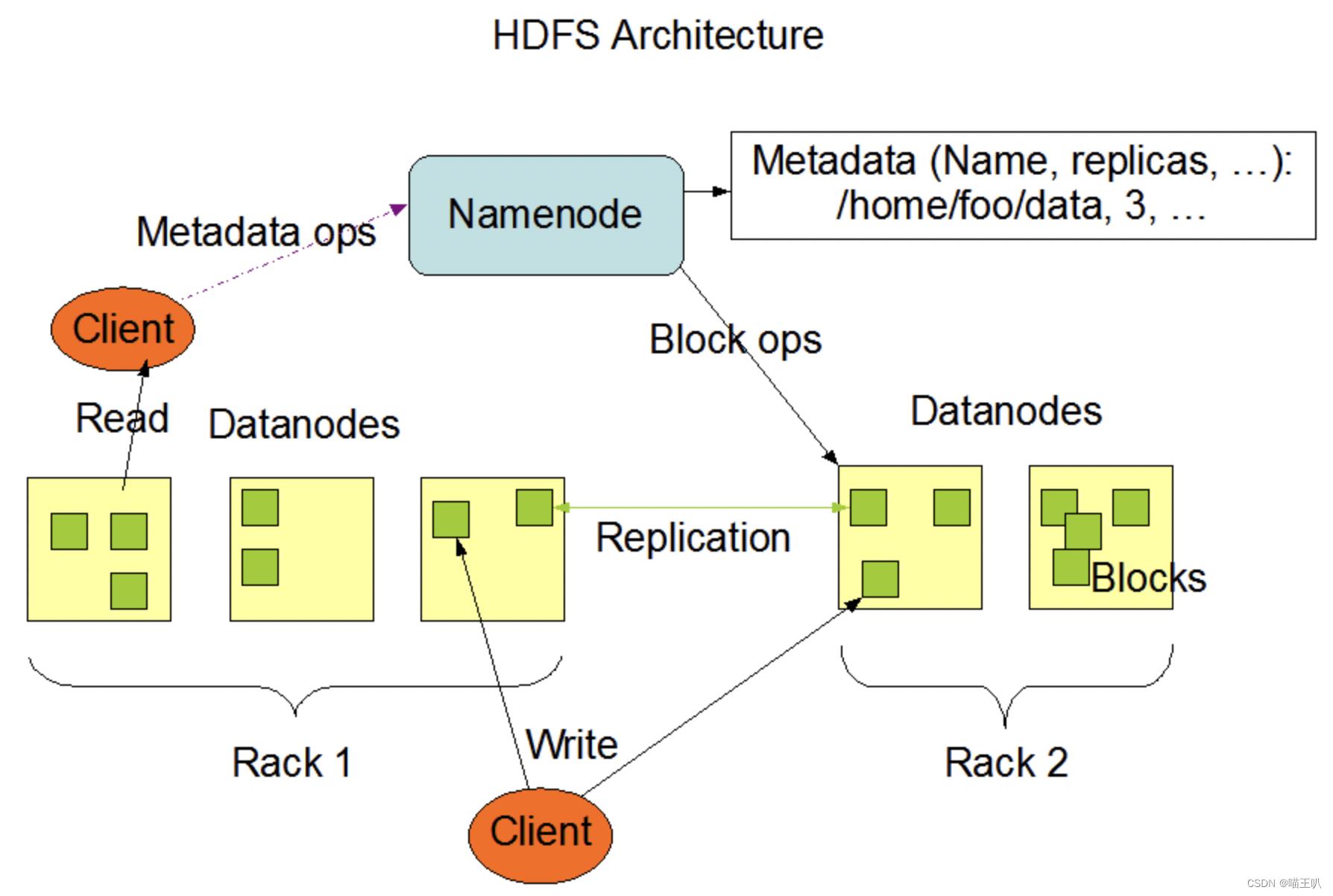
其中 HDFS 是一种分布式的文件系统,它的主要组成是 NameNode、SecondaryNameNode 和 Datanode 等。
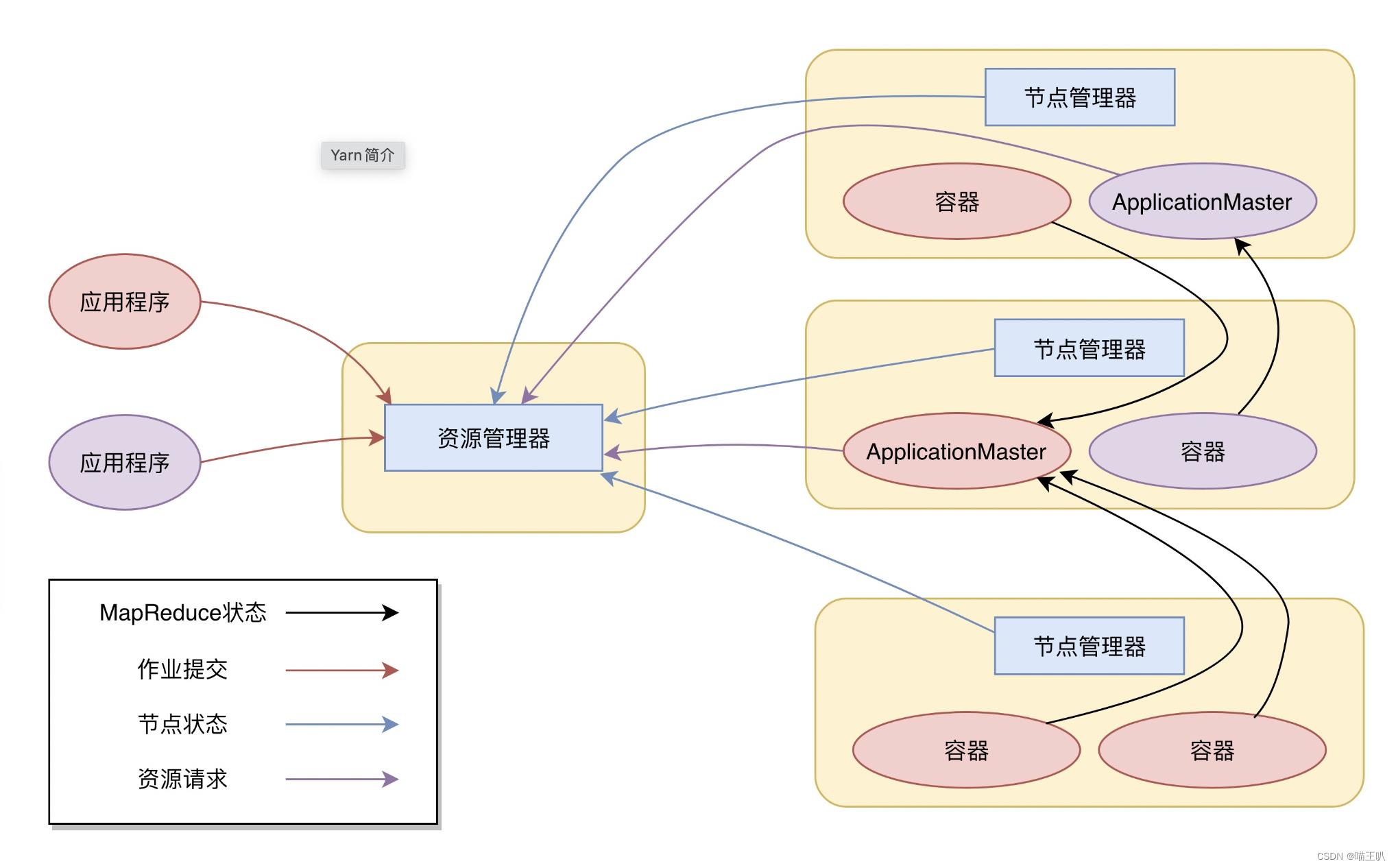
而 Yarn 是 hadoop 在 2.x 版本后设计的分布式资源调度工具,其主要组成为 NodeManager 和 ResourceManager 等。
更详细的基础知识可以参考我的博客笔记:
https://blog.csdn.net/weixin_40815218/article/details/126838369
安装过程
一般情况下,搭建一个高可用的 hadoop 集群通常是选择两台以上的物理服务器来运行不同的节点。本文的目的是搭建一个用于学习的集群,可以先不考虑 HA,而据我了解,将一台机器用作多个服务器的方法一般有虚拟机方式和 docker 容器方式两种。
相比于搭建虚拟机,我更倾向于选择后者,因为虚拟机的安装和配置更加复杂,对资源消耗也更大。同时因为之前参加 twu 也已经安装好了 colima 虚拟环境下的docker,就愉快地决定用docker开始搭建了。
搭建集群的第一步是先搭建一个单机的伪分布式集群,验证环境的可用性。
#bug1
这里开始了第一个坑:
由于过于信任 docker 的平台无关性,我先搜索了"docker 安装 hadoop3.x",忽略了macOS m1芯片aarch64架构的特性,并根据社区中教程文章开始操作。
首先拉取了一个centos镜像,docker run 运行镜像后,docker exec 进入容器,安装配置了 jdk1.8、openssh、hadoop后 docker commit 保存镜像,发现如下报错:
The requested image's platform (linux/amd64) does not match the detected host platform (linux/arm64/v8) and no specific platform was requested
无奈得知想要重复使用一个镜像的话需要保证芯片架构的一致性。于是重新寻找适用于aarch64的镜像,最后找到一篇博文讲到这方面问题:
https://blog.csdn.net/LiuWH1688/article/details/120608075
这篇博客中的项目对MacOS M1芯片、arm64架构等做了适配。
项目地址:https://github.com/Weihong-Liu/hadoop-docker/blob/main/hadoop-docker-aarch64
第一个坑结束。
#bug2
高兴地 clone 了项目开始实践,参详其 Dockerfile,作者使用 ubuntu 作为系统镜像,分别安装适用的 hadoop 和 jdk1.8 的 aarch版本,还预装了openssh,同时载入了外部配置文件并配置了各种环境变量,准备工作可以说相当全面。
我充满信心地使用 docker build 运行 Dockerfile 文件生成 hadoop 节点镜像,最后自动生成了三个节点容器并进入了 master 节点容器。一切都很完美直到我运行 start-all.sh 启动了集群,这里遇到第二个大坑:
运行没有报任何异常,但是 jps 查看进程后发现 namenode 节点不能正常启动,这时就想到查看 logs 日志,观察发现 hadoop 日志没有错误信息,然后想看下系统日志 /var/log/message 发现日志文件都没有~
百思不得其解后向原项目提交了一个 issue 寻求帮助,作者回复已做修复后我查看修改记录发现作者将 resourcemanager 的地址中 master 节点修改为了 slave2 节点,这样做的动机是防止 docker 单个容器的内存占用过高导致节点挂掉。于是我获得了灵感,觉得这可能是因为内存不足导致的,但同时也疑惑为什么没有生成 记录 oom 的 heapdump 文件。这里我就使用 yarn --daemon start 和 hdfs --daemon start 尝试单独启动指定节点,发现现象是启动了 master 的 namenode,slave2 的 resourcemanager 就会 down 掉,再尝试启动 resourcemanager,namenode 又会 down 掉。这也更加证实了我的猜想没错。
首先我尝试 docker -m p1 --memory-swap p2 指定 docker 的内存资源分配,发现没有效果。然后意识到当前环境下 docker 的各个容器之间共享内存资源,而现在 docker 的总内存资源只有 2G,这才是问题所在。
于是把问题视角上升到 docker 的父容器 colima,通过查阅资料得知 colima 也可以通过简单配置 colima --cpu p1 --memory p2 start 来分配内存资源。重启 colima 时发现如下输出:
Reducing the guest memory from 4GiB to 3GiB, to avoid host kernel panic on macOS <= 12.3 with QEMU >= 7.0; Please update macOS to 12.4 or later, or downgrade QEMU to 6.2; See https://github.com/lima-vm/lima/issues/795 for the further background
于是无奈地顺便升级了macOS系统版本到12.6,重启 colima 后再次进入 docker 容器发现内存确实提高到了指定的 4G 内存。这时重新启动了 hadoop 集群,所有节点运行正常。
#bug3
这时我想要在 mac 的浏览器访问 localhost:9870 查看 hdfs 系统 和 localhost:8088/cluster 查看 cluster 节点信息。
无奈发现 404 not found。经过一番查阅资料,得知 mac 环境不会自动创建 docker 网卡 用于与 docker 容器通信。
参考文章:https://blog.csdn.net/qq_35371031/article/details/104601403
文章提供了解决问题的三种方法:
1. 使用 vpn 代理
2. host 模式代替 bridge 模式
3. 端口映射
其中替换为 host 模式的方法在不同容器之间会有端口冲突;
而端口映射方法需要指定端口而不是IP,不够灵活,具体参考文章:
http://t.zoukankan.com/EasonJim-p-7819478.html
最终采用了 vpn 代理方法,具体参考文章:
https://blog.csdn.net/tqtaylor/article/details/119799526
注意,可能是因为系统差异,文章中所用的配置文件地址(/usr/local/etc/docker-connector.conf)不正确,参考原始项目后得知应该改为 $(brew --prefix)/etc/docker-connector.conf
经过一番尝试,终于可以在浏览器访问 hdfs 和 cluster 啦!!
以上是关于Mac M1芯片本地安装 hadoop 集群填坑之路的主要内容,如果未能解决你的问题,请参考以下文章