Mysql相关知识点汇总
Posted every__day
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql相关知识点汇总相关的知识,希望对你有一定的参考价值。
mysql 相关知识点
提示:本文是学习 丁奇老师《Mysql实战 45 讲》的个人总结
文章目录
前言
将 MySql 学习的相关内容形成若干篇文章,以加深印象
一、日志相关
1.查询的流程
连接器、分析器、优化器、执行器
2. WAL 技术
Write-Ahead-Logging 先写日志,后写磁盘。(日志是顺序写,速度快,磁盘是随机写,速度慢)
当需要更新一条记录时,InnoDB 引擎会把记录写到 redo log 里,再更新内存。这时更新操作就结束了。
通常在后台不忙的时候,InnoDB 引擎会把这个操作记录,写到磁盘上。
redo logg 用于保证 crash-safe ,数据库异常重启后,数据不丢失。
innodb _flush_log_at_trx_commit 设置为1,表示每次事务的 redo_log都直接持久化到磁盘。
INSERT INTO T (id, k) VALUES(id1,k1),(id2,k2)
假设 k1 所在的数据页在内存中,k2 的不在内存中
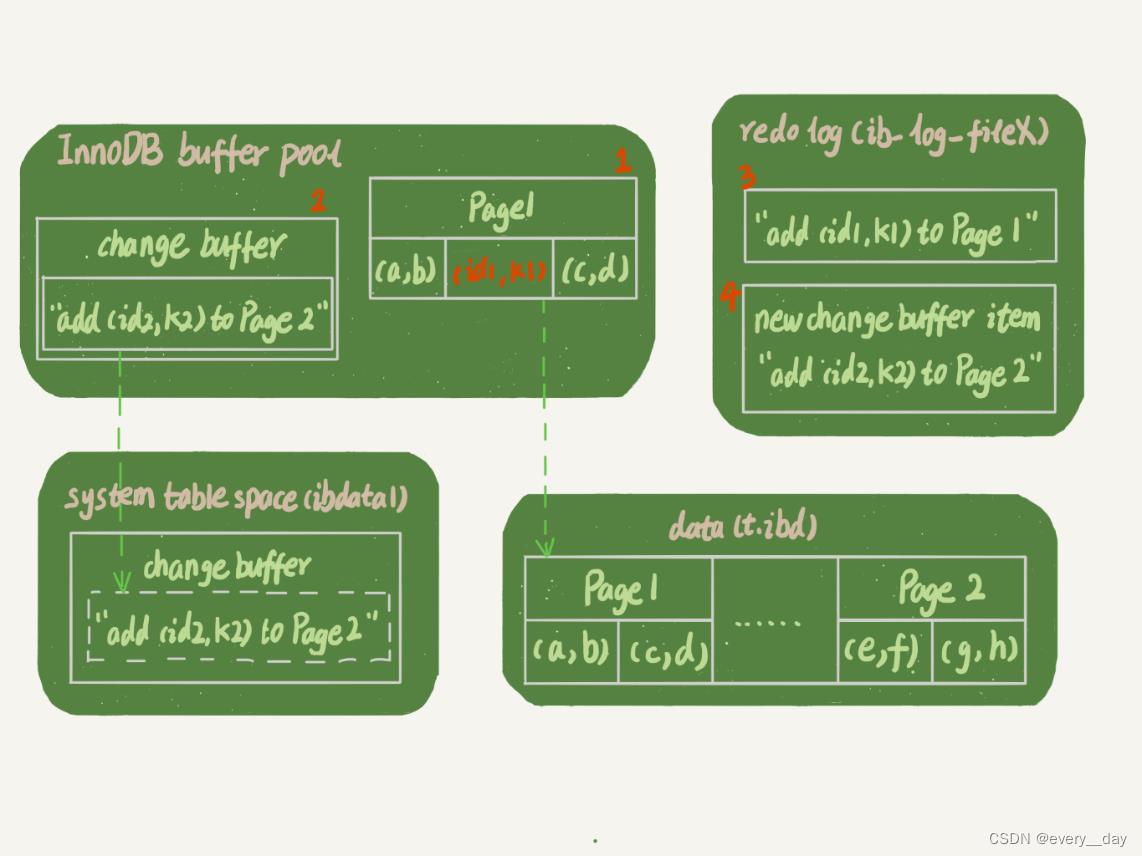
更新语句做如下操作
- Page1 在内存中,直接更新
- Page2 不在内存中,在 change buffer 中记录下,要往 Page2中插入一条数据
- 将上面两步的内容,记录到 redo log (图中 3 和 4 )
做了这些,事务就结束了,成本很低,写了两次内存,之后写了一次磁盘,且是顺序写。图中的箭头是后台操作,不影响更新时间。
如果随后执行查询操作
SELECT * FROM T WHERE k IN (k1, k2);
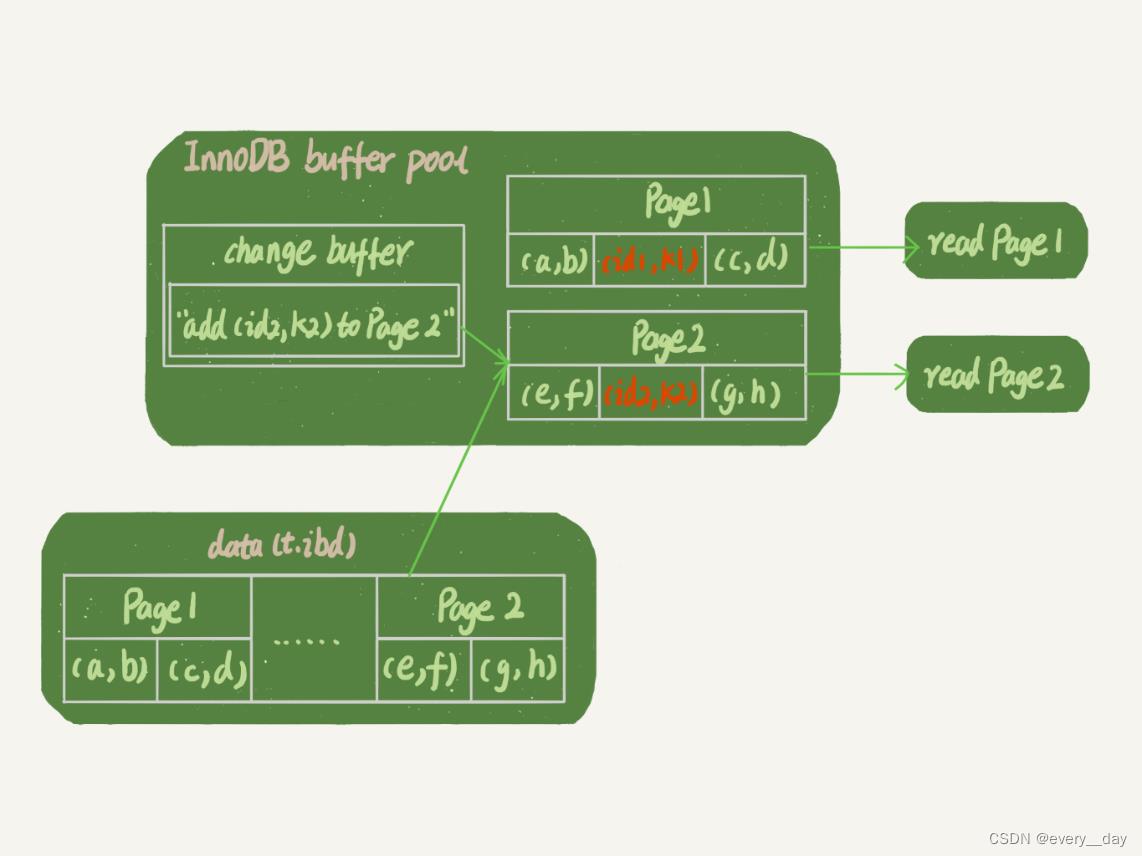
Page1在内存中,直接读取即可,
Page2 从磁盘读取,结合 change buffer,在内存中生成正确数据。
redo log主要节省的是,随机写磁盘的IO消耗(转为顺序写)。change buffer主要节省的是,随机读磁盘的IO消耗。
3. binlog 与两阶段提交
更新一条数据,大概流程
- 内存中找到这行数据,不存在就加载,
- 写入新行,更新内存
- 写入 redo log,状态为 prepare
- 写入 binlog
- 更新 redo log 状态为 commit
sync_binlog 设置为1,表示每次事务的binlog都写入磁盘,保证数据库异常重启时,binlog不丢失
4. 刷脏页(flush)
当内存中数据页跟磁盘上数据页内容不一致时,这个内存页叫**“脏页**”。
什么情况下会刷脏页:
- redo log 要写满了。
- 系统内存不足,需要淘汰一些数据页,这些数据页若是脏页,要 flush。
- Mysql 认为系统空闲的时候。
- Mysql 正常关闭时。
刷脏页是常态,但要刷的脏页太多,或是日志写满时,都会明显影响性能。
innodb_io_capacity 建议设置为磁盘的 IOPS。
如果一个查询,需要在执行过程中先 flush 掉一个脏页,这个查询就比平时慢了。如果这个脏页相邻的数据页,也是脏页,就连带着一起刷掉,那该查询就会更慢。 innodb_flush_neighbors 为 1 ,有连带机制, 为 0 禁止连带机制。
二、隔离相关
1.隔离级别
read uncommittedread committedrepleatable readserializable
读已提交 和 可重复读 逻辑类似,主要区别:
- 可重复读的隔离级别下,事务开始的时候,创建一致性视图,事务中的语句共用这一个视图。
- 读已提交隔离级别下,每个语句执行前,都会算出一个新的视图。
2.MVCC
InnoDB 中的每个事务,都有一个事务ID,叫 transaction id,它是在事务开始时,向 InnoDB 申请的,按申请顺序严格递增的。
每行数据也有多个版本,每次事务更新行数据时,会生成一个新的数据版本,并把 transaction id 赋值给这个新版本的数据,记作 row_trx_id。 undo log 可以实现不同数据版本的追溯。
对于一个事务版本来说,除了自己更新总是可见外,有三种情况
- 版本未提交,不可见。
- 版本已提交,且在视图创建前提交的,可见。
- 版本已提交,但在视图创建后提交的,不可见。
在可重复读的场景下:
- 读值的逻辑
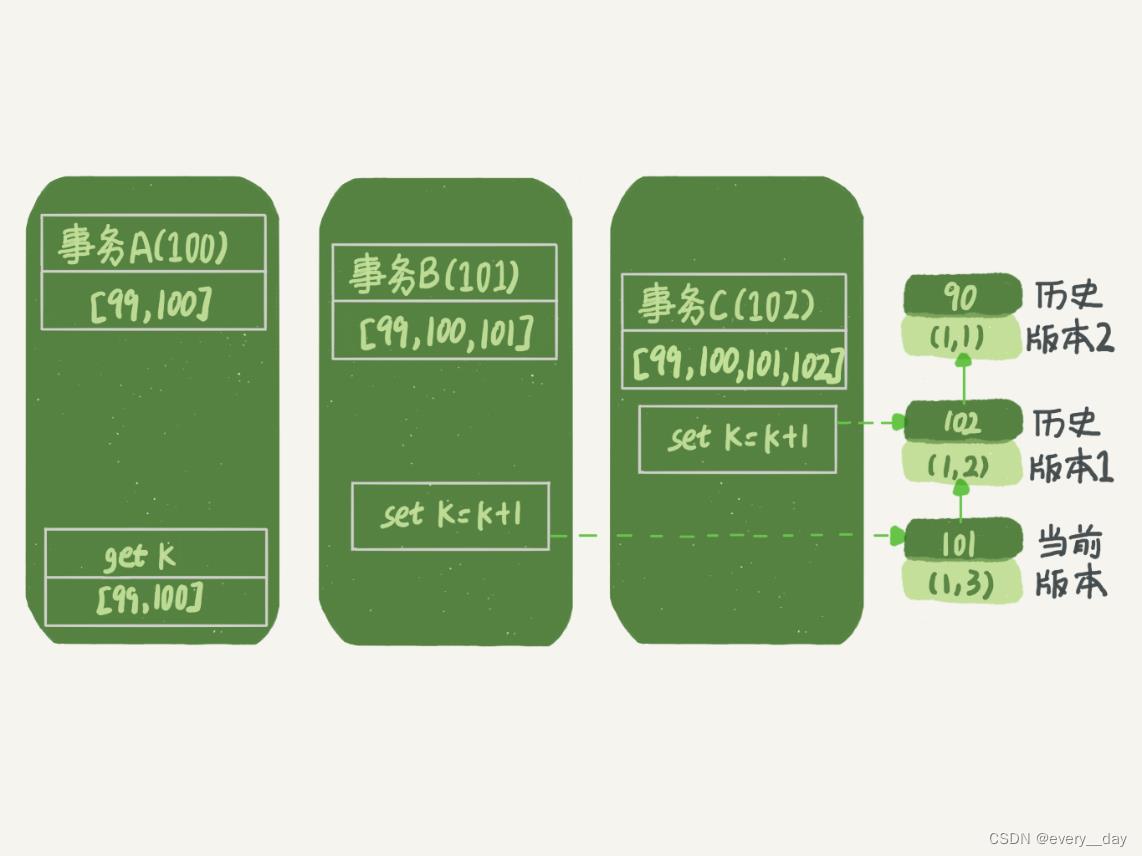
事务A,高水位是100,读取 k 的值时,当前版本 101,大于其最高水位,回溯到上一个版本,
版本为102,大于其最高水位,再回溯到上个版本,版本号为90,小于最高水位,读该值。
- 更新的逻辑
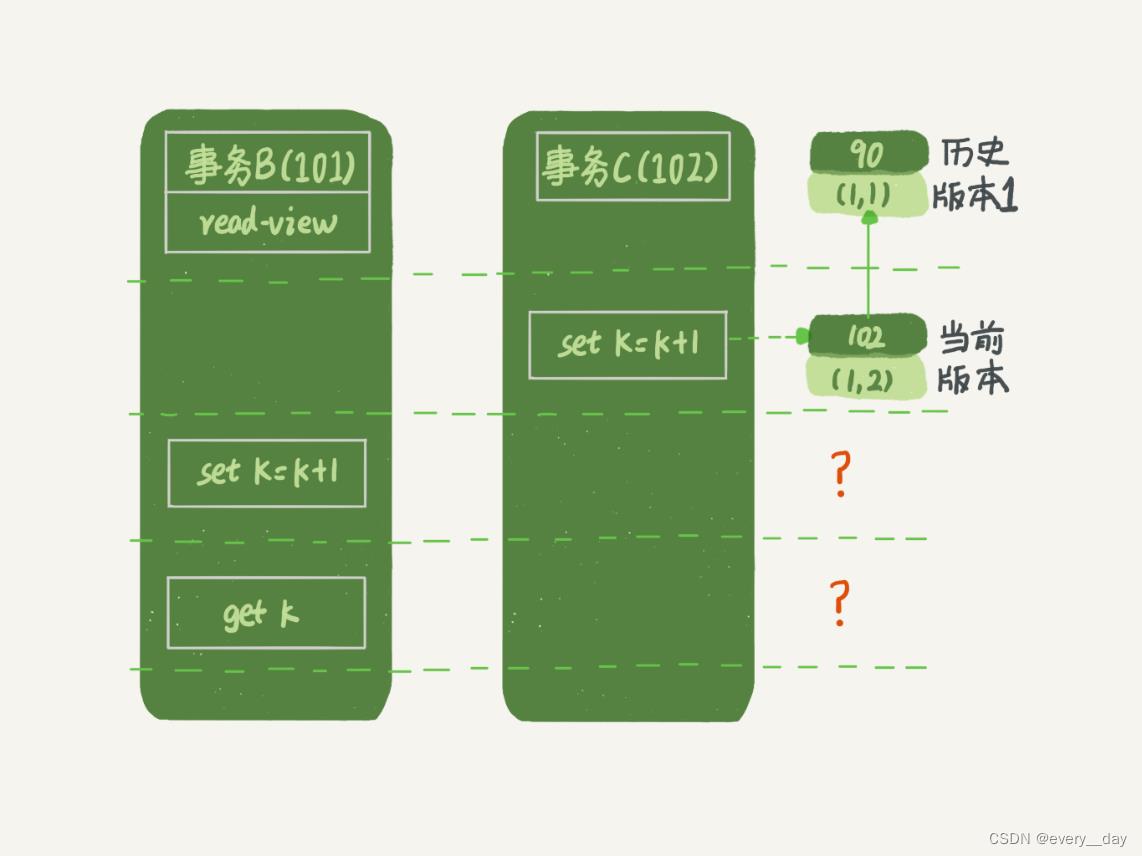
更新数据都是先读后写,而这个读,只能读当前值——当前读 current read。
事务B中 set 语句时,先是当前读,k 值 为2(如果事务C没有提交,阻塞),再赋值,k 值为3,同时生成新的数据版本,row_trx_id 为 101。 之后 B 事务中 get 判断版本号是 101,与自身版本号相同,可见。
select 语句加锁也是当前读。
SELECT * FROM TABLE WHERE ID = 1 LOCK IN SHARE MODE -- 共享锁
SELECT * FROM TABLE WHERE ID = 1 FOR UPDATE -- 排它锁
特别说明: C事务如果没有提交,根据两阶段锁协议,C 事务会占着锁,B 事务的当前读就会阻塞,直到C事务提交,释放了锁,B 事务继续执行。
可重复读的核心是一致性读(consistent read),事务更新数据时,一定是当前读,即一定要拿到锁。当该行的行锁被其它事务占用时,需要进入锁等待。
在读已提交模式下:
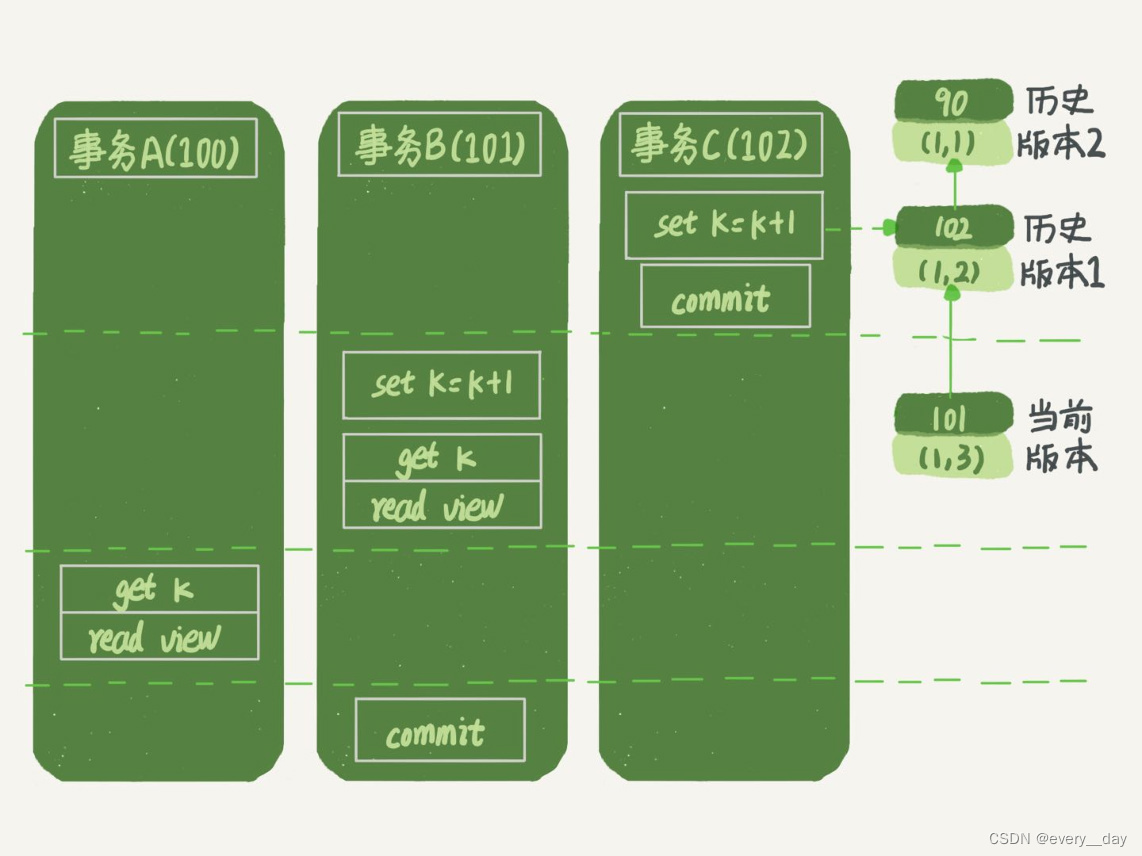
A 事务读到的 k 值是2,B 事务的修改对 A 不可见,因为 创建视图前没有提交。
总结:
- InnoDB 的行数据有多个版本,每个版本有自己的 row_trx_id。
- 每个事务或语句有自己的一致性视图。
- 普通查询是一致性读,根据 row_trx_id 和 一致性视图,确认版本可见性。
- 当前读,必需拿到锁才会执行,读当已提交完成的最新版本。拿不到锁就阻塞。
- 可重复读,查询只承认事务启动前就已提交完成的数据。
- 读已提交,查询只承认语句执行前就已提交完成的数据。
3.幻读
repleatable read 可重复读,在这个隔离级别下,说说幻读的问题。
幻读在当前读时才会出现,幻读专指插入新行。
为解决幻读问题,InnoDB 引入了间隙锁(Gap Lock),
间隙锁的引入,虽然解决了幻读的问题,可容易引起死锁,影响并发度。
简单的处理方法,就是把数据库的隔离级别设置为:读提交,且把 binglog 格式设置为 row。
(读提交级别,会有数据与日志不一致的问题,binlog 设置为 row,可避免这个问题。)
间隙锁与间隙锁之间,不会有锁冲突。
读已提交 和 可重复读 逻辑类似,主要区别:
- 可重复读的隔离级别下,事务开始的时候,创建一致性视图,事务中的语句共用这一个视图。
- 读已提交隔离级别下,每个语句执行前,都会算出一个新的视图。
三、索引相关
1.常用索引模型
- .哈希表: 适用于等值查询的场景,范围查询就需要全量扫描。
- 有序数组:等值查询和范围查询非常优秀,插入数据时,成本很高。
- 搜索树:读写性能都比较好,O(log(N))
2.InnoDB 索引
B+树,叶子结点存储数据,其它节点存id。
回表:在非主键索引上找到主键ID,以此ID在主键索引上再查找数据,叫回表。
覆盖索引:在非主键索引上查询时,需要的字体,该索引上本来就有,不需要回表。
最左前缀:指建立联合索引时,索引字段是有顺序的。where 条件命中最左侧的一个或N个字段,就可以命中索引。
索引下推:使用到联合索引时,where条件中的字段,在该索引中,就不需要回表,直接用索引里的字段值,做相应判断,叫索引下推。
3.chang buffer
当需要更新一个数据页时,若数据页在内存里,直接更新即可。如果不在内存里,在不影响数据一致性的前提下, InnoDB 会将更新缓存在 change buffer 中,就不需要从磁盘中读取这个数据页了。访问这个数据页会触发merger操作,后台线程也会定期merge,关闭数据库时,也会merge.
如果能将更新先记录到 change buffer,减少随机读取磁盘,可以提升性能。而且,数据读入内存,需要占用 buffer pool,所以这种方式还可以避免占用内存,提高内存使用率。
比如插入一条数据时,目标数据页不在内存中,普通索引可以使用 change buffer,不用读磁盘。唯一性索引不能,因其必需判断索引的唯一性,要读磁盘,将数据页读入内存。
对于写多读少的业务场景,change buffer + 普通索引,可提高性能。
反之,如果一个业务写入后要立马读取,会触发 merge,且要访问磁盘,不会提高性能。
4.merge 操作的流程
- 从磁盘读入数据页到内存(老版本的数据页)
- 从change buffer 找出该数据库的 change buffer 记录(可能有多条),依次应用,得到新的数据页
- 写 redo log, 包括数据页的变更和 change buffer 的变更
至此 merge 操作结束,此时数据库和 chang buffer对应的磁盘位置都未修改,属于脏页。刷脏页属于另外一个过程了。
5.mysql 选错索引
优化器会选择索引,会考虑多个方面,如扫描行数据、是否使用临时表、是否排序等因素。
扫描行数的判断,Mysql 执行查询前,是通过索引的区分度来估计扫描行数的。
mysql 统计信息不准,可以用 analyze table 来修正
选错索引的处理方法:
- 强制选定一个索引,force index
- 新建一个合适的索引,或是删除错误的索引
- 修改sql 语句,如 order by a limit 1 改成 order by a,b limit 1 (文章中的例子,这里不写上下文了)
四、锁相关
1.全局锁 FTWRL
Flush tables with read lock,该命令全使整库处于只读状态。
典型使用场景:整库进行逻辑备份
2.表级锁
表锁 和 元数据锁 MDL
表锁的例子 lock tables t1 read, t2 write
MDL(metadata lock)
读锁与读锁,不互斥
读锁与写锁,写锁与写锁之间,互斥
事务中的MDL锁,在语句执行时,开始申请,事务提交时,才会释放。
如何安全的给一个小表加字段?
小表也可能是热点表,加字段时要申请MDL写锁,没查没拿到,会阻塞,后继这个表读写操作都会被阻塞。
比较安全的做法是,申请MDL锁时,设置等待时间,如果没拿到,就放弃,不阻塞后继其它线程的读写操作。
ALTER TABLE tbl_name NOWAIT add column …
ALTER TABLE tbl_name WAIT N add column …
命令 show processlist ,若 出现 Waiting for table metadata lock,
即表示 有线程 请求可持有 MDL 锁,其它线程会被阻塞。
3.行锁
两阶段锁:InnoDB事务中,行锁是在需要的时候加上,在事务提交时释放。并不是在不需要时释放。
所以在事务中要锁多个行,把最可能造成冲突的,最影响并发的放在最后。
出现死锁有两种处理策略:
- 直接进入等待,直到超时, innodb_lock_wait_timeout 来设置超时时间。
- 发起死锁检测,发现死锁后,主动回滚其中的一个事务。 innodb_deadlock_detect 设置为 on
4.next-key lock
一个间隙锁 + 行锁 构成所谓的 next-key lock,其为前开后闭区间。
(间隙锁是可重复读级别下才有效,本段内容默认在可重复读的级别下)
加锁规则,有人总结为两个原则,两个优化,还有一个 bug
- 原则1:加锁的基本单位是 next-key,(前开后闭区间)。
- 原则2:查找过程中,访问到的对象才会加锁。
- 优化1:索引上的等值查询,给唯一索引加锁时,next-key 会退化为行锁
- 优化2:索引上的等值查询,向右遍历且最后一个不满足条件时,next-key 会退化为间隙锁。
- 一个bug:唯一索引的范围查找,访问到不满足条件的第一个数据为止。
以这个建表语句为例
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);
案例1:等值查询间隙锁

- 根据原则1,加锁单位是 next-key,sessionA 加锁范围是 (5, 10];
- 同时根据优化2,索引上的等值查询,最后一个退化为间隙锁,得到最终加锁范围 (5, 10)
案例2:非唯一索引等值锁

- 非唯一索引,访问 c=5 这行后,会再访问 c = 10 才会停止,(0, 5], (5, 10],都会加锁
- 根据优化2,最后一个退化为间隙锁,最终加锁范围是 (0, 10)
- 上面两条并没有在 主键索引上访问,根据原则2,仅在非唯一索引上加锁, session B 访问的是主键索引,所以没有被阻塞
额外说明下,若是 用 for update ,系统会认为之后有更新操作,会给主键索引上加锁
案例3:主键索引范围锁

- session A 访问 id = 10时,最终退化为 行锁,即给 id = 10 这条数据加锁
- 范围查询,继续访问到 id = 15,不符合条件,next-key 加锁 (10, 15]
注意 sission A 访问 id = 10时,是等值判断,访问 id = 15 时,是范围判断。
案例4:非唯一索引范围锁
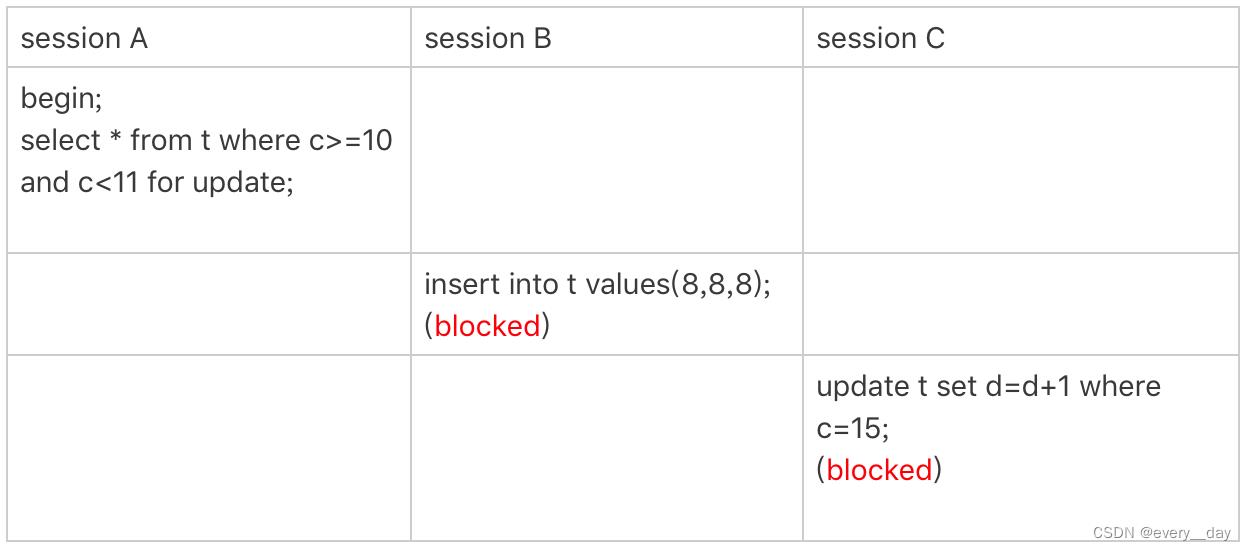
- session A 访问 c = 10 时,加锁范围是 (5, 10],唯一索引时,会退化为行锁,c 不是唯一索引
- 范围查找,访问 c = 15 时,才会停止访问,对 (10, 15] 加锁,范围查找,没有优化,最终加锁范围是 (5, 15 ]
案例5:唯一索引范围锁 bug
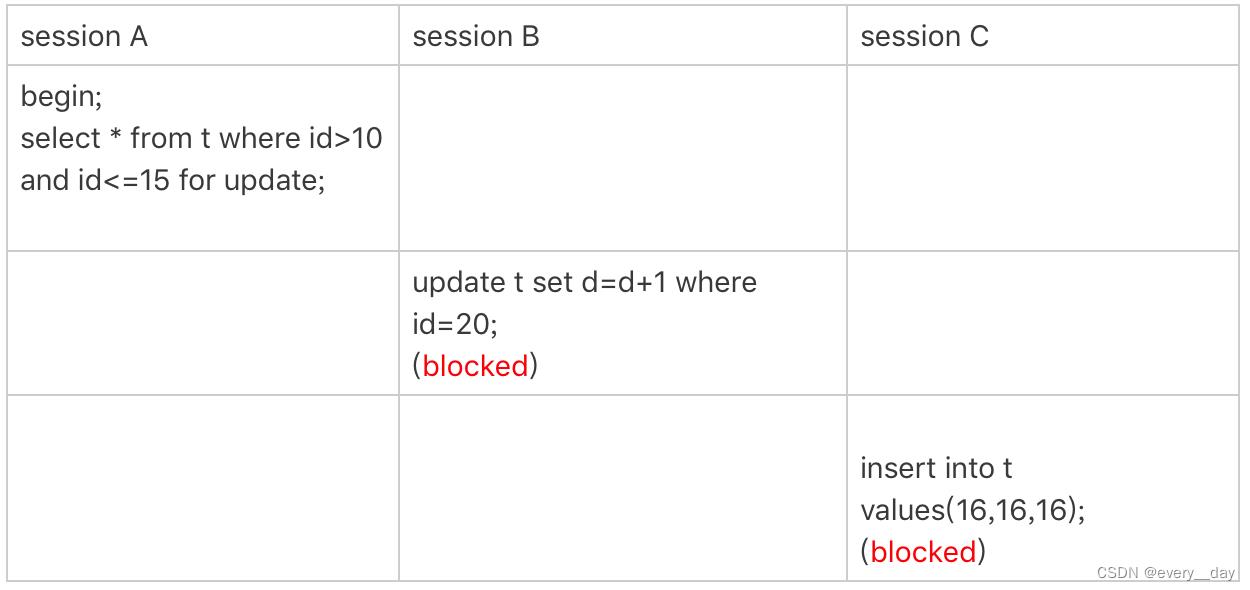
- 按原则1,在主键索引上,查到 id = 15 就该停止了,加锁范围是 (10, 15]
但 InnoDB 实现上,继续又往右扫描了一行,(15, 20] 这个范围也给锁住了。
算是 bug 么?官方没有修正它。
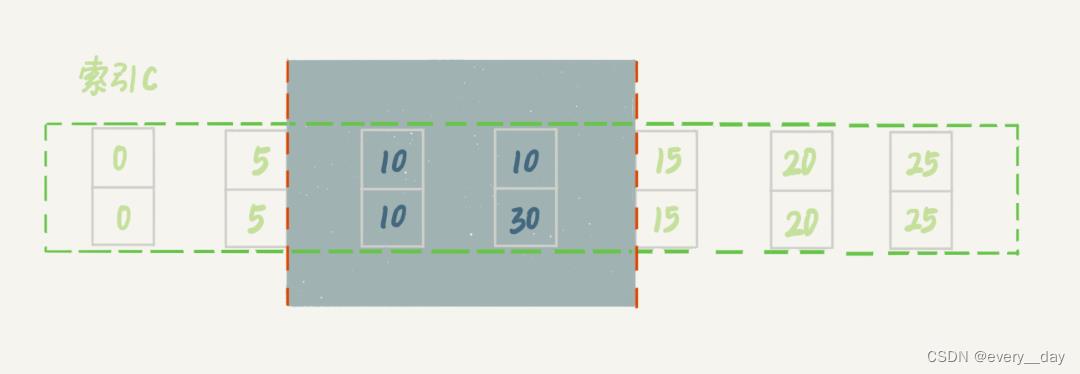
案例6:非唯一索引上,存在等值
加一条数据,此时 c = 10 就有两条数据
mysql> insert into t values(30,10,30);
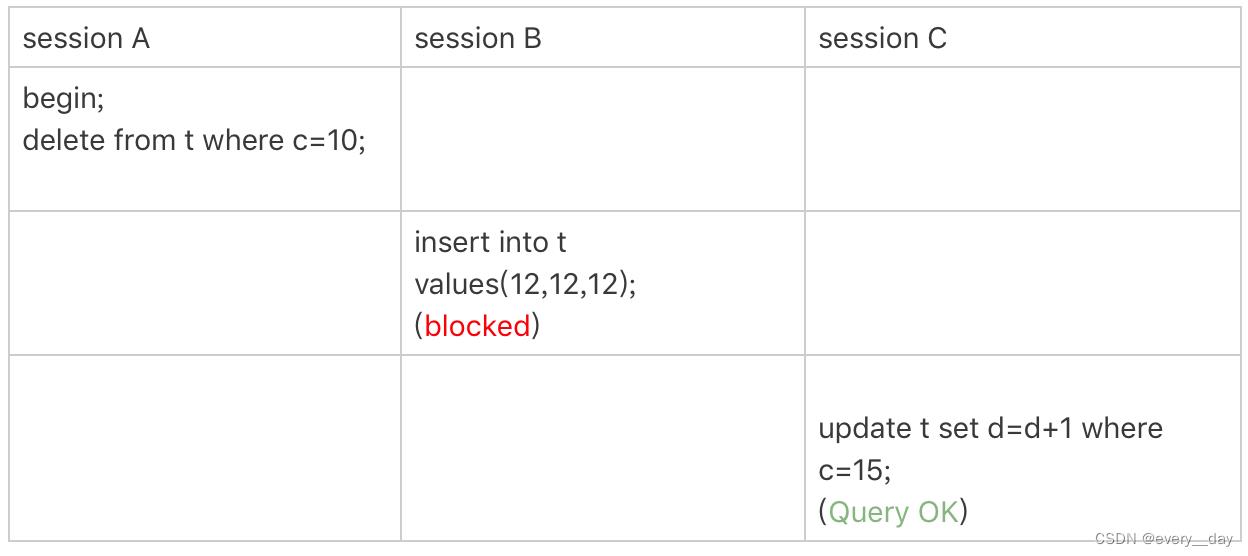
索引c 上加锁范围如下
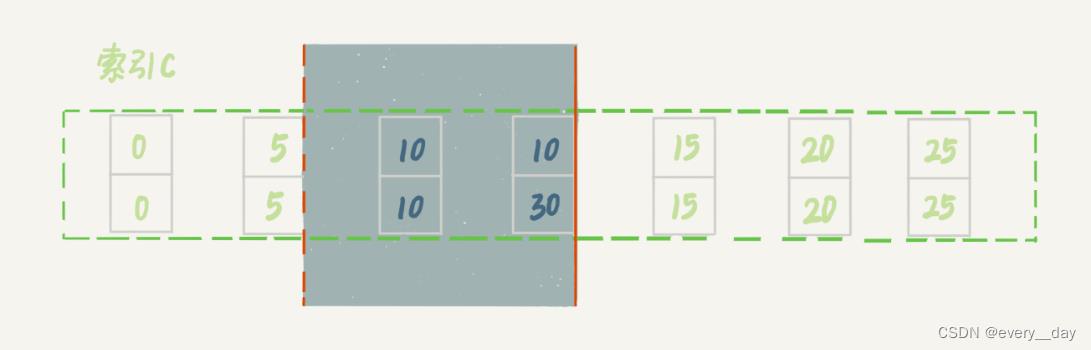
案例7:limit 语句加锁
案例6 还有个对照案例,

这个带limit, 扫描到第二个 以= 10 就停止了,加锁范围小一些。
所以说,删除数据时,尽量加上 limit ,可以控制删除的条数,还可以减小锁的范围。
五、排序与优化
1.order by 的工作原理
假设有客户信息表的定义如下。要查询城市为杭州的,且按姓名排序,返回前1000个人的姓名和年龄。
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`city` varchar(16) NOT NULL,
`name` varchar(16) NOT NULL,
`age` int(11) NOT NULL,
`addr` varchar(128) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `city` (`city`)
) ENGINE=InnoDB;
// 查询语句可以这么写
select city,name,age from t where city='杭州' order by name limit 1000 ;
Mysql 会给每个线程分配一块内存,用于排序。这块内存叫 sort_buffer。
这条排序的SQL,执行流程大概如下:
- 初始化 sort_buffer,确定放入 city, name, age 三个字段。
- 从索引 city,中取第一个满足条件 city = ‘杭州’ 的主键 id。
- 用上步中的 id,在主键 id 索引中,取出整行数据,将 city, name,age 三个字段放入 sort_buffer中
- 从索引 city 中,取第二个符合条件的id,重复 步骤 2 和 3 ,直到条件不满足为止
- 对 sort_buffer 中的数据,按 name 做快速排序。
- 取排序结果的前 1000 返回

其中按 name 排序,若数据量小,直接在内存中完成。若数据量大,则借助磁盘临时文件来完成。
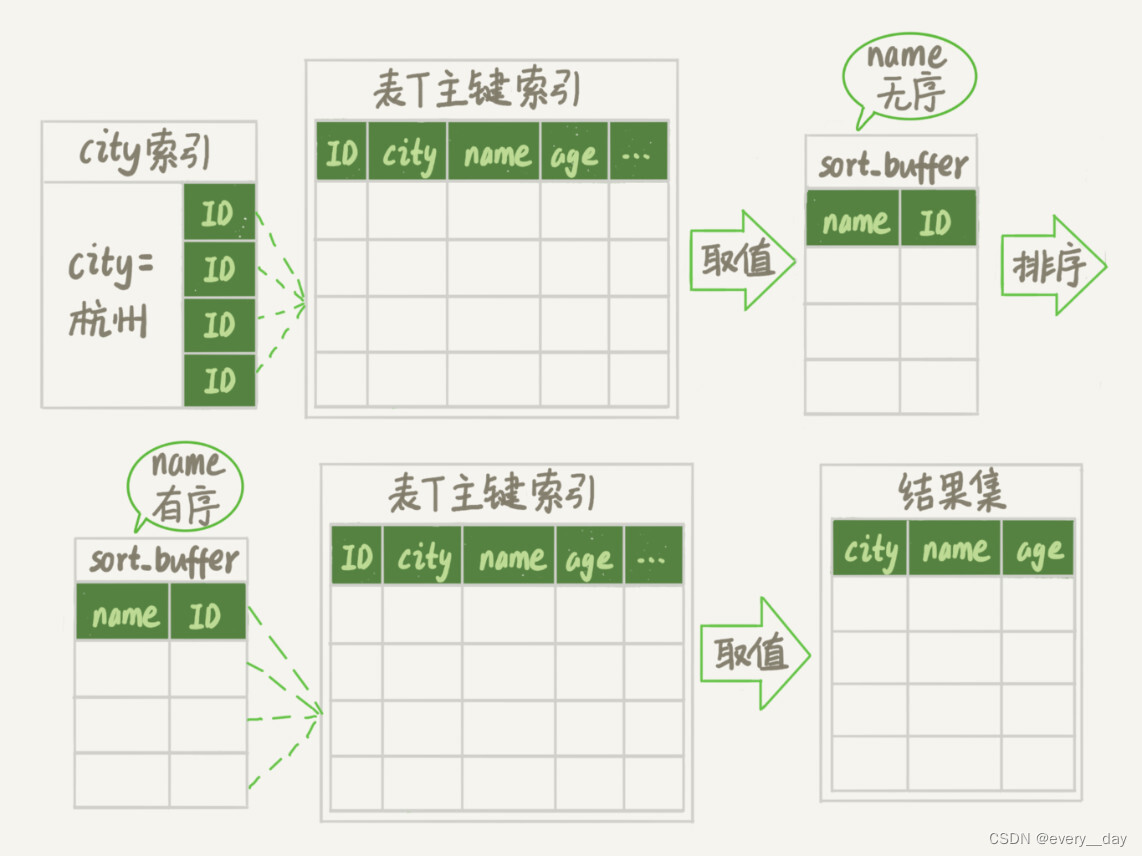
上面例子中,只返回name和age两个字段,若返回的字段特别多,
即 sort_buffer 中行数据很大时,Mysql 会采取另外一种策略进行排序。
- 初始化 sort_buffer,确定放入 name, id 两个字段
- 从索引 city,中取第一个满足条件 city = ‘杭州’ 的主键 id。
- 用上步中的 id,在主键 id 索引中,取出整行数据,将 name,id 两个字段放入 sort_buffer中。
- 从索引 city 中,取第二个符合条件的id,重复 步骤 2 和 3 ,直到条件不满足为止。
- 对 sort_buffer 中的数据,按 name 做快速排序。
- 取排序结果的前 1000行,并拿 对应的 id,到原表中取 city,name,age三个字段返回。
这两种排序,也体现了 Mysql 的设计思想:如果内存够,就多利用内存,尽量减小磁盘的访问。
2.优化相关
对索引字段做函数操作,可能会破坏索引的有序性,优化器会放弃使用树的搜索功能。
比如索引字段的隐式转换,字符集转换都可能引起索引失效
五、其它
1.数据空洞与表重建
参数 innobd_file_per_table
设置为 ON 表示,每个表数据存储在,以 idb 为后缀的文件中
设置为 OFF 表示,表数据放在系统共享表空间,跟数据字典放在一起
删除一条数据,innodb 会把该条记录标记为删除,文件并没有减小。
或是删除整个数据页,那整个数据页被标记为可复用。
删除数据可造成数据空洞,插入数据也会。
如果一个表,需要清除空洞,收缩表空间,可用 alter table A engine = innoDB 命令
大致流程如下:
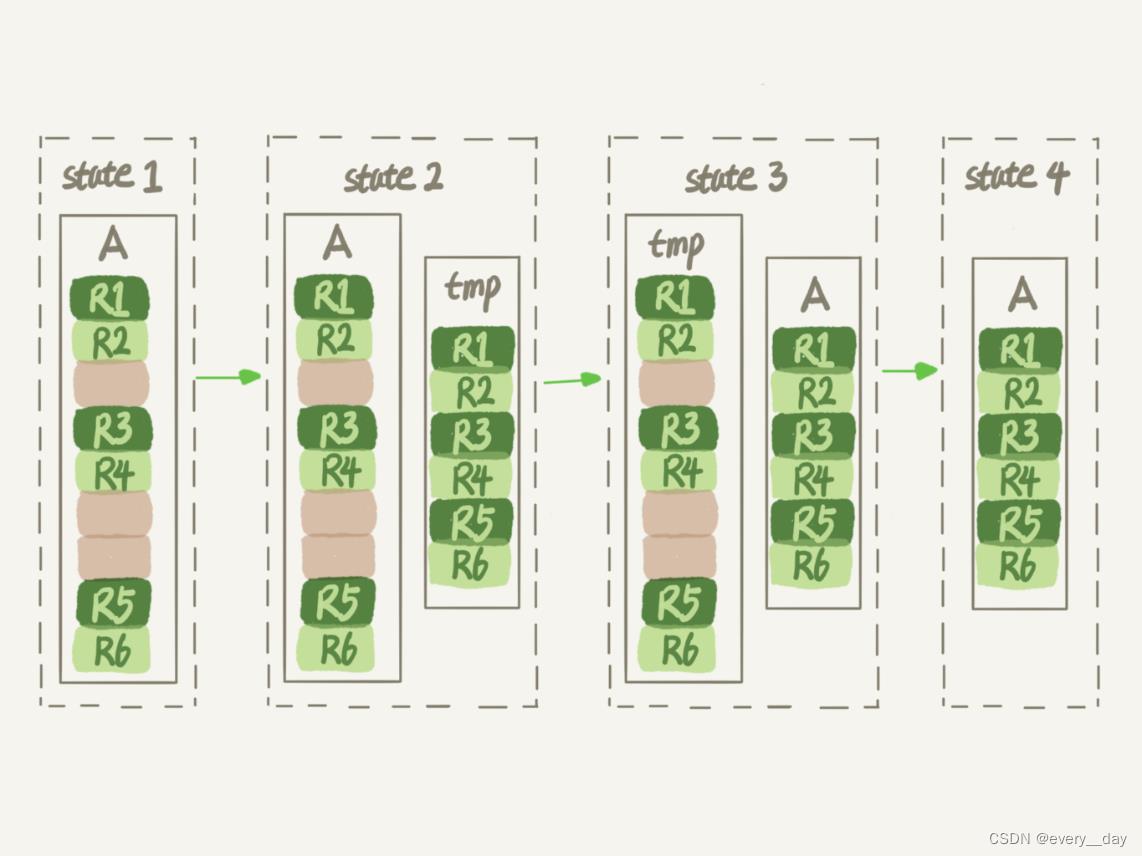
此过程中 表 A 不能有更改,不是 on Line 的
2.count(*)
- MYISAM 表 count(*) 很快,但不支持事务
- show table status 返回快,但结果不准确
- InnoDB 表 count(*) 结果很准确,但性能有问题
按效率排序 count(字段)<count(主键 id)<count(1)≈count(*),
建议,尽量使用 count(*),它做了优化,语义是“取行数”。
总结

以上是关于Mysql相关知识点汇总的主要内容,如果未能解决你的问题,请参考以下文章