2022 年 TI 杯大学生电子设计竞赛具有自动泊车功能的电动车(B 题)——小车视觉神经网络模型压缩的解决办法(流媒体嵌入式端)
Posted zhaohaobingSUI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2022 年 TI 杯大学生电子设计竞赛具有自动泊车功能的电动车(B 题)——小车视觉神经网络模型压缩的解决办法(流媒体嵌入式端)相关的知识,希望对你有一定的参考价值。
2022 年 TI 杯大学生电子设计竞赛具有自动泊车功能的电动车(B 题)——小车视觉神经网络模型压缩的解决办法(流媒体、嵌入式端)
- 1 开发环境的创建
- 1.1 Conda简介
- 1.2 miniconda
- 1.3 conda操作
- 2 多媒体数据收集和标注
- 2.1 多媒体数据下载
- 2.2 数据标注方法
- 2.3 网上常用的数据集
- 3 流媒体服务器搭建和访问
- 3.1 视频推流
- 3.2 用opencv打开rtsp视频流
- 4 目标检测分类算法
- 4.1 软件安装
- 4.2 利用yolov4训练新的数据集
- 5 模型部署
- 5.1 flask API
- 5.2 onnx
- 5.3 ncnn在嵌入式平台使用
1 开发环境的创建
1.1 Conda简介
Conda是一个包管理器,Anaconda是一个发行包。Anaconda是一个打包的
集合器皿,里面预装好了conda、某个版本的python、众多packages、科学计
算工具等等,所以也称为Python的一种发行版。也可以理解:conda是包的管
理,可以安装包(conda install samtools),删除环境,查找等用法。
除了Conda之外,Python的包管理工具还有Miniconda,顾名思义,它只包
含最基本的内容——python与conda,以及相关的必须依赖项。
1.2 miniconda
百度搜索conda清华, 进入anaconda镜像站,找到miniconda后安装,网
址如下。
https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/
找到相对应的版本并下载。
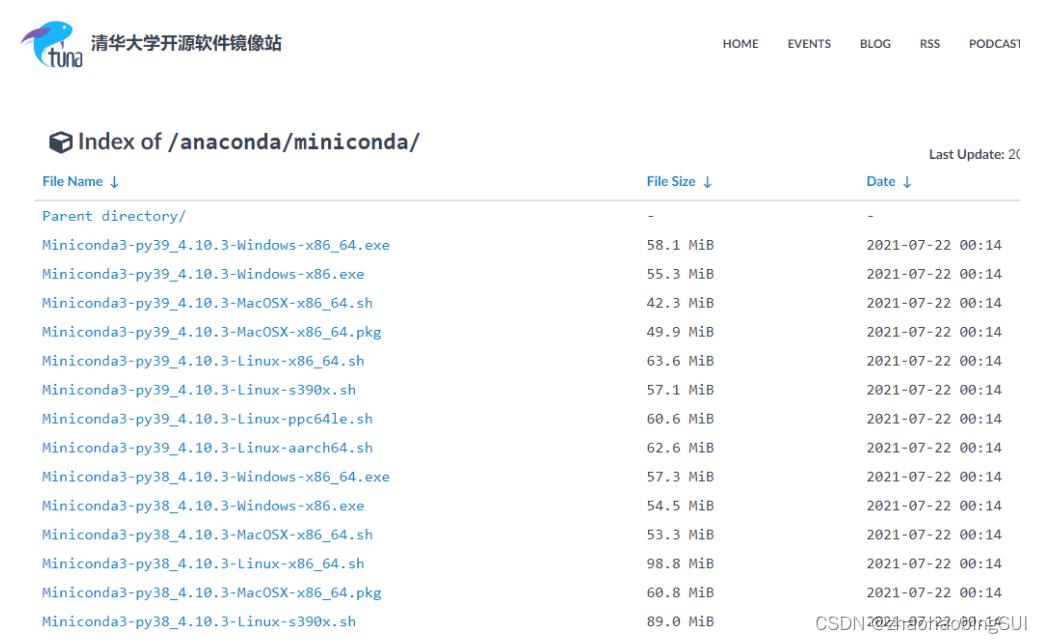
下载之后,安装过程如下图。
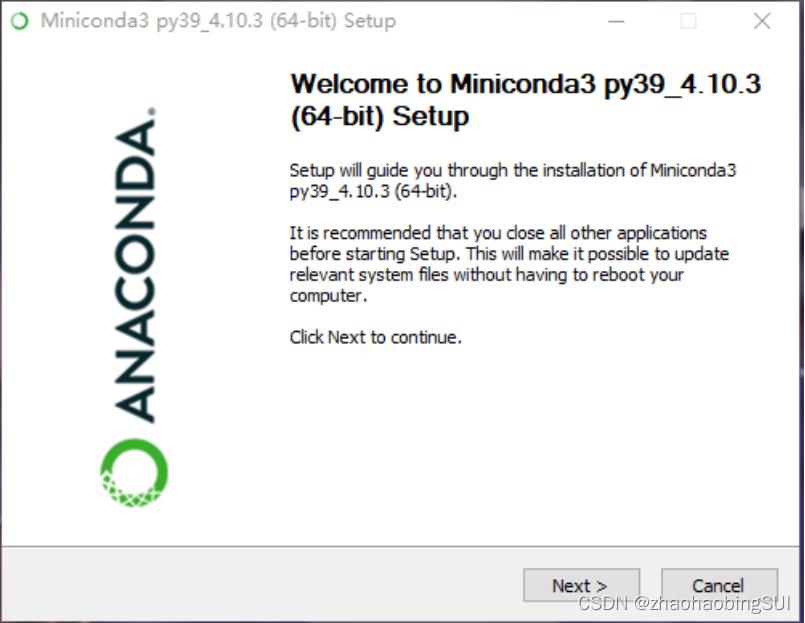
点击next继续,一直下一步。修改安装路径。

最后完成安装。
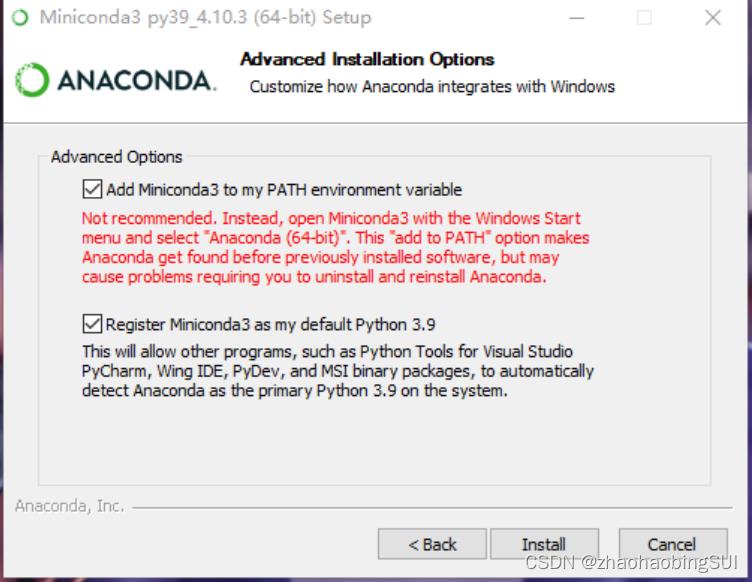
安装完成后,会发现菜单多出Prompt命令窗口,直接打开。在这个命令窗
口里面是可以直接使用conda的,但cmd窗口使用conda会找不到命令,需要手
动添加环境变量到path。


1.3 conda操作
#获取版本号
conda --version 或 conda -V
#检查更新当前conda
conda update conda
#查看当前存在哪些虚拟环境
conda env list 或 conda info -e
#查看--安装--更新--删除包
conda list:
conda search package_name# 查询包
conda install package_name
conda install package_name=1.5.
conda update package_name
conda remove package_name
#创建名为your_env_name的环境
conda create --name your_env_name
#创建制定python版本的环境
conda create --name your_env_name python=2.
conda create --name your_env_name python=3.
#创建包含某些包(如numpy,scipy)的环境
conda create --name your_env_name numpy scipy
#创建指定python版本下包含某些包的环境
conda create --name your_env_name python=3.6 numpy scipy
2 多媒体数据收集和标注
2.1 多媒体数据下载
多媒体数据的收集可以通过百度搜索引擎进行图片下载,具体的工具使用方法如下:
首先,下载软件:https://www.crsky.com/soft/247901.html,下载完解压即可,
打开exe程序,如下:

接着出现如下界面。使用前需要先登录微信,然后选择图片保存位置,在“搜索”中输入需要查找的图片名称,在“数量”中填入需要的数量,点击“下载”
即可,如下:
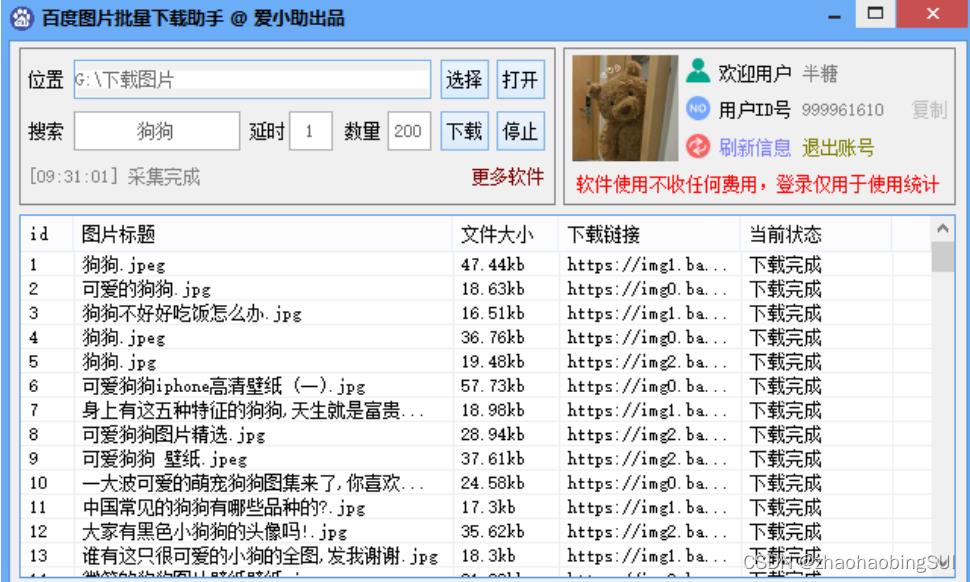
查看保存图片的文件夹,图片保存成功,如下:

2.2 数据标注方法
下面介绍对数据集的标注方法,在目标检测的实验中,若数据集本身没有标注,则该步骤必不可少,若本身已存在标注,则可忽略此步骤。(环境:Windows
- Anaconda)
在该步骤中我们选择了 LabelImg 工具,下载地址为:
https://pypi.org/project/labelImg/#files,如下图:
下载以后解压,得到如下文件(图中的保存路径为D:\\labelmg\\labelImg-1.8.6):

再找到Anaconda Prompt面板并打开,如下图所示:
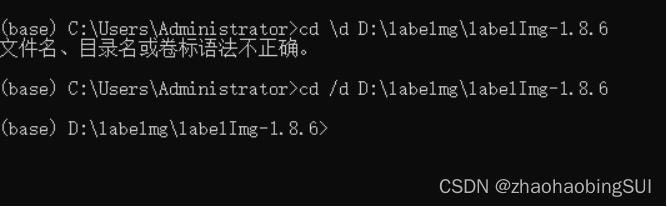
在该面板中输入上述的保存路径,格式为: cd /d +保存路径,如下图所示:
再依次按照下图输入命令,如下:
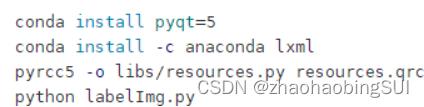
上述最后的命令输入后,即在 Anaconda Prompt 面板中输入 python
labelImg.py后,labellmg工具打开,界面如下:
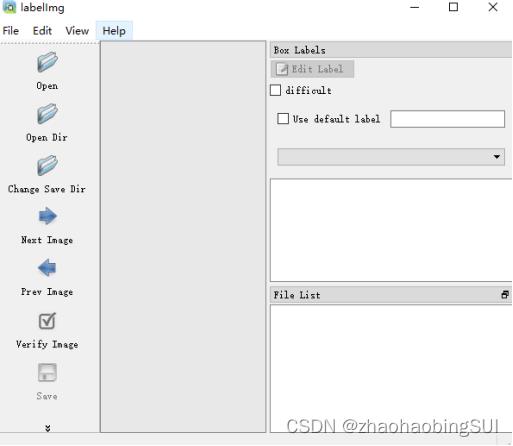
点击 Open Dir 选择影像图片文件夹之后,图片便加载进来了,点击左侧
Create RectBox,就可以在图像上绘制矩形框了,即进行数据标注操作。矩形框
绘制结束后,会弹出一个框,选择你要标记的类别,如果列表里面没有这个类别,
可以在方框中输入,最后点击OK,如下新建了类别fire:
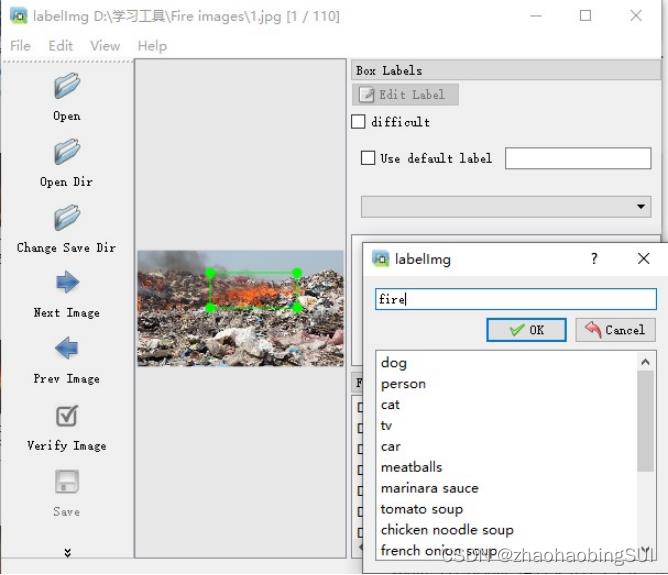
每张图片标注后,需要点击save才算保存,之后,点击next image进入下
一张图片标注,最终每张图片标注的结果将保存在xml文件中,xml文件和图片
名称一致,大致格式如下图所示:

所有图片标注完之后,数据集标注工作结束。
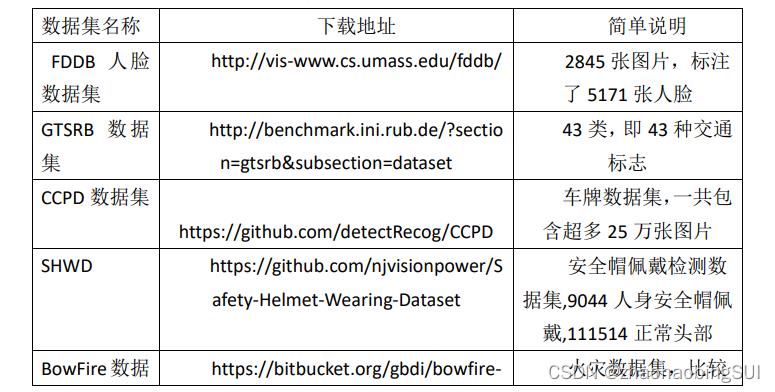
2.3 网上常用的数据集
目前,网上有许多开源的数据集(人脸,安全帽,交通标志,火灾,蔬菜,
车牌),下面列出比较常用的数据集,如下表所示:

3 流媒体服务器搭建和访问
3.1 视频推流
VLC播放器下载地址:http://www.videolan.org/,按下图步骤安装好VLC播
放器:

打开VLC播放器,点击媒体,点击流,如下:
点击添加,添加想要串流的本地文件,如下所示:
接着点击下一步,如下:
下拉框中选择RTSP,并点击添加,如下:
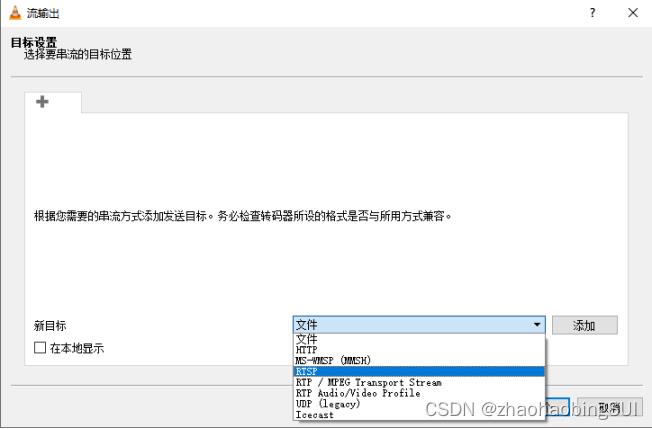
点击添加之后,端口是默认的,路径可以自己选择(路径需要记住),并点击下一个,如下:
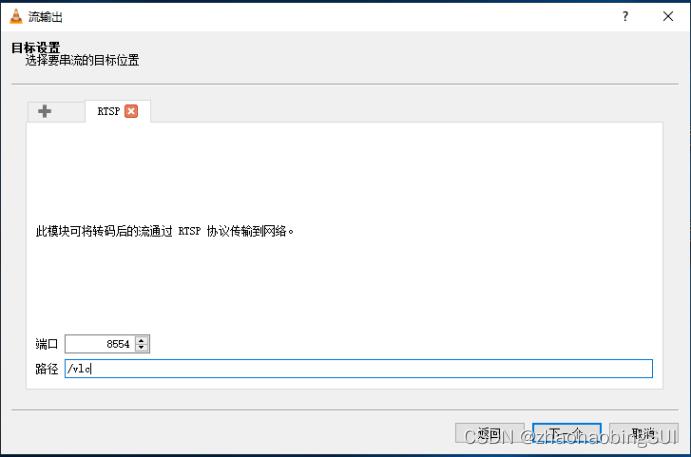
这里需要注意,激活转码不需要勾选,同时配置文件选择如下图,并点击下一个:
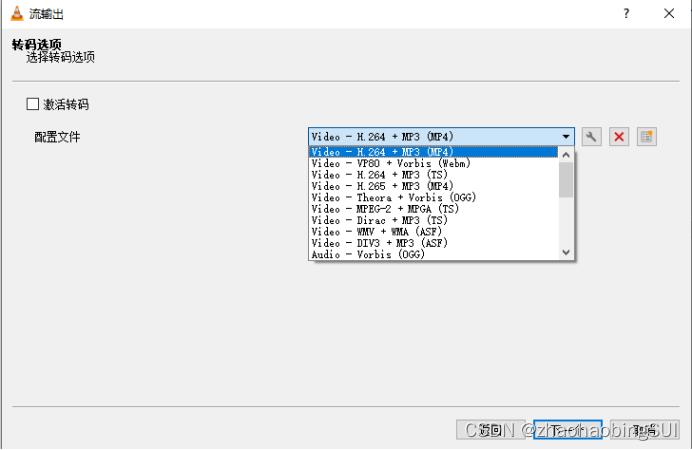
点击流,如下:
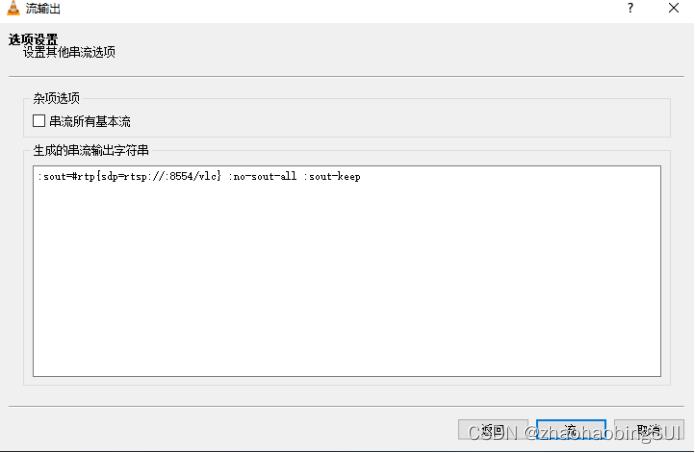
上述完成之后,视频成功发布,发布之后的VLC如下图所示:

验证视频是否发布成功,可以另外再启动一个VLC Media Player界面,如下
图选择:
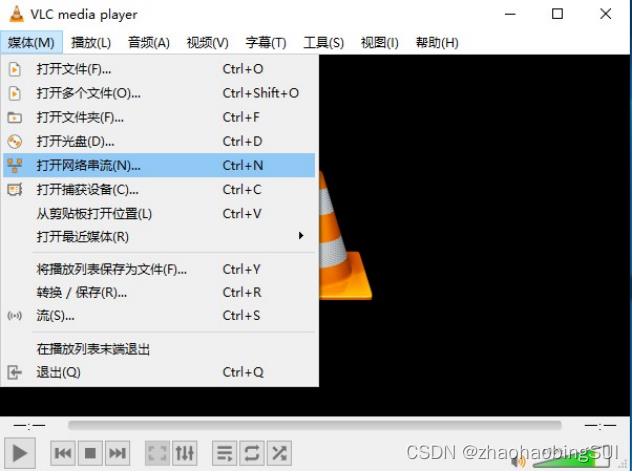
之后,输入:rstp://+本地ip 地址+:+端口号/+路径,例:
rtsp://114.213.210.112:8554/vlc,如下图所示:
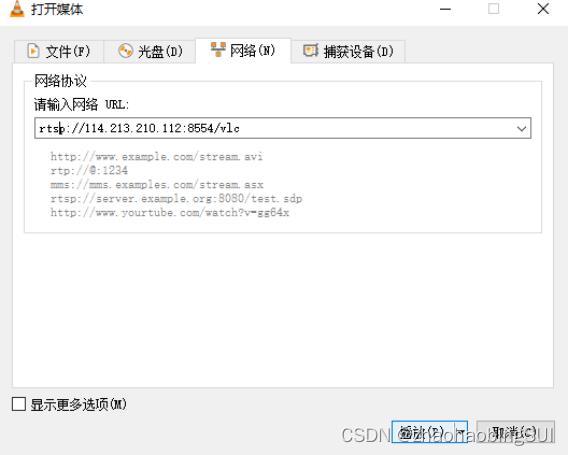
确认播放之后就可以看到视频了(需要注意视频时长,确保第一个VLC界面

的视频还在推送过程中),如下图:
3.2 用opencv打开rtsp视频流
在python的环境下利用opencv打开rtsp视频流,这里提供一个公共rtsp
视频流地址来作为一个例子,如下:
rtsp://wowzaec2demo.streamlock.net/vod/mp4:BigBuckBunny_115k.mov
代码如下所示:
#引入库
import cv2
cap =
cv2.VideoCapture("rtsp://wowzaec2demo.streamlock.net/vod/mp4:BigBuckBunny_115k.mov")
ret, frame = cap.read()
while ret:
ret, frame = cap.read()
cv2.imshow("frame",frame)
#点击"q"键直接终止播放
#参数 1 表示延时1ms切换到下一帧
if cv2.waitKey(1) & 0xFF == ord('q'):
break
#退出播放界面
cv2.destroyAllWindows()
cap.release()
运行之后可以得到播放界面,如下所示:
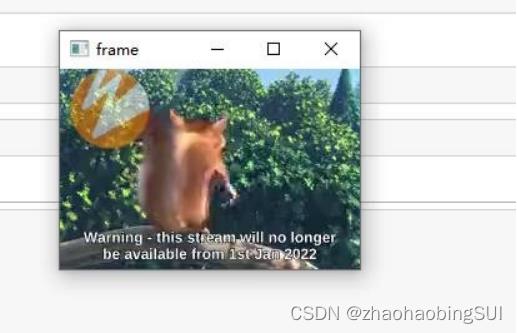
点击“q”键可以随时退出播放界面。
4 目标检测分类算法
4.1 软件安装
以yolov4为例,打开https://github.com/AlexeyAB/darknet这个教程,将这个
项目下载到本地文件。接下来需要下载一下:
- Opencv: OpenCV >= 2.4: https://opencv.org/releases.html
- 安装完成后,添加环境变量:右击此电脑-属性-高级系统设置-环境变
量,找到系统变量中的path(找到自己的安装目录相对应的文件位置):
C:\\Program Files\\opencv\\build\\x64\\vc15\\bin - C :\\Program Files\\opencv\\build\\x64\\vc14\\bin
添加完成后,建议重启下,保证环境变量生效。 - CMake >= 3.12: https://cmake.org/download/
- Visual Studio 2019 https://visualstudio.microsoft.com/zh-hans/than
k-you-downloading-visual-studio/?sku=Community
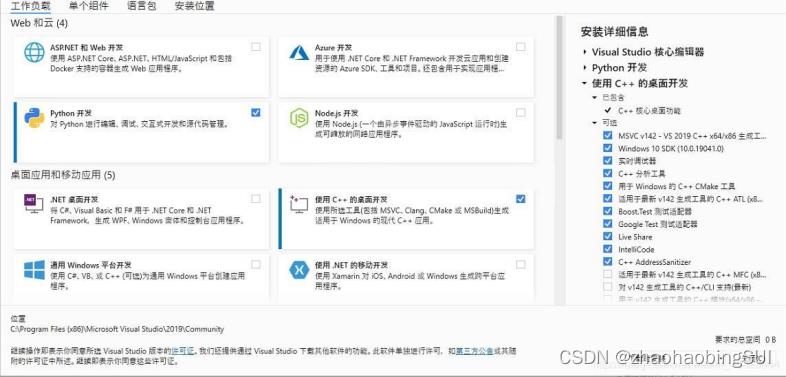
一直下一步,选择如上图,同时选择自己要安装的位置并安装。
安装配置完成后,打开cmake:
1 :导入之前下载好的github项目
2 , 3 :configure 选择vs2019,x64
4: 完成后开始编译
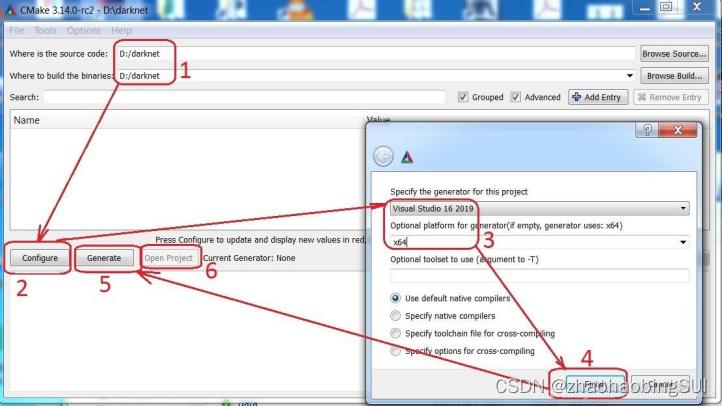
采用cpu运行,configure报错后,选择将ENABLE_CUDA取消(后面的方
框取消√)。
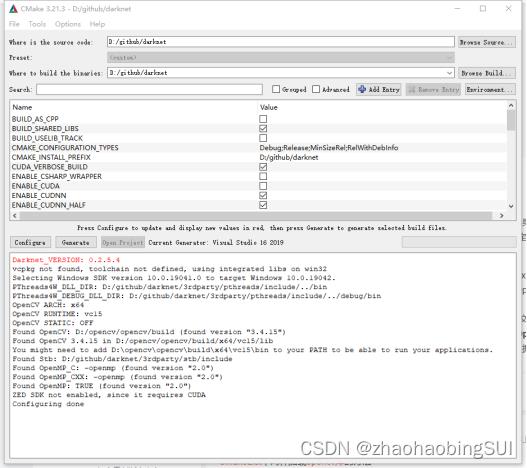
如果报错找不到对应的opencv文件,可以手动指定路径。


- 显示congifure done后,点击generate
- generate done后,点击open project就会自动打开vs2019
- 选择release,x64,点击生成解决方案。
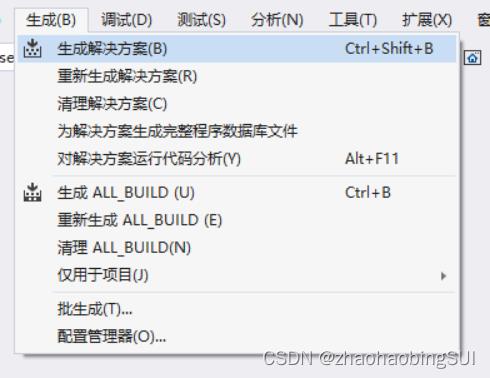

- 生成完成后,在原项目文件中就会出现一个release文件夹,里面有dark
net.exe文件,此时直接运行时失败的。
8.下载YOLOV4权重文件
链接:https://pan.baidu.com/s/1ZNK7FbqC2TlVKukQFqGYSw
提取码:g0ju
将权重文件和对 7 中的exe文件复制到D:\\download\\darknet-master\\build\\d
arknet\\x64目录中。

- 在命令提示窗口输入 cd /d D:\\download\\darknet-master\\build\\darknet\\x64
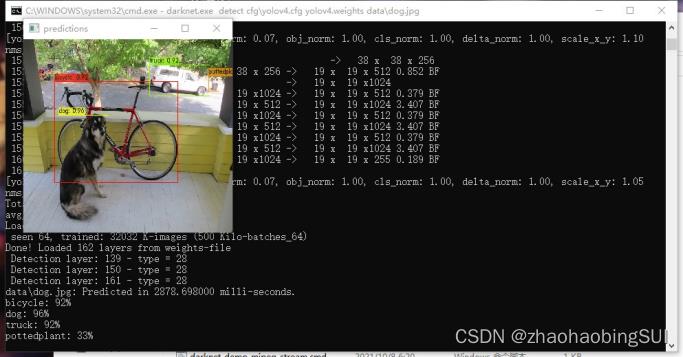
接下来输入 darknet.exe detect cfg\\yolov4.cfg yolov4.weights data\\dog.jpg
输入完成后进行作者项目中的dog.jpg的目标检测。
4.2 利用yolov4训练新的数据集
1 、Yolov4预训练模型yolov4.conv.137下载地址:https://pan.baidu.com/s/1k
wAwefd3absOrZSTAGnbhQ,提取码:x3gz,放在在build/darknet/x64/下目录下。
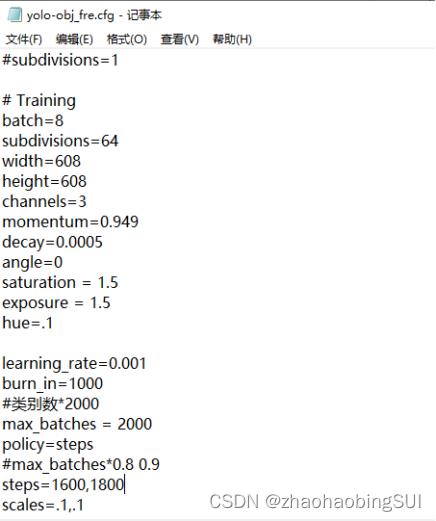
2 、创建配置文件:放在darknet-master/cfg/下,创建yolo-obj_fre.cfg(复制
cfg/yolov4-custom.cfg文件并重命名即可),但需要在几个地方修改,如下所示:
- batch=8 #依据你电脑的显存大小而定,尽量设大
一点 - subdivisions=64 # 看情况而定
- max_batches=2000 #classes*2000
- steps=1600, 1800 #max_batches0.8,max_batches0.9
- 修改 3 个[yolo]下classes=1 #你要训练的类别数
- 修改 2 个[yolo]上面filters=18 #filters=(classes + 5)x3,注意只修改每个[y
olo]上面最后一个conv的filters

创建fre.names文件,其中每一行写上一个你要训练的一个类别,如下:

3 、在build\\darknet\\x64\\data\\下,创建fre.data文件,文件格式为:
⚫ classes= 1
⚫ train = build/darknet/x64/data/train.txt # 这个下面说,train.txt
里面存放着训练图片的存放路径
⚫ valid = build/darknet/x64/data/test.txt #
⚫ names = build/darknet/x64/data/fre.names # 创建的fre.names
⚫ backup = backup/ #权重存在在backup文件中
4 、再处理自己的数据集(jpg文件+xml文件),将jpg文件放在./build/dar
knet/x64/data/obj中,将xml文件放在./build/darknet/x64/data/train_label,接下
来需要将xml文件转化为yolov4需要的txt文件,代码如下:
import os
import argparse
import xml.etree.ElementTree as ET
import glob
def xml_to_txt(data_path,anno_path,path,use_difficult_bbox=False):
classes = ['am','fm','gsm','qpsk']
28
image_inds = file_name(data_path+"train_label/") #遍历 xml 文件
with open(anno_path, 'a') as f:
for image_ind in image_inds:
img_txt = data_path + 'obj/'+ image_ind + '.txt'
img_txt_file = open(img_txt, 'w')
image_path = os.path.join(data_path, 'obj/', image_ind + '.jpg')
label_path = os.path.join(data_path, 'train_label', image_ind +'.xml')
root = ET.parse(label_path).getroot()
objects_size = root.findall('size')
image_width = int(objects_size[0].find('width').text)
image_height = int(objects_size[0].find('height').text)
objects = root.findall('object')
for obj in objects:
difficult = obj.find('difficult').text.strip()
if (not use_difficult_bbox) and(int(difficult) == 1):
continue
bbox = obj.find('bndbox')
class_ind = str(classes.index(obj.find('name').text.lower().strip()))
xmin = int(bbox.find('xmin').text.strip())
xmax = int(bbox.find('xmax').text.strip())
ymin = int(bbox.find('ymin').text.strip())
ymax = int(bbox.find('ymax').text.strip())
x_center = str((xmin + xmax)/(2*image_width))
y_center = str((ymin + ymax)/(2*image_height))
width_ = str((xmax - xmin)/(image_width))
height_ = str((ymax - ymin)/(image_height))
class_ind += ' ' + ','.join([x_center+' '+y_center+' '+width_+' '+height_])
img_txt_file.write(class_ind + "\\n")
f.write(image_path + "\\n")
def file_name(file_dir):
L = []
for root, dirs, files in os.walk(file_dir):
for file in files:
if os.path.splitext(file)[1] == '.xml':
L.append(file.split(".")[0])
return L
if __name__ == '__main__':
num1 =
xml_to_txt('./build/darknet/x64/data/','./build/darknet/x64/data/train.txt','train')
# num2 = convert_voc_annotation('./data/', './data/test.txt', False)
print('done')
5 、运行完上述代码,可以在./build/darknet/x64/data/下生成 train.txt 文件
(里面保存训练图片文件的路径),在./build/darknet/x64/data/obj/ 下生成 img.
txt(每一张图片对应的txt文件,与jpg文件放在一起),同时test.txt可以直接
复制train.txt,两者可相同。
6 、接着训练模型,本例子中将上述的文件以及darknet.exe全部复制到了根
目录darknet-master中,进入该目录下,输入darknet.exe detector train fre.dat
a cfg/yolo-obj_fre.cfg yolov4.conv.137即可训练模型,最终的权重均保存在darkn
et-master/backup中。

5 模型部署
5.1 flask API
Flask是一个基于Python开发的微型web框架,使用Flask实现简单的 api,
形成特定网页,过程如下所示:

首先需要利用pip安装flask(python环境下),如下:
接着用简单代码测试一下,代码如下:
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello():
return 'hello,world'
if __name__ == "__main__":
app.run()
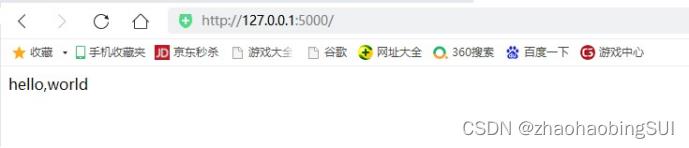
运行之后,出现了一个网址,http://127.0.0.1:5000/,如下:

在浏览器中打开,可以看见效果,如下:
5.2 onnx
⚫ 模型转化成onnx
首先需要利用pip安装onnx库,如下:
利用darknet2onnx.py文件将darknet模型转化为onnx模型,下载地址为:
https://hub.fastgit.org/Tianxiaomo/pytorch-YOLOv4,运行tool/darknet2onnx.py文
件,注意:cfgfile(darknet的cfg文件路径)、weightfile(darknet的weight文
件路径)需要补充,修改如下:

运行该文件以后,可以将darknet模型转为ONNX模型(本例子是在jupyter
notebook中运行的),结果如下,转化成功:

⚫ Onnx模型与flask的结合
这部分主要针对onnx模型在flask上的部署,即实现在网页上上传图片,然
后网页上显示目标识别后的结果。(利用pycharm)
首先在pycharm中创建一个新的flask project,如下:
而后将https://hub.fastgit.org/Tianxiaomo/pytorch-YOLOv4中的文件tool和
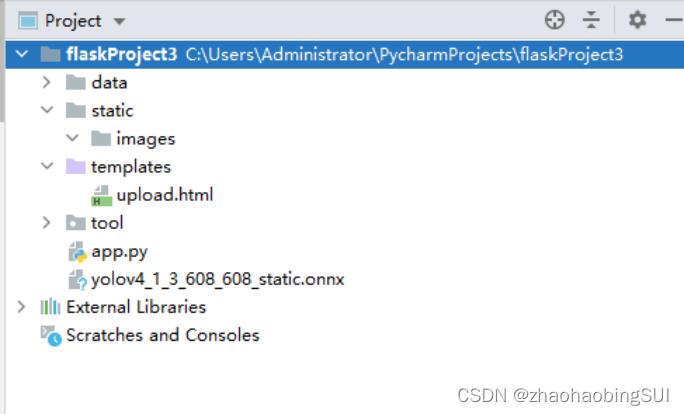
data导入,将上述步骤中生成的onnx模型导入,再在static下新建一个目录images,
用来存放待检测的图片test.jpg。在templates下新建了一个upload.html文件,
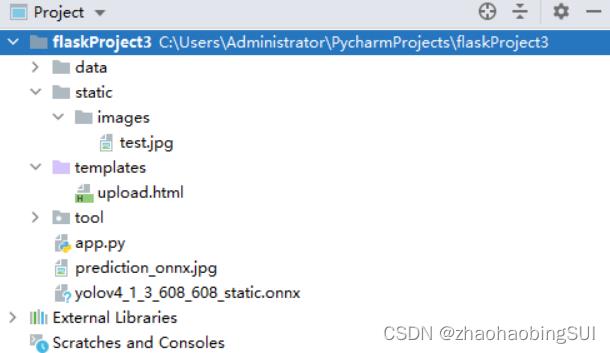
用来定义网页的页面。该project的文件总目录如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Flask 上传图片</title>
</head>
<body>
<h1>使用 Flask 上传本地图片并显示</h1>
<form action="" enctype='multipart/form-data' method='POST'>
<input type="file" name="file" style="margin-top:20px;"/>
<br>
<input type="submit" value=" 上 传 " class="button-new"
style="margin-top:15px;"/>
</form>
</body>
</html>
app.py 文件代码如下:
# coding:utf-8
from flask import Flask, render_template, request, redirect, url_for, make_response, jsonify
from datetime import timedelta
34
import os
import time
# 设置允许的文件格式
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'JPG', 'PNG', 'bmp'])
import cv2
import onnxruntime
from tool.utils import *
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1] in ALLOWED_EXTENSIONS
# 改写,只有检测部分
def test(onnx, image_path):
# onnx 模型的推理
session = onnxruntime.InferenceSession(onnx)
# session = onnx.load(onnx_path)
print("The model expects input shape: ", session.get_inputs()[0].shape)
image_src = cv2.imread(image_path)
# 检测
detect(session, image_src)
def detect(session, image_src):
# 1*3*高*宽
IN_IMAGE_H = session.get_inputs()[0].shape[2]
IN_IMAGE_W = session.get_inputs()[0].shape[3]
# Input,数据预处理
resized = cv2.resize(image_src, (IN_IMAGE_W, IN_IMAGE_H),
interpolation=cv2.INTER_LINEAR)
img_in = cv2.cvtColor(resized, cv2.COLOR_BGR2RGB)
img_in = np.transpose(img_in, (2, 0, 1)).astype(np.float32)
img_in = np.expand_dims(img_in, axis=0)
img_in /= 255.0
print("Shape of the network input: ", img_in.shape)
# Compute
input_name = session.get_inputs()[0].name
outputs = session.run(None, input_name: img_in)
boxes = post_processing(img_in, 0.4, 0.6, outputs)
num_classes = 80
35
if num_classes == 20:
namesfile = 'data/voc.names'
elif num_classes == 80:
namesfile = 'data/coco.names'
else:
namesfile = 'data/names'
class_names = load_class_names(namesfile)
plot_boxes_cv2(image_src, boxes[0], savename='prediction_onnx.jpg',
class_names=class_names)
#创建实例
app = Flask(__name__)
# 设置静态文件缓存过期时间
app.send_file_max_age_default = timedelta(seconds=1)
onnx="yolov4_1_3_608_608_static.onnx"
@app.route('/upload', methods=['POST', 'GET']) # 添加路由,访问的网址
def upload():
#方法的使用模式
if request.method == 'POST':
#原先 file 的控件名
f = request.files['file']
if not (f and allowed_file(f.filename)):
return jsonify("error": 1001, "msg": "only png\\PNG\\jpg\\JPG\\Bmp")
#获取表单数据
user_input = request.form.get("name")
basepath = os.path.dirname(__file__) # 当前文件所在路径
upload_path = os.path.join(basepath, 'static/images', 'test.jpg') #以 test 的名称
存放
f.save(upload_path)
#检测
test(onnx, upload_path)
image_data = open('prediction_onnx.jpg', "rb").read()
response = make_response(image_data)
response.headers['Content-Type'] = 'image/png'
return response
return render_template('upload.html')
36
if __name__ == '__main__':
#host 表示共享访问
app.run(host='0.0.0.0',port=8987, debug=True)
其中,上传的图片我们用test.jpg文件名保存,检测后得到的图片结果用
prediction_onnx.jpg来保存,run该项目,会生成一个网址如下:

点击该网址,会出现如下情况:

我们需要在该网址后添加规定的路由upload,再访问,得到如下网页页面:
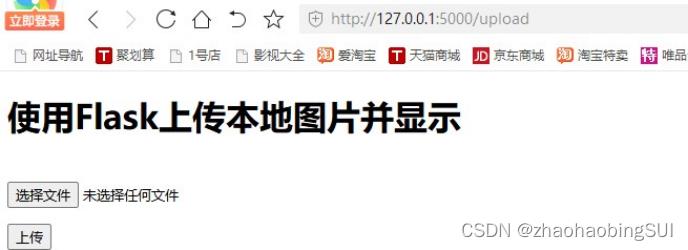
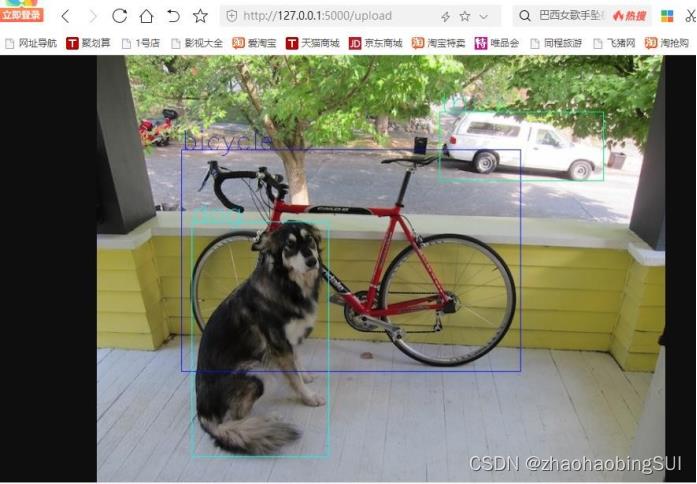
选择我们待检测的图片,并点击上传,会显示结果,如下:
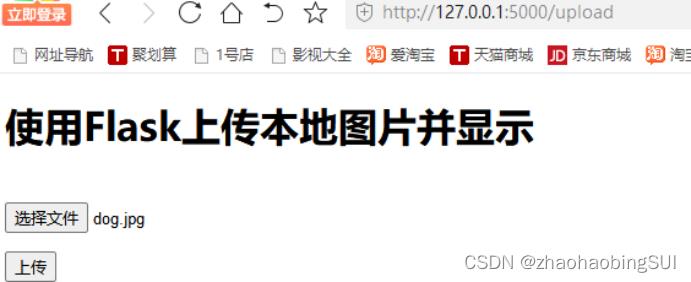
此时该project的总文件目录如下:
除flask之外,可视化界面还可以用Gradio编写。Gradio是MIT的开源项目,
使用gradio只需在原有的代码中增加几行,就能自动化生成交互式web页面,
并支持多种输入输出格式。同时还支持生成能外部网络访问的链接,能够迅速让
他人体验你的算法。下面以最简单的图像灰度化为例,展示gradio进行界面编写
的过程。
使用之前,需要进行gradio的安装。
pip install gradio
然后,创建一个简单py文件,代码如下:
import gradio as gr
import cv2
def to_black(image):
output = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
return output
interface = gr.Interface(fn=to_black, inputs="image", outputs="image")
interface.launch(share=True)
gr.Interface有三个参数,第一个为处理函数,第二个为函数的输入,第三个
为输出。更多的用法,请参考https://gradio.app/docs/.
5.3 ncnn在嵌入式平台使用
下载并安装protobuf-3.4.0
1 、下载地址:https://pan.baidu.com/s/1fRV1OpJsUXscUNlC4uvUMA 提取
码:bt4q
2 、下载后解压
3 、打开VS2019的X64命令行(注意不是cmd)
4 、在VS2019的X64命令行下执行以下命令
cd <protobuf-root-dir>
mkdir build-vs2019
cd build-vs2019
cmake -G"NMake Makefiles" -DCMAKE_BUILD_TYPE=Release
- DCMAKE_INSTALL_PREFIX=%cd%/install -Dprotobuf_BUILD_TESTS=OFF
- Dprotobuf_MSVC_STATIC_RUNTIME=OFF …/cmake
nmake
nmake install
注:<protobuf-root-dir> 为你刚刚解压的protobuf-3.4.0文件夹的根目录。
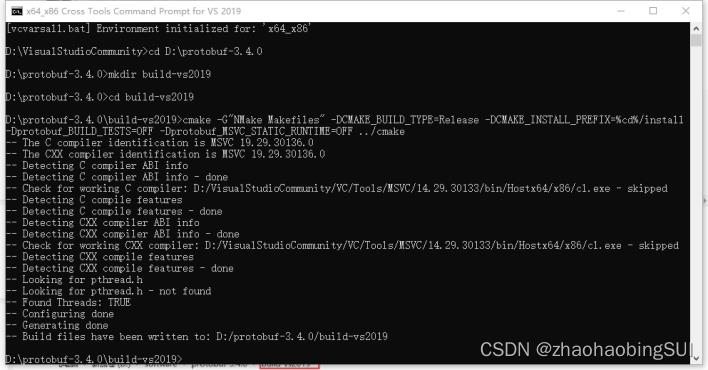
输入nmake后,继续输入nmake install就完成了
5 、成功后会产生build-vs2019文件夹以及该文件夹下的若干文件夹及文件

构建ncnn的library
1 、ncnn下载地址:https://github.com/Tencent/ncnn (官网)
2 、git clone该项目,或者直接下载压缩包
3 、打开VS2019的X64命令行(进入到ncnn根目录下)执行以下语句
注意:cmake -G…这条命令有三个需要换成之前安装
protobuf-3.4.0的根目录
cd
mkdir -p build-vs2019
cd build-vs2019
cmake - G"NMake Makefiles" -DCMAKE_BUILD_TYPE=Release -DCMAKE_I
NSTALL_PREFIX=%cd%/install -DProtobuf_INCLUDE_DIR=/build-v
s2019/install/include -DProtobuf_LIBRARIES=/build-vs2019/insta
ll/lib/libprotobuf.lib -DProtobuf_PROTOC_EXECUTABLE=/build-vs
2019/install/bin/protoc.exe -DNCNN_VULKAN=OFF …
nmake
nmake install
例 如 我 的 ncnn 安 装 目 录 是 D:\\ncnn-master,opencv 安装目录
是:/opencv/opencv,所以我的第四条命令如下
cmake -G"NMake Makefiles" ^-DCMAKE_BUILD_TYPE=Release -DCMAKE_IN
STALL_PREFIX=%cd%/install ^
- DProtobuf_INCLUDE_DIR=D:/protobuf-3.4.0/build-vs2019/install/include ^
- DProtobuf_LIBRARIES=D:/protobuf-3.4.0/build-vs2019/install/lib/libprotobuf.lib ^
- DProtobuf_PROTOC_EXECUTABLE=D:/protobuf-3.4.0/build-vs2019/install/bin/protoc.exe ^ …
- DNCNN_VULKAN=OFF … ^-DOpenCV_DIR=D:/opencv/opencv/build …
后 续 过 程 和 protobuf 一 样 , 在 译 后 , 在 目 录
ncnn-master/build-vs2019/tools/onnx下,有onnx2ncnn这个可执行文件,这个
文件是将模型onnx转化为ncnn模型。在ncnn-master/build-vs2019/tools/caffe
文件夹下有 caffe2ncnn 这个可执行文件,是将 caffe 模型转为 ncnn,在
nncnn-master/build-vs2019/tools 下有一个 ncnn2mem 这个文件用来将 ncnn
模型进行加密的。onnx转化为ncnn模型时,我们需要使用的是onnx2ncnn这
个可执行文件。
在将onnx转换为ncnn模型前,我们需要简化onnx模型,以免出现不可
编译的情况
首先,安装onnx-smiplifier
pip install onnx-simplifier
然后简化onnx模型
python -m onnxsim yolov4.onnx yolov4-sim.onnx

onnx转换为ncnn,首先将yolov-sim.onnx模型复制粘贴到ncnn-master
/build-vs2019/tools/onnx,在这个界面打开终端输入:
./onnx2ncnn yolov4-sim.onnx yolov4-sim.param yolov4-sim.bin
最后得到的parm和bin文件即是ncnn所需要的模型,其中param存放
的是模型结构,bin存放的是类似卷积这些op的权重文件。
以上是关于2022 年 TI 杯大学生电子设计竞赛具有自动泊车功能的电动车(B 题)——小车视觉神经网络模型压缩的解决办法(流媒体嵌入式端)的主要内容,如果未能解决你的问题,请参考以下文章