Flink-状态与容错-Broadcast State--flink1.13
Posted 宝哥大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink-状态与容错-Broadcast State--flink1.13相关的知识,希望对你有一定的参考价值。
文章目录
Flink 从 1.5.0 版本开始引入了一种新的状态,称为广播状态。在这篇文章中,我们会解释什么是广播状态以及展示一个示例来说明如何使用广播状态。
一、广播状态介绍
1.1、什么是广播状态
广播状态可以以某种方式组合处理两个事件流。第一个流的事件被广播到算子所有并行实例上,并存储在状态中。另一个流的事件不会被广播,但是会被发送到同一算子的各个实例上,并与广播流的事件一起处理。这种新的广播状态非常适合低吞吐量和高吞吐量流 Join 或需要动态更新处理逻辑的应用程序。我们将使用一个具体示例来演示如何使用广播状态,并展示具体的API。
1.2、广播状态的动态模型评估
想象一下,一个电子商务网站获取用户所有交互行为作为用户行为流。运营该网站的公司分析交互行为以增加收入,改善用户体验,以及检测和防止恶意行为。该网站实现了一个流应用程序,用于检测用户事件流上的行为模式。但是,我们希望每次模式修改时不需要修改以及重新部署应用程序,应用程序能从模式数据流 接收新模式并动态更新模式。在下文中,我们将逐步讨论此应用程序,并展示如何利用 Flink 中的广播状态功能。
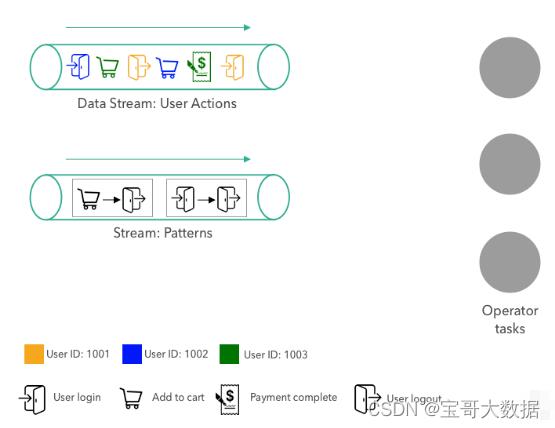
我们示例应用程序接收两个数据流。第一个数据流提供在网站上的用户行为操作,在上图的左上方显示。用户交互事件由不同类型的操作(用户登录,用户退出,添加到购物车或完成支付)以及由不同颜色编码的用户ID组成。在上图中我们可以看到用户行为数据流最新三个事件分别为:1001用户的登录事件、1003用户的支付完成事件以及1002用户的添加购物车事件。
第二个流提供了动态模型评估的用户操作模式。一个模式由两个连续的行为组成。在上图中的模式流包含以下两个模式:
-
模式#1:用户登录后并立即退出,没有浏览电子商务网站上的任何页面。
-
模式#2:用户将物品添加到购物车并立即退出,没有进行购买。
这些模式有助于企业更好地分析用户行为,检测恶意行为并改善网站的用户体验。例如,如果商品被添加到购物车而没有后续购买,网站团队可以采取适当的措施来更好地了解用户未完成购买的原因并进行一些工作改善网站的转化率( 如提供折扣,限时免费送货优惠等)。
在右侧,该图显示了算子的三个并发任务,该算子接收模式流和用户行为流,并在用户行为流上进行模式评估,然后向下游发送匹配的模式。为简单起见,我们示例中的算子仅计算满足单个模式的连续两个操作。当从模式流接收到新模式时,新模式会替换当前模式。原则上,还可以实现计算更复杂的模式或多个模式,这些模式可以单独添加或是删除。
我们将描述模式匹配应用程序如何处理用户操作和模式流。下图中
首先将模式发送给算子。该模式被广播到算子的所有三个并发任务上。任务将模式存储在其广播状态中。由于广播状态只应使用广播数据进行更新,因此所有任务的状态都是一样的。

接下来,第一个用户行为根据用户ID分区并发送到算子任务上。分区可确保同一用户的所有行为都由同一个任务处理。
下图显示了算子任务消费第一个模式和前三个行为事件后应用程序的状态

当任务收到新的用户行为时,通过查看用户最新行为和前一个行为来评估当前的活跃模式。对于每个用户,算子都将前一个行为存储在 Keyed State 中。由于上图中的任务到目前为止每个用户仅收到了一个行为(因为我们刚刚才启动应用程序),因此不需要进行模式评估。最后, 最新行为会更新 Keyed State 中存储的前一个行为,以便能够在同一用户的下一个行为到达时进行查找。
在处理完前三个行为之后,下一个行为(用户1001的退出行为)被发送到处理用户 1001 的任务上。当任务接收到新行为时,从广播状态中查找当前模式以及用户1001的前一个行为。由于两个行为匹配模式(用户登录后并立即退出),因此任务发出一个模式匹配事件。最后,任务使用最新行为来覆盖 Keyed State 上的前一个行为。如下图:
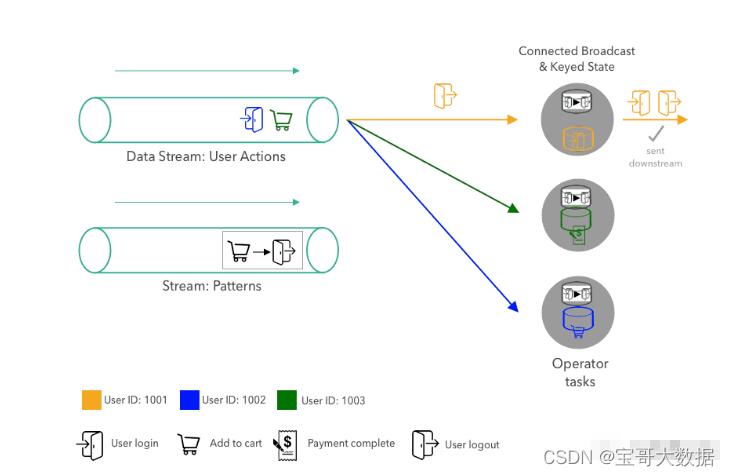
当一个新模式进入了模式流,它会被广播给所有任务,并且每个并发任务通过使用新模式替换当前模式来更新其广播状态。

一旦用新模式更新了广播状态,匹配逻辑就像之前一样继续执行,即用户行为事件按 key 分区并由负责的任务进行评估。
三、API介绍
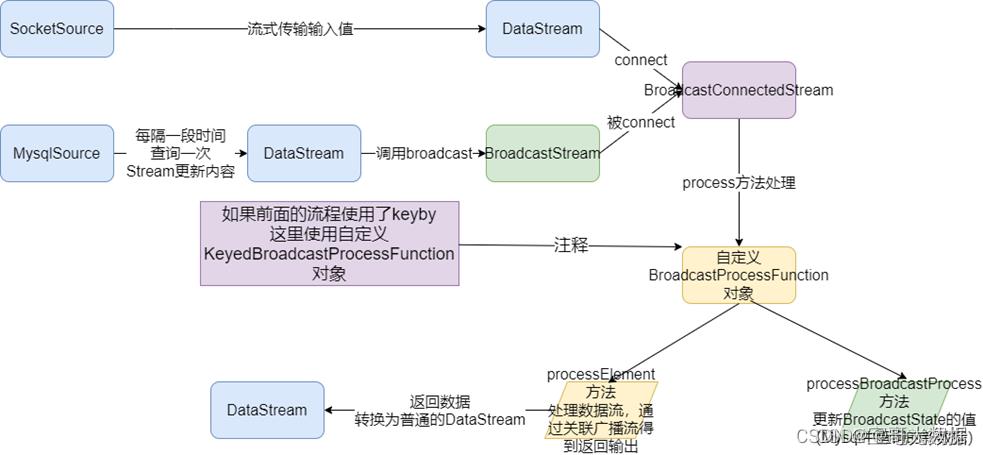
为了关联一个非广播流(keyed 或者 non-keyed)与一个广播流(BroadcastStream),我们可以调用非广播流的方法 connect(),并将 BroadcastStream 当做参数传入。 这个方法的返回参数是 BroadcastConnectedStream,具有类型方法 process(),传入一个特殊的 CoProcessFunction 来书写我们的模式识别逻辑。 具体传入 process() 的是哪个类型取决于非广播流的类型:
- 如果流是一个 keyed 流,那就是 KeyedBroadcastProcessFunction 类型;
- 如果流是一个 non-keyed 流,那就是 BroadcastProcessFunction 类型。
DataStream<String> output = colorPartitionedStream
.connect(ruleBroadcastStream) // connect() 方法需要由非广播流来进行调用,BroadcastStream 作为参数传入。
.process(
// 传入一个特殊的 CoProcessFunction 来书写我们的模式识别逻辑
// KeyedBroadcastProcessFunction 中的类型参数表示:
// 1. key stream 中的 key 类型
// 2. 非广播流中的元素类型
// 3. 广播流中的元素类型
// 4. 结果的类型,在这里是 string
new KeyedBroadcastProcessFunction<Color, Item, Rule, String>()
// 模式匹配逻辑
);
3.1、BroadcastProcessFunction 和 KeyedBroadcastProcessFunction
在传入的 BroadcastProcessFunction 或 KeyedBroadcastProcessFunction 中,我们需要实现两个方法。processBroadcastElement() 方法负责处理广播流中的元素,processElement() 负责处理非广播流中的元素。 两个子类型定义如下:
public abstract class BroadcastProcessFunction<IN1, IN2, OUT> extends BaseBroadcastProcessFunction
public abstract void processElement(IN1 value, ReadOnlyContext ctx, Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(IN2 value, Context ctx, Collector<OUT> out) throws Exception;
public abstract class KeyedBroadcastProcessFunction<KS, IN1, IN2, OUT>
public abstract void processElement(IN1 value, ReadOnlyContext ctx, Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(IN2 value, Context ctx, Collector<OUT> out) throws Exception;
public void onTimer(long timestamp, OnTimerContext ctx, Collector<OUT> out) throws Exception;
需要注意的是 processBroadcastElement() 负责处理广播流的元素,而 processElement() 负责处理另一个流的元素。两个方法的第二个参数(Context)不同,均有以下方法:
- 得到广播流的存储状态:ctx.getBroadcastState(MapStateDescriptor<K, V> stateDescriptor)
- 查询元素的时间戳:ctx.timestamp()
- 查询目前的Watermark:ctx.currentWatermark()
- 目前的处理时间(processing time):ctx.currentProcessingTime()
- 产生旁路输出:ctx.output(OutputTag outputTag, X value)
- 在 getBroadcastState() 方法中传入的 stateDescriptor 应该与调用 .broadcast(ruleStateDescriptor) 的参数相同。
这两个方法的区别在于对 broadcast state 的访问权限不同。在处理广播流元素这端,是具有读写权限的,而对于处理非广播流元素这端是只读的。 这样做的原因是,Flink 中是不存在跨 task 通讯的。所以为了保证 broadcast state 在所有的并发实例中是一致的,我们在处理广播流元素的时候给予写权限,在所有的 task 中均可以看到这些元素,并且要求对这些元素处理是一致的, 那么最终所有 task 得到的 broadcast state 是一致的。
注意:processBroadcastElement() 的实现必须在所有的并发实例中具有确定性的结果。
同时,KeyedBroadcastProcessFunction 在 Keyed Stream 上工作,所以它提供了一些 BroadcastProcessFunction 没有的功能:
- 1、processElement() 的参数 ReadOnlyContext 提供了方法能够访问 Flink 的定时器服务,可以注册事件定时器(event-time timer)或者处理时间的定时器(processing-time timer)。当定时器触发时,会调用 onTimer() 方法, 提供了 OnTimerContext,它具有 ReadOnlyContext 的全部功能,并且提供:
- 查询当前触发的是一个事件还是处理时间的定时器
- 查询定时器关联的key
- 2、processBroadcastElement() 方法中的参数 Context 会提供方法 applyToKeyedState(StateDescriptor<S, VS> stateDescriptor, KeyedStateFunction<KS, S> function)。 这个方法使用一个 KeyedStateFunction 能够对 stateDescriptor 对应的 state 中所有 key 的存储状态进行某些操作。
注意:注册一个定时器只能在 KeyedBroadcastProcessFunction 的 processElement() 方法中进行。 在 processBroadcastElement() 方法中不能注册定时器,因为广播的元素中并没有关联的 key。
3.2、重要注意事项
这里有一些 broadcast state 的重要注意事项,在使用它时需要时刻清楚:
1、没有跨 task 通讯:如上所述,这就是为什么只有在 (Keyed)-BroadcastProcessFunction 中处理广播流元素的方法里可以更改 broadcast state 的内容。 同时,用户需要保证所有 task 对于 broadcast state 的处理方式是一致的,否则会造成不同 task 读取 broadcast state 时内容不一致的情况,最终导致结果不一致。
2、broadcast state 在不同的 task 的事件顺序可能是不同的: 虽然广播流中元素的过程能够保证所有的下游 task 全部能够收到,但在不同 task 中元素的到达顺序可能不同。 所以 broadcast state 的更新不能依赖于流中元素到达的顺序。
3、所有的 task 均会对 broadcast state 进行 checkpoint:虽然所有 task 中的 broadcast state 是一致的,但当 checkpoint 来临时所有 task 均会对 broadcast state 做 checkpoint。 这个设计是为了防止在作业恢复后读文件造成的文件热点。当然这种方式会造成 checkpoint 一定程度的写放大,放大倍数为 p(=并行度)。Flink 会保证在恢复状态/改变并发的时候数据没有重复且没有缺失。 在作业恢复时,如果与之前具有相同或更小的并发度,所有的 task 读取之前已经 checkpoint 过的 state。在增大并发的情况下,task 会读取本身的 state,多出来的并发(p_new - p_old)会使用轮询调度算法读取之前 task 的 state。
4、不使用 RocksDB state backend: broadcast state 在运行时保存在内存中,需要保证内存充足。这一特性同样适用于所有其他 Operator State。
四、案例-实现配置动态更新
实时过滤出配置中的用户,并在事件流中补全这批用户的基础信息。
1、事件流:表示用户在某个时刻浏览或点击了某个商品,格式如下
"userID": "user_3", "eventTime": "2019-08-17 12:19:47", "eventType": "browse", "productID": 1
"userID": "user_2", "eventTime": "2019-08-17 12:19:48", "eventType": "click", "productID": 1
2、配置数据: 表示用户的详细信息,在mysql中,如下
DROP TABLE IF EXISTS `user_info`;
CREATE TABLE `user_info` (
`userID` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`userName` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`userAge` int(11) NULL DEFAULT NULL,
PRIMARY KEY (`userID`) USING BTREE
) ENGINE = MyISAM CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of user_info
-- ----------------------------
INSERT INTO `user_info` VALUES ('user_1', '张三', 10);
INSERT INTO `user_info` VALUES ('user_2', '李四', 20);
INSERT INTO `user_info` VALUES ('user_3', '王五', 30);
INSERT INTO `user_info` VALUES ('user_4', '赵六', 40);
输出结果:
(user_3,2019-08-17 12:19:47,browse,1,王五,33)
(user_2,2019-08-17 12:19:48,click,1,李四,20)
4.1、逻辑步骤
1. env
2. source
2.1. 构建实时数据事件流-自定义随机
<userID, eventTime, eventType, productID>
2.2.构建配置流-从MySQL
<用户id,<姓名,年龄>>
3. transformation
3.1. 定义状态描述器
MapStateDescriptor<Void, Map<String, Tuple2<String, Integer>>> descriptor =
new MapStateDescriptor<>("config",Types.VOID, Types.MAP(Types.STRING, Types.TUPLE(Types.STRING, Types.INT)));
3.2. 广播配置流
BroadcastStream<Map<String, Tuple2<String, Integer>>> broadcastDS = configDS.broadcast(descriptor);
3.3. 将事件流和广播流进行连接
BroadcastConnectedStream<Tuple4<String, String, String, Integer>, Map<String, Tuple2<String, Integer>>> connectDS =eventDS.connect(broadcastDS);
3.4. 处理连接后的流-根据配置流补全事件流中的用户的信息
4. sink
5. execute
4.2、代码实现
4.2.1、java实现
import org.apache.flink.api.common.state.BroadcastState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ReadOnlyBroadcastState;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple4;
import org.apache.flink.api.java.tuple.Tuple6;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.BroadcastConnectedStream;
import org.apache.flink.streaming.api.datastream.BroadcastStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.util.Collector;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
/**
* Desc
* 需求:
* 使用Flink的BroadcastState来完成
* 事件流和配置流(需要广播为State)的关联,并实现配置的动态更新!
*/
public class BroadcastStateConfigUpdate
public static void main(String[] args) throws Exception
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.source
//-1.构建实时的自定义随机数据事件流-数据源源不断产生,量会很大
//<userID, eventTime, eventType, productID>
DataStreamSource<Tuple4<String, String, String, Integer>> eventDS = env.addSource(new MySource());
//-2.构建配置流-从MySQL定期查询最新的,数据量较小
//<用户id,<姓名,年龄>>
DataStreamSource<Map<String, Tuple2<String, Integer>>> configDS = env.addSource(new MySQLSource());
//3.transformation
//-1.定义状态描述器-准备将配置流作为状态广播
MapStateDescriptor<Void, Map<String, Tuple2<String, Integer>>> descriptor =
new MapStateDescriptor<>("config", Types.VOID, Types.MAP(Types.STRING, Types.TUPLE(Types.STRING, Types.INT)));
//-2.将配置流根据状态描述器广播出去,变成广播状态流
BroadcastStream<Map<String, Tuple2<String, Integer>>> broadcastDS = configDS.broadcast(descriptor);
//-3.将事件流和广播流进行连接
BroadcastConnectedStream<Tuple4<String, String, String, Integer>, Map<String, Tuple2<String, Integer>>> connectDS =eventDS.connect(broadcastDS);
//-4.处理连接后的流-根据配置流补全事件流中的用户的信息
SingleOutputStreamOperator<Tuple6<String, String, String, Integer, String, Integer>> result = connectDS
//BroadcastProcessFunction<IN1, IN2, OUT>
.process(new BroadcastProcessFunction<
//<userID, eventTime, eventType, productID> //事件流
Tuple4<String, String, String, Integer>,
//<用户id,<姓名,年龄>> //广播流
Map<String, Tuple2<String, Integer>>,
//<用户id,eventTime,eventType,productID,姓名,年龄> //需要收集的数据
Tuple6<String, String, String, Integer, String, Integer>>()
//处理事件流中的元素
@Override
public void processElement(Tuple4<String, String, String, Integer> value, ReadOnlyContext ctx, Collector<Tuple6<String, String, String, Integer, String, Integer>> out) throws Exception
//取出事件流中的userId
String userId = value.f0;
//根据状态描述器获取广播状态
ReadOnlyBroadcastState<Void, Map<String, Tuple2<String, Integer>>> broadcastState = ctx.getBroadcastState(descriptor);
if (broadcastState != null)
//取出广播状态中的map<用户id,<姓名,年龄>>
Map<String, Tuple2<String, Integer>> map = broadcastState.get(null);
if (map != null)
//通过userId取map中的<姓名,年龄>
Tuple2<String, Integer> tuple2 = map.get(userId);
//取出tuple2中的姓名和年龄
String userName = tuple2.f0;
Integer userAge = tuple2.f1;
out.collect(Tuple6.of(userId, value.f1, value.f2, value.f3, userName, userAge));
//处理广播流中的元素
@Override
public void processBroadcastElement(Map<String, Tuple2<String, Integer>> value, Context ctx, Collector<Tuple6<String, String, String, Integer, String, Integer>> out) throws Exception
//value就是MySQLSource中每隔一段时间获取到的最新的map数据
//先根据状态描述器获取历史的广播状态
BroadcastState<Void, Map<String, Tuple2<String, Integer>>> broadcastState = ctx.getBroadcastState(descriptor);
//再清空历史状态数据
broadcastState.clear();
//最后将最新的广播流数据放到state中(更新状态数据)
broadcastState.put(null, value);
);
//4.sink
result.print();
//5.execute
env.execute();
/**
* <userID, eventTime, eventType, productID>
*/
public static class MySource implements SourceFunction<Tuple4<String, String, String, Integer>>
private boolean isRunning = true;
@Override
public void run(SourceContext<Tuple4<String, String, String, IntegerFlink中的状态与容错
Flink 使用 Broadcast State 的4个注意事项