IncSpan: Incremental Mining of Sequential Patterns in Large Database
Posted Casey321
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了IncSpan: Incremental Mining of Sequential Patterns in Large Database相关的知识,希望对你有一定的参考价值。
目录
- Abstract
- Introduction
- Preminlinary concepts
- Buffer semi-frequent patterns
- INCSPAN: DESIGN AND IMPLEMENTATION
- CONCLUSION
Abstract
许多真实生活中的序列数据库都呈现递增趋势。当一小部分序列增长或将一些新序列添加到数据库中时,我们不希望从头开始挖掘序列模式。因此应该开发序列模式挖掘增量算法,以便挖掘能够适应增量数据库更新。然而,增量挖掘序列模式并不是重要的,特别是当现有序列增量增长时,因为由于增长的子序列与原始子序列的相互作用,这种增长可能导致许多新模式的生成。在本研究中,本文开发了一个有效的算法IncSpan,通过探索一些有趣的属性,为序列模式的增量挖掘。实验研究表明,IncSpan的性能优于以前提出的一些增量算法,以及一个具有很大边际的非增量算法。
Introduction
序列模式挖掘是数据挖掘中一个重要而活跃的研究课题,具有广泛的客户购物交易分析、挖掘网络日志、挖掘DNA序列等应用前景。
在先前的研究中,已经提出了相当多的序列模式或封闭序列模式挖掘算法,可以有效地从大型序列数据库中挖掘频繁的子序列。这些算法以一种一次性的方式工作:挖掘整个数据库并获得一组结果。然而,在许多应用程序中,数据库是增量更新的。例如,客户购物交易数据库每天都在增长,因为为现有客户添加新购买的商品和/或为新客户插入新的购物序列,供后续客户购物。其他的例子包括天气序列和患者治疗序列,它们随着时间逐渐增长。现有的序列挖掘算法不适合处理这种情况,因为从旧数据库中挖掘出的结果在更新后的数据库上不再有效,而且从头开始挖掘更新后的数据库的效率是令人难以忍受的。
在应用程序中有两种数据库更新:(1)插入新的序列(表示为插入),以及(2)将新的项集/项附加到现有的序列中(表示为附加)。一个真正的应用程序可以同时包含两者。
第一种情况更容易处理:插入。插入的一个重要特性是
D
B
′
DB^\\prime
DB′=
D
B
∪
∆
d
b
DB∪∆db
DB∪∆db中的频繁序列必须在
D
B
DB
DB或
∆
d
b
∆db
∆db(或两者)中都是频繁的。如果一个序列在
D
B
DB
DB和
∆
d
b
∆db
∆db中都不常见,那么它在
D
B
′
DB^\\prime
DB′,中就不能很常见,如下图所示。这个属性类似于在增量频繁模式挖掘中使用的频繁模式。这种增量频繁模式挖掘算法可以很容易地扩展到处理插入情况下的序列模式挖掘。
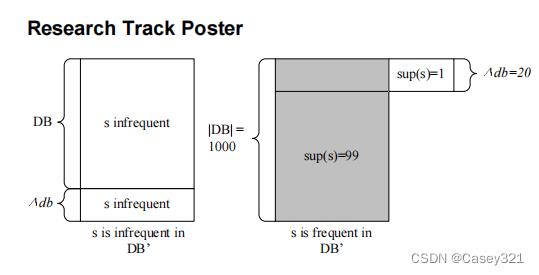
处理第二种情况比处理第一种情况要复杂得多。这是因为不仅附加的项可能在
∆
d
b
∆db
∆db中生成新的本地频繁序列,而且本地不频繁序列可能将其出现计数贡献给原始数据库中相同的不频繁序列,从而产生频繁序列。例如,在上图中附加的数据库中,假设|DB|=1000和|∆db|=20,最小支持10%。假设一个序列s在
D
B
DB
DB中出现99次(sup=9.9%)。此外,
s
s
s在
∆
d
b
∆db
∆db中也很少见,只有1次出现(sup=5%)。虽然s在
D
B
DB
DB和
∆
d
b
∆db
∆db中都不常见,但在
D
B
′
DB^\\prime
DB′中却是频繁的,出现了100次。这个问题使增量挖掘复杂化,因为我们不能忽略
∆
D
B
∆DB
∆DB中的罕见序列,但是即使在一个小的
∆
D
B
∆DB
∆DB中也有指数级的罕见序列,并且根据数据库中的罕见序列集合来检查它们将是非常昂贵的。
当数据库使用插入(insert)和附加(append)的组合更新数据库时,我们可以将插入视为附加的特殊情况——将插入的序列视为原始数据库中空序列的附加事务。然后将这个问题简化为附加问题。因此,我们将在下面的讨论中重点关注附加案例。本文提出了一种有效的算法IncSpan,用于对多个数据库增量的增量挖掘。几个新想法引入算法开发:(1)维护一组“几乎频繁”序列的候选人更新数据库,有几个好的属性和导致有效的技术,和(2)两个优化技术,反向模式匹配和共享投影,旨在提高性能。反向模式匹配用于对序列中的序列模式进行匹配,并修剪一些搜索空间。共享投影是为了减少一些共享公共前缀的序列的数据库投影的数量。我们的性能研究表明,IncSpan是高效的和可扩展的。
Preminlinary concepts

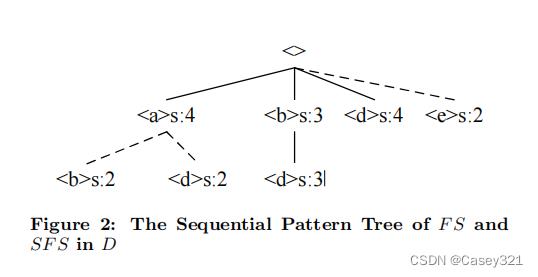
序列模式树
T
T
T是表示数据库中频繁子序列集合的树。
T
T
T中的每个节点p都有一个标记为s或i的标记,表示节点是项目集中的起始项目;我的意思是节点是项目集中的中间项。每个节点
p
p
p都有一个支持值,它表示从
T
T
T的根开始到以节点
p
p
p结束的子序列的支持值。
问题声明。给定一个序列数据库 D D D, m i n s u p minsup minsup、频繁的子序列 F S FS FS,和一个附加序列数据库 D ′ D^\\prime D′,增量序列模式挖掘的问题是从 D ′ D^\\prime D′挖掘频繁的子序列 F S ′ FS^\\prime FS′基于 F S FS FS而不是挖掘 D ′ D^\\prime D′从头开始。
Buffer semi-frequent patterns
本文将提出缓冲半频繁模式的想法,研究其特性,并设计了如何逐步挖掘和维护FS和SFS的解决方案。
Buffering Semi-frequent Patterns
该文缓冲了半频繁的模式,这可以被认为是一种基于统计数据的方法。这个技术是降低最低支持缓冲比 µ ≤ 1 µ ≤ 1 µ≤1和保持一组 S F S SFS SFS原始数据库 D D D。这是因为因为 S F S SFS SFS序列“几乎频繁”,大多数频繁的子序列附加数据库将来自 S F S SFS SFS或他们已经频繁在原始数据库。通过对原始数据库进行一次小的更新,预计只有一小部分以前不常见的子序列会变得频繁。这是基于对原始数据库的更新在项目上具有统一的概率分布的假设。预计数据库更新的部分引入的大部分频繁子序列将来自 S F S SFS SFS。 S F S SFS SFS在频繁的子序列和不频繁的子序列之间形成了一种边界(或“缓冲区”)。





(
1
−
µ
)
(1−µ)
(1−µ) *
m
i
n
s
u
p
minsup
minsup,
µ
µ
µ越小,我们保留的缓冲区就越大,算法需要的数据库投影就越少。
µ
µ
µ的选择是启发式的。如果
µ
µ
µ太高,那么缓冲区就很小,我们必须做大量的数据库投影来发现缓冲区之外的序列。如果
µ
µ
µ设置得很低,我们将在缓冲区中保留许多子序列。但是使用
µ
∗
m
i
n
s
u
p
µ∗minsup
µ∗minsup挖掘缓冲模式比使用
m
i
n
s
u
p
minsup
minsup挖掘效率低得多。

INCSPAN: DESIGN AND IMPLEMENTATION
IncSpan: Algorithm Outline

Reverse Pattern Matching
反向模式匹配是一种新的优化技术。它与从结尾到前面的序列匹配一个序列模式。这是用来检查在LDB中,一个序列模式支持度的增加。由于附加的项目总是在原始序列的末端部分,反向模式匹配将比从前面的投影更有效。



Shared Projection


CONCLUSION
该文研究了大型数据库中序列模式的增量挖掘问题,并解决了从头开始挖掘附加数据库的低效问题。通过探索几种平衡效率和可重用性的新技术,我们提出了一种IncSpan算法。IncSpan的性能大大优于非增量方法(使用预固定的Span)和之前提出的增量挖掘算法ISM。它是一种很有前途的算法来解决许多实际应用的实际问题。
有许多与IncSpan相关的有趣的研究问题有待进一步研究。例如,增量挖掘的封闭序列模式,结构化的数据库/或数据流中的模式是未来研究中的有趣问题。
以上是关于IncSpan: Incremental Mining of Sequential Patterns in Large Database的主要内容,如果未能解决你的问题,请参考以下文章