机器学习sklearn----支持向量机SVC模型评估指标
Posted iostreamzl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习sklearn----支持向量机SVC模型评估指标相关的知识,希望对你有一定的参考价值。
文章目录
前言
前面一篇博文介绍了SVC处理二分类问题是怎么样来解决样本不均衡。这里我们要来将用什么指标来衡量模型的好坏
SVC提供的接口score是计算模型的准确率的,这个指标在样本均衡的情况下是完全适用的, 但是在遇到样本不均衡问题的时候就失去了意义,而我们日常面对的数据会有较多的不均衡, 面对这样的问题,我们需要采用新的模型评估指标,而我们的评估指标需要能够反映模型捕获少数类的能力, 在现实中我们需要寻找捕获少数类的能力和将多数类判错后需要付出的代价的平衡。 如果一个模型能尽量的捕获少数类,还能将多数类尽量判断正确,那么这个模型就非常优秀了。 为了评估模型这样的能力,我们将引用混淆矩阵和ROC曲线来评估模型
本次使用的数据还是上篇博文中一模一样,数据生成及模型训练代码如下:
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
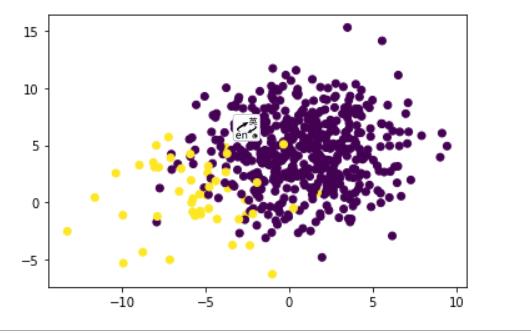
# 创建一个样本不均衡的数据集
X, y = make_blobs(n_samples=[500, 50],
n_features=2,
cluster_std=3,
random_state=3)
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.show()
# 不采用样本均衡SVC模型效果
svc_none_class_weight = SVC(kernel='linear').fit(X, y)
# 采用样本均衡参数class_weight
svc_with_class_weight = SVC(kernel='linear', class_weight=1: 10).fit(X, y)
混淆矩阵
混淆矩阵是二分类问题的一个很重要的评估指标,在样本不均衡问题非常的有用。 在混淆矩阵中我们将少数类认为是正例,多数类认为是负例。这里方便理解将少数类认为是1, 多数类认为是0. 标准二分类的混淆矩阵如下所示
| 预测值 | |||
| 1 | 0 | ||
| 真实值 | 1 | 11 | 10 |
| 0 | 01 | 00 | |
在混淆矩阵中真实值是写在预测值前面的,比如11,前面的1表示真实值,后面的1表示预测值, 那么其他的几个数字也有了自己的意义。 混淆矩阵中主对角线上的11,00表示预测完全正确的情况,10,01表述预测出错的情况,基于混淆矩阵可以产生7个模型评估指标,这些指标的结果都是在0-1之间的,下面来一一介绍这几个指标
指标1准确率
准确率(样本均衡时比较有意义):所有预测正确的样本于总样本的比例,也就是常用的scores,通常来说越接近1越好 计算方式:
准
确
率
=
预
测
正
确
的
样
本
数
量
所
有
样
本
总
数
准确率 = \\frac 预测正确的样本数量 所有样本总数
准确率=所有样本总数预测正确的样本数量
print("没有使用样本均衡的模型准确率: ".format(svc_none_class_weight.score(X, y)))
print("使用样本均衡后的模型准确率: ".format(svc_with_class_weight.score(X, y)))
# 没有使用样本均衡的模型准确率: 0.9490909090909091
# 使用样本均衡后的模型准确率: 0.8836363636363637
# 这里的样本是不均衡的,所以这个指标的意义不大
指标2精确度
精确度(precesion):也叫做查准率,表示少数类的预测准确率,也就是被预测为少数类的样本中,真正的少数类的占比,计算公式如下:
精
确
度
=
预
测
为
少
数
类
中
真
正
的
少
数
类
的
总
数
预
测
样
本
为
少
数
类
的
总
数
精确度 = \\frac 预测为少数类中真正的少数类的总数 预测样本为少数类的总数
精确度=预测样本为少数类的总数预测为少数类中真正的少数类的总数
精确度越高,表述捕获少数类的能力越高,反之表示误伤了过多的多数类,精确度是多数类判错后需要付出代价的一个重要衡量指标,精确度越低,代价越高
pn_score = (y[y == svc_none_class_weight.predict(X)] == 1).sum() / (svc_none_class_weight.predict(X) == 1).sum()
print("没有使用样本均衡的模型精确度: ".format(pn_score))
pw_score = (y[y == svc_with_class_weight.predict(X)] == 1).sum() / (svc_with_class_weight.predict(X) == 1).sum()
print("使用样本均衡的模型精确度: ".format(pw_score))
# 没有使用样本均衡的模型精确度: 0.7619047619047619
# 使用样本均衡的模型精确度: 0.4326923076923077
这里的结果采用了样本均衡后精确度降低了,是因为模型将大量的多数类判断为了少数类, 虽然能有更多的少数类被识别出来,但是伴随的是大量多数类的牺牲,让分母的数值变得比较大, 最终导致了精确度降低,生活中的取舍需要看我们的需求是追求高精确度,还是低代价。
指标3召回率
召回率:也叫做查全率,敏感度等,表示的是少数类被预测正确的样本在少数类的占比,召回率越高表明捕获到的少数类越多,召回率是越高越好,召回率的计算公式如下:
召
回
率
=
少
数
类
被
预
测
准
确
的
样
本
数
少
数
类
的
样
本
总
数
召回率 = \\frac 少数类被预测准确的样本数 少数类的样本总数
召回率=少数类的样本总数少数类被预测准确的样本数
召回率和精确度是此消彼长的,两者之间的平衡代表了捕捉少数类的能力和尽量不误伤多数类之间的平衡
rn_score = (y[y == svc_none_class_weight.predict(X)] == 1).sum() / (y == 1).sum()
print("没有使用样本均衡的模型召回率: ".format(rn_score))
rw_score = (y[y == svc_with_class_weight.predict(X)] == 1).sum() / (y == 1).sum()
print("使用样本均衡的模型召回率: ".format(rw_score))
# 没有使用样本均衡的模型召回率: 0.64
# 使用样本均衡的模型召回率: 0.9
指标4F1-measure
F1-measure:为了同时兼顾召回率和精确度,用召回率和精确度的调和平均来衡量两者之间的平衡 F1-measure是在0-1之间的数,且越靠近1越好, 较高的F1保证了召回率和精确度都较高, F1-measure的计算公式如下:
F
1
−
m
e
a
s
u
r
e
=
2
1
p
+
1
r
=
2
∗
p
∗
r
p
+
r
F1-measure = \\frac 2 \\frac1p + \\frac1r = \\frac 2 * p * r p + r
F1−measure=p1+r12=p+r2∗p∗r
其中p表示精确度,r表示召回率
f1n_score = (2 * pn_score * rn_score) / (pn_score + rn_score)
print("没有使用样本均衡的模型F1指标: ".format(f1n_score))
f1w_score = (2 * pw_score * rw_score) / (pw_score + rw_score)
print("没有使用样本均衡的模型F1指标:".format(f1w_score))
# 没有使用样本均衡的模型F1指标: 0.6956521739130435
# 使用样本均衡的模型F1指标:0.5844155844155844
指标5假负率
假负率:用来衡量少数类中被判错为多数类的占比,假负率 = 1 - 召回率
指标6特异度
特异度:表示所有多数类中被正确预测的样本占多数类的比例,计算公式如下:
多
数
类
被
预
测
正
确
的
样
本
数
多
数
类
的
样
本
总
数
\\frac 多数类被预测正确的样本数 多数类的样本总数
多数类的样本总数多数类被预测正确的样本数
sn_score = (y[y == svc_none_class_weight.predict(X)] == 0).sum() / (y == 0).sum()
print("没有使用样本均衡的模型特异度:".format(sn_score))
sw_score = (y[y == svc_with_class_weight.predict(X)] == 0).sum() / (y == 0).sum()
print("没有使用样本均衡的模型特异度:".format(sw_score))
# 没有使用样本均衡的模型特异度:0.98
# 没有使用样本均衡的模型特异度:0.882
指标7假正率
假正率:衡量一个模型将多数类判错的能力,假正率 = 1 - 特异度
sklearn中的混淆矩阵
sklearn中提供了大量的类来帮助我们使用混淆矩阵和计算模型的评估指标
| 含义 | |
|---|---|
| sklearn.metrics.confusion_matrix | 混淆矩阵 |
| sklearn.metrics.accuracy_score | 准确率 |
| sklearn.metrics.precision_score | 精确度 |
| sklearn.metrics.recall_score | 召回率 |
| sklearn.metrics.f1_score | f1-measure |
以上是关于机器学习sklearn----支持向量机SVC模型评估指标的主要内容,如果未能解决你的问题,请参考以下文章