“数据中台读写分离表分区”解决MySQL 单表数据量并放量双高的效率瓶颈
Posted 瀚岳-诸葛弩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了“数据中台读写分离表分区”解决MySQL 单表数据量并放量双高的效率瓶颈相关的知识,希望对你有一定的参考价值。
需求情景:现有一数据库表,用于记录每一台设备的各种指标项数据,每台设备指标项约150个左右,共有10台设备(后期还会增加),每台设备每2秒写入1次数据,即:数据库单表每秒写入数据量=10台设备*150个指标项数据/2 = 750 写/秒 的并发。单日写数据量高达6,480万。在单台数据库服务器的情况下肯定并发卡死,更不用谈查询效率。
解决方案:
- 在数据采集端,将每台设备每次需要采集的数据做成json字符串,而不是每个指标项都做一次插入,如下图所示:
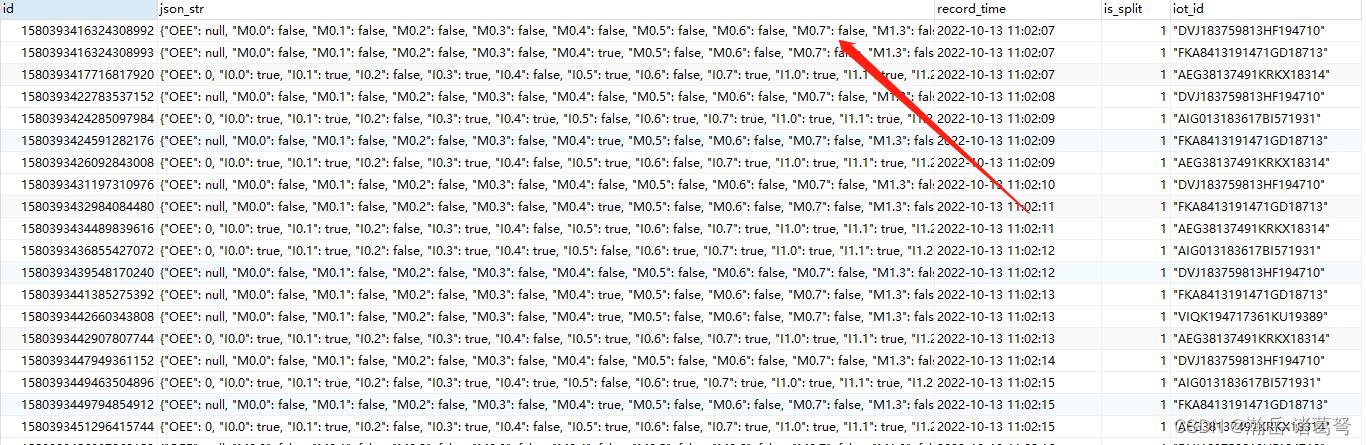
这是一个很重要的改动,网上有很多说法,类似“数据中台”之类的,就是专门有个地方以串行方式接收数据,保证数据不掉。这里用的不是数据中台的全部,只是用了其部分思想。如此,每台设备每次传输的数据,不管有多少,在程序采集端就构建为一条json字符串。10台设备现在每2秒传一次的写并发现在为:10/2 = 5写/秒,相较于750写/秒的并发,大大减少。单日写入数据为:43.2万,记录从数量上看减少150倍。
- 库表结构设计
为保障写表效率,尽量不做索引。数据库表结构如下:

表结构说明:
is_split的作用是用于程序级实现数据的转移,后面做读表的时候有用。

这里,为了保证写效率,只对主键建立了索引,其实,这个索引不建立都没有什么问题。
- 读、写分离设计
此处的读写分离不是真正意义上的读写分离,没有用到rose等专用软件来做。就是通过定时事物进行数据的批量写完成。
如上图所示,device_data数据定时写入device_data_read表中。存储过程如下所示:
CREATE DEFINER=`root`@`%` PROCEDURE `DW_division`()
begin
declare temp_latest_id bigint(50);
select id into temp_latest_id from device_data order by id desc limit 1;-- 通过雪花id找到所要处理的数据的锚点。
insert into device_data_read(id,json_str,record_time,is_split,iot_id)
select id,json_str,record_time,1,json_extract(json_str,'$.iotid') from device_data where iot_id is null and id<=temp_latest_id;
update device_data set is_split=1, iot_id=json_extract(json_str,'$.iotid') where iot_id is null and id<=temp_latest_id;
end之前用雪花id的作用在此处就体现出来了,可以通过有序的数字类型,快速锚定数据点。这里做了两步操作:
- 将数据批量写入读表,通过insert into ... select ...方式批量写入数据库表效率很高;
- 如果采集程序是自己写的,后面的json_extract都可以不用,可以进一步提高程序效率,由于采集程序是第三方完成,所以这里的效率还是受到一定影响;
- 做完后,将is_split标记设置为1,避免停电、宕机后不知道程序做到哪了的情况。
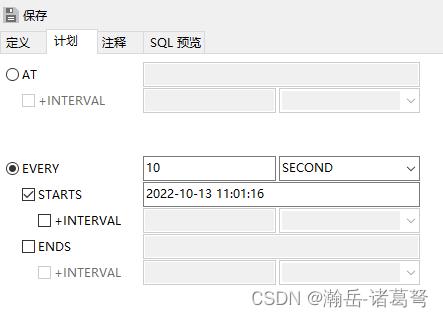
定时调用存储过程,由于对查询的效率实施性要求并不是那么高,此处的数据传输方案是10秒1次,建立一个定时任务即可。如下图:
- 读表的处理(索引+动态表分区)
读表在结构上与写表完全一致,但在索引建立上,可以根据自身查询需要建立多个索引字段。
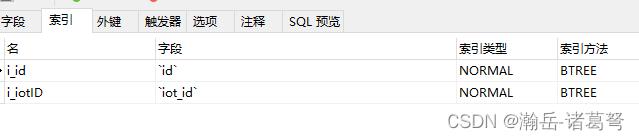
如上图所示,读表增加了1个索引。
考虑到单表单日数据还是有43.2万,在超过千万数据的情况下,查询无论如何都会非常慢。此时,通过引入表分区和动态表分区(通过定时任务,每天调用一次表分区函数)思想,将每日数据做成一个表分区,即可较好地解决实时查询问题。如下图:

建立动态表分区时有几个需要注意的地方:
- 用于分割表分区的字段需要是整形,或者能够通过函数转化为整形的字段,如上图,本人通过日期进行分割,那么:就需要通过to_days函数将当前日期转为整形。
- 通过navicat进行表分区设计,只能实现静态的表分区,想要每天做一个分区,需要根据自身业务需求编写动态增加表分区的代码,其实:核心代码只有一条:
alter table device_data_read add partition(partition 分区名 values less than (to_days('分区值')))基于上述代码,构建存储过程如下:
CREATE DEFINER=`root`@`%` PROCEDURE `auto_table_division`()
begin
declare tempTimeStr varchar(40);
declare parName varchar(40);
declare sqlstr varchar(2000);
set tempTimeStr = date_format(NOW(),'%Y%m%d');
set parName = CONCAT("p",tempTimeStr);
set sqlstr = "alter table device_data_read add partition(partition 分区名 values less than (to_days('分区值')))";
set sqlstr = replace(sqlstr,'分区名',parName);
set sqlstr = replace(sqlstr,'分区值',now());
set @sqlstrPara = sqlstr;
select @sqlstrPara;
prepare sqlsentence from @sqlstrPara;
execute sqlsentence;
DEALLOCATE prepare sqlsentence;
end业务逻辑比较简单,代码不详述。
- 建立时间,每天凌成0点0分调用1次即可完成动态表分区的建立工作。
- 经过上述调整,性能有非常明显的改善,业务逻辑存储过程在40万左右记录下,执行效率可保证在1秒以内:

SCADA实现了实施高效展示(最大延时10秒)
以上是关于“数据中台读写分离表分区”解决MySQL 单表数据量并放量双高的效率瓶颈的主要内容,如果未能解决你的问题,请参考以下文章