Trie树(字典树)实现词频统计或前缀匹配类型的问题
Posted Sup_Heaven
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Trie树(字典树)实现词频统计或前缀匹配类型的问题相关的知识,希望对你有一定的参考价值。
一、概念
如果我们有and,as,at,cn,com这些关键词,那么trie树(字典树)是这样的:
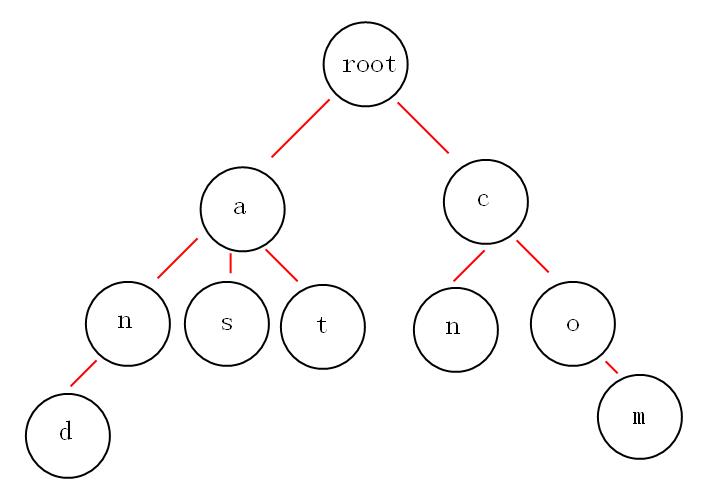
从上面的图中,我们或多或少的可以发现一些好玩的特性。
第一:根节点不包含字符,除根节点外的每一个子节点都包含一个字符。
第二:从根节点到某一节点,路径上经过的字符连接起来,就是该节点对应的字符串。
第三:每个单词的公共前缀作为一个字符节点保存。
二、使用范围
既然学Trie树,我们肯定要知道这玩意是用来干嘛的。
第一:词频统计。
可能有人要说了,词频统计简单啊,一个hash或者一个堆就可以打完收工,但问题来了,如果内存有限呢?还能这么
玩吗?所以这里我们就可以用trie树来压缩下空间,因为公共前缀都是用一个节点保存的。
第二: 前缀匹配
就拿上面的图来说吧,如果我想获取所有以"a"开头的字符串,从图中可以很明显的看到是:and,as,at,如果不用trie树,
你该怎么做呢?很显然朴素的做法时间复杂度为O(N2) ,那么用Trie树就不一样了,它可以做到h,h为你检索单词的长度,
可以说这是秒杀的效果。
三、Trie关键实现
1、结构体
//trie树结构体
struct Trie
Trie *next[26];
bool isWord;
Root;
//插入操作(也是构建Trie树)
void insert(char *tar)
Trie* head = &Root;
int id;
while(*tar)
id = *tar - 'a';
if(head->next[id] == NULL)
head->next[id] = new Trie();
head = head->next[id];
tar++;
head->isWord = true;
3、查找操作
//查找
bool search(char *tar)
Trie* head = &Root;
int id;
while(*tar)
id = *tar - 'a';
if(head->next[id] == NULL)
return false;
head = head->next[id];
tar++;
if(head->isWord)
return true;
else
return false;
四、解题应用
poj2503题,大概的意思是给定两种语言A,B的中单词的对应关系,然后告诉你B的一个单词,让你输出在A中的单词,直观的理解比如就是告诉你英文tree,让你输出中文“树”,自己根据上面的思想,适当改变结构体,C实现的代码如下:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
typedef struct NodeType
struct NodeType* child[26];
char word[11];
int isWord;
Node;
void insertWord(Node* node,char* wo,char* wt)
int id;
while(*wt)
id=*wt-'a';
if(node->child[id]==NULL)
node->child[id]=(Node*)malloc(sizeof(Node));
(node->child[id])->isWord=0;
for(int i=0;i<26;i++)
node->child[id]->child[i]=NULL;
node=node->child[id];
wt++;
node->isWord=1;
strcpy(node->word,wo);
char* searchWord(Node* node,char* wd)
char noWord[5]="eh";
int id;
while(*wd)
id=*wd-'a';
if(node->child[id]==NULL)
return noWord;
node=node->child[id];
wd++;
if(node->isWord)
return node->word;
else
return noWord;
int main()
int i,j;
char wo[11],wt[11],wd[25];
Node* node=(Node*)malloc(sizeof(Node));
node->isWord=0;
for(i=0;i<26;i++)
node->child[i]=NULL;
while(gets(wd) && wd[0] != 0)
for(i=0;wd[i]!=' ';i++)
wo[i] = wd[i];
wo[i] = 0;
for(++i,j=0; wd[i]; i++,j++)
wt[j] = wd[i];
wt[j] = 0;
insertWord(node,wo,wt);
while(scanf("%s",wd)!=EOF)
char* word=searchWord(node,wd);
printf("%s\\n",word);
return 0;
为了提高Java的水平,又用Java写了一遍,但Java中数据的输入我改了一下,先输入n对单词对,再输入m个查询单词,,因为实在不知道Java里面读取的是空行和不断读取的格式到底是怎么样的,反正重要的是思想,Java代码如下:
package com.lxq.poj2503;
import java.util.Scanner;
public class Main
public static void main(String[] args)
int n,m;
String lan=null,forgn = null,word=null;
Scanner sc=new Scanner(System.in);
n=sc.nextInt();
Node node=new Node();
for(int i=0;i<n;i++)
lan=sc.next();
forgn=sc.next();
insertWord(node,lan,forgn);
m=sc.nextInt();
for(int i=0;i<m;i++)
word=sc.next();
System.out.println(searchWord(node,word));
private static String searchWord(Node node, String word)
for(int i=0;i<word.length();i++)
int id=word.charAt(i)-'a';
if(node.child[id]==null)
return "eh";
node=node.child[id];
if(node.isWord)
return node.word;
else
return "eh";
private static void insertWord(Node node, String lan, String forgn)
for(int i=0;i<forgn.length();i++)
int id=forgn.charAt(i)-'a';
if(node.child[id]==null)
node.child[id]=new Node();
node=node.child[id];
node.isWord=true;
node.word=lan;
class Node
Node[] child=new Node[26];
String word;
boolean isWord;
public Node()
for(int i=0;i<26;i++)
child[i]=null;
isWord=false;
以上是关于Trie树(字典树)实现词频统计或前缀匹配类型的问题的主要内容,如果未能解决你的问题,请参考以下文章