最详细Java---HashMap 与 Hashtable 的区别?
Posted AnWen~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最详细Java---HashMap 与 Hashtable 的区别?相关的知识,希望对你有一定的参考价值。
-
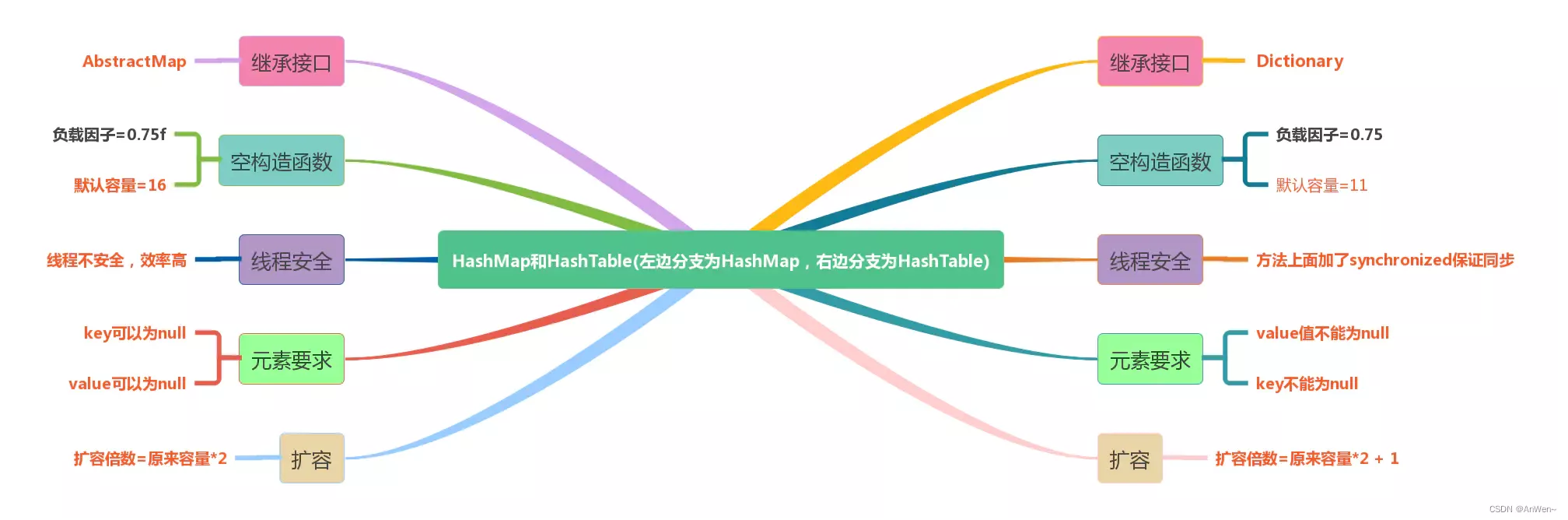
HashMap产生于JDK1.2,HashTable产生于JDK1.1
Hashtable继承自Dictionary类,而HashMap继承自AbstractMap类。二者都实现了Map接口。
- Dictionary就是为了记录键值的一一对应关系,已经过时
- Map将Key映射到Value对象,这个就是为了取代Dictionary抽象类
-
Null Key && Null Value
-
HashMap允许是支持null键和null值的,允许一个null键和多个null值
-
HashTable不允许null键值,在遇到null时,会抛出NullPointerException异常。
-
HashMap在实现时对null做了特殊处理,将null的hashCode值定为了0,从而将其存放在哈希表的第0个bucket中。
static final int hash(Object key) int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
-
-
数据结构
- HashMap和HashTable都使用哈希表来存储键值对。在数据结构上是基本相同的,都创建了一个**继承自Map.Entry的私有的内部类Entry,每一个Entry对象表示存储在哈希表中的一个键值对**
- Node和Entry封装内容差不多,只是名字不同。HashMap采用Node。HashTable采用Entry
- HashMap/HashTable内部创建**有一个Entry类型的引用数组**,用来表示哈希表,数组的长度,即是哈希桶的数量。
- 而数组的每一个元素都是一个Entry引用,从Entry对象的属性里,也可以看出其是链表的节点,每一个Entry对象内部又含有另一个Entry对象的引用。
- jdk1.8 中,哈希表存储采用数组+链表+红黑树实现,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
-
线程安全性
- HashMap是非synchronized的,而Hashtable是synchronized的。这说明Hashtable是线程安全的,而且多个线程可以共享一个Hashtable;
- 因为
Hashtable内部的方法基本都经过synchronized修饰。(如果你要保证线程安全的话就使用ConcurrentHashMap(采用CAS---乐观锁和Synchronized---悲观锁),只锁住当前桶吧!);
-
hash不同
-
HashMap添加元素时,是使用自定义的哈希算法,而HashTable是直接采用key的hashCode()
-
HashTable 计算hash,直接用key的hashCode(),再取模,取模运算效率不高
-
HashMap,先得到hashCode,在高位计算,最后使用优化的取模运算
-
这个方法非常巧妙,它通过**h & (table.length -1)来得到该对象的保存位,而HashMap底层数组的长度总是2的n次方,这是HashMap在速度上的优化。当length总是2的n次方时**,h& (length-1)运算等价于对length取模,也就是h%length,但是&比%具有更高的效率。
-
在JDK1.8的实现中,优化了高位运算的算法,通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的,这么做可以在数组table的length比较小的时候,也能保证考虑到高低Bit都参与到Hash的计算中,同时不会有太大的开销
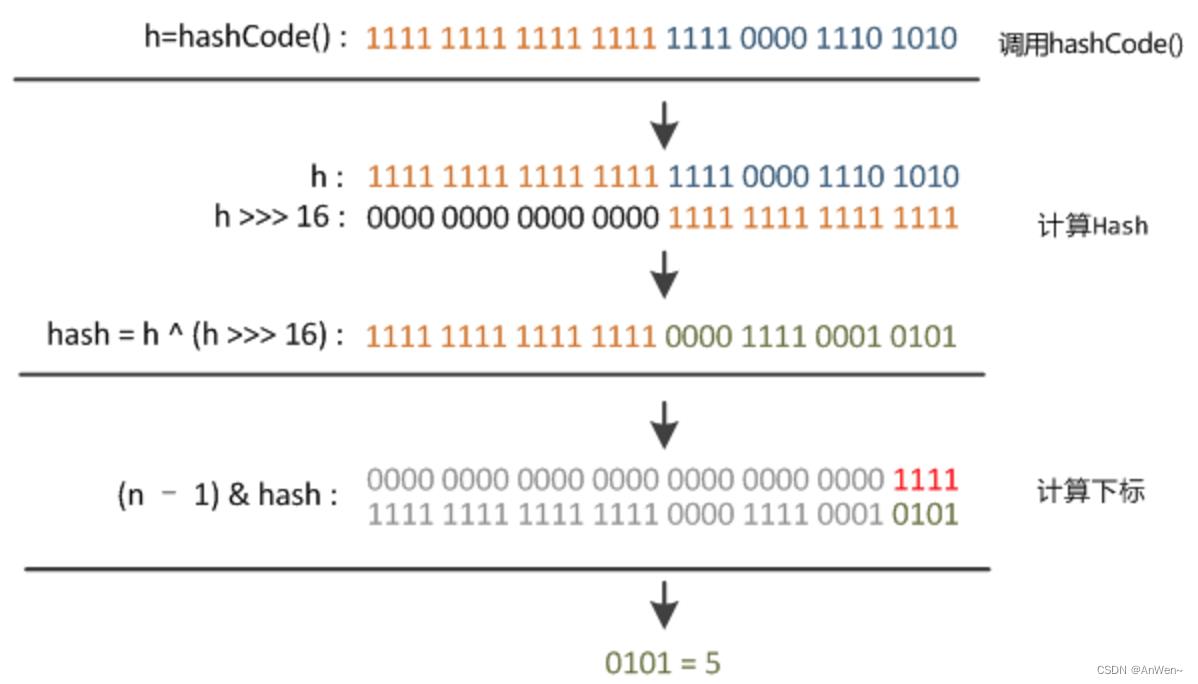
int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; // &0x7FFFFFFF的目的是为了将负的hash值转化为正值,因为hash值有可能为负数,而&0x7FFFFFFF后,只有符号外改变,而后面的位都不变。 ====================HashMap============ static final int hash(Object key) int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); i = (n - 1) & hash
-
-
初始化
- HashTable在不指定容量的情况下的默认容量为11,而HashMap为16
- Hashtable不要求**底层数组的容量一定要为2的整数次幂,而HashMap则要求一定为2的整数次幂**。
- 创建时如果不指定容量初始值,
Hashtable默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1。 HashMap默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。- 创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而
HashMap会将其扩充为 2 的幂次方大小(HashMap中的tableSizeFor()方法保证,下面给出了源代码)。 - 也就是说
HashMap总是使用 2 的幂作为哈希表的大小,后面会介绍到为什么是 2 的幂次方。
-
遍历方式
- HashMap只支持Iterator遍历
- HashTable支持Iterator和Enumeration两种方式遍历
-
迭代器不同
- HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的迭代器(enumerator)却不是fail-fast的。
- 所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。而Hashtable 则不会。
-
contains方法
- HashMap把Hashtable的contains方法改成containsValue和containsKey;
- Hashtable则保留了contains,containsValue和containsKey三个方法,其中contains和containsValue功能相同。
-
同步性
- Hashtable是同步(synchronized)的,适用于多线程环境,
- hashmap不是同步的,适用于单线程环境。
- 多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。
- **由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。**如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
-
效率
- 因为线程安全的问题,
HashMap要比Hashtable效率高一点。 - 另外,
Hashtable基本被淘汰,不要在代码中使用它;
- 因为线程安全的问题,
以上是关于最详细Java---HashMap 与 Hashtable 的区别?的主要内容,如果未能解决你的问题,请参考以下文章