Kafka: 异常知其所以然
Posted dinl_vin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka: 异常知其所以然相关的知识,希望对你有一定的参考价值。
1. kafka Producer内存不足
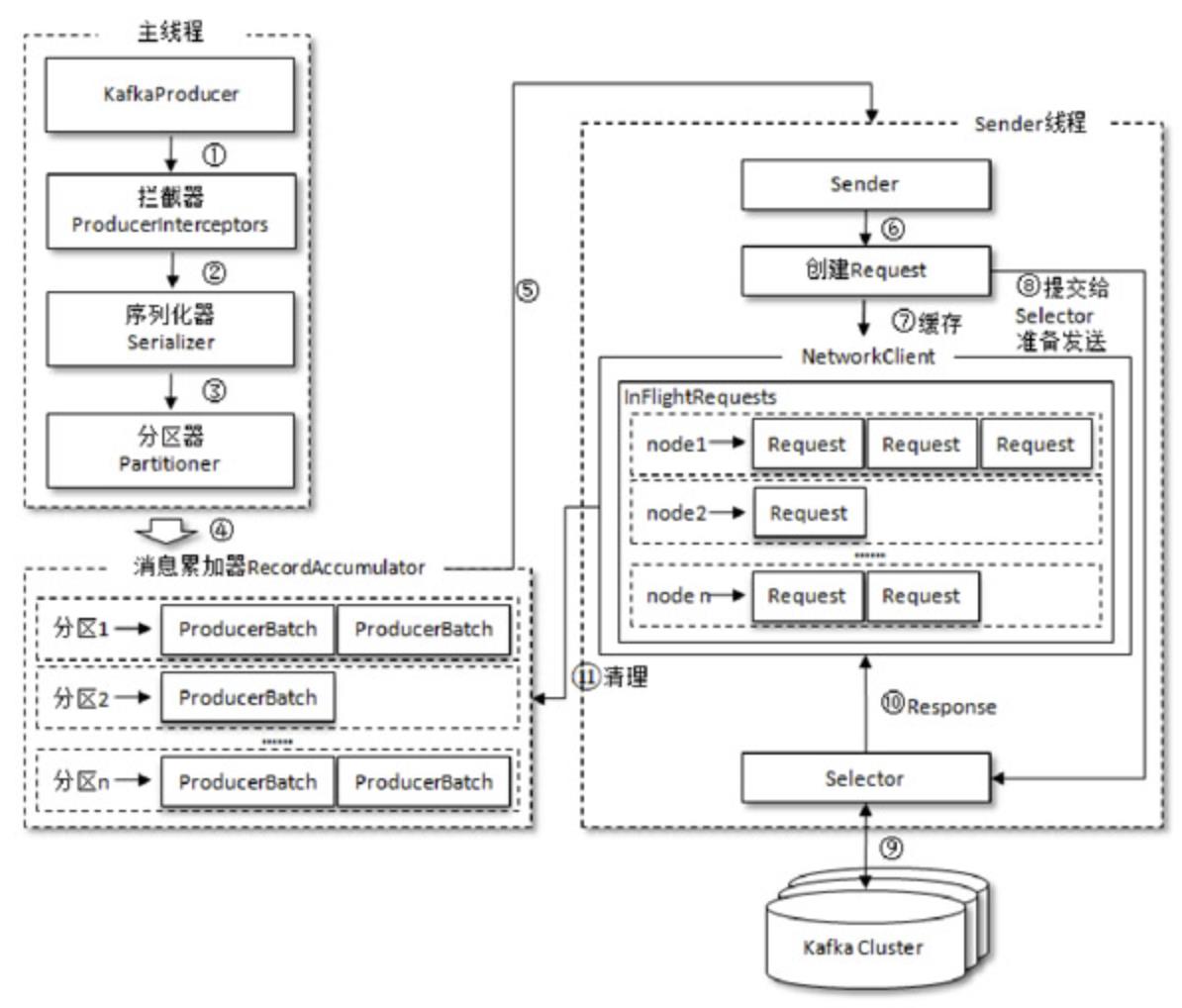
生产者客户端由两个线程协调运行:主线程和Sender线程(发送线程);
主线程由KafkaProducer创建消息,通过拦截器序列化器跟分区器之后缓存到消息累加器(RecordAccumulator),然后通过Sender线程批量发送。这个缓存大小由生产者客户端buffer.memory配置,默认值为32MB,一次发送的间隔时间由max.block.ms配置,此参数的默认值为60000ms,即60s。
在上述两个配置均为默认配置的时候,如果发送端的消息每分钟大小超过32MB,这个时候KafkaProducer的send()方法要么被阻塞,要么抛出异常。
2. kafka数据丢失的几种可能
1)生产者没有指定重试次数(默认的重试次数是0),发生了一些可重试的Exception。
常见的可重试Exception包括:
-
NetworkException: 表示网络异常,有可能是瞬时的网络故障,重试可以恢复;
-
LeaderNotAvaliableException: leader副本不可用,有可能老的leader副本下线,新的leader副本正在选举,也是重试可恢复的。
-
UnknownTopicOrPartitionException: 虽然topic和分区是会自动创建的,创建分区不是一个瞬时的操作,这个过程是需要一定时间的,在此期间内发送的Record有可能会抛出此异常,该异常同样可以通过retry解决。
-
NotEnoughReplicasException: 因为min.insync.replicas>可用的replica数,这个异常也可以重试,直到Replica Map中有可用的副本接受消息并返回。
-
NotCoordinatorException: 收到的事务ID与协调器不一致的时候会抛出此异常。
-
TimeoutException:Request timeout的时候会抛出此异常,参数是
request.timeout.ms,注意这个参数需要比服务器端的request.timeout.ms要大,这样可以减少因为重试造成的消息重复。
Producer端的重试参数
prop.put(ProducerConfig.RETRIES_CONFIG, 10); //重试10次
prop.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, Duration.ofMinutes(3).toMillis()); //3min重试一次,默认为60s
2) acks配置不正确
acks是用来指定kafka中必须有多少个副本收到这条消息,生产者才会认为这条消息成功写入,它涉及到权衡吞吐性跟可靠性,一般来说acks的值越大,可靠性越大,但是吞吐性能会随之降低.(因为acks中可选all,所以该参数配置的时候用字符串类型)
- acks = 1(默认):
生产者发送消息之后,只要分区的leader副本成功写入消息,那么它就会收到来自服务端的成功响应。如果消息无法写入leader副本,比如在leader 副本崩溃、重新选举新的leader 副本的过程中,那么生产者就会收到一个错误的响应,如果没有重试机制,在写入下一个leaader副本时失败了就会缺数据.(前面回复ack的leader副本在后面一次选举中没有当选leader)
- acks=0
我发我的,不管你收没收到,因为没法得知服务器的响应,如果在写入过程中出现了什么异常,消息就丢失了.
- acks=-1 或 acks=all
这个是最强可靠性的保证,所有replica收到ack才算写入成功.
以上是关于Kafka: 异常知其所以然的主要内容,如果未能解决你的问题,请参考以下文章