Prometheus+Grafana (史上最全)
Posted 架构师-尼恩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Prometheus+Grafana (史上最全)相关的知识,希望对你有一定的参考价值。
尼恩大架构 最强环境 系列文章
一键打造 本地elk 实操环境:
ELK日志平台(elasticsearch +logstash+kibana)原理和实操(史上最全)
高级开发必备,架构师必备
一键打造 本地Prometheus+Grafana 实操环境:
高级开发必备,架构师必备
一键打造 本地centos 虚拟机环境:
地表最强 开发环境: vagrant+java+springcloud+redis+zookeeper镜像下载(&制作详解)
高级开发必备,架构师必备
尼恩大架构的 精彩文章大汇总:
什么是性能可观测

可观测性包括 Metrics、Traces、Logs 3 个维度。可观测能力帮助我们在复杂的分布式系统中快速排查、定位问题,是分布式系统中必不可少的运维工具。
在性能压测领域中,可观测能力更为重要,除了有助于定位性能问题,其中Metrics性能指标更直接决定了压测是否通过,对系统上线有决定性左右,具体如下:
• Metrics,监控指标
系统性能指标,包括请求成功率、系统吞吐量、响应时长
资源性能指标,衡量系统软硬件资源使用情况,配合系统性能指标,观察系统资源水位
• Logs,日志
施压引擎日志,观察施压引擎是否健康,压测脚本执行是否有报错
采样日志,采样记录 API 的请求和响应详情,辅助排查压测过程中的一些出错请求的参数是否正常,并通过响应详情,查看完整的错误信息
• Traces,分布式链路追踪用于性能问题诊断阶段,通过追踪请求在系统中的调用链路,
定位报错 API 的报错系统和报错堆栈,快速定位性能问题点
本篇阐述如何使用 Prometheus 实现性能压测 Metrics 的可观测性。
系统监控的核心指标
系统性能指标
压测监控最重要的 3 个指标:请求成功率、服务吞吐量(TPS)、请求响应时长(RT),这 3 个指标任意一个出现拐点,都可以认为系统已达到性能瓶颈。
这里特别说明下响应时长,对于这个指标,用平均值来判断很有误导性,因为一个系统的响应时长并不是平均分布的,往往会出现长尾现象,表现为一部分用户请求的响应时间特别长,但整体平均响应时间符合预期,这样其实是影响了一部分用户的体验,不应该判断为测试通过。因此对于响应时长,常用 99、95、90 分位值来判断系统响应时长是否达标。
另外,如果需要观察请求响应时长的分布细节,可以补充请求建联时长(Connect Time)、等待响应时长(Idle Time)等指标。
资源性能指标
压测过程中,对系统硬件、中间件、数据库资源的监控也很重要,包括但不限于:
• CPU 使用率
• 内存使用率
• 磁盘吞吐量
• 网络吞吐量
• 数据库连接数
• 缓存命中率
… …
压测施压机性能指标
压测链路中,施压机性能是容易被忽略的一环,为了保证施压机不是整个压测链路的性能瓶颈,需要关注如下施压机性能指标:
• 压测进程的内存使用量
• 施压机 CPU 使用率,Load1、Load5 负载指标
• 基于 JVM 的压测引擎,需要关注垃圾回收次数、垃圾回收时长
什么是 Load1、Load5 负载指标?
在Linux机器上,有多个命令都可以查看机器的负载信息。其中包括uptime、top、w等。
uptime命令
uptime命令能够打印系统总共运行了多长时间和系统的平均负载。
uptime命令可以显示的信息显示依次为:现在时间、系统已经运行了多长时间、目前有多少登陆用户、系统在过去的1分钟、5分钟和15分钟内的平均负载。
[root@cdh1 ~]# uptime
17:35:43 up 0 min, 2 users, load average: 4.10, 0.92, 0.30
[root@cdh1 ~]# uptime
17:35:43 up 23:41, 3 users, load averages: 1.74 1.87 1.97
这行信息的后半部分,显示”load average”,它的意思是”系统的平均负荷”,
里面有三个数字,我们可以从中判断系统负荷是大还是小。1.74 1.87 1.97 这三个数字的意思分别是1分钟、5分钟、15分钟内系统的平均负荷。我们一般表示为load1、load5、load15。
一般情况下,大家最好根据自己机器的实际情况,建立一个指标的基线(如近一个月的平均值),只要日常的load在基线上下范围内不太大都可以接收,如果差距太多可能就要人为介入检查了。
大部分情况下的建议的值:
当系统负荷持续大于0.75,你必须开始调查了,问题出在哪里,防止情况恶化。
当系统负荷持续大于1.0,你必须动手寻找解决办法,把这个值降下来。
当系统负荷达到5.0,就表明你的系统有很严重的问题,长时间没有响应,或者接近死机了。你不应该让系统达到这个值。
以上指标都是基于单CPU的,但是现在很多电脑都是多核的。所以,对一般的系统来说,是根据cpu数量去判断系统是否已经过载(Over Load)的。如果我们认为0.75算是单核机器负载的安全线的话,那么四核机器的负载最好保持在3(4*0.75 = 3)以下。
还有一点需要提一下,在Load Avg的指标中,有三个值,1分钟系统负荷、5分钟系统负荷,15分钟系统负荷。我们在排查问题的时候也是可以参考这三个值的。
一般情况下,1分钟系统负荷表示最近的暂时现象。15分钟系统负荷表示是持续现象,并非暂时问题。如果load15较高,而load1较低,可以认为情况有所好转。反之,情况可能在恶化。
什么是prometheus
phometheus:当前一套非常流行的开源监控和报警系统。
prometheus的运行原理
通过HTTP协议周期性抓取被监控组件的状态。输出被监控组件信息的HTTP接口称为exporter。
常用组件大部分都有exporter可以直接使用,比如haproxy,nginx,mysql,Linux系统信息(包括磁盘、内存、CPU、网络等待)。
prometheus主要特点
- 一个多维数据模型(时间序列由metrics指标名字和设置key/value键/值的labels构成)。
- 非常高效的存储,平均一个采样数据占~3.5字节左右,320万的时间序列,每30秒采样,保持60天,消耗磁盘大概228G。
- 一种灵活的查询语言(PromQL)。
- 无依赖存储,支持local和remote不同模型。
- 采用http协议,使用pull模式,拉取数据。
- 监控目标,可以采用服务器发现或静态配置的方式。
- 多种模式的图像和仪表板支持,图形化友好。
- 通过中间网关支持推送时间。
什么是 Grafana
虽然 Prometheus 提供的 Web UI 也可以很好的查看不同指标的视图,但是这个功能非常简单,只适合用来调试。要实现一个强大的监控系统,还需要一个能定制展示不同指标的面板,能支持不同类型的展现方式(曲线图、饼状图、热点图、TopN 等),这就是仪表盘(Dashboard)功能。
因此 Prometheus 开发了一套仪表盘系统 PromDash,不过很快这套系统就被废弃了,官方开始推荐使用 Grafana 来对 Prometheus 的指标数据进行可视化,这不仅是因为 Grafana 的功能非常强大,而且它和 Prometheus 可以完美的无缝融合。
Grafana 是一个用于可视化大型测量数据的开源系统,它的功能非常强大,界面也非常漂亮,
使用它可以创建自定义的控制面板,你可以在面板中配置要显示的数据和显示方式,
它 支持很多不同的数据源,比如:Graphite、InfluxDB、OpenTSDB、Elasticsearch、Prometheus 等,而且它也 支持众多的插件。
下面我们就体验下使用 Grafana 来展示 Prometheus 的指标数据。首先我们来安装 Grafana,我们使用最简单的 Docker 安装方式:
$ docker run -d -p 3000:3000 grafana/grafana
运行上面的 docker 命令,Grafana 就安装好了!你也可以采用其他的安装方式,参考 官方的安装文档。安装完成之后,我们访问 http://localhost:3000/ 进入 Grafana 的登陆页面,输入默认的用户名和密码(admin/admin)即可。
第一条战线:Prometheus 如何监控机器?
采用标准的PGOne技术组件Prometheus Server + Grafana + node_exporter完成对机器的性能监控。
第二条战线:Prometheus 如何监控 flink?
采用技术组件client lib(flink-metrics-prometheus_x.jar) + PushGateway + Prometheus Server + Grafana完成对 flink 的监控。
Prometheus的体系结构
下图说明了Prometheus的体系结构及其某些生态系统组件:

Prometheus直接或通过中间推送网关从已检测的作业中删除指标,以处理短暂的作业。它在本地存储所有报废的样本,并对这些数据运行规则,以汇总和记录现有数据中的新时间序列,或生成警报。Grafana或其他API使用者可以用来可视化收集的数据。
Prometheus+Grafana分层架构
从分层的角度来说,Prometheus+Grafana分层架构图如下:

、
Promcthcus体系涉及的组件
Promcthcus负责时序型指标数据的采集及存储,但数据的分析、聚合及直观展示以及告警等功能并非由Prometheus Server所负责。
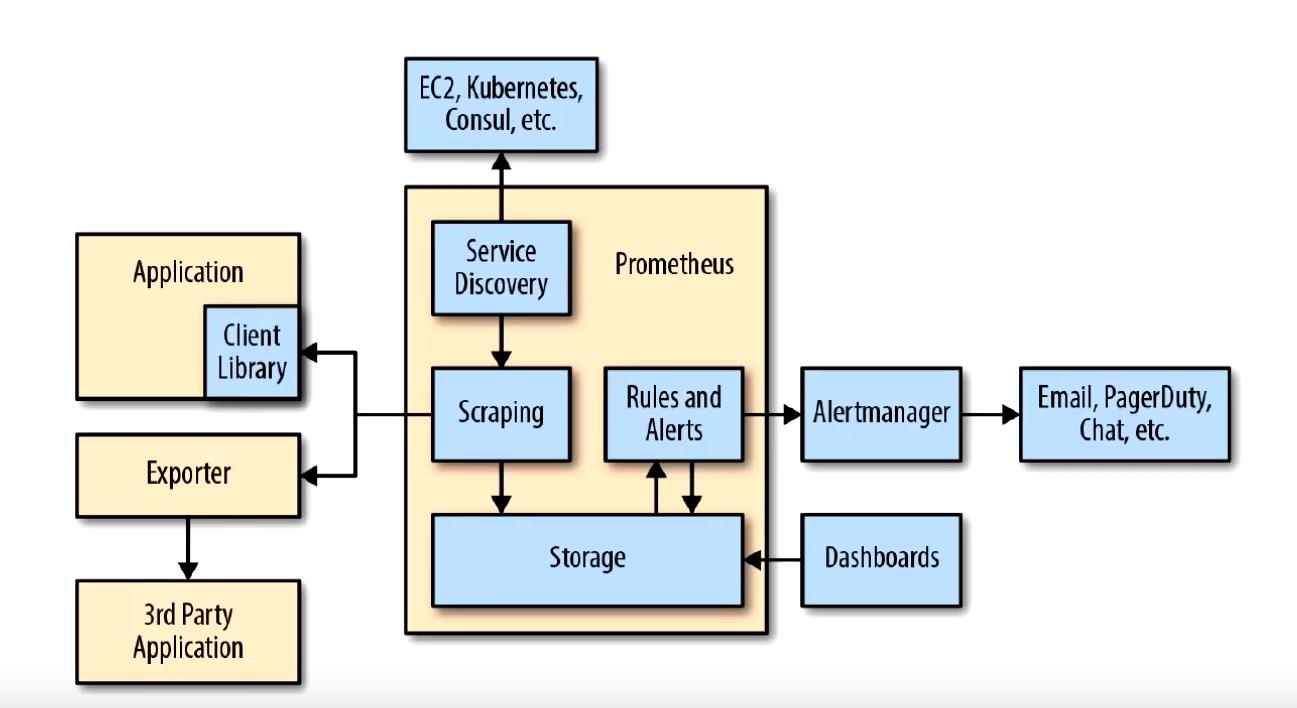
Prometheus生态系统包含多个组件,其中许多是可选的:
- Prometheus server - 收集和存储时间序列数据
- Client Library: 客户端库,为需要监控的服务生成相应的
- metrics 并暴露给 - Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
- pushgateway - 对于短暂运行的任务,负责接收和缓存时间序列数据,同时也是一个数据源
- exporter - 各种专用exporter,面向硬件、存储、数据库、HTTP服务等
- alertmanager - 处理报警
- webUI等,其他各种支持的工具,本身的界面值适合用来语句查询,数据可视化,需要第三方组件,比如Grafana。
如何收集度量值
度量指标由监控系统执行的过程通常可以分为两种方法:推和拉。

Prometheus基于HTTP call,从配置文件中指定的网络端点(endpoint)上周期性获取指标数据。

Prometheus支持通过三种类型的途径从目标上“抓取(Serape)”指标数据:
- Exporters:被监控的目标不支持pro的数据格式,通过exporters抽取指标数据,进行格式化处理成pro兼容的数据格式,再响应给pro server。
- Instrumentation:应用系统内建了pro兼容的指标数据格式,pro server可以直接采集。
- Push gateway:pro采用 pull 模式,可能由于不在一个子网或者防火墙原因,导致 Prometheus 无法直接拉取各个 target 数据。在监控业务数据的时候,需要将不同数据汇总, 由 Prometheus 统一收集。暂存在pushgateway,等待Prometheus server拉取。

指标类型
Promcthcus使用4种方法来描述监视的指标。
计数器
Counter:
计数器,用于保存单调递增型的数据,例如站点访问次数等;不能为负值,也不支持减少,但可以重置回0;
比如网络总访问数。
仪表盘
Gauge:仪表盘,用于存储有着起伏特征的指标数据,例如内存空闲大小等。
Gauge是Counter的超集;但存在指标数据丢失的叮能性时,Counter能让用户确切了解指标随时间的变化状态,而Gauge则可能随时问流逝而精准度越来越低。
比如CPU的使用率:

直方图
在大多数情况下人们都倾向于使用某些量化指标的平均值,例如 CPU的平均使用率、页面的平均响应时间。这种方式的问题很明显,以系统API调用的平均响应时间为例:如果大多数API请求都维持在100ms的响应时间范围内,而个别请求的响应时间需要5s,那么就会导致某些WEB页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。
Histogram常常用于观察,一个Histrogram包含下列值的合并:
- Buckets:桶是观察的计数器。它应该有个最大值的边界和最小值的边界。它的格式为basename> _bucket
- 观察结果的和,这是所有观案的和。针对它的格式是《basename>_sum
- 观察结果统计,这是在本次观察的和。它的格式为《basename>_count
Summary
Summary与Histogram类型类似,用于表示段时间内的数据采集结果(通常是请求持或时间或响应大小),但它直接存储了分位数通过客户端计算,然后展示出来,而不是通过区间来计算。
指标摘要及聚合
指标摘要
通常米说,单个指标对我们价值很小,往往需要联合并可视化多个指标,这其中需要一些数学变换,例如,我们可能会统计函数应用于指标或指标组,一些可能应用常见函数包括:
- 计数:计算特定时间间降内的观索点数,
- 求和:将特定时间间隔内所有观察点的值累计相加。
- 平均值,提供特定时间间隔内所有伯的平均值,
- 中间数:数值的几何中点,正好50%的数值位于它前面,而另外50%则位于它后面,
- 百分位数:度量占总数特定百分比的观察点的值。
- 标准差:显示指标分布中与平均值的标准差,这可以测量出数据集的差异程度。标准差为0表示数据都等于平均值较高的标准兰意味着数据分布的范围很广
- 变化率:显示时间序列中数据之间的变化程度。
指标聚合
除了上述的指标描要外,你可能经常希望能看到来自当个源的指标的聚合图,例如所有应用程序服务器的磁盘空间使用情况。指标聚合最典型的样式就是在一张图上显示多个指标,这有助于你识别环境的发展趋势。
例如,负载均衡器中的问歇性故障可能导致多个服务器的Web流量下降,这通常比通过查看每个单独的指标更容易发现。

一键安装 prometheus
bridge网络管理
不指定网络驱动时默认创建的bridge网络
docker network create monitor-network
查看网络内部信息
docker network inspect monitor-network
列所有列表的网络
docker network ls
移除指定的网络
docker network rm default_network
创建库
注意,数据库提前建好grafana 库:
/usr/bin/mysql -uroot -p123456 --connect-expired-password <<EOF
create database grafana default character set utf8mb4 collate utf8mb4_unicode_ci;
grant all privileges on grafana.* to root@'%' identified by '123456' WITH GRANT OPTION;
flush privileges;
EOF
docker编排文件
version: "3.5"
services:
prometheus:
image: prom/prometheus:v2.30.0
container_name: prometheus
volumes:
- /tmp:/tmp
- ./prometheus.yml:/etc/prometheus/prometheus.yml
command: "--config.file=/etc/prometheus/prometheus.yml --storage.tsdb.path=/prometheus --storage.tsdb.wal-compression --storage.tsdb.retention.time=7d"
hostname: prometheus
ports:
- "9090:9090"
depends_on:
- exporter
networks:
base-env-network:
aliases:
- prometheus
prometheus-nacos-sd:
image: nien/prometheus-nacos-sd:1.0.0
container_name: prometheus-nacos-sd
hostname: prometheus-nacos-sd
volumes:
- /tmp:/tmp
command: "--nacos.address=192.168.56.121:8848 --nacos.namespace=public --output.file=/tmp/nacos_sd_public.json --refresh.interval=600"
networks:
base-env-network:
aliases:
- prometheus-nacos-sd
exporter:
image: prom/node-exporter:v1.2.2
container_name: exporter
hostname: exporter
ports:
- "9100:9100"
networks:
base-env-network:
aliases:
- exporter
# 用于UI展示
# https://grafana.com/docs/grafana/latest/installation/docker
grafana:
image: grafana/grafana:8.1.5
container_name: grafana
hostname: grafana
restart: unless-stopped
ports:
- "3000:3000"
# volumes:
# - "./grafana/grafana-storage:/var/lib/grafana"
# - "./grafana/public:/usr/share/grafana/public" # 这里面可处理汉化包 可参考 https://github.com/WangHL0927/grafana-chinese
# - "./grafana/conf:/usr/share/grafana/conf"
# - "./grafana/log:/var/log/grafana"
# - "/etc/localtime:/etc/localtime"
environment:
GF_EXPLORE_ENABLED: "true"
GF_SECURITY_ADMIN_PASSWORD: "admin"
GF_INSTALL_PLUGINS: "grafana-clock-panel,grafana-simple-json-datasource,alexanderzobnin-zabbix-app"
# 持久化到mysql数据库
GF_DATABASE_URL: "mysql://root:123456@192.168.56.121:3306/grafana" # TODO 修改
depends_on:
- prometheus
networks:
base-env-network:
aliases:
- grafana
# mysql数据库 => 用于grafana持久化数据
# mysql:
# image: nien/mysql:5.7
# container_name: prometheus_mysql
# restart: unless-stopped
# volumes:
# - "./mysql5.7/my.cnf:/etc/mysql/my.cnf"
# - "./mysql5.7/data:/var/lib/mysql"
# - "./mysql5.7/log/mysql/error.log:/var/log/mysql/error.log"
# environment:
# TZ: Asia/Shanghai
# LANG: en_US.UTF-8
# MYSQL_ROOT_PASSWORD: root # 设置root用户密码
# MYSQL_DATABASE: grafana # 初始化数据库grafana
# ports:
# - "3306:3306"
# docker network create base-env-network
networks:
base-env-network:
external:
name: "base-env-network"
一键安装 prometheus的脚本
rm -rf /home/docker-compose/prometheus
cp -rf /vagrant/sit-ware/prometheus /home/docker-compose/
cd /home/docker-compose/
chmod 777 -R prometheus
cd prometheus
docker-compose --compatibility up -d
docker-compose logs -f
docker-compose down
mysql/5.7.31
docker save mysql:5.7.31 -o /vagrant/3G-middleware/mysql.5.7.31.tar
docker save registry.cn-hangzhou.aliyuncs.com/zhengqing/canal-server:v1.1.5 -o /vagrant/3G-middleware/canal-server.v1.1.5.tar
docker save registry.cn-hangzhou.aliyuncs.com/zhengqing/canal-admin:v1.1.5 -o /vagrant/3G-middleware/canal-admin.v1.1.5.tar
进入 prometheus
http://promethus所在的服务器地址:9090
http://cdh1:9090/

点击targets

进入 grafana
grafana 默认密码 admin admin
http://cdh1:3000/explore?left=%5B%22now-1h%22,%22now%22,%22–%20Grafana%20–%22,%7B%7D%5D&orgId=1

啥也没有
Prometheus+Grafana监控SpringBoot项目JVM信息
SpringBoot项目配置JVM采集
(1)maven依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
(2)application.properties
spring.application.name=springboot_jvm
server.port=6001
management.endpoints.web.exposure.include=*
management.metrics.tags.application=$spring.application.name
(3)SpringBoot添加PrometheusMeterRegistry 注册器
@Configuration
public class CustomPrometheusConfig
@Bean
@ConditionalOnMissingBean
public PrometheusMeterRegistry prometheusMeterRegistry(PrometheusConfig prometheusConfig,
CollectorRegistry collectorRegistry, Clock clock)
return new PrometheusMeterRegistry(prometheusConfig, collectorRegistry, clock);
@Bean
@ConditionalOnMissingBean
public CollectorRegistry collectorRegistry()
return new CollectorRegistry(true);
(4)启动springboot项目,访问 可以看到一些统计指标
http://localhost:18081/consumer/actuator/prometheus
http://192.168.56.1:28088/seata-seckill/actuator/prometheus

Prometheus配置
参考末尾的 基于nacos的服务发现
访问地址:
http://cdh1:9090/targets#pool-spring-boot

配置grafana监控Linux系统
使用
node_explorer可以暴露Linux系统的指标信息,然后Prometheus就可以通过定时扫描的方式获取并存储指标信息了。
使用 Exporter 收集指标
目前为止,我们看到的都还只是一些没有实际用途的指标,如果我们要在我们的生产环境真正使用 Prometheus,往往需要关注各种各样的指标,譬如服务器的 CPU负载、内存占用量、IO开销、入网和出网流量等等。
正如上面所说,Prometheus 是使用 Pull 的方式来获取指标数据的,要让 Prometheus 从目标处获得数据,首先必须在目标上安装指标收集的程序,并暴露出 HTTP 接口供 Prometheus 查询,这个指标收集程序被称为 Exporter,不同的指标需要不同的 Exporter 来收集,目前已经有大量的 Exporter 可供使用,几乎囊括了我们常用的各种系统和软件,官网列出了一份 常用 Exporter 的清单,各个 Exporter 都遵循一份端口约定,避免端口冲突,即从 9100 开始依次递增,这里是 完整的 Exporter 端口列表。
另外值得注意的是,有些软件和系统无需安装 Exporter,这是因为他们本身就提供了暴露 Prometheus 格式的指标数据的功能,比如 Kubernetes、Grafana、Etcd、Ceph 等。
这一节就让我们来收集一些有用的数据。
inux直接安装node_exporter
首先我们来收集服务器的指标,这需要安装 node_exporter,这个 exporter 用于收集 *NIX 内核的系统,
如果你的服务器是 Windows,可以使用 WMI exporter。

这次我们直接把安装到Linux服务器上,将下载的安装包解压到指定目录,并修改文件夹名称:
cd /mydata
tar -zxvf node_exporter-1.1.2.linux-amd64.tar.gz
mv node_exporter-1.1.2.linux-amd64 node_exporter
进入解压目录,使用如下命令运行,服务将运行在9100端口上;
cd node_exporter
./node_exporter >log.file 2>&1 &
- 使用
curl命令访问获取指标信息接口,获取到信息表示运行成功;
curl http://localhost:9100/metrics
# HELP promhttp_metric_handler_requests_in_flight Current number of scrapes being served.# TYPE promhttp_metric_handler_requests_in_flight gaugepromhttp_metric_handler_requests_in_flight 1# HELP promhttp_metric_handler_requests_total Total number of scrapes by HTTP status code.# TYPE promhttp_metric_handler_requests_total counterpromhttp_metric_handler_requests_totalcode="200" 2175promhttp_metric_handler_requests_totalcode="500" 0promhttp_metric_handler_requests_totalcode="503" 0
使用Docker容器安装node_exporter
如果使用Docker容器安装,监控的会是Docker容器的指标信息
exporter:
image: prom/node-exporter:v1.2.2
container_name: exporter
hostname: exporter
ports:
- "9100:9100"
networks:
base-env-network:
aliases:
- exporter
注意事项
一般情况下,node_exporter 都是直接运行在要收集指标的服务器上的,官方不推荐用 Docker 来运行 node_exporter。如果逼不得已一定要运行在 Docker 里,要特别注意,这是因为 Docker 的文件系统和网络都有自己的 namespace,收集的数据并不是宿主机真实的指标。可以使用一些变通的方法,比如运行 Docker 时加上下面这样的参数:
docker run -d \\
--net="host" \\
--pid="host" \\
-v "/:/host:ro,rslave" \\
quay.io/prometheus/node-exporter \\
--path.rootfs /host
关于 node_exporter 的更多信息,可以参考 node_exporter 的文档 和 Prometheus 的官方指南 Monitoring Linux host metrics with the Node Exporter,
另外,Julius Volz 的这篇文章 How To Install Prometheus using Docker on Ubuntu 14.04 也是很好的入门材料。
创建一个任务定时扫描暴露的指标信息
接下来修改Prometheus的配置文件,创建一个任务定时扫描暴露的指标信息;
# 采集node exporter监控数据,即linux
- job_name: exporter
static_configs:
- targets: ['exporter:9100']
labels:
instance: exporter
http://exporter:9100/metrics

创建仪表盘grafna
重启Prometheus容器,可以通过加号->Dashboard来创建仪表盘;

https://grafana.com/grafana/dashboards/


导入Dashboard
选择导入Dashboard并输入ID,最后点击Load即可;
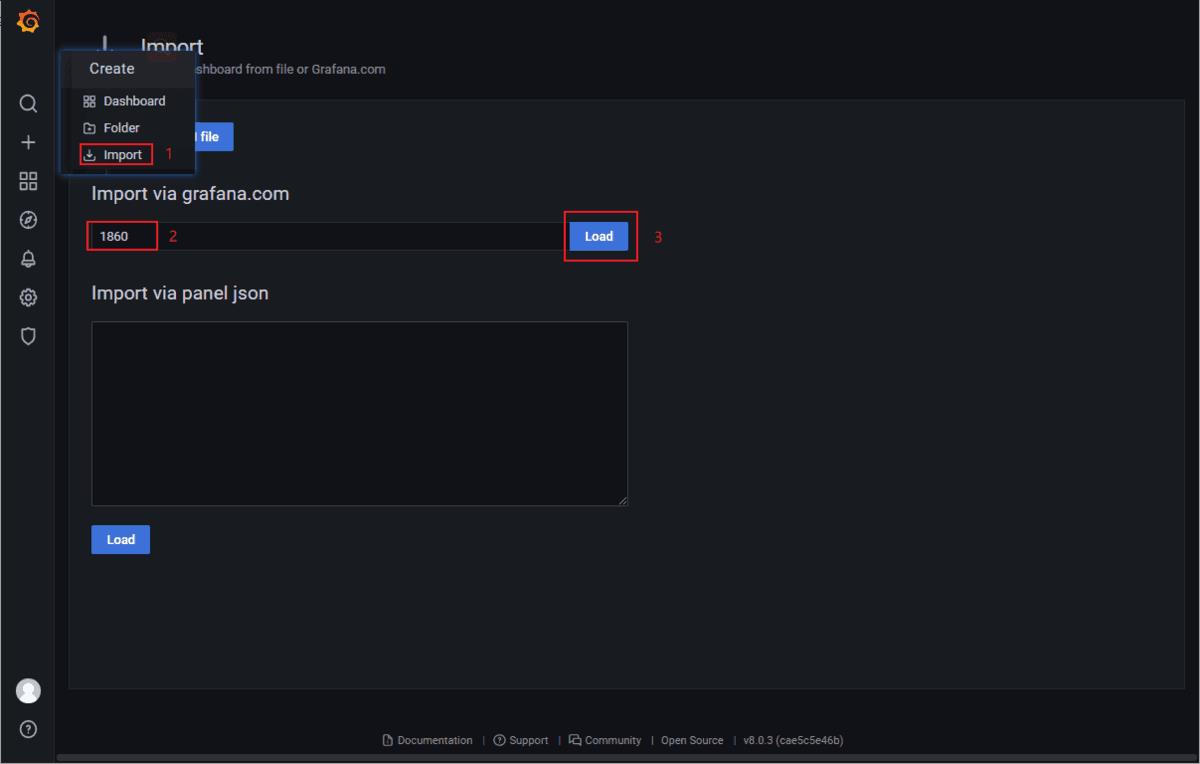
导入之后

选择数据源为Prometheus
选择数据源为Prometheus,最后点击Import;

导入成功后就可以在Grafana中看到实时监控信息了,是不是够炫酷!

配置grafana监控SpringBoot应用
主要步骤
- 通过Prometheus提供的Java client包,在spring boot工程中生成我们关心的业务指标,
- 将spring boot工程打成docker 镜像
- 部署docker容器
- 修改Prometheus对应的
file_sd_configs文件,将部署的服务追加进去 - 通过Grafana观察业务指标
本文主要阐述的是对容器中业务指标的监控,对容器的监控以及环境的搭建参照 一键部署 脚本。
具体步骤,请参见视频
找jvm的 dashboard

JVM Quarkus 面板

14370
导入后的效果如下:

Prometheus数据模型
Prometheus会将所有采集到的样本数据以时间序列(time-series)的方式保存在内存数据库中,并且定时保存到硬盘上。
从根本上,说Prometheus存储的所有数据都是时间序列。
所以说: Prometheus中的数据,都是时间序列值。
time-series 时间序列值
一条 具有时间戳的数据流,只属于单个度量指标和该度量指标下的多个标签维度。
一条 Prometheus 数据,就是一条数据流,由一个指标名称(metric)和 N 个标签(label,N >= 0)组成的,
例如:
http_requests_total 表示系统收到请求总数的时间序列,
同一指标中的每个key/value(称为label)都称作一个维度,如(
http_requests_totalcode=200)代表请求成功的时间序列.
又例如:
promhttp_metric_handler_requests_totalcode="200",instance="192.168.0.107:9090",job="prometheus" 106
这条数据的指标名称为 promhttp_metric_handler_requests_total,并且包含三个标签 code、instance 和 job,这条记录的值为 106。
在springboot应用中,可以通过Prometheus 插件,看到大量的时间序列值,如下图所示

上面说过,Prometheus 是一个时序数据库,相同指标、相同标签的数据,构成一条时间序列。
外部应用通过PromQL来对时间序列进行相应的查找,
在查询时还可以利用Prometheus提供的功能丰富的函数对时间序列中的值进行计算。
每条time-series通过指标名称(metrics name)和一组标签集(labelset)命名。
换句话说:
每个序列通过 指标名称(metrics name)以及一组标签集(labelset)命名唯一确定,
总之,time-series是按照时间戳和值的序列顺序存放的,我们称之为向量(vector)。
Sample样本值
指标名称(metrics name)相同,label相同的记录称为一个样本值,样本形成了实际的时间序列数据。
每个采样值包括:
-
一个64位的浮点值
-
一个精确到毫秒级的时间戳
Prometheus一个时间序列,存的就是各个样本值,在不同时间点的数据
除了存储时间序列数据外,Prometheus还可以生成临时派生的时间序列作为查询的结果。
metrics name指标名称
metric度量指标名称:
指定监控目标系统的测量特征
如:http_requests_total - 接收http请求的总计数。
metric度量指标可能包含ASCII字母、数字、下划线和冒号,
指标名称 必须配正则表达式 [a-zA-Z_:][a-zA-Z0-9_:]* 。
注意:指标名称中的冒号,是保留用于用户定义的录制规则。
它们不应被exporter或直接仪表使用。
label标签
标签开启了Prometheus的多维数据模型:
对于相同的度量名称,通过不同标签列表的结合, 会形成特定的度量维度实例。
例如:
如(http_requests_totalcode=200)代表请求成功的时间序列.
如( /api/tracksmethod=POST) 所有包含度量名称为 /api/tracks 的http请求,打上method=POST的标签,则形成了具体的http请求。
这个查询语言在这些度量和标签列表的基础上进行过滤和聚合。
改变任何度量上的任何标签值,则会形成新的时间序列图。
标签label名称的命名规则:
标签label名称可以包含 ASCII字母、数字和下划线。
它们必须匹配正则表达式 [a-zA-Z_][a-zA-Z0-9_]*。
带有 _ 下划线的标签名称被保留内部使用。
标签labels值包含任意的Unicode码。
Notation(符号)
Notation(符号)表示一个度量指标和一组键值对标签,需要使用以下符号:
[metric name][label name]=[label value], …
例如,度量指标名称是api_http_requests_total, 标签为method="POST", handler="/messages" 的示例如下所示:
api_http_requests_totalmethod=“POST”, handler=“/messages”
这些命名和OpenTSDB使用方法是一样的。
TSDB时序数据库
什么是TSDB?
TSDB(Time Series Database)时序数据库,我们可以简单的理解为一个优化后用来处理时间序列数据的软件,并且数据中的数组是由时间进行索引的。
OpenTSDB is a distributed, scalable Time Series Database (TSDB) written on top of HBase;
基于Hbase的分布式的,可伸缩的时间序列数据库。主要用途,就是做监控系统;譬如收集大规模集群(包括网络设备、操作系统、应用程序)的监控数据并进行存储,查询。
时间序列数据库的特点
1、大部分时间都是写入操作
2、写入操作几乎时顺序添加的,大多数示函到达后都以时间排序。
3、写操作很少写入很久之前的数据,也很少更新数据。
大多数情况在数据被采集到数秒或者数分钟后就会被写入数据库
4、删除操作一般为区块删除,选定开始的历史时间并指定后续的区块。
很少单独删除某个时间或者分开的随机时间的数据。
5、基本数据大,一般超过内存大小。
一般选取的只是某一小部分且规律,缓存几乎不起任何作用。
6、读操作是十分典型的升序或者降序的顺序读
7、高并发的读操作十分常见
指标名称要表明观察的目的(不是强制的)如(http_requests_total表示系统收到请求总数的时间序列),
同一指标中的每个key/value(称为label)都称作一个维度,如(http_requests_totalcode=200)代表请求成功的时间序列.
外部应用通过PromQL来对时间序列进行相应的查找,
在查询时还可以利用Prometheus提供的功能丰富的函数对时间序列中的值进行计算。
度量指标类型
Prometheus提供的客户端jar包中, 把指标类型分为如下四种
- Counter
- Gauge
- Histogram
- Summary
注意:
这个分类只针对客户端使用者有效,在Prometheus server端是不进行区分的。
对于Prometheus server端而言,客户端返回的, 都是时间序列对应的一个Sample.
如http_requests_totalcode=200 290,
表示 Prometheus server拉取指标的这个时间点,请求成功的总数是290次.
一个Sample,是一个纯文本数据,
另外:
即便不用Prometheus提供的客户端,只要返回的数据满足这种格式,Prometheus server就能正常存储.
注意:Prometheus服务还没有充分利用这些类型,将来可能会发生改变。
Counter(计数器)类型
counter 是表示单个单调递增计数器的 累积度量值,其值只能在重启时增加或重置为零。
例如,您可以使用计数器来表示所服务的请求数,已完成的任务或错误。
注意:
不要使用计数器来暴露可能减少的值。
另外:
不要使用计数器来处理当前正在运行的进程数,而是使用gauge。
使用场景
Counter对应的指标值只能是一个单独的数值,并且除了能在服务启动时重置外,只能对指标值做累加操作,不能做减法操作,
可以用来统计请求次数、任务执行次数、关键业务对象操作次数等。
Gauge(计量器、测量器)
gauge是一个度量指标,它表示一个既可以递增, 又可以递减的值。
测量器主要测量类似于温度、当前内存使用量等,也
可以统计当前服务运行随时增加或者减少的线程数量
使用场景
Gauge对应的指标值只能是一个单独的数值,
与Counter不同的是,可以对Gauge代表的指标值做加减操作,一般用来表示温度、正在执行的job等指标
Histogram(柱状图、直方图)
Histogram 柱状图,不再是简单对指标的sample值进行加减等操作,对于每一个sample值执行下面的三个操作:
- 根据Histogram定义时指定的bucket区间,将sample分到各个bucket中,每个bucket中存放的是落入这个区间的个数
- 对每个采样点值累计和(sum)
- 对采样点的次数累计和(count)
例子
例如我们通过Prometheus提供的客户端通过
Histogram.build().name("job_execute_time").help("job执行时间时间分布(分)").buckets(1,5,10) .register();
定义了一个histogram,用来统计job执行时间的分布。
对应的buckets是(1,5,10),代表四个区间
- <=1分钟
- <=5分钟
- <=10分钟
- <无穷大
Histogram会生成如下6个维度的指标值
job_execute_time_bucketle="1.0",
job_execute_time_bucketle="5.0",
job_execute_time_bucketle="10.0",
job_execute_time_bucketle="+Inf",
job_execute_time_count
job_execute_time_sum
当我们有一个job执行时间为5.6分钟,则对应的各个维度的值变成
job_execute_time_bucketle="1.0", 0.0
job_execute_time_bucketle="5.0", 0.0
job_execute_time_bucketle="10.0", 1.0
job_execute_time_bucketle="+Inf", 1.0
job_execute_time_count 1.0
job_execute_time_sum 5.6
无穷大的肯定是和
job_execute_time_count一致的
可以看到Histogram类型的指标不会保留各个sample的具体数值,每个bucket中也只是记录样本数的counter。
原理
直方图对观察结果进行采样(通常是请求持续时间或响应大小等),并将其计入可配置存储桶中。
它还提供所有观察值的总和。
基本度量标准名称为的直方图在scrape区间显示多个时间序列:
- 暴露的观察桶的累积计数器:
<basename>_bucketle="<upper inclusive bound>" - 所有观测值的总和:
<basename>_sum - 已观察到的事件数:
<basename>_count,和<basename>_bucketle="+Inf"相同
使用histogram_quantile函数, 计算直方图或者是直方图聚合计算的分位数阈值。
一个直方图计算Apdex值也是合适的, 当在buckets上操作时,记住直方图是累计的。
详见直方图和总结
Summary
Summary 采样点分位图统计,类似于histgram,但是采用分位数来将sample分到不同的bucket中,
具体的区别查看HISTOGRAMS AND SUMMARIES,
虽然它还提供观察的总数和所有观测值的总和,但它在滑动时间窗口上计算可配置的分位数。
基本度量标准名称<basename>的summary在scrape期间公开了多个时间序列:
- 流φ-quantiles (0 ≤ φ ≤ 1), 显示为
<basename>quantiles="[φ]" <basename>_sum, 是指所有观察值的总和<basename>_count, 是指已观察到的事件计数值
有关φ-分位数,Summary用法和histogram图差异的详细说明,详见histogram和summaries
有关summaries的客户端使用文档:
Summary 和 Histogram 的区分
Summary 和 Histogram 的一个区分要点是 summary 在客户端侧计算分位数,然后直接暴露它们,
然而 histogram 在客户端侧暴露桶的技术,然后在服务端侧使用 histogram_quantitle() 函数来计算分位数。
| Histogram | Summary | |
|---|---|---|
| 所需的配置 | 合理定义直方图的区间 | 确定好分位数和滑动窗口。其他的分位数和滑动窗口后面是不能计算的 |
| 客户端性能 | 监控容易,只需要累加Counter即可 | 监控比较昂贵,因为要计算分位数 |
| 服务端性能 | 服务器必须计算分位数。 如果临时计算的时间过长(例如在大型仪表板中),则可以使用[记录规则] | 服务端消耗低 |
时间序列的个数(除了_sum 和 _count) | 每个桶一个时间序列 | 每个分位数一个时间序列 |
| 分位数误差 | 相关bucket的宽度定义决定了误差 | 分位数是预先定义好的 |
| 时间滑动窗口的指定分位数 | 使用普罗表达式的实时查询 | 由client预定义好 |
| 聚合 | 使用普罗表达式的实时查询 | 通常来说不可聚合 |
学习 PromQL
通过上面的步骤安装好 Prometheus 之后,我们现在可以开始体验 Prometheus 了。
Prometheus 提供了可视化的 Web UI 方便我们操作,直接访问 http://localhost:9090/ 即可,它默认会跳转到 Graph 页面:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IkPBJMhj-1665201510803)(https://www.likecs.com/default/index/img?u=aHR0cDovL3d3dy5hbmVhc3lzdG9uZS5jb20vdXNyL3VwbG9hZHMvMjAxOC8xMC8xOTM3NDE3NTI3LmpwZw%3D%3D)]
第一次访问这个页面可能会不知所措,我们可以先看看其他菜单下的内容,
比如:Alerts 展示了定义的所有告警规则,Status 可以查看各种 Prometheus 的状态信息,有 Runtime & Build Information、Command-Line Flags、Configuration、Rules、Targets、Service Discovery 等等。
实际上 Graph 页面才是 Prometheus 最强大的功能,在这里我们可以使用 Prometheus 提供的一种特殊表达式来查询监控数据,这个表达式被称为 PromQL(Prometheus Query Language)。
通过 PromQL 不仅可以在 Graph 页面查询数据,而且还可以通过 Prometheus 提供的 HTTP API 来查询。查询的监控数据有列表和曲线图两种展现形式(对应上图中 Console 和 Graph 这两个标签)。
我们上面说过,Prometheus 自身也暴露了很多的监控指标,也可以在 Graph 页面查询,展开 Execute 按钮旁边的下拉框,可以看到很多指标名称,
我们随便选一个,譬如:promhttp_metric_handler_requests_total,这个指标表示 /metrics 页面的访问次数,Prometheus 就是通过这个页面来抓取自身的监控数据的。在 Console 标签中查询结果如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GrQ7qRq1-1665201510803)(https://www.likecs.com/default/index/img?u=aHR0cDovL3d3dy5hbmVhc3lzdG9uZS5jb20vdXNyL3VwbG9hZHMvMjAxOC8xMC8yMDgyOTY1NDM1LmpwZw%3D%3D)]
上面在介绍 Prometheus 的配置文件时,可以看到 scrape_interval 参数是 15s,也就是说 Prometheus 每 15s 访问一次 /metrics 页面,所以我们过 15s 刷新下页面,可以看到指标值会自增。
在 Graph 标签中可以看得更明显:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NK3Kybb7-1665201510803)(https://www.likecs.com/default/index/img?u=aHR0cDovL3d3dy5hbmVhc3lzdG9uZS5jb20vdXNyL3VwbG9hZHMvMjAxOC8xMC8zMDQ0MzM5NzcxLmpwZw%3D%3D)]
数据模型
要学习 PromQL,首先我们需要了解下 Prometheus 的数据模型,
一条 Prometheus 数据由一个指标名称(metric)和 N 个标签(label,N >= 0)组成的,比如下面这个例子:
promhttp_metric_handler_requests_totalcode="200",instance="192.168.0.107:9090",job="prometheus" 106
这条数据的指标名称为 promhttp_metric_handler_requests_total,并且包含三个标签 code、instance 和 job,这条记录的值为 106。
上面说过,Prometheus 是一个时序数据库,相同指标相同标签的数据构成一条时间序列。
如果以传统数据库的概念来理解时序数据库,可以把指标名当作表名,标签是字段,timestamp 是主键,还有一个 float64 类型的字段表示值(Prometheus 里面所有值都是按 float64 存储)。
这种数据模型和 OpenTSDB 的数据模型是比较类似的,详细的信息可以参考官网文档 Data model。另外,关于指标和标签的命名,官网有一些指导性的建议,可以参考 Metric and label naming 。
虽然 Prometheus 里存储的数据都是 float64 的一个数值,但如果我们按类型来分,可以把 Prometheus 的数据分成四大类:
- Counter
- Gauge
- Histogram
- Summary
Counter 用于计数,例如:请求次数、任务完成数、错误发生次数,这个值会一直增加,不会减少。Gauge 就是一般的数值,可大可小,例如:温度变化、内存使用变化。Histogram 是直方图,或称为柱状图,常用于跟踪事件发生的规模,例如:请求耗时、响应大小。它特别之处是可以对记录的内容进行分组,提供 count 和 sum 的功能。Summary 和 Histogram 十分相似,也用于跟踪事件发生的规模,不同之处是,它提供了一个 quantiles 的功能,可以按百分比划分跟踪的结果。例如:quantile 取值 0.95,表示取采样值里面的 95% 数据。更多信息可以参考官网文档 Metric types,Summary 和 Histogram 的概念比较容易混淆,属于比较高阶的指标类型,可以参考 Histograms and summaries 这里的说明。
这四种类型的数据只在指标的提供方作区分,也就是上面说的 Exporter,如果你需要编写自己的 Exporter 或者在现有系统中暴露供 Prometheus 抓取的指标,你可以使用 Prometheus client libraries,这个时候你就需要考虑不同指标的数据类型了。如果你不用自己实现,而是直接使用一些现成的 Exporter,然后在 Prometheus 里查查相关的指标数据,那么可以不用太关注这块,不过理解 Prometheus 的数据类型,对写出正确合理的 PromQL 也是有帮助的。
PromQL 入门
我们从一些例子开始学习 PromQL,最简单的 PromQL 就是直接输入指标名称,比如:
# 表示 Prometheus 能否抓取 target 的指标,用于 target 的健康检查``up
这条语句会查出 Prometheus 抓取的所有 target 当前运行情况,譬如下面这样:
upinstance="192.168.0.107:9090",job="prometheus" 1``upinstance="192.168.0.108:9090",job="prometheus" 1``upinstance="192.168.0.107:9100",job="server" 1``upinstance="192.168.0.108:9104",job="mysql" 0
也可以指定某个 label 来查询:
upjob="prometheus"
这种写法被称为 Instant vector selectors,这里不仅可以使用 = 号,还可以使用 !=、=~、!~,比如下面这样:
upjob!="prometheus"``upjob=~"server|mysql"``upjob=~"192\\.168\\.0\\.107.+"
=~ 是根据正则表达式来匹配,必须符合 RE2 的语法。
和 Instant vector selectors 相应的,还有一种选择器,叫做 Range vector selectors,它可以查出一段时间内的所有数据:
http_requests_total[5m]
这条语句查出 5 分钟内所有抓取的 HTTP 请求数,注意它返回的数据类型是 Range vector,没办法在 Graph 上显示成曲线图,一般情况下,会用在 Counter 类型的指标上,并和 rate() 或 irate() 函数一起使用(注意 rate 和 irate 的区别)。
# 计算的是每秒的平均值,适用于变化很慢的 counter``# per-second average rate of increase, for slow-moving counters``rate(http_requests_total[5m])` `# 计算的是每秒瞬时增加速率,适用于变化很快的 counter``# per-second instant rate of increase, for volatile and fast-moving counters``irate(http_requests_total[5m])
此外,PromQL 还支持 count、sum、min、max、topk 等 聚合操作,还支持 rate、abs、ceil、floor 等一堆的 内置函数,更多的例子,还是上官网学习吧。如果感兴趣,我们还可以把 PromQL 和 SQL 做一个对比,会发现 PromQL 语法更简洁,查询性能也更高。
HTTP API
我们不仅仅可以在 Prometheus 的 Graph 页面查询 PromQL,Prometheus 还提供了一种 HTTP API 的方式,可以更灵活的将 PromQL 整合到其他系统中使用,譬如下面要介绍的 Grafana,就是通过 Prometheus 的 HTTP API 来查询指标数据的。实际上,我们在 Prometheus 的 Graph 页面查询也是使用了 HTTP API。
我们看下 Prometheus 的 HTTP API 官方文档,它提供了下面这些接口:
- GET /api/v1/query
- GET /api/v1/query_range
- GET /api/v1/series
- GET /api/v1/label/<label_name>/values
- GET /api/v1/targets
- GET /api/v1/rules
- GET /api/v1/alerts
- GET /api/v1/targets/metadata
- GET /api/v1/alertmanagers
- GET /api/v1/status/config
- GET /api/v1/status/flags
从 Prometheus v2.1 开始,又新增了几个用于管理 TSDB 的接口:
- POST /api/v1/admin/tsdb/snap
以上是关于Prometheus+Grafana (史上最全)的主要内容,如果未能解决你的问题,请参考以下文章