“华为杯”第十八届中国研究生数学建模竞赛一等奖经验分享
Posted 周先森爱吃素
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了“华为杯”第十八届中国研究生数学建模竞赛一等奖经验分享相关的知识,希望对你有一定的参考价值。
迟来很久的经验分享,有帮助别忘了点赞哦!!!
简介
距离去年参与研究生数学建模并获得全国一等奖已经过去了一年,由于一直比较忙也没有抽空来对之前的比赛做一个总结,最近看到师弟们在准备参与今年的竞赛,于是写了这篇文章来做一个简单的经验总结。
赛前准备
- 组队分工
一般的话是三个人组队,我的建议是一个人负责建模和编程,另外两个人负责论文内容(包括撰写和可视化素材),这是我们实践中发现雄安率比较高的一种分工方式,当然这里有个前提就是负责编程的这个人的能力要比较强,要对算法和建模都比较了解。换言之,一般计算机这边会选择数据挖掘类的题目,因此这个负责编程的人要对数据挖掘的一些生态比较熟悉(我们组是我负责这一块的,我对Python的数据挖掘竞赛的一些生态都比较了解,包括pandas、numpy、scipy、scikit-learn、xgboost、matplotlib、seaborn、plotly等库)。另外两个人负责论文的撰写,这个也很重要,因为最终呈现给评委的就是论文,很少有人去看代码这些补充材料的,所以一定要格式规范且美观。 - 算法准备
负责算法和建模的编程人员需要学习相应的生态库,比如matlab生态或者python生态,熟悉一种即可,然后要对一些主流的机器学习算法有所实战经验,因为实际上数学建模周期很短,很少会采用一些深度学习模型,更多的时候还是现有机器学习模型的组合调优。同时也要熟悉一些可视化工具库,python这边的话用的多的是matplotlib、seaborn和plotly等,这些数据分析或者模型决策的可视化有利于丰富论文内容并帮助理解(谁不喜欢看图呢)。此外,其实历年的优秀解法都有类似之处,需要去看看前几年的优秀论文并体会其中的建模思路,有利于最后一问的思路展开。 - 论文准备
负责论文撰写的人在准备阶段,需要大量阅读之前的优秀论文,学习其排版组织、前后逻辑、章节划分等可取之处,比如他们摘要怎么写的有亮点、总结怎么拔高、文中什么时候公式说明什么时候图表说明、这一章怎么分小结的。同时,为了便于理解,可以在序章插入文章结构图之类的,这就要求会使用思维导图(xmind)、流程图(visio)等软件。此外还要学会如何导入参考文献到word中,毕竟论文最后需要一些参考文献作为佐证。此外要准备好论文模板(一般官方会给),以便于短暂的比赛期内能够迅速合作撰写,可以考虑Word自带的在线协作。
赛中安排
我们选择是当时选题量非常大的一道非常经典的数据挖掘类赛题,即2021年的D题“抗胰腺癌候选药物的优化建模”。赛题说明里面包括背景介绍、数据集介绍及建模指标、需解决问题,我们重点关注后面二者。“数据集介绍及建模指标”这部分告诉我们如何去理解数据集,这部分很重要,有助于后面的特征工程,然后会大体阐述这个赛题的最终任务是什么,但是不是狠具体。“需解决问题”这部分就是本次赛题需要解决的四个具体任务,一般是一个问题在论文里写一章来解答。
问题1:

很具有代表性的一个挖掘题,其实就是做一个特征选择,注意是特征选择而不是降维,降维会破坏原有的特征,而本题是为了找到更加合理的少部分特征。针对问题一,针对化合物的729个分子描述符进行变量选择,选出对生物活性影响最大的20个分子描述符并按照重要性排序。首先,设计了二阶段粗筛-细筛策略,粗筛阶段建立基于随机森林的递归特征消除模型(RF-RFE),细筛阶段建立基于相关性分析的特性筛选模型。接着,对模型分阶段进行求解,第一阶段先从所有变量中挑选出35个候选变量,第二阶段再从候选变量中消除高相关性的低排名变量,得到20个核心变量及其贡献度排名。最后,采用变量分布性检验和相关性检验确定所得变量的合理性。
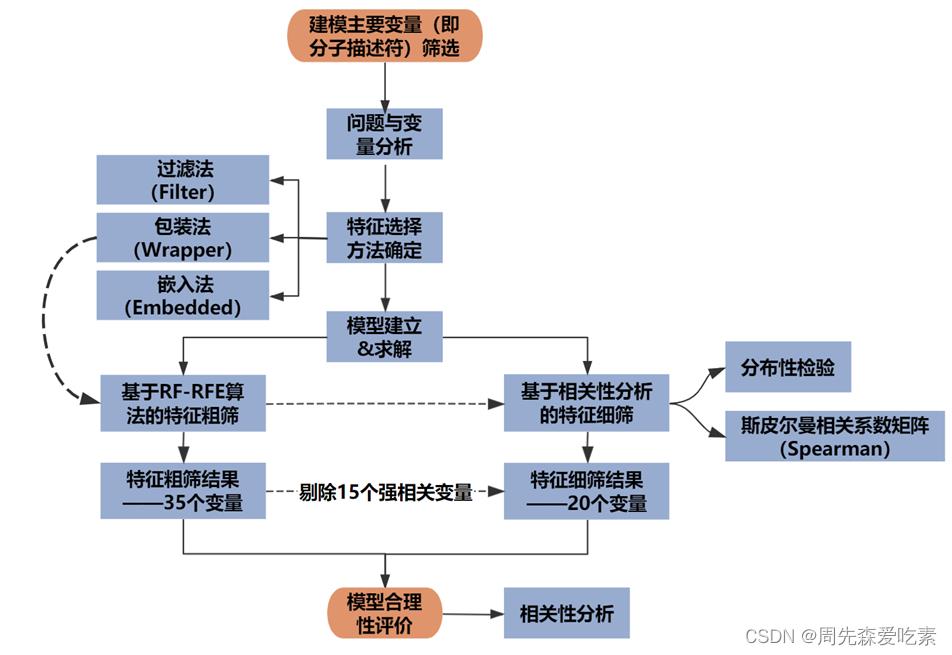
其中,借助seaborn进行相关性分析如下,我们消除掉部分高相关的。
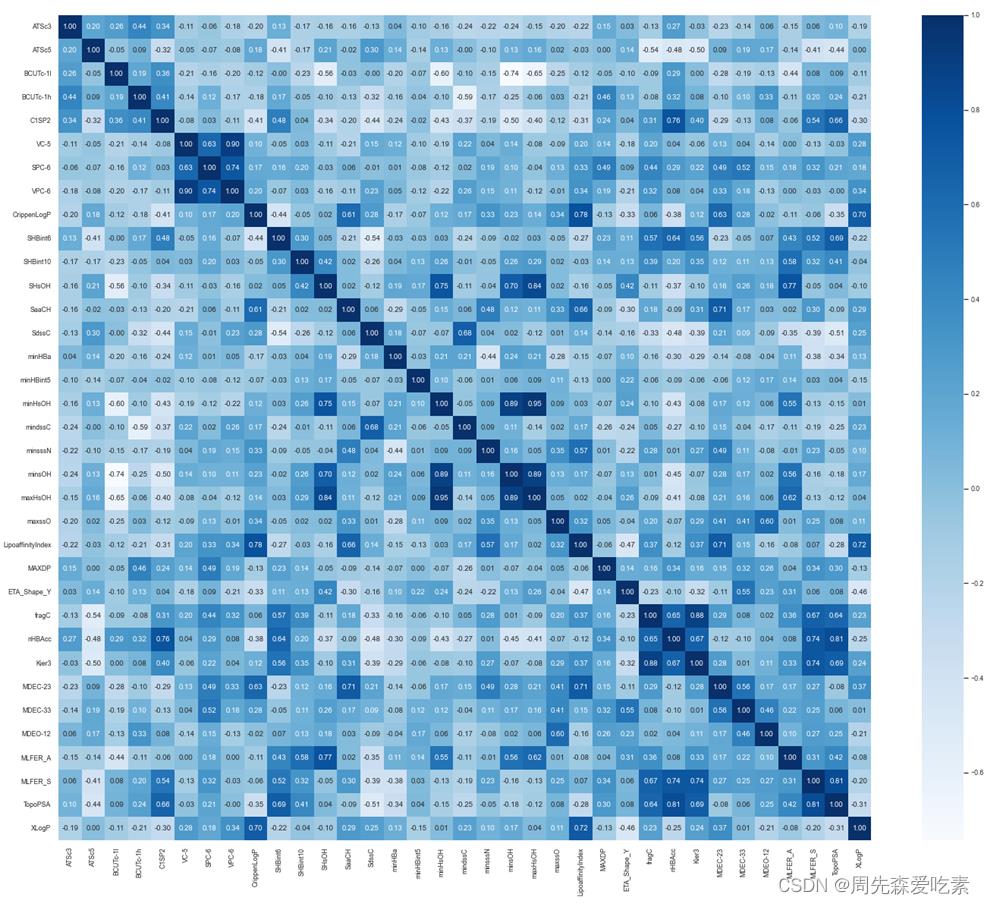
问题2:

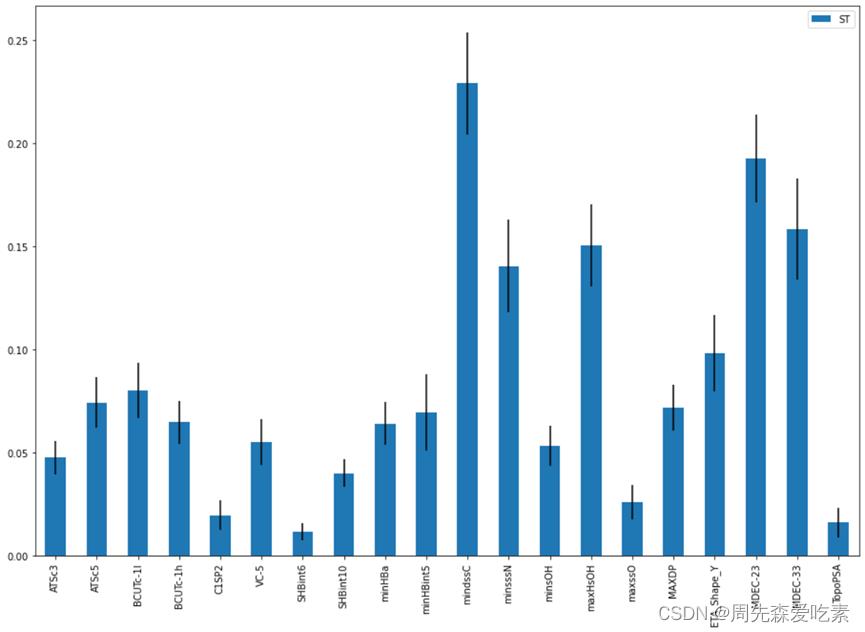
这题是一个常规的回归问题,是在第一问的基础上进行的,我们就是采用了一些强树模型进行对比。针对问题二,建立化合物对ERα生物活性的定量预测模型,参与建模的变量不超过问题一的20个。首先,考虑到化合物生物活性值pIC50由IC50变换得到,且与药物活性正相关,因此建立pIC50预测模型,再进行目标转换得到对应的IC50值。其次,分别建立基于梯度提升回归、支持向量机回归、极端梯度提升回归的ERα生物活性预测模型,并对三种模型的预测效果进行分析。最后,对模型进行Sobol敏感性分析,探究核心变量与ERα生物活性的内在联系。
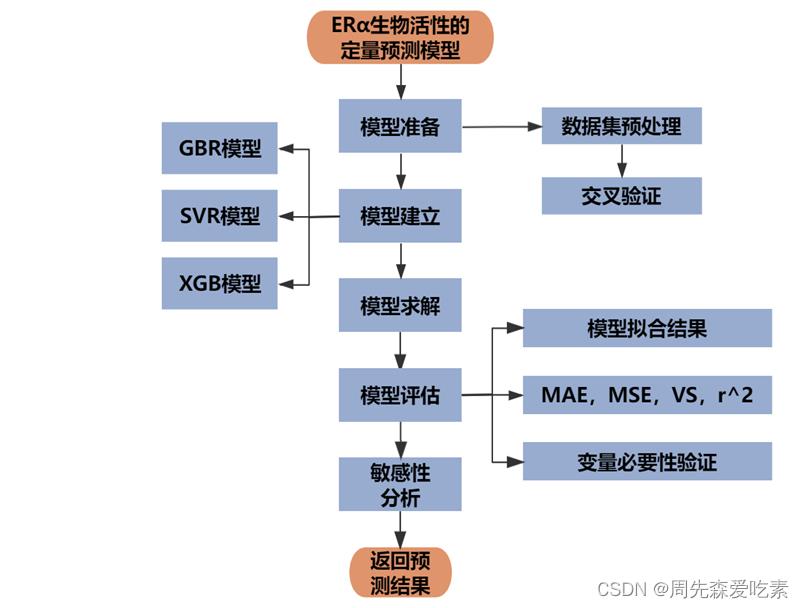
敏感性分析如下。
问题3:

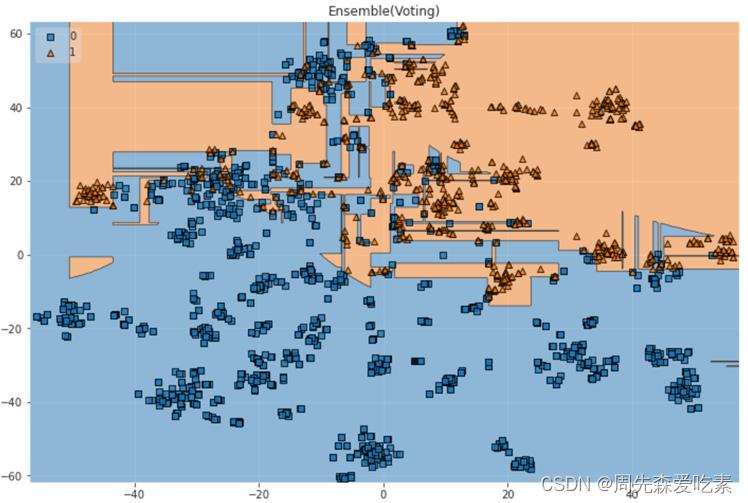
这题是个典型的分类问题,我们对每个指标建立一个分类模型,共计5个模型,模型的构建思路是基于基模型进行集成模型搭建。针对问题三,建立化合物的Caco-2、CYP3A4、hERG、HOB、MN的性质分类预测模型。首先,分析得出上述五种性质均存在类别不均衡的问题,采用过采样策略进行样本平衡,以保证后续模型具有非偏向鲁棒性。然后,通过交叉验证法确定变量使用策略,以归一化后的全部分子描述符作为建模依据。接着,分别建立基于决策树、逻辑回归、支持向量机的基分类模型,并采用投票法(Voting)和堆叠法(Stacking)策略构建集成分类模型,并对上述模型进行预测效果分析。最后,通过模型决策面的可视化确定了构建的分类模型具有较强的复杂特征适应能力且分类准确。
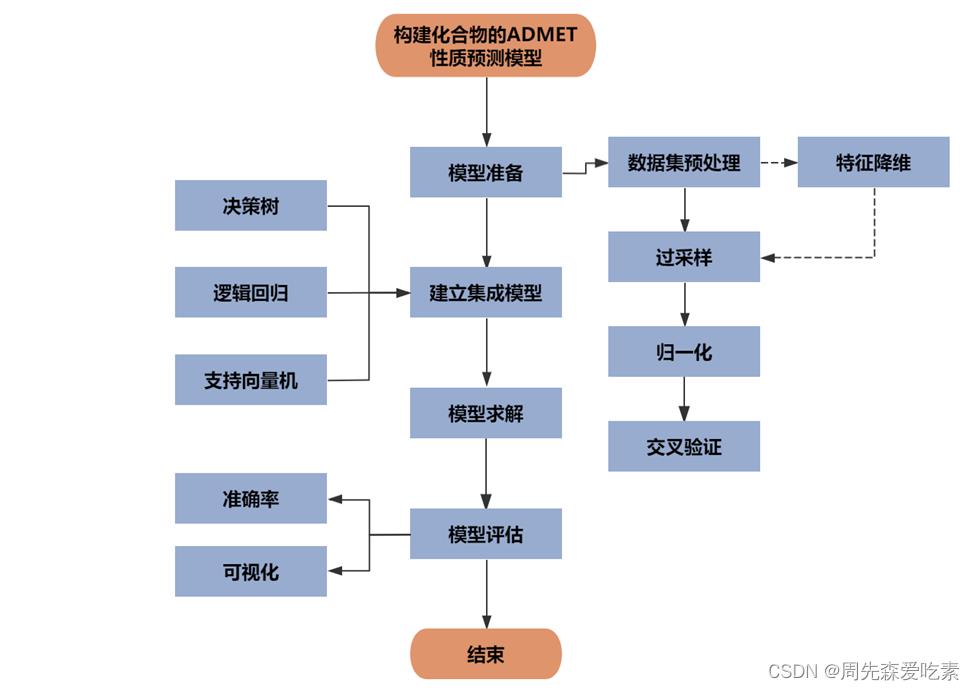
投票法模型的决策边界二维可视化。
问题4:

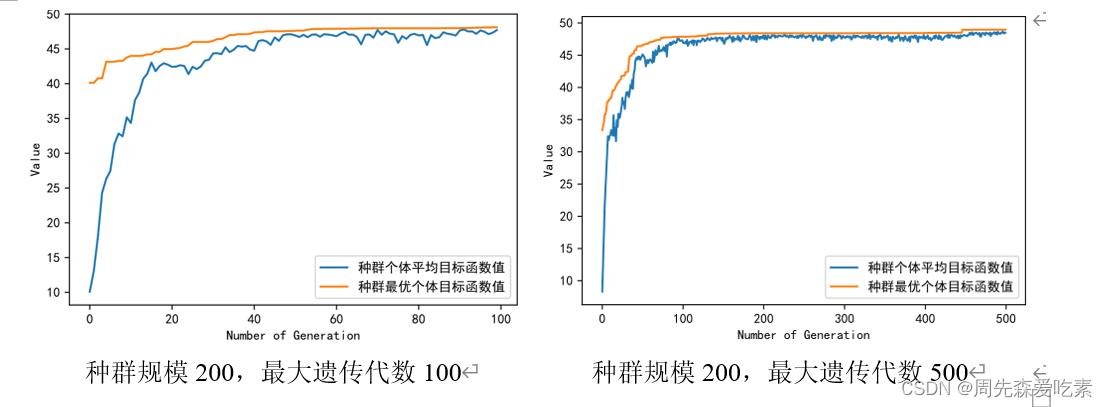
这题应该是这整个赛题的压轴题,这是一个比较开放的任务,我们已经得到了很不错的分类和回归模型,他们可以用来衡量一个化合物的好坏,那么现在你能否利用这些已有的模型,生成一些不错的药物呢?其实就是已知模型,反搜索一些合适的特征,我们这边采用了比较经典的遗传算法。针对问题四,探究分子描述符拥有更好生物活性和ADMET性质的条件。首先,设计了基于ADMET性质和ERα生物活性联合任务评分策略,并以最大化该得分为目标函数,以20个核心变量为决策变量,以其在数据集中的现有范围经过20%扩张后作为约束,建立核心变量优化的规划模型。其次,采用精英保留的遗传算法对模型进行求解,并对算法关键内容进行针对性设计,确定的大部分核心变量优质范围均相比于赛题样本缩小50%以上。最后,对优秀样本进行合理性验证,证明了遗传得到的子代样本具有较强的综合性能。
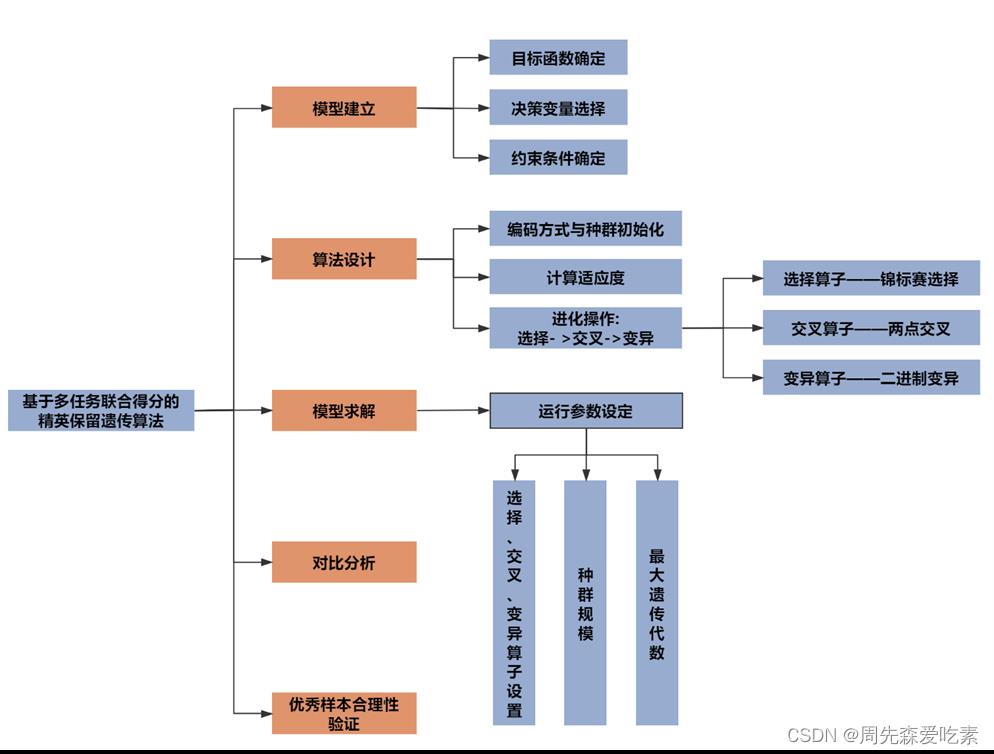
具体优化函数公式比较多,上面只给出基础思路,因为每个人建模思路都可能不一样。下图是迭代搜索的一些参数搜索。
注意点
- 第一,摘要要通过加粗等方式给人展现亮点,因为据传言一审主要看摘要‘;总结要体现优点和缺点,以及一些展望。文中合适的时候就可以给出一些可视化,比如模型可视化、预测可视化、流程可视化,毕竟评审人也是人,还是比较喜欢元素丰富的作品。
- 第二,一定要对每个题目有明确的结果在论文中说明,不要方法说了半天在验证集上很好用,最后没有在测试集上进行推理并给出结果。也就是说,针对问题的每一章都要有一节明确为模型预测结果。
- 第三,提交截至前一天会要求填写论文的md5校验码,这时候一定要根据PDF文件生成校验码提交,并且此后这个PDF绝对不能修改,任何改动都不可以。
总结
研究生数学建模对于实战功力的提升非常巨大,而且强度有点大,那些深夜肝论文的日子终会称为有趣的回忆,最后附上获奖证书。

以上是关于“华为杯”第十八届中国研究生数学建模竞赛一等奖经验分享的主要内容,如果未能解决你的问题,请参考以下文章