Python 爬虫正则表达式和re库,及re库的基本使用,提取单个页面信息
Posted the丶only
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 爬虫正则表达式和re库,及re库的基本使用,提取单个页面信息相关的知识,希望对你有一定的参考价值。
一、正则表达式
正则表达式是处理字符串的强大工具,它有自己特定的语法结构,有了它,实现字符串的检索、替换、匹配验证都不在话下,正则表达式在所有编程里通用,所以不仅仅是python使用。
以下是常用的正则表达式,用的时候参考即可,不需要死记硬背,用得多了自然就熟悉了。
| 字符 | 描述 |
|---|---|
| d | 匹配任意数字,等价于 [0-9] |
| D | 匹配任意非数字的字符,d的取反 |
| w | 代表字母,数字,下划线。也就是 a-z、A-Z、0-9、_。 |
| W | 代表不是字母,不是数字,不是下划线的。w的取反 |
| n | 代表一个换行 |
| r | 代表一个回车 |
| f | 代表换页 |
| t | 代表一个 Tab |
| s | 代表所有的空白字符,也就是上面这个:n、r、t、f |
| S | 代表所有不是空白的字符,s的取反 |
| A | 代表字符串的开始 |
| Z | 代表字符串的结束 |
| ^ | 匹配字符串开始的位置 |
| $ | 匹配字符创结束的位置 |
| . | 代表所有的单个字符,除了 n r |
| […] | 代表在 [] 范围内的字符,比如 [a-z] 就代表 a到z的字母 |
| [^…] | 代表不在 [] 范围内的字符 ,[…] 的取反 |
| n | 匹配在 n 前面的东西,比如: o2 不能匹配 Bob 中的 o ,但是能匹配 food 中的两个o |
| n,m | 匹配在 n,m 前面的东西,比如:o1,3 将匹配“fooooood”中的前三个o |
| n, | 匹配在 n, 前面的东西,比如:o2, 不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o |
| * | 和 0, 一个样,匹配 * 前面的 0 次或多次。 比如 zo* 能匹配“z”、“zo”以及“zoo” |
| + | 和1, 一个样,匹配 + 前面 1 次或多次。 比如 zo+”能匹配“zo”以及“zoo”,但不能匹配“z” |
| ? | 和0,1 一个样,匹配 ?前面 0 次或 1 次 |
| a | b |
| () | 匹配括号里面的内容 |
1、python爬虫最常用组合
死记硬背,估计很难记住,很多人就不想学了。但是只要记住最常用的组合即可。
.*? 是我们在匹配过程中最常使用到的,表示的就是匹配任意字符。
\\d+ 匹配任意数字组合。
上面的 .*? 为什么不直接用 .* 而需要加个 ?,这个涉及到贪婪还是非贪婪匹配。
2、贪婪还是非贪婪匹配
贪婪匹配:就是我们的第一段代码,一个数一个数都要去匹配,会尽可能多的去匹配内容。
非贪婪匹配:会尽量少的匹配符合条件的内容 也就是说,一旦发现匹配符合要求,立马就匹配成功,而不会继续匹配下去。
例子:
aacbacbc 用 a.*b 贪婪匹配的内容是:aacbacb
aacbacbc 用 a.*?b 非贪婪匹配的内容是:aacb
二、Python的Re库
Python语言中的re模块拥有全部的正则表达式功能。
1、re.match函数
函数语法:
re.match(pattern, string, flags=0)
pattern: 模式字符串 string:要匹配的字符串 flags:可选参数,比如re.I 不区分大小写
匹配成功re.match方法返回一个匹配的对象,否则返回None。
示例:
import re
print(re.match('ywbj', 'ywbj.cc')) # 在起始位置匹配
print(re.match('ywbj', 'ywbj.cc').span()) # 在起始位置匹配
print(re.match('ywbj', 'www.ywbj.cc')) # 不在起始位置匹配
执行结果:
<re.Match object; span=(0, 4), match='ywbj'>
(0, 4)
3 None
从例子中我们可以看出,re.match()方法返回一个匹配的对象,而不是匹配的内容。
通过调用span()可以获得匹配结果的位置。
而如果从起始位置开始没有匹配成功,即便其他部分包含需要匹配的内容,re.match()也会返回None。
2、分组捕获
以上可以看到返回的是匹配的对象,不是匹配的内容。
需要获取匹配的内容,我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
一般一个小括号括起来就是一个捕获组。我们可以使用group()来提取每组匹配到的字符串。
- group(num=0): 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。
- groups(): 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
示例:
import re
content = "I have 100 dogs and cats"
res = re.match('^I.*?(\\d+)(.*?)and(.*?)$',content)
print(res.group())
print(res.groups())
print(res.group(1))
print(res.group(2))
print(res.group(3))
执行结果:
I have 100 dogs and cats
('100', ' dogs ', ' cats')
100
dogs
cats
以上成功通过group捕获需要的词组和内容。
3、re.search()函数
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
示例:
import re
content = "I have 100 dogs and 200 cats"
res = re.search('\\d+',content)
print(res.group())
执行结果:
100
以上,如果用re.match则无法匹配,因为正则表达式不符合字符串规范,会报错。
而用re.search,直接匹配整个字符串。找到第一个符合 \\d+ 的字符串100。
注:仅仅是匹配第一个符合的,所以只有100,后面的200不会匹配。
3、re.findall()函数
re.search可以直接匹配找到符合正则的字符串,但是仅仅是第一个符合的。
如果需要匹配全部的符合的,则用到re.findall()函数。
re.findall()在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
示例:
import re
content = "I have 100 dogs and 200 cats"
res = re.findall('\\d+',content)
print(res)
执行结果:
['100', '200']
由于返回的是返回一个列表或元组,所以也不需要group来捕获。如果需要一个一个捕获,用res[0] 或res[1]来一个一个显示捕获的值。
4:re.sub()函数
检索和替换,Python 的 re 模块提供了re.sub用于替换字符串中的匹配项。
语法:
re.sub(pattern, repl, string, count=0, flags=0)
参数:
pattern : 正则中的模式字符串。
repl : 替换的字符串,也可为一个函数。
string : 要被查找替换的原始字符串。
count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
示例:
import re
content = "I have 100 dogs and 200 cats"
res = re.sub('\\d+','300',content)
print(res)
执行结果:
I have 300 dogs and 300 cats
5:re.compile()函数
这个主要就是把我们的匹配符封装一下,这个也是很常用的一个函数。
表达式:
re.compile(pattern[, flags])
参数:
pattern : 一个字符串形式的正则表达式
flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
- re.I 忽略大小写
- re.L 表示特殊字符集 \\w, \\W, \\b, \\B, \\s, \\S 依赖于当前环境
- re.M 多行模式
- re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符)
- re.U 表示特殊字符集 \\w, \\W, \\b, \\B, \\d, \\D, \\s, \\S 依赖于 Unicode 字符属性数据库
- re.X 为了增加可读性,忽略空格和 # 后面的注释
示例:
import re
content = "I have 100 dogs and cats"
res = re.match('^I.*?(\\d+)(.*?)and(.*?)$',content,re.S)
print(res.group())
print(res.groups())
以上,我们可以先用re.compile把正则表达式封装,便于以后反复使用。封装后如下:
import re
content = "I have 100 dogs and cats"
pattern = re.compile('^I.*?(\\d+)(.*?)and(.*?)$',re.S)
res = re.match(pattern,content)
print(res.group())
print(res.groups())
执行结果相同:
I have 100 dogs and cats
('100', ' dogs ', ' cats')
6、其他函数
re.finditer,和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
import re
it = re.finditer(r"\\d+","12a32bc43jf3")
for match in it:
print (match.group() )
输出结果:
12
32
43
3
re.split,split 方法按照能够匹配的子串将字符串分割后返回列表。
示例:
import re
pattern = re.compile(r"[A-Z]+")
m = pattern.split("abcDefgHijkLmnoPqrs")
print(m)
执行结果
['abc', 'efg', 'ijk', 'mno', 'qrs']
其他函数,具体用法可参考官方文档:https://docs.python.org/zh-cn/3/library/re.html
三、网页中的正则提取
1、正则表达式分析
惯例,同样以豆瓣电影排行做分析,链接为:https://movie.douban.com/top250
查看源代码,简单点,我们提取4个信息即可。分别是排名序号、电影名称、导演演员、年份类型。
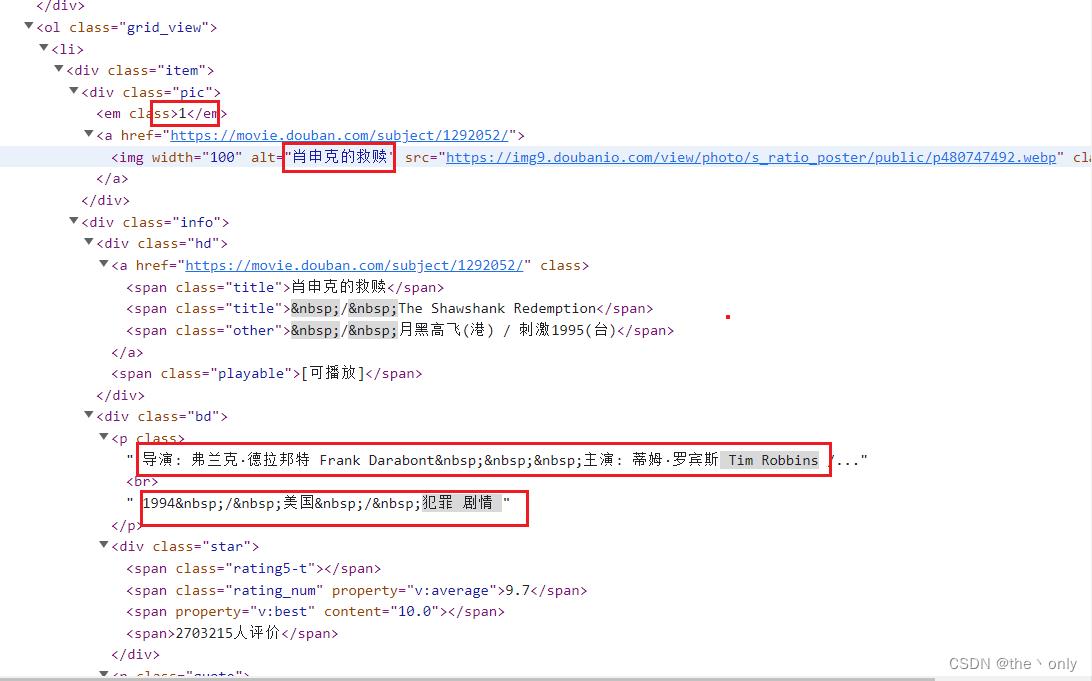
分析,所有信息在li标签中,所以首尾用在 li 标签中找就行了。需要的提取的信息,用()分组捕获就行。
1:第一个信息,排名序号,排名序号1在class></em之间。em是唯一的,比较简单。
<li.*?(\\d+)</em.*?li>
2:第二个信息,电影名称,有很多地方,但是我们选个唯一明显不重复的,alt= 后面是标签里唯一的,整个标签里面就一个信息,所以这里比较简单,这时正则表达式为。
<li.*?(\\d+)</em.*?alt="(.*?)".*?li>
3:第三个信息,导演演员,在<p 标签里面,br>标签上方,这时正则表达式为。
<li.*?(\\d+)</em.*?alt="(.*?)".*?<p.*?">(.*?)<br>.*?li>
4:第四个信息,年份类型,同理br>标签后方,</p结束,这个也很明显,最后的正则表达式为。
<li.*?(\\d+)</em.*?alt="(.*?)".*?<p.*?">(.*?)<br>(.*?)</p.*?li>
2、页面信息提取
正则表达式完成后,基本完成一大半了。现在简单提取相关信息。
这里用到两个库,re库正则表达式,和requests库抓取页面
import requests
import re
headers = 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (Khtml, like Gecko)Chrome/65.0.3325.162 Safari/537.36'
url='https://movie.douban.com/top250'
req=requests.get(url,headers=headers)
html=req.text
#print(req.text)
pattern= re.compile('<li.*?(\\d+)</em.*?alt="(.*?)".*?<p.*?">(.*?)<br>(.*?)</p.*?li>',re.S)
items=re.findall(pattern,html)
print(items)
执行结果,返回一个列表,还有\\n空格等,比较乱,类似如下:
[('1', '肖申克的救赎', '\\n 导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins ', '\\n 1994 / 美国 / 犯罪 剧情\\n '), ('2', '霸王别姬', '\\n 导演: 陈凯歌 Kaige Chen 主演: 张国荣 Leslie Cheung ', '\\n 1993 / 中国大陆 中国香港 / 剧情 爱情 同性\\n '), ('3', '阿甘正传', '\\n 导演: 罗伯特·泽米吉斯 Robert Zemeckis 主演: 汤姆·汉克斯 Tom Hanks ', '\\n 1994 / 美国 / 剧情 爱情\\n '), ('4', '泰坦尼克号', '\\n
...
3、列表去\\n空格
为了整洁,我们先抓取列表第一个数据 即 items[0] ,并去掉\\n和空格。
列表去除\\n,需要用到 strip() 函数, strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。但是该函数只支持字符串,不支持列表。所以需要用循环的方式。如下:
new=[x.strip() for x in items[0] if x.strip()!='']
最后更改后的代码为:
import requests
import re
headers = 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/65.0.3325.162 Safari/537.36'
url='https://movie.douban.com/top250'
req=requests.get(url,headers=headers)
html=req.text
#print(req.text)
pattern= re.compile('<li.*?(\\d+)</em.*?alt="(.*?)".*?<p.*?">(.*?)<br>(.*?)</p.*?li>',re.S)
items=re.findall(pattern,html)
#print(items[0])
new=[x.strip() for x in items[0] if x.strip()!='']
print(new)
执行结果这时候整洁多了:
['1', '肖申克的救赎', '导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins', '1994 / 美国 / 犯罪 剧情']
4、循环提前整个页面信息
以上只有第一个信息,整个页面有很多信息,需要全部提取,并排列整齐,所以需要再次用到for循环,一列一列的显示出来。
最终代码为:
import requests
import re
headers = 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/65.0.3325.162 Safari/537.36'
url='https://movie.douban.com/top250'
req=requests.get(url,headers=headers)
html=req.text
#print(req.text)
#pattern= re.compile('<li.*?(\\d+)</em.*?alt="(.*?)".*?</li>',re.S)
pattern= re.compile('<li.*?(\\d+)</em.*?alt="(.*?)".*?<p.*?">(.*?)<br>(.*?)</p.*?li>',re.S)
items=re.findall(pattern,html)
#print(items[0])
for item in items:
new=[x.strip() for x in item if x.strip()!='']
print(new)
执行结果:
['1', '肖申克的救赎', '导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...', '1994 / 美国 / 犯罪 剧情']
['2', '霸王别姬', '导演: 陈凯歌 Kaige Chen 主演: 张国荣 Leslie Cheung / 张丰毅 Fengyi Zha...', '1993 / 中国大陆 中国香港 / 剧情 爱情 同性']
['3', '阿甘正传', '导演: 罗伯特·泽米吉斯 Robert Zemeckis 主演: 汤姆·汉克斯 Tom Hanks / ...', '1994 / 美国 / 剧情 爱情']
['4', '泰坦尼克号', '导演: 詹姆斯·卡梅隆 James Cameron 主演: 莱昂纳多·迪卡普里奥 Leonardo...', '1997 / 美国 墨西哥 澳大利亚 加拿大 / 剧情 爱情 灾难']
['5', '这个杀手不太冷', '导演: 吕克·贝松 Luc Besson 主演: 让·雷诺 Jean Reno / 娜塔莉·波特曼 ...', '1994 / 法国 美国 / 剧情 动作 犯罪']
['6', '美丽人生', '导演: 罗伯托·贝尼尼 Roberto Benigni 主演: 罗伯托·贝尼尼 Roberto Beni...', '1997 / 意大利 / 剧情 喜剧 爱情 战争']
['7', '千与千寻', '导演: 宫崎骏 Hayao Miyazaki 主演: 柊瑠美 Rumi Hîragi / 入野自由 Miy...', '2001 / 日本 / 剧情 动画 奇幻']
['8', '辛德勒的名单', '导演: 史蒂文·斯皮尔伯格 Steven Spielberg 主演: 连姆·尼森 Liam Neeson...', '1993 / 美国 / 剧情 历史 战争']
['9', '盗梦空间', '导演: 克里斯托弗·诺兰 Christopher Nolan 主演: 莱昂纳多·迪卡普里奥 Le...', '2010 / 美国 英国 / 剧情 科幻 悬疑 冒险']
['10', '星际穿越', '导演: 克里斯托弗·诺兰 Christopher Nolan 主演: 马修·麦康纳 Matthew Mc...', '2014 / 美国 英国 加拿大 / 剧情 科幻 冒险']
['11', '忠犬八公的故事', '导演: 莱塞·霍尔斯道姆 Lasse Hallström 主演: 理查·基尔 Richard Ger...', '2009 / 美国 英国 / 剧情']
['12', '楚门的世界', '导演: 彼得·威尔 Peter Weir 主演: 金·凯瑞 Jim Carrey / 劳拉·琳妮 Lau...', '1998 / 美国 / 剧情 科幻']
['13', '海上钢琴师', '导演: 朱塞佩·托纳多雷 Giuseppe Tornatore 主演: 蒂姆·罗斯 Tim Roth / ...', '1998 / 意大利 / 剧情 音乐']
['14', '三傻大闹宝莱坞', '导演: 拉库马·希拉尼 Rajkumar Hirani 主演: 阿米尔·汗 Aamir Khan / 卡...', '2009 / 印度 / 剧情 喜剧 爱情 歌舞']
['15', '机器人总动员', '导演: 安德鲁·斯坦顿 Andrew Stanton 主演: 本·贝尔特 Ben Burtt / 艾丽...', '2008 / 美国 / 科幻 动画 冒险']
['16', '放牛班的春天', '导演: 克里斯托夫·巴拉蒂 Christophe Barratier 主演: 让-巴蒂斯特·莫尼...', '2004 / 法国 瑞士 德国 / 剧情 喜剧 音乐']
['17', '无间道', '导演: 刘伟强 / 麦兆辉 主演: 刘德华 / 梁朝伟 / 黄秋生', '2002 / 中国香港 / 剧情 犯罪 惊悚']
['18', '疯狂动物城', '导演: 拜伦·霍华德 Byron Howard / 瑞奇·摩尔 Rich Moore 主演: 金妮弗·...', '2016 / 美国 / 喜剧 动画 冒险']
['19', '大话西游之大圣娶亲', '导演: 刘镇伟 Jeffrey Lau 主演: 周星驰 Stephen Chow / 吴孟达 Man Tat Ng...', '1995 / 中国香港 中国大陆 / 喜剧 爱情 奇幻 古装']
['20', '熔炉', '导演: 黄东赫 Dong-hyuk Hwang 主演: 孔侑 Yoo Gong / 郑有美 Yu-mi Jung /...', '2011 / 韩国 / 剧情']
['21', '控方证人', '导演: 比利·怀尔德 Billy Wilder 主演: 泰隆·鲍华 Tyrone Power / 玛琳·...', '1957 / 美国 / 剧情 犯罪 悬疑']
['22', '教父', '导演: 弗朗西斯·福特·科波拉 Francis Ford Coppola 主演: 马龙·白兰度 M...', '1972 / 美国 / 剧情 犯罪']
['23', '当幸福来敲门', '导演: 加布里尔·穆奇诺 Gabriele Muccino 主演: 威尔·史密斯 Will Smith ...', '2006 / 美国 / 剧情 传记 家庭']
['24', '触不可及', '导演: 奥利维·那卡什 Olivier Nakache / 艾力克·托兰达 Eric Toledano 主...', '2011 / 法国 / 剧情 喜剧']
['25', '怦然心动', '导演: 罗伯·莱纳 Rob Reiner 主演: 玛德琳·卡罗尔 Madeline Carroll / 卡...', '2010 / 美国 / 剧情 喜剧 爱情']
到这里,单个页面的信息就已经提取完成了,也算是完成了爬虫的一小步了。
以上是关于Python 爬虫正则表达式和re库,及re库的基本使用,提取单个页面信息的主要内容,如果未能解决你的问题,请参考以下文章