什么是spark?通俗易懂,一文读懂
Posted 淼淼_喵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是spark?通俗易懂,一文读懂相关的知识,希望对你有一定的参考价值。
Spark是什么
官方定义: 定义:*Apache Spark是用于**大规模数据(large-scala data)**处理的**统一(unified)**分析引擎。*
分析引擎(计算引擎): 我们目前接触的引擎有:
-
MapReduce 分布式计算引擎
-
Spark 分布式
内存计算引擎
计算引擎: 通用的 可以执行开发人员提供的业务代码的一种框架.
Spark框架中有一个核心的数据结构: RDD
Pandas中的数据结构是DataFrame, 多数API都是针对DF对象来进行的.
同样, Spark的数据结构是RDD对象, 多数API都是针对RDD对象来进行的
RDD对象是一个真正的分布式对象, Pandas的DataFrame则是一个单机的对象.
拓展阅读 Hadoop 和 Spark 对比
| Hadoop | Spark | |
|---|---|---|
| 类型 | 基础平台, 包含计算, 存储, 调度 | 分布式计算工具 |
| 场景 | 大规模数据集上的批处理 | 迭代计算, 交互式计算, 流计算 |
| 价格 | 对机器要求低, 便宜 | 对内存有要求, 相对较贵 |
| 编程范式 | Map+Reduce, API 较为底层, 算法适应性差 | RDD组成DAG有向无环图, API 较为顶层, 方便使用 |
| 数据存储结构 | MapReduce中间计算结果在HDFS磁盘上, 延迟大 | RDD中间运算结果在内存中 , 延迟小 |
| 运行方式 | Task以进程方式维护, 任务启动慢 | Task以线程方式维护, 任务启动快 |
Spark四大特点
-
速度贼快: 比MapReduce 快100倍以上( 基于内存计算 )
-
易于使用: API 写起来很简单, 和pandas差不多(比pandas还简单)
-
通用性强: 可用于离线批处理\\ SQL处理\\ 流计算 \\ 机器学习计算\\ 图计算
-
离线批处理(Core) SQL处理(SparkSQL)
-
-
运行方式很多: 可以运行在 YARN \\ 可以独立运行(StandAlone) \\ 可以运行在云平台上 \\ 可以运行在容器集群上 \\ 等等等.
Spark框架模块 - 了解
-
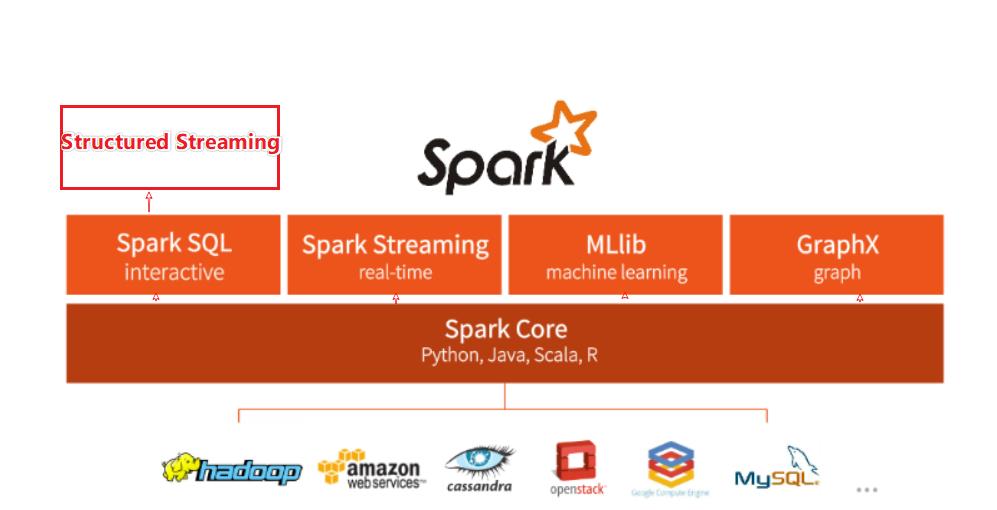
-
SparkCore: Spark的核心模块, 一切Spark的功能最底层由它提供 -
SparkSQL: Spark的结构化数据处理模块, 基于Core -
SparkStreaming: Spark的流计算模块 基于Core
-
Spark MLib: 机器学习模块. 基于Core
-
Spark GraphX: 图计算模块 基于Core
-
StructuredStreaming: 结构化
流, 基于SparkSQL模块
以上是关于什么是spark?通俗易懂,一文读懂的主要内容,如果未能解决你的问题,请参考以下文章