ARMS实践|日志在可观测场景下的应用
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ARMS实践|日志在可观测场景下的应用相关的知识,希望对你有一定的参考价值。
日志在可观测场景下的应用
随着 IT 架构改变与云原生技术实践,融入开发与业务部门视角,运维团队具备比原有监控更广泛、更主动的可观测能力。日志作为可观测三支柱(Tracing、Metrics、Logs)之一,帮助运维团队追踪程序运行状态、定位故障根因、还原故障现场。以故障发现和故障定位为目的使用日志场景可大致分为日志搜索和日志分析两类:
1. 日志搜索:
- 通过日志关键字搜索日志;
- 通过线程名、类名搜索日志;
- 结合 Trace 上下文信息,衍生出根据 TraceID、根据 spanName、parentSpanName、serviceName、parentServiceName 搜索日志。
2. 日志分析:
- 查看、分析指定日志数量的趋势;
- 根据日志内容生成指标(比如每次交易成功打印一条日志,可以生成关于交易额的一个指标);
- 自动识别日志模式(比如查看不同模式的日志数量的变化,占比)。
在实际生产中,通过灵活组合以上几种使用方式,运维团队可以很好地排除日常观测、故障定位过程中的干扰因素,更快的定界甚至定位问题根因。
常见开源日志解决方案的不足
常见的日志解决方案多是利用主机上安装日志采集 Agent,通过配置日志采集路径的方式将日志采集到第三方系统存储、查询、展示、分析。较为成熟的有 ELK(Elasticsearch、Logstash、Kibana)开源方案,其活跃的社区、简单的安装流程、便捷使用方式等优势吸引了不少用户。
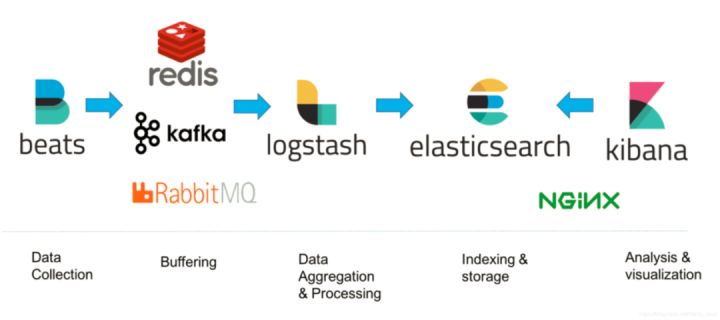
但 ELK 方案也存在着些许不足:
1. 运维成本高:搭建一套完整的 ELK 系统需要部署 ES 集群,kafka 集群以及 logstash 组件等等,以及随着日志规模的增长带来多集群拆分、多集群升级、稳定性等问题,往往需要投入更多人力。
2. 资源开销大:ELK 架构中几乎所有组件的资源开销都会随着日志规模的增长线性增长,占用极大成本。
3. 企业级能力缺乏:日志中往往包含业务关键信息,需要一套完备的多租户隔离以及细粒度的权限控制方案,这在开源免费 ELK 架构中是缺乏的。
基于 ARMS 的日志解决方案
相较于 ELK 开源自建方案,是否可以有更轻量、更容易运维的日志解决方案呢?
目前,应用实时监控服务 ARMS 提供一套简单易用的日志解决方案,让运维团队可以一键集成应用日志。相较于开源方案,丰富功能性、压降成本的同时,进一步提升易用性。
功能性
1. 自动富化日志
关联调用链上下文包括 TraceID、ServerIP、spanName,parentSpanName,serviceName,parentServiceName。全面满足根据 TraceID 搜索日志、查找触发异常日志打印的上游应用、上游接口等需要将 Tracing 和 Logs 进行关联分析的可观测场景。
2. 提供智能日志聚类能力
针对规模大、内容杂、且格式也难以做到统一规范的日志进行汇总、抽象聚类,使运维人员迅速发现异常日志与正常日志“类别”上的不同,从而快速定位异常日志、发现问题。
3. 提供 LiveTail 能力
针对线上日志进行实时监控分析,毫秒级别延迟上报日志,最贴近tail -f的日志查看体验,有效减轻运维压力。
4. 基于 ARMS 的 Arthas 能力,运行时调整 logger 输出级别
5. 一键生成基于日志的报警、日志转指标的能力(内测中 即将上线)。
易用性
- ARMS 控制台一键开通,即可使用日志相关全套功能;
- 无需安装额外日志采集组件,避免应用改造;
- 无需管理运维日志服务端以及日志,降低日常运维工作量;
- 支持日志服务 SLS、及 ARMS 直接采集的日志。
运维成本
- 日志功能处于公测阶段,完全免费;
- 提供灵活可配置的日志丢弃策略,从源头上减少大量无效日志;
- 提供灵活可配置的日志存储策略,可根据应用重要程度配置日志存储时长。
ARMS 日志功能展示 & 场景最佳实践
前置要求
1. 升级到 2.7.1.4 以及更高版本的 Agent(K8s 应用重启后会升级到 2.7.1.4 版本 agent,非 K8s 应用需要用户手动下载最新版本 Agent 并挂载)。
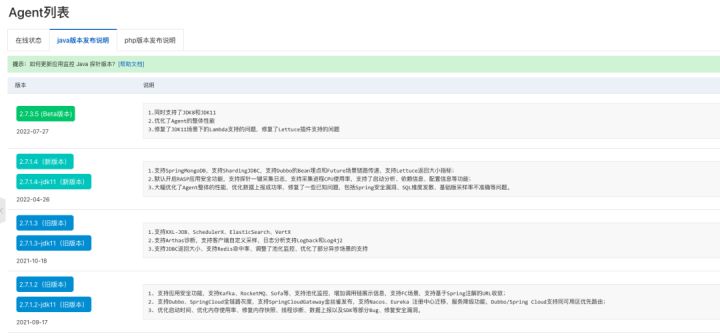
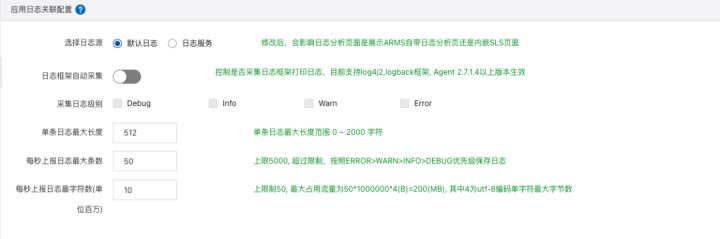
2. 在 ARMS 控制台应用列表页,点开需要开启日志采集功能的应用,点击左侧最下方应用设置,点到自定义配置页,打开日志采集开关并根据实际场景配置相应参数,最后点击保存。
- 对于直接采集的日志,是通过 ARMS 探针采集日志框架的输出并直接推送到 ARMS 的日志分析中心。
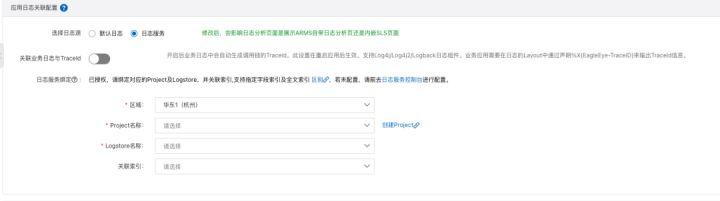
- 如果您需要将应用的日志采集到日志服务 SLS,并在 ARMS 应用配置中配置相应的 Project 和 Logstore,ARMS 会内嵌日志服务的页面方便您进行日志分析。
功能应用演示
1. 根据 TraceID 搜索日志
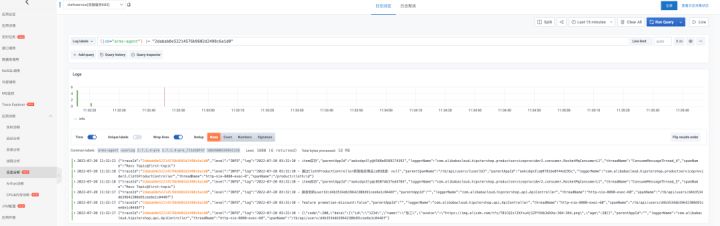
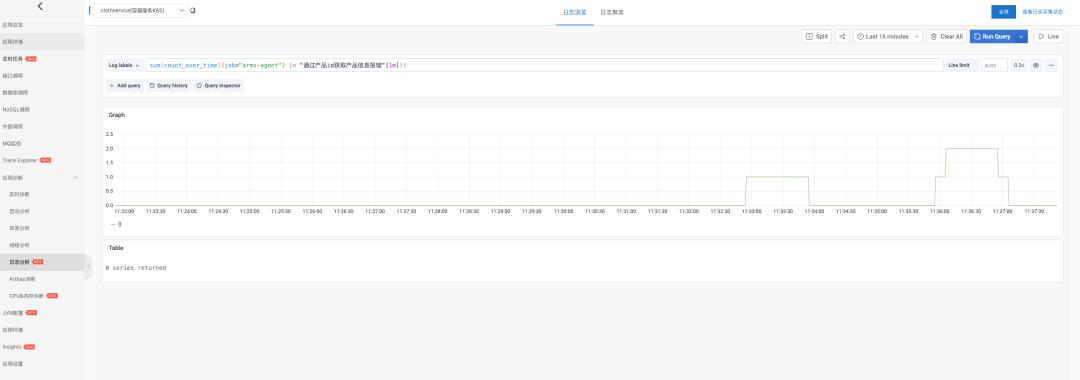
2. 查看包含置顶关键字的日志条数变化趋势
3. LiveTail
点击下方链接,查看操作视频:https://developer.aliyun.com/live/250112
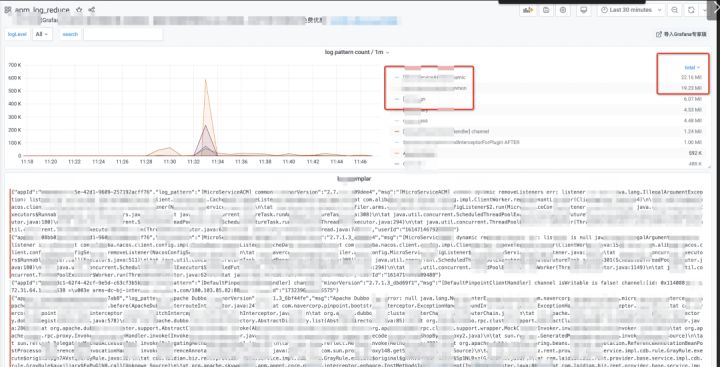
4. 日志聚类下图中上方左侧是识别出来不同模式的日志条数变化趋势,右图是不同模式日志选择时间段内总条数降序排序,下方是不同模式下的日志原文,可通过在 search 中搜索不同日志模式查看该模式下的日志原文样本。
ARMS 日志功能更多案例可查看 ARMS 官方文档:https://help.aliyun.com/document_detail/432298.html
最佳实践
下面简单介绍两个阿里云可观测团队在云服务 SRE 场景下应用使用 ARMS 日志功能的最佳实践。
案例:指标下跌问题排查
- 背景
应用 A 主要负责接收业务应用通过 RPC 上报流量信息、解析信息、简单处理后写存储。其中业务的流量信息包括时间戳、业务应用名、接口名、一分钟的接口请求量、一分钟的接口请求总耗时。写入存储后,可在控制台查看该业务应用的流量监控信息。某日 某业务应用B反馈扩容后流量监控信息下跌,随即开始排查问题。
- 排查方案
1. 首先打开日志平台。查看应用 A 相关日志。看到较多写存储限流异常,统计该异常数量最近3小时趋势发现无明显增加,说明该异常态少量出现,无影响,继续排查。
2. 怀疑应用 A 部分节点 hang 死,导致应用 B 上报数据失败,随即查看应用 A 不同实例日志输出量。发现基本均匀,该怀疑排除。
3. 此时,基本排除应用 A 的问题,开始怀疑数据上报异常。由于应用B的流量监控信息只是下跌并未跌 0,怀疑应用 B 部分节点数据上报异常。通过日志分析,获得当前应用 B 当前正常上报数据的 IP 列表,给到用户,发现应用 B 新扩容机器均未成功上报数据,怀疑新扩容机器网络异常。
4. 通过日志平台查看应用 B 日志,看到较多网络异常,查看该异常分布机器,均分布在新扩容机器上,与上一步结论吻合。随即登陆一台机器,发现到应用 A 的网络确实不通,随即联系网络同学恢复该问题。
- 场景总结
通过日志检索与日志分析结合使用,最终定位到问题根因。
案例: 日志存储成本降低
- 背景
应用 C 因为开发人员众多,日志打印级别设置不合理,日志量很大,日志功能成本开销很高,急需降本提效。
- 治理方案
1. 基于过往日志排查问题经验,很少需要查看一周前日志。因此,将日志存储时长策略缩短,由一个月调整为一周
2. 通过 ARMS 日志模式自动识别的功能,查看当前 top-k 的日志模式,发现较多模式的日志属于无效日志。设置日志丢弃策略,将无效的日志丢弃。
- 场景总结
结合存储时长调整和日志模式自识别,日志整体成本降低到以前的十分之一。目前,ARMS 日志应用功能已全面开放,让运维团队快速拥有日志分析与搜索能力!
作者:陈陈
本文为阿里云原创内容,未经允许不得转载。
以上是关于ARMS实践|日志在可观测场景下的应用的主要内容,如果未能解决你的问题,请参考以下文章