protobuf介绍和语法
Posted 两片空白
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了protobuf介绍和语法相关的知识,希望对你有一定的参考价值。
目录
前言
Protobuf即Protocol Buffers,是Google公司开发的一种跨语言和平台的序列化数据结构的方式,是一个灵活的、高效的用于序列化数据的协议。
与XML和JSON格式相比,protobuf更小、更快、更便捷。protobuf是跨语言的,并且自带一个编译器(protoc),只需要用protoc进行编译,就可以编译成Java、Python、C++、C#、Go等多种语言代码,然后可以直接使用,不需要再写其它代码,自带有解析的代码。
只需要将要被序列化的结构化数据定义一次(在.proto文件定义),便可以使用特别生成的源代码(使用protobuf提供的生成工具)轻松的使用不同的数据流完成对结构数据的读写操作。甚至可以更新.proto文件中对数据结构的定义而不会破坏依赖旧格式编译出来的程序。
Protobuf的优点如下:
- 性能号,效率高
序列化后字节占用空间比XML少3-10倍,序列化的时间效率比XML快20-100倍。 - 有代码生成机制
将对结构化数据的操作封装成一个类,便于使用。 - 支持向后和向前兼容
当客户端和服务器同时使用一块协议的时候, 当客户端在协议中增加一个字节,并不会影响客户端的使用 - 支持多种编程语言
Protobuf目前已经支持Java,C++,Python、Go、Ruby等多种语言。
Protobuf的缺点如下:
- 二进制格式导致可读性差
- 缺乏自描述
语法
protobuf协议文件名后缀名为.proto。一个简单的protobuf协议如下:
1 syntax="proto3";
2
3 package protobuf.addressbook;
4
5 enum PhoneType
6
7 MOBILE = 0;
8 HOME = 1;
9 WORK = 2;
10
11
12 message Person
13
14 optional string name = 1;
15 optional uint32 age = 2;
16 optional string email = 3;
17
18 message PhoneNumber
19
20 optional string number = 1;
21 optional PhoneType type = 2;
22
23
24 repeated PhoneNumber phone = 4;
25
26
27
28
29 message AddressBook
30
31 repeated Person person = 1;
32
标识符
- syntax:标识使用的protobuf是哪个版本。上面表示使用的是3.x版本。
- package:标识生成目标文件的包名。在C++中表示的是命名空间。上面。表示生成的类和函数在protobuf命名空间的addressbook命令空间下。
- enum:表示一个枚举类型。会在目标.h文件中自动生成一个枚举类型。
- message:标识一条消息。会在目标文件中自动生成一个类。
字段
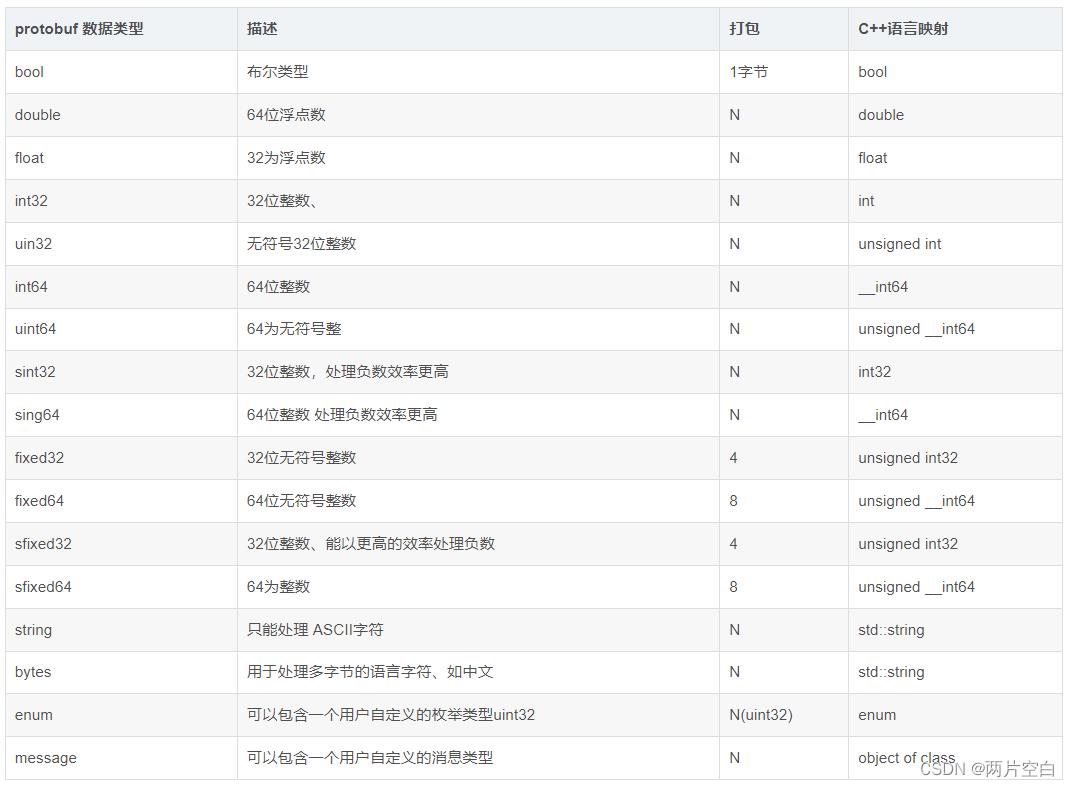
N 表示打包的字节并不是固定。而是根据数据的大小或者长度。
例如int32,如果数值比较小,在0~127时,使用一个字节打包。
关于枚举的打包方式和uint32相同。
关于message,类似于C语言中的结构包含另外一个结构作为数据成员一样。
关于 fixed32 和int32的区别。fixed32的打包效率比int32的效率高,但是使用的空间一般比int32多。因此一个属于时间效率高,一个属于空间效率高。根据项目的实际情况,一般选择fixed32,如果遇到对传输数据量要求比较苛刻的环境,可以选择int32.
proto2和proto3区别
总的来说proto3比proto2支持跟多语言,但是更加简洁。去除了复杂的语法和特性。
- 必须指明版本
syntax = "proto3";- 字段规则移除了"required",并把optional改名为了singlar,但是亲测,optional还可以用。
实际在proto2中也不推荐使用required,因为该字段是永久性的。如果以后因为某种原因,想不用该字段,或者要将该字段改成optional或者repeated,那么使用旧接口读取新的协议时,如果发现没有该字段,他们会认为该字段是不完整的,会拒接接收该消息,或者直接丢弃。
- “repeated”字段默认采用 packed 编码
在 proto2 中,需要明确使用 [packed=true] 来为字段指定比较紧凑的 packed 编码方式。
- 移除了 default 选项
在 proto2 中,可以使用 default 选项为某一字段指定默认值。在 proto3 中,字段的默认值只能根据字段类型由系统决定。也就是说,默认值全部是约定好的,而不再提供指定默认值的语法。
在字段被设置为默认值的时候,该字段不会被序列化。这样可以节省空间,提高效率。
但这样就无法区分某字段是根本没赋值,还是赋值了默认值。这在 proto3 中问题不大,但在 proto2 中会有问题。
- 枚举类型的第一个字段约定必须为 0
- 移除了对分组的支持
分组的功能完全可以用消息嵌套的方式来实现,并且更清晰。
- 移除了对扩展的支持,新增了 Any 类型
proto3 中新增的 Any 类型有点像 C/C++ 中的 void*
- 增加了 JSON 映射特性
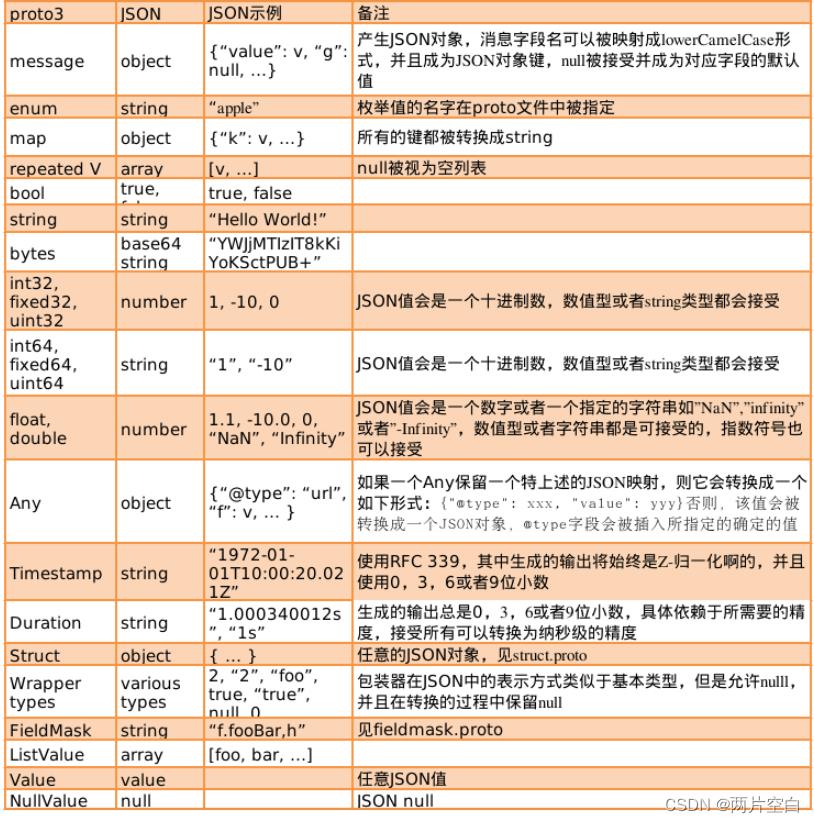
- Map
如果要创建一个关联映射,Protobuf提供了一种快捷的语法:
key_type可以是任意Integer或者string类型(除了floating和bytes的任意标量类型都可以),value_type可以是任意类型,但不能是map类型。
map<key_type, value_type> map_field = N;
注意:
- Map的字段可以是repeated。
- 序列化后的顺序和map迭代器的顺序是不确定的,所以不要期望以固定顺序处理Map。
- 当为.proto文件产生生成文本格式的时候,map会按照key 的顺序排序,数值化的key会按照数值排序。
map语法序列化后等同于如下内容,所以Map不经常使用。
message MapFieldEntry
key_type key = 1;
value_type value = 2;
repeated MapFieldEntry map_field = N;
- Oneof
Oneof定义用来代表在实现的时候,该组属性中的字段有且只能有一个被定义,不能出现多个。
message SampleMessage
oneof test_oneof
string name = 4;
SubMessage sub_message = 9;
上述定义中只能出现name或者sub_message的出现,不能同时出现。
注意:
- Oneof不能出现repeated类型
- 重复传递值到Oneof多个域仅仅最后的会生效,其它的将被忽略掉。
protobuf的编译和使用可以看:下一篇博客
参考文档:
ProtoBuf 语法简介_n大橘为重n的博客-CSDN博客_protobuf语法
Protobuf简介_Shower稻草人的博客-CSDN博客_protobuf介绍
【Protocol Buffer】Protocol Buffer入门教程(三):proto3与proto2的区别_沧海一笑的技术博客_51CTO博客
Protobuf简介_Shower稻草人的博客-CSDN博客_protobuf介绍
以上是关于protobuf介绍和语法的主要内容,如果未能解决你的问题,请参考以下文章