MGADA | 用于目标检测的多粒度对齐域自适应
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MGADA | 用于目标检测的多粒度对齐域自适应相关的知识,希望对你有一定的参考价值。
欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
大家好,我是极智视界,本文解读一下 MGADA 用于目标检测的多粒度对齐域自适应。

由于源域和目标域之间的数据分布不同,自适应目标检测具有很大的挑战性。本文提出了统一的基于多粒度对齐的目标检测框架,用于域不变特征学习。为此,对不同粒度的依赖项进行编码,包括像素级、实例级和类别级,以对齐两个域。基于 backbone 的像素级 feature maps,首先开发了全尺度门控融合模块,通过尺度感知卷积聚合实例的判别表示,从而实现鲁棒的多尺度目标检测。同时,提出了多粒度鉴别器来识别不同粒度的样本 (像素、实例和类别) 来自哪个域。值得注意的是,作者不仅利用了不同类别中的实例区分性,还利用了两个域之间的类别一致性。在多个域自适应场景下进行了广泛的实验,证明了提出的框架在不同 backbone 的 anchor-free FCOS 和 基于 anchor 的 Faster RCNN 检测器上优于现有算法。
论文地址:https://arxiv.org/abs/2203.16897
代码地址:https://github.com/tiankongzhang/MGADA
文章目录
1. 简介
随着深度学习的出现,基于大规模标注数据集的现代目标检测方法取得了显著进展。然而,这种受域约束的模型通常在没有标注的训练数据集的新环境中表现的很差。为了解决这个问题,一个可行的解决方法是通过以对抗方式进行无监督域自适应来减少标签丰富的源域和标签不可知的目标域之间的差异。具体来说,引入域鉴别器来识别图像来自源域还是来自目标域,而目标检测器学习域不变特征用来混淆鉴别器。然而,经典的域自适应框架在杂乱的背景会受到尺度变化的影响,导致性能受限。由于网络中的卷积层是固定核的,难以捕捉具有各种尺度和纵横比目标的准确特征。对于小目标,特征是从众多背景的大区域中卷积而来的;而对于大目标,卷积只覆盖了一小部分,缺乏全局结构信息。
另一方面,为了更加好地适应目标域,一些研究人员从不同粒度的角度,如实例级、像素级和类别级,采用了各种特征对齐策略。实例级对齐依赖于检测建议的池化特征来帮助训练 域鉴别器。然而,实例级池化操作可能会对尺度和纵横比变化的目标的特征造成失真。相比之下,像素级对齐侧重于考虑每个像素的较低级别特征,以处理目标和背景的跨域变化。然而,对于同一类别的不同尺度的目标,其像素级特征之间存在较大的差距。最近,类别级对齐利用两个域的类别区分性来处理硬对齐实例,然而这些工作更多关注图像级和实例级预测之间的一致性。
为了解决上述问题,作者提出了一个统一的基于多粒度对齐的无监督域自适应目标检测框架。如图1所示,在像素、实例和类别等不同粒度的角度对依赖项进行编码,以对齐源域和目标域,这并不是以前的单粒度对齐技术的粗略组合。
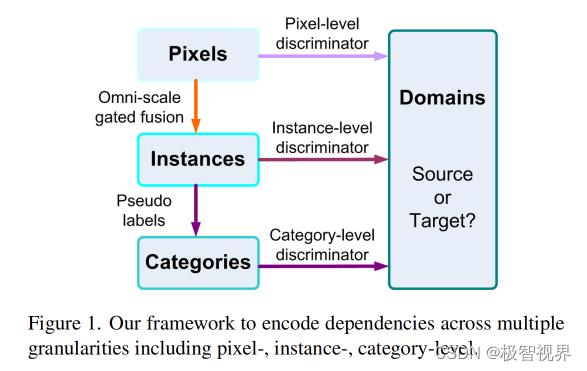
为了适应各种情况,作者的全尺度门控融合从低分辨率和高分辨率流中选择最合理的卷积来提取特征。具体来说,首先基于像素级 backbone 特征映射来估计粗检测作为指导。然后,激活并行卷积以聚合具有相似尺度和纵横比的实例的判别表示。这样,后续的目标检测头可以更加准确地预测多尺度目标。同时,作者引入了一种新的类别级鉴别器,不仅考虑了不同类别中实例的可鉴别性,而且考虑了源域和目标域之间的类别一致性。为了监督类别级鉴别器,将伪标签分配给目标检测中具有高置信度的重要实例。总之,在单个粒度的样本中构造了多粒度鉴别器,因此不同粒度的信息可以互补,以达到更加好的域自适应性能。
为了验证该方法的有效性,作者在不同的域自适应场景 (Cityscapes、FoggyCityscapes、Sim10k、KITTI、PASCAL VOC、Clipart 和 Watercolor) 上进行了全面的实验。在 anchor-free FCOS 和 基于 anchor 的 Faster RCNN 的基础上,backbone 使用 VGG-16 和 ResNet-101,在不同的数据集上获得了最好的性能。例如,使用 FCOS 从源域 Cityscapes 到 目标域 FoggyCityscapes 的 mAP 自适应得分为 43.8%,这比第二好的方法 CFA 高了 3.6%。
Contributions (1) 提出了多粒度对齐框架来编码跨像素、实例和类别粒度的依赖关系,以进行自适应目标检测,这可以应用于不同的目标检测器;(2) 设计了全尺度门控融合模块,根据不同尺度和纵横比的目标提取判别表示;(3) 类别级判别器模型既考虑了不同类别中的实例判别能力,又考虑了源域和目标域之间的类别一致性;(4) 在五种域自适应算法上,作者提出的方法达到了最先进的性能。
2. 方法
如图3所示,给定来自源域s 和 目标域t 的图像,首先使用 backbone 计算基本特征映射,然后通过全尺度门控融合模块对像素级特征进行融合,生成多尺度实例的判别表示。在融合特征的基础上,目标检测能够更加准确地识别出目标。同时引入了多粒度判别器,从像素级、实例级和类别级等不同角度来区分源域和目标域之间的特征分布。
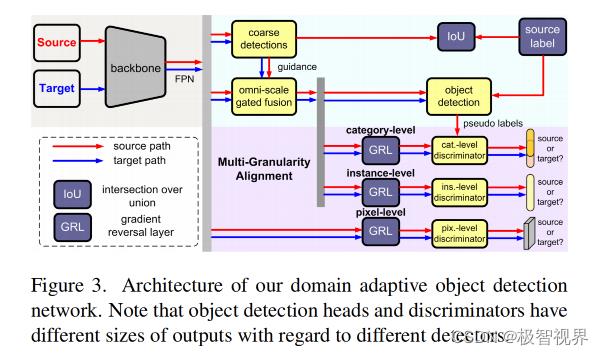
值得注意的是,作者的方法可以应用于不同的检测器 (如基于 anchor 的 Faster RCNN 和 anchor-free 的 FCOS) 和 backbones (如 VGG-16 和 ResNet-101)。在不丧失通用性的情况下,首先以 FCOS 为例,然后说明提出的方法是如何在 Faster RCNN 中应用的。对于 FCOS 检测器,提出了 backbone 特征映射的 后三个阶段,并使用 FPN 将它们组合成多级特征映射 F^k,k∈3, 4, 5, 6, 7 。
2.1 全尺度门控目标检测
以往的域自适应方法大多集中在特定级别和注意力区域的鉴别器上,然而 anchor-free 模型中的点表示难以在杂乱的背景中提取鲁棒性强的特征,而基于 anchor 的模型中的 AlignROI 操作可能会扭曲不同尺度和纵横比的目标特征。为了解决这个问题,作者采用了全尺度门控融合模块来适应不同尺度和纵横比的各种情况。具体而言,在粗检测的尺度指导下,选择具有不同 kernels 的最合理的卷积来提取实例在目标尺度方面的紧凑特征,因此它可以应用于不同的检测器。
Scale guidance 其次是多级特征映射 F^k,咱们可以通过使用一系列卷积层来预测候选目标框。根据《Generalized intersection over union: A metric and a loss for bounding box regression》作者使用交叉熵 IoU loss 来回归前景像素中目标的 bounding boxes,如公式(1)。
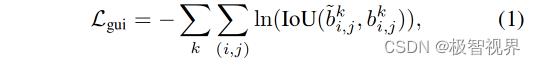
对于特征映射中的每个像素 (i, j),对应的 box 可以定义为一个4维向量,分别表示当前位置与 ground truth box 的上、下、左、右边界之间的距离。因此,可以将每个级别的归一化目标比例用公式(2) 进行计算。
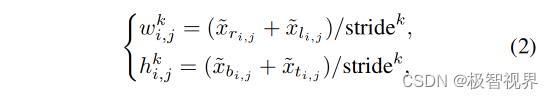
如 FCOS 检测器所定义的,每个级别的特征映射用于单独检测范围 [−1, 64], [64, 128], [128, 256], [256, 512], [512, +∞] 内具有不同尺度的目标,因此大多数目标尺度小于8。
Omni-scale gated fusion 为了适应不同尺度、不同纵横比的目标,作者设计了由低分辨流和高分辨率流组成的全尺度门控融合模块。如图4所示,低分辨率流包含三个具有不同内核 (w ∈ 3x3, 3x5, 5x3) 的并行卷积层,用于小目标的特征提取。在高分辨率流中,首先应用步长为 2 的 3x3 卷积层来扩展感受野,然后应用内核为 w (w^k>5, h^k>5) 的卷积层来处理大目标。
之后,引入门掩码 G 根据预测的粗框来对每个卷积层进行加权,如 公式(3)。
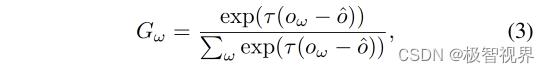
最后,可以合并像素级特征以利用实例的尺度表示,如公式(4)。
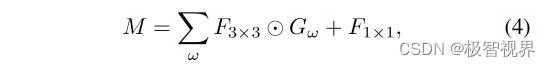
Object detection 在获得合并的特征映射 M 后,开始预测目标的类别和 bounding boxes。在 FCOS 网络中,目标检测头由分类、中心度和回归分支组成。分类和中心度分支通过 focal loss 和 交叉熵损失来进行优化,而回归分支采用 IoU损失来进行优化。总的损失函数定义为 公式(5)。
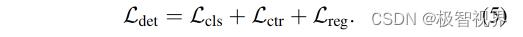
2.2 多粒度鉴别器
如引言部分讨论,应用多粒度鉴别器通过像素、实例和类别在内的不同角度来识别样本是属于源域还是目标域。梯度反转层 (GRL) 减少了两个域之间的差异,该层在优化目标检测网络时转换反向梯度。鉴别器由四个堆叠的 convolution-groupnorm-relu层 和 一个额外的 3x3 卷积层组成。
Pixel-level and instance-level discriminators 像素级 和 实例级鉴别器分别用于执行特征映射像素级和实例级对齐。如图3所示,给定输入的多级特征F 和 合并特征M,类似于以前的工作,使用相同的损失函数,例如,像素级鉴别器的损失函数定义为公式(6)。
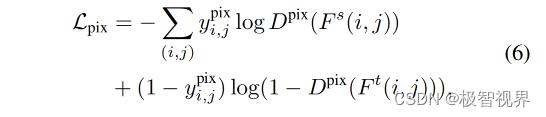
Category-level discriminator 如图2© 所示,作者的类别级鉴别器用于保持不同域分布之间的语义一致性。
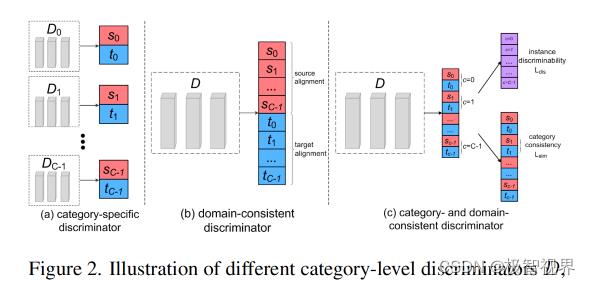
具体来说,根据输出的特征映射来预测每幅图像中像素的类别和域标记。由于没有监督类别级鉴别器的 ground-truth,咱们将伪标签分配给具有高置信度的重要样本。在实际中,给定一批输入图像,咱们可以使用目标检测头输出类别概率图,并计算所有级别上的最大类别概率。让 S 表示一组选定的实例,使其概率大于阈值。然后将不同类别的实例按公式(7) 进行分类。
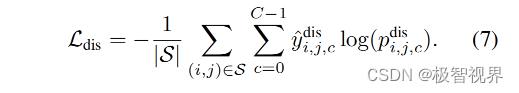
而两个域中的相同类别由公式(9) 对齐。
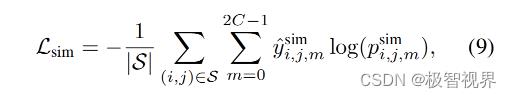
2.3 总的损失函数
全尺度门控目标检测网络由 Lgui 和 Ldet 来进行监督,同时对多粒度鉴别器进行了不同粒度的优化,包括像素级、实例级和类别级,总之,整体损失函数定义为公式(12),其中 α 是目标检测和多粒度鉴别器之间的平衡因子。
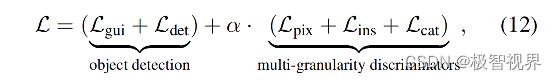
2.4 实现细节
Extension of out framework 作者为了将提出的框架扩展到 Faster-RCNN,使用步长为 16 的 backbone 特征来收集基本特征图 F。由于 Faster-RCNN 是一种 two-stage 的目标检测方法,直接使用区域建议网络 (RPN) 来预测粗略的候选框,由原始的 RPN 损失进行监督。同样,使用目标检测头中的分类和回归分支来估计目标的类别和 bounding boxes。注意 Faster-RCNN 中的 RPN 只预测前 K 个建议。为了融合不同卷积层的特征映射,首先将每个卷积层后的特征映射连接起来,然后通过 ROIAlign 操作提取每个建议的特征。最后,根据 RPN 输出,由相应的目标尺度确定合并的特征。
Optimization strategy 根据经验分两个阶段训练提出的网络。首先,禁用类别级鉴别器并在没有多尺度增强的情况下训练剩余的网络;其次,通过添加类别级鉴别器和多尺度增强来微调整个网络。该模型的学习率为 0.005,动量为 0.9,衰减权重为 0.0001。
3. 实验
表1中,在 Cityscapes 到 FoggyCityscapes 天气适应数据集上评估了提出的方法。
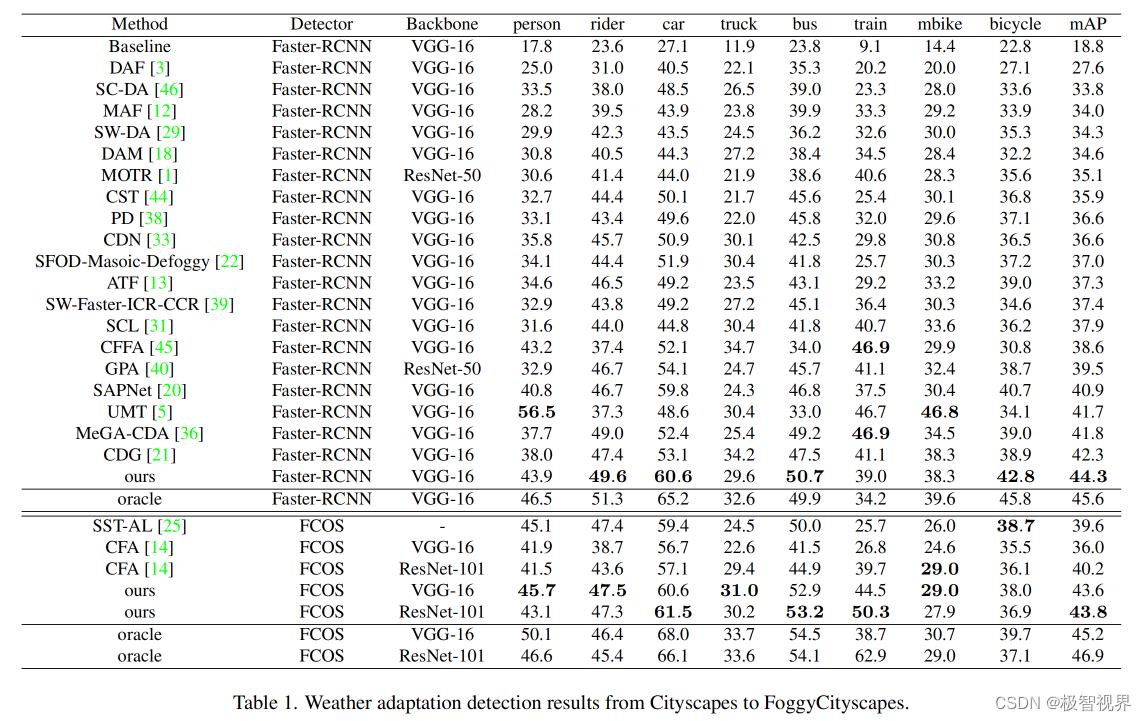
表2中,提供了 synthetic-to-real 适应数据集上的结果,其中 Sim10k 是源域,Cityscapes 是目标域。
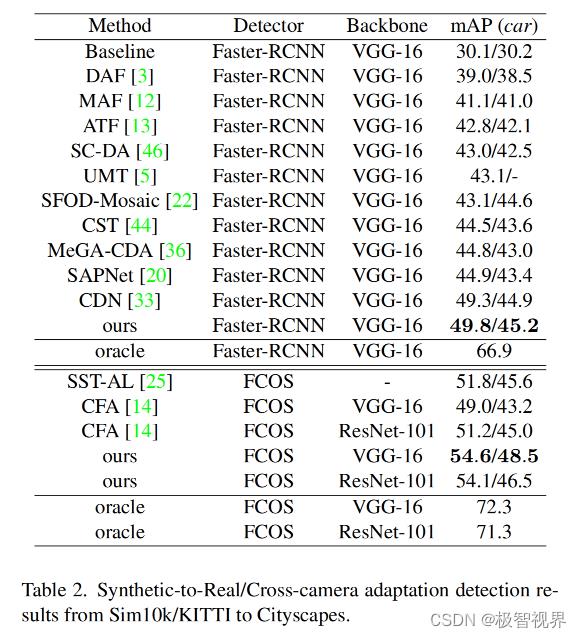
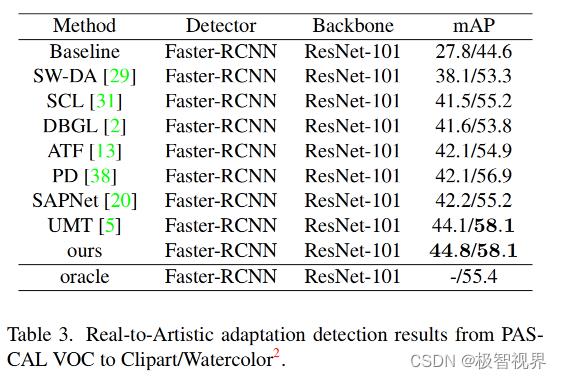
表3中使用 Faster-RCNN 和 ResNet-101 在从 PASCAL VOC 到 Clipart 和 Watercolor 的 real-to-artistic 适应数据集上评估了论文的方法。
如图5所示,所提出的全尺度门控融合和类别级鉴别器降低了自适应域中目标检测的误报。

表4中,与 baseline 方法相比,在目标检测网络中使用全尺度门控融合,显著提高了所有尺度的性能。
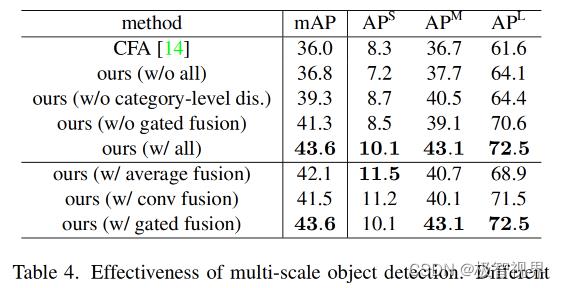
表5中,使用传统的像素级鉴别器仅获得了 39.3% 的 mAP 得分。

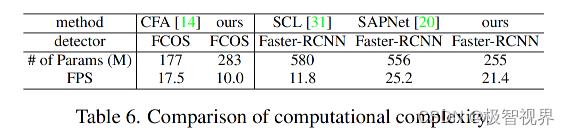
此外,在表6中展示了提出的方法与其他 SOTA 工作的计算复杂度的比较。
4. 总结
在本文中,作者对像素级、实例级和类别级信息之间的多粒度相关性进行编码,以更加准确地对齐源域和目标域的特征分布。值得注意的是,所提出的全尺度门控融合模块可以利用具有最合理卷积的多尺度特征映射中的实例特征。同时,多粒度判别器可以区分两个域上不同类别的实例。实验表明,在作者的框架中,上述设计在域自适应目标检测的不同检测器和 backbones 上具有优越性。
5. 参考
[1] Multi-Granularity Alignment Domain Adaptation for Objection Detection.
[2] Generalized intersection over union: A metric and a loss for bounding box regression.
好了,以上解读了 MGADA 用于目标检测的多粒度对齐域自适应。希望我的分享能对你的学习有一点帮助。
【极智视界】

搜索关注我的微信公众号【极智视界】,获取我的更多经验分享,让我们用极致+极客的心态来迎接AI !
以上是关于MGADA | 用于目标检测的多粒度对齐域自适应的主要内容,如果未能解决你的问题,请参考以下文章