小林coding图解操作之硬件结构
Posted xiao zhou
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小林coding图解操作之硬件结构相关的知识,希望对你有一定的参考价值。
操作系统硬件结构
1、冯诺依曼体系结构
冯诺依曼体系结构中,最重要的是定义计算机基本结构为 5 个部分,分别是运算器、控制器、存储器、输入设备、输出设备,这 5 个部分也被称为冯诺依曼模型。
并且约定使用二进制进行计算和存储。(电子计算机出现以后,使用电子管来表示多种状态过于复杂,所以所有的电子计算机中只有两种基本的状态,开和关。也就是说,电子管的两种状态决定了以电子管为基础的电子计算机采用二进制来表示数字和数据)
运算器、控制器是在中央处理器里的,存储器就我们常见的内存,输入输出设备则是计算机外接的设备,比如键盘就是输入设备,显示器就是输出设备。
存储单元和输入输出设备要与中央处理器打交道的话,离不开总线。所以,它们之间的关系如下图:

1.1 内存
存储单位是字节(byte),存储空间是从0地址线性增长。这种结构类似于数组,所以内存中每个存储空间访问速度相同(随机访问)。
1.2 中央处理器(CPU)
- 32 位 CPU 一次可以计算 4 个字节
- 64 位 CPU 一次可以计算 8 个字节
这里的32位和64位是CPU的位宽
为什么CPU带宽如此设计?
CPU 要这样设计,是为了能计算更大的数值,如果是 8 位的 CPU,那么一次只能计算 1 个字节 0~255 范围内的数值,这样就无法一次完成计算 10000 * 500 ,于是为了能一次计算大数的运算,CPU 需要支持多个 byte 一起计算,所以 CPU 位宽越大,可以计算的数值就越大,比如说 32 位 CPU 能计算的最大整数是 4294967295。
CPU内部还有一些组件,如:寄存器、控制单元、逻辑运算单元。
寄存器种类各有不同,各自又有不同的作用。
- 通用寄存器,用来存放需要进行运算的数据,比如需要进行加和运算的两个数据。
- 程序计数器,用来存储 CPU 要执行下一条指令「所在的内存地址」,注意不是存储了下一条要执行的指令,此时指令还在内存中,程序计数器只是存储了下一条指令的地址。
- 指令寄存器,用来存放程序计数器指向的指令,也就是指令本身,指令被执行完成之前,指令都存储在这里。
1.3 总线
总线是用于 CPU 和内存以及其他设备之间的通信,总线可分为 3 种:
- 地址总线,用于指定 CPU 将要操作的内存地址
- 数据总线,用于读写内存的数据
- 控制总线,用于发送和接收信号,比如中断、设备复位等信号,CPU 收到信号后自然进行响应,这时也需要控制总线
1.4 输入输出设备
输入设备向计算机输入数据,计算机经过计算后,把数据输出给输出设备。期间,如果输入设备是键盘,按下按键时是需要和 CPU 进行交互的,这时就需要用到控制总线了。
2、线路位宽与 CPU 位宽
计算机中的数据都是二进制,而二进制的数据传输是通过高低电压(高电压表示1,低电压表示0)
如果只有一位线路,那么就意味着一次只能传输一个bit的内容
数字10,二进制是1010,占用了四个bit位,那么在一条线路的情况想传输的话,最少就需要四次线路传输。
基于这种情况,我们想尽可能的提高数据传输的性能,我们就要适当提高线路位数。
32位线路,可以表述2^ 32;64位线路,可以表述2^ 64
CPU 的位宽最好不要小于线路位宽,比如 32 位 CPU 控制 40 位宽的地址总线和数据总线的话,工作起来就会非常复杂且麻烦,所以 32 位的 CPU 最好和 32 位宽的线路搭配,因为 32 位 CPU 一次最多只能操作 32 位宽的地址总线和数据总线。
如果用 32 位 CPU 去加和两个 64 位大小的数字,就需要把这 2 个 64 位的数字分成 2 个低位 32 位数字和 2 个高位 32 位数字来计算,先加个两个低位的 32 位数字,算出进位,然后加和两个高位的 32 位数字,最后再加上进位,就能算出结果了,可以发现 32 位 CPU 并不能一次性计算出加和两个 64 位数字的结果。
但是并不代表 64 位 CPU 性能比 32 位 CPU 高很多,很少应用需要算超过 32 位的数字,所以如果计算的数额不超过 32 位数字的情况下,32 位和 64 位 CPU 之间没什么区别的,只有当计算超过 32 位数字的情况下,64 位的优势才能体现出来。
另外,32 位 CPU 最大只能操作 4GB 内存,就算你装了 8 GB 内存条,也没用。而 64 位 CPU 寻址范围则很大,理论最大的寻址空间为 2^64。
3.存储器
3.1 存储器的层次结构
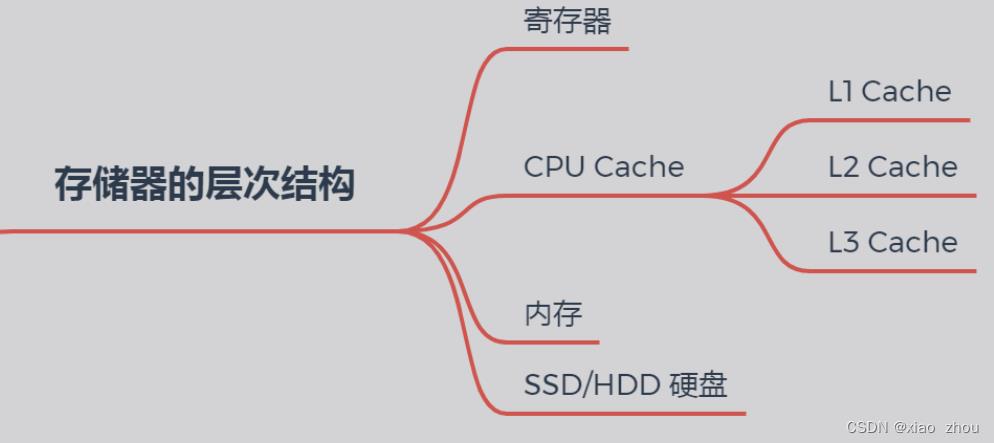
- 速度:寄存器 > CPU Cache > 内存 > 硬盘
- 容量:寄存器 < CPU Cache < 内存 < 硬盘
(1)寄存器:寄存器是最快的,它直接把数据提供给CPU快速处理,但是存储量通常只有几KB
(2)CPU Cache:中文称为 CPU 高速缓存,CPU Cache 用的是一种叫 SRAM(Static Random-Access Memory,静态随机存储器) 的芯片。处理速度相比寄存器慢了一点,但是能存储的数据也稍微多了一些。
CPU Cache通常分为L1 L2 L3,3层。
其中 L1 Cache 通常分成「数据缓存」和「指令缓存」,L1 是距离 CPU最近的,因此它比 L2、L3 的读写速度都快、存储空间都小。
L2 Cache同样每个 CPU 核心都有,但是 L2 高速缓存位置比 L1 高速缓存距离 CPU 核心 更远,它大小比 L1 高速缓存更大,CPU 型号不同大小也就不同,通常大小在几百 KB 到几 MB 不等,访问速度则更慢。
L3 Cache通常是多个 CPU 核心共用的,位置比 L2 高速缓存距离 CPU 核心 更远,大小也会更大些,通常大小在几 MB 到几十 MB 不等。
寄存器和 CPU Cache 都是在 CPU 内部,跟 CPU 挨着很近,因此它们的读写速度都相当的快,但是能存储的数据很少。
(3)内存:使用的是一种叫作 DRAM (Dynamic Random Access Memory,动态随机存取存储器) 的芯片。系统和软件的运行空间是由内存提供。
(3)硬盘:相比内存的优点是断电后数据还是存在的,而内存、寄存器、高速缓存断电后数据都会丢失。
总结
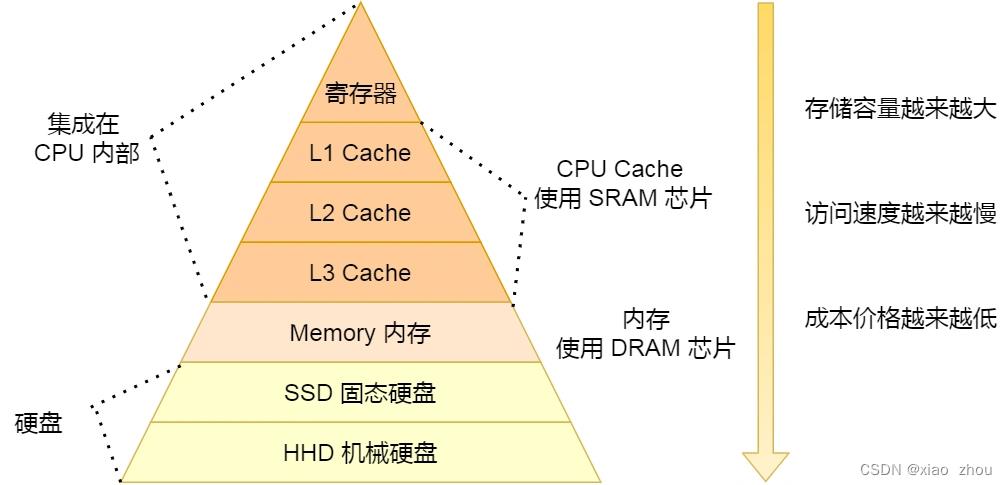
每个存储器只和相邻的一层存储器设备打交道,并且存储设备为了追求更快的速度,所需的材料成本必然也是更高,也正因为成本太高,所以 CPU 内部的寄存器、L1\\L2\\L3 Cache 只好用较小的容量,相反内存、硬盘则可用更大的容量,这就我们今天所说的存储器层次结构。
4.CPU缓存一致性
CPU 从内存中读取数据到 Cache 的时候,并不是一个字节一个字节读取,而是一块一块的方式来读取数据的,这一块一块的数据被称为 CPU Cache Line(缓存块),所以 CPU Cache Line 是 CPU 从内存读取数据到 Cache 的单位。
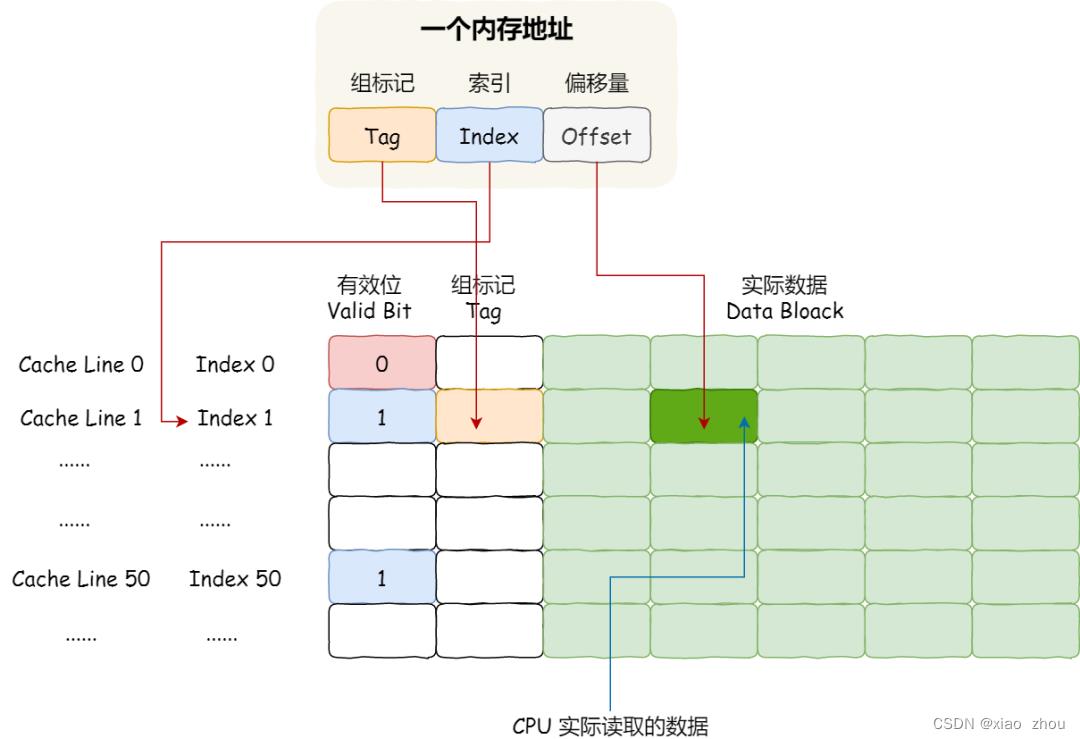
4.1 CPU Cache 的数据写入
1、写直达
保持内存与 Cache 一致性最简单的方式是,把数据同时写入内存和 Cache 中,这种方法称为写直达。
在这个方法里,写入前会先判断数据是否已经在 CPU Cache 里面了:
- 如果数据已经在 Cache 里面,先将数据更新到 Cache 里面,再写入到内存里面;
- 如果数据没有在 Cache 里面,就直接把数据更新到内存里面。
写直达法很直观,也很简单,但是问题明显,无论数据在不在 Cache 里面,每次写操作都会写回到内存,这样写操作将会花费大量的时间,无疑性能会受到很大的影响。
2、写回
在写回机制中,当发生写操作时,新的数据仅仅被写入 Cache Block 里,只有当修改过的 Cache Block「被替换」时才需要写到内存中,减少了数据写回内存的频率,这样便可以提高系统的性能。
那具体如何做到的呢?下面来详细说一下:
- 如果当发生写操作时,数据已经在 CPU Cache 里的话,则把数据更新到 CPU Cache 里,同时标记 CPU Cache 里的这个 Cache Block 为脏(Dirty)的,这个脏的标记代表这个时候,我们 CPU Cache 里面的这个 Cache Block 的数据和内存是不一致的,这种情况是不用把数据写到内存里的;
- 如果当发生写操作时,数据所对应的 Cache Block 里存放的是「别的内存地址的数据」的话,就要检查这个 Cache Block 里的数据有没有被标记为脏的:
(1)如果是脏的话,我们就要把这个 Cache Block 里的数据写回到内存,然后再把当前要写入的数据,先从内存读入到 Cache Block 里,然后再把当前要写入的数据写入到 Cache Block,最后也把它标记为脏的;
(2)如果 Cache Block 里面的数据没有被标记为脏,则就直接将数据写入到这个 Cache Block 里,然后再把这个 Cache Block 标记为脏的就好了。
这样的好处是,如果我们大量的操作都能够命中缓存,那么大部分时间里 CPU 都不需要读写内存,自然性能相比写直达会高很多。
4.2 缓存一致性的问题
现在 CPU 都是多核的,由于 L1/L2 Cache 是多个核心各自独有的,那么会带来多核心的缓存一致性(Cache Coherence) 的问题,如果不能保证缓存一致性的问题,就可能造成结果错误。
那么,要解决这一问题,就需要一种机制,来同步两个不同核心里面的缓存数据。要实现的这个机制的话,要保证做到下面这 2 点:
- 第一点,某个 CPU 核心里的 Cache 数据更新时,必须要传播到其他核心的 Cache,这个称为写传播(Write Propagation)
- 第二点,某个 CPU 核心里对数据的操作顺序,必须在其他核心看起来顺序是一样的,这个称为事务的串行化(Transaction Serialization)。
(1)对于第一点很好理解,我们要做的就是,当一个CPU在自己的Cache中更新了数据,那么我们就要将其更新到其他其他CPU的Cache中。
(2)第二点解决的问题是,当多个CPU对变量进行改变时,(一号CPU对变量赋值为100,二号CPU对变量赋值为200),其他CPU在进行写传播的顺序问题。(三号CPU是先变100再变200,或者先变200再变100,这是无法确定的)
而保证所有CPU都能做到相同的数据变化顺序的过程就是事务的串行化
核心
1、CPU 核心对于 Cache 中数据的操作,需要同步给其他 CPU 核心;
2、要引入「锁」的概念,如果两个 CPU 核心里有相同数据的 Cache,那么对于这个 Cache 数据的更新,只有拿到了「锁」,才能进行对应的数据更新。
接下来将说明如何实现事物的串行化
4.3 总线嗅探
写传播的原则就是当某个 CPU 核心更新了 Cache 中的数据,要把该事件广播通知到其他核心。最常见实现的方式是总线嗅探(Bus Snooping)。
总线嗅探就是,当某一CPU将其L1 Cache中的变量修改,就会通过总线把这个事件广播给其他所有CPU。然后每个 CPU 核心都会监听总线上的广播事件,并检查是否有相同的数据在自己的 L1 Cache 里面,如果其他CPU 核心的 L1 Cache 中有该数据,那么也需要把该数据更新到自己的 L1 Cache。
缺点:可以发现,总线嗅探方法很简单, CPU 需要每时每刻监听总线上的一切活动,但是不管别的核心的 Cache 是否缓存相同的数据,都需要发出一个广播事件,这无疑会加重总线的负载。另外,总线嗅探只是保证了某个 CPU 核心的 Cache 更新数据这个事件能被其他 CPU 核心知道,但是并不能保证事务串行化。
于是,有一个协议基于总线嗅探机制实现了事务串行化,也用状态机机制降低了总线带宽压力,这个协议就是 MESI 协议,这个协议就做到了 CPU 缓存一致性。
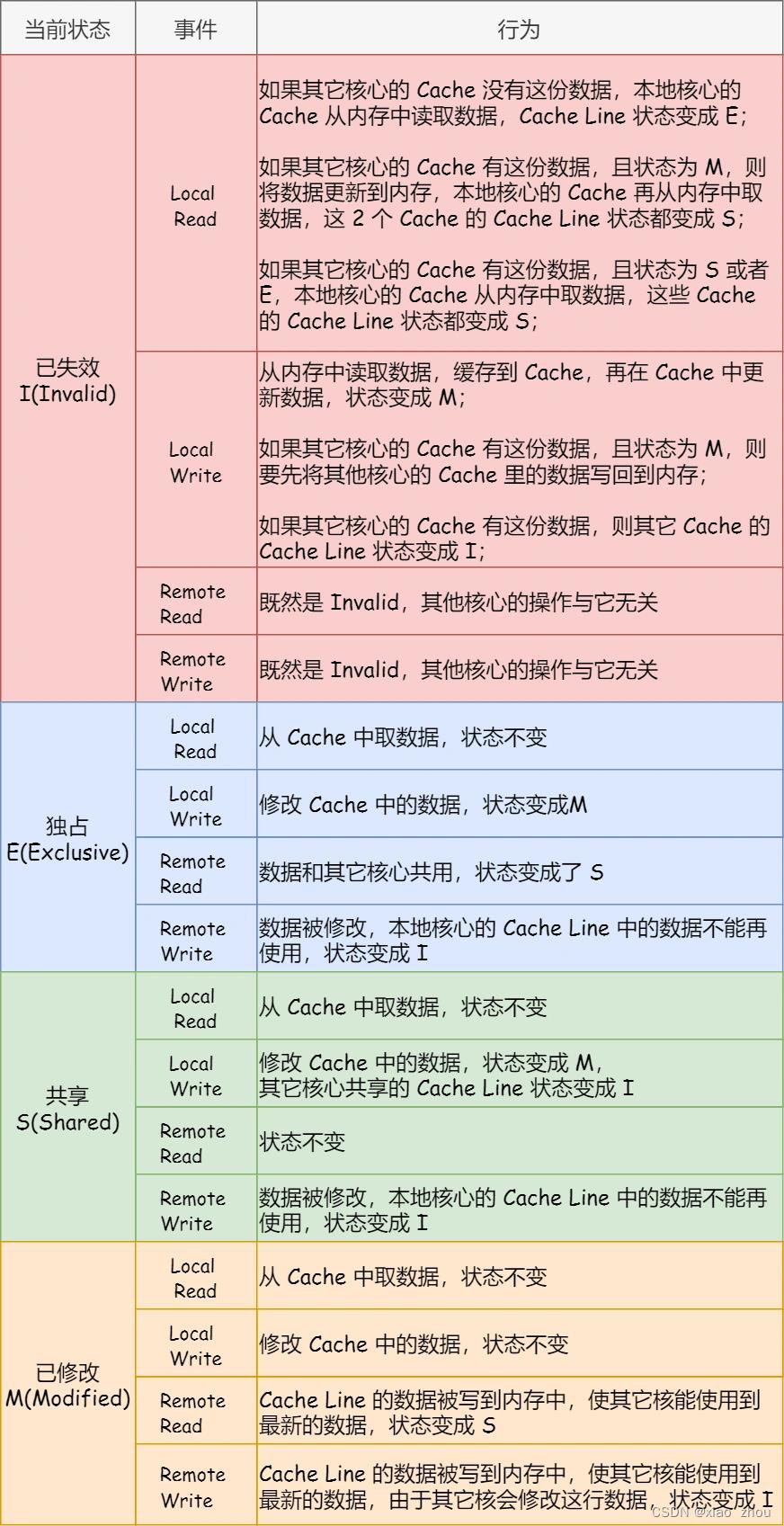
4.4 MESI 协议
MESI 协议其实是 4 个状态单词的开头字母缩写,分别是:
- Modified,已修改
- Exclusive,独占
- Shared,共享
- Invalidated,已失效
这四个状态来标记 Cache Line 四个不同的状态。
(1)「已修改」状态就是我们前面提到的脏标记,代表该 Cache Block 上的数据已经被更新过,但是还没有写到内存里。
(2)而「已失效」状态,表示的是这个 Cache Block 里的数据已经失效了,不可以读取该状态的数据。
(3)「独占」和「共享」状态都代表 Cache Block 里的数据是干净的,也就是说,这个时候 Cache Block 里的数据和内存里面的数据是一致性的。
(4)「独占」和「共享」的差别在于,独占状态的时候,数据只存储在一个 CPU 核心的 Cache 里,而其他 CPU 核心的 Cache 没有该数据。这个时候,如果要向独占的 Cache 写数据,就可以直接自由地写入,而不需要通知其他 CPU 核心,因为只有你这有这个数据,就不存在缓存一致性的问题了,于是就可以随便操作该数据。另外,在「独占」状态下的数据,如果有其他核心从内存读取了相同的数据到各自的 Cache ,那么这个时候,独占状态下的数据就会变成共享状态。
(5)「共享」状态代表着相同的数据在多个 CPU 核心的 Cache 里都有,所以当我们要更新 Cache 里面的数据的时候,不能直接修改,而是要先向所有的其他 CPU 核心广播一个请求,要求先把其他核心的 Cache 中对应的 Cache Line 标记为「无效」状态,然后再更新当前 Cache 里面的数据。
4.5 CPU读写数据
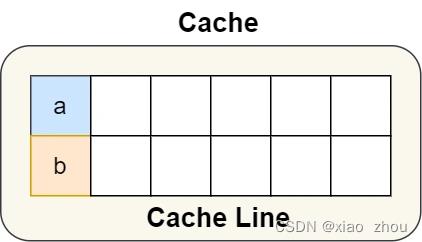
4.5.1 伪共享
因为多个线程同时读写同一个 Cache Line 的不同变量时,而导致 CPU Cache 失效的现象称为伪共享(False Sharing)。
解释:CPU读取数据是以Cache Line为单位,如果多个线程同时读写同一个 Cache Line 的不同变量,根据MESI协议,这多个线程每次读写各自变量时候,仍然会反复将Cache Line写入内存并再读取回来,没有起到提高性能的效果。
避免方法:在 Linux 内核中存在 __cacheline_aligned_in_smp 宏定义,是用于解决伪共享的问题。
- 如果在多核(MP)系统里,该宏定义是 __cacheline_aligned,也就是 Cache Line 的大小;
- 而如果在单核系统里,该宏定义是空的;
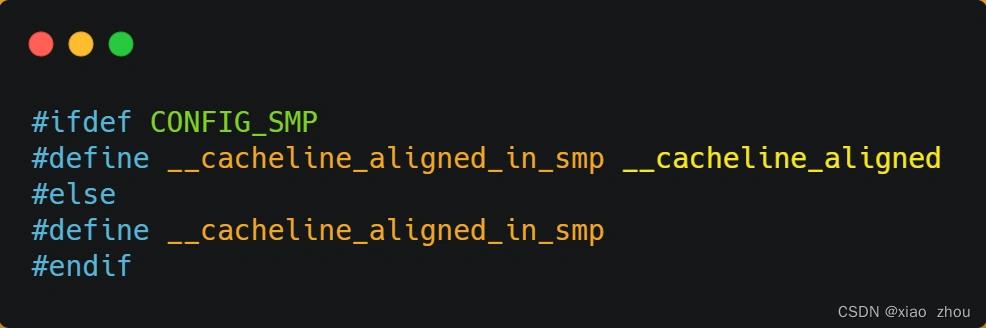
使用方法:
这样a,b两个变量就不会在同一个Cache Line中了。

原文在小林coding
以上是关于小林coding图解操作之硬件结构的主要内容,如果未能解决你的问题,请参考以下文章