Redis_17_Redis服务器中的数据库(五种基本类型底层存放)
Posted 毛奇志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis_17_Redis服务器中的数据库(五种基本类型底层存放)相关的知识,希望对你有一定的参考价值。
文章目录
- 一、前言
- 二、RedisObject对象
- 三、字符串对象string
- 四、列表对象list
- 五、哈希对象hash(map)
- 六、集合对象set
- 七、有序集合对象sortedset
- 八、五种基本类型的特点与应用
- 九、尾声
一、前言
上一篇介绍了 Redis服务器中的数据库(键值对的存放和生存时间的存放),这篇介绍 Redis服务器中的数据库(五种基本类型底层存放)。
二、RedisObject对象
这个很重要,要看懂后面五个类型的底层结构,要先搞懂redisObjet和sds(sdshdr)的结构,其中redisObject包括类型type、编码encoding,sds包括 free、len、buf 三个属性
2.1 RedisObject对象
Redis基于以上的数据结构创建了一个对象体系,包含了字符串对象,列表对象,哈希对象,集合对象,有序集合对象这五种对象.
Redis的对象体系还实现了基于引用计数技术的内存回收机制,同时基于引用计数技术实现了对象共享机制,在适当条件,通过多个数据库键共享同一个对象来节约内存.
Redis中的每一个对象都由一个redisObject结构表示,这个redisObject对象结构中和保存数据有关的三个属性:type属性、encoding属性、ptr属性,如下:
typedef struct redisObject
//类型
unsigned type:4;
//编码
unsigned encoding:4;
//指向底层实现数据结构的指针
void *ptr;
// ...
robj;
下面分别对类型type、编码encoding、指针ptr分别介绍:
2.2 类型type
| 类型常量 | 对象名称 | TYPE命令输出 |
|---|---|---|
| REDIS_STRING | 字符串对象string | “string” |
| REDIS_LIST | 列表对象list | “list” |
| REDIS_HASH | 哈希对象hash(map) | “hash” |
| REDIS_SET | 集合对象set | “set” |
| REDIS_ZSET | 有序集合对象sorted-set | “zset” |
注意,看这个表,一定要区分好“类型常量”、“对象名称”,如下:
1)当我们称呼一个数据库键为“字符串键”时,我们指的是“这个数据库键对应的值为字符串对象”;当我们称呼一个数据库键为“列表键”时,我们指的是“这个数据库键对应的值为列表对象”;
2)TYPE命令输出(上表第三列):当我们对一个数据库键执行TYPE命令时,命令返回的结果是数据库键对应的值对象的类型,而不是键对象的类型。
其实,这些东西都是一些概念理论上的纠结,实际开发中,我们以实现需求为主,也不一定要区分的这么清楚,当然面试中可能用得到。
2.3 编码encoding
| 编码常量 | 编码对应的底层数据结构 | redis中具体类型(5种) | OBJECT ENCODING 命令输出 |
|---|---|---|---|
| REDIS_ENCODING_INT | long类型整数(编码常量后缀是INT,但是其实现的底层数据结构是long) | REDIS_STRING | “int” |
| REDIS_ENCODING_EMBSTR | embstr编码的简单动态字符串(SDS simple dynamic string) | REDIS_STRING | “embstr” |
| REDIS_ENCODING_RAW | raw编码的简单动态字符串(SDS simple dynamic string) | REDIS_STRING | “raw” |
| REDIS_ENCODING_HT | 字典(编码常量后缀为HT,表示dictionary/hashtable,即字典) | REDIS_HASH、REDIS_SET | “hashtable” |
| REDIS_ENCODING_LINKEDLIST | 双向链表/双端链表(linkedlist,见名达意,不解释) | REDIS_LIST | “linkedlist” |
| REDIS_ENCODING_ZIPLIST | 压缩列表(ziplist,见名达意,不解释) | REDIS_LIST、REDIS_HASH、REDIS_ZSET | “ziplist” |
| REDIS_ENCODING_INTSET | 整型集合(intset,见名达意,不解释) | REDIS_SET | “intset” |
| REDIS_ENCODING_SKIPLIST | 跳跃表和字典(skiplist,见名达意,不解释) | REDIS_ZSET | “skiplist” |
2.4 sds
sds英文全称 simple dynamic string,这里是简单动态字符串,这个很重要,下面会用到。
struct sdshdr
// 记录buf数组中未使用字节的数量
int free;
// 记录buf数组中已使用字节的数量,等于sds所保存字符串的长度
int len;
// 字节数组,用于保存字符串
char buff[];
结构(下面介绍五种基本类型底层结构会用到):

free:0 表示这个sds没有分配任何未使用空间;
len:5 表示这个sds保存了一个5个字节的字符串;
buf:Hello 表示一个char类型的数组,数组的前五个字节分别保存了‘H’‘e’‘l’‘l’‘o’,最后一个字符保存了空字符‘\\0’.
三、字符串对象string
由上面的编码表可以知道,字符串编码包括三种 int raw embstr,三者对比:
如果保存的是整数值,且可用long类型表示,那么编码设为int;
如果保存的是一个字符串,并且长度大于32字节,那么使用SDS(simple dynamic string,简单动态字符串)保存,编码设为raw;
如果保存的是一个字符串,并且长度小于或等于32字节,那么编码设为embstr;
3.1 int编码

对于这个图的解释:
redisObject:
分为三个 类型type 编码encoding 指针ptr
type为五种基本类型,这里为string
encoding,redis任何一种基本类型至少有两种编码,这里是int
ptr:指针,指向底层数据结构的指针,这里指向底层long类型数据7758258
3.2 raw编码

对于这个图的解释:
redisObject: 分为三个 类型type 编码encoding 指针ptr
type为五种基本类型,这里为string
encoding,redis任何一种基本类型至少有两种编码,这里是raw
ptr:指针,指向底层数据结构的指针,这里指向sdshdr
sdshdr :
sds simple dynamic string,简单动态字符串 ; hdr High available Data Replication,高可用性复制 ; 合在一起 sds hdr 简单动态字符串高可用性复制,包括三个 free 表示
free:0 表示这个sds没有分配任何未使用空间;
len:36表示这个sds保存了一个36个字节的字符串;
buf:Hello 表示一个char类型的数组,数组的前36个字节分别保存了’H’‘e’‘l’‘l’‘o’‘ ’‘w’‘o’‘r’‘l’‘d’'H’‘e’‘l’‘l’‘o’‘ ’‘w’‘o’‘r’‘l’‘d’‘H’‘e’‘l’‘l’‘o’‘ ’‘w’‘o’‘r’‘l’‘d’’.’‘.’‘.’,
最后一个字符保存了空字符‘\\0’.
3.3 embstr编码
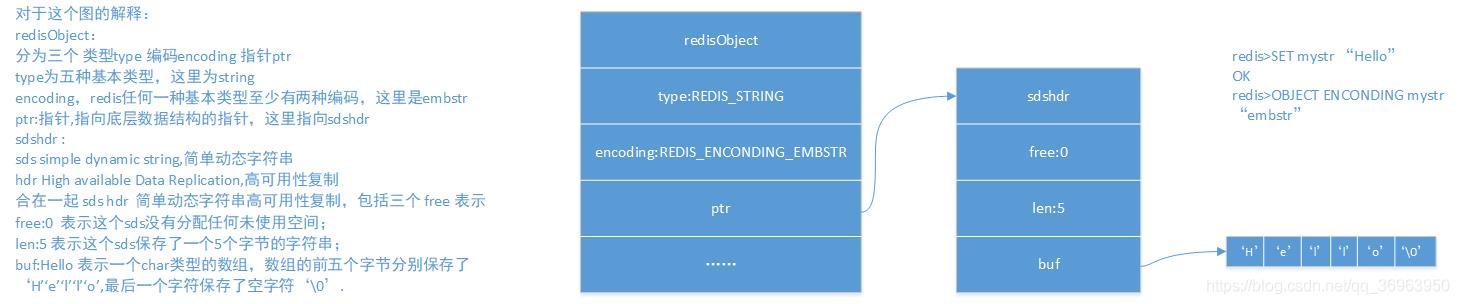
对于这个图的解释:
redisObject:
分为三个 类型type 编码encoding 指针ptr
type为五种基本类型,这里为string
encoding,redis任何一种基本类型至少有两种编码,这里是embstr
ptr:指针,指向底层数据结构的指针,这里指向sdshdr
sdshdr :
sds simple dynamic string,简单动态字符串
hdr High available Data Replication,高可用性复制
合在一起 sds hdr 简单动态字符串高可用性复制,包括三个 free 表示
free:0 表示这个sds没有分配任何未使用空间;
len:5 表示这个sds保存了一个5个字节的字符串;
buf:Hello 表示一个char类型的数组,数组的前五个字节分别保存了‘H’‘e’‘l’‘l’‘o’,最后一个字符保存了空字符‘\\0’.
最后点一下,用long double类型表示的浮点数在redis中也是字符串来表示的,了解即可。
编码是指存储类型的方式,字符串对象中embstr编码和raw编码有什么区别?
当字符串长度小于32字节,字符串对象将使用emstr编码,大于32字节,字符串使用raw。
embstr直接一次性创建一块内存,内存一定是连续的;raw会分别两次创建redisObject结构与sdshdr结构,内存不一定是连续的。
embstr优势:
(1) 内存释放更快:内存释放是embstr只需要释放一次,而raw需要释放两次
(2) 查找更快: embstr查找的更快
四、列表对象list
由上面的编码表可以知道,字符串编码包括两种:linkedlist ziplist
4.1 ziplist编码

zlbytes:表示的是总长度,总字节数
zllen:表示的是数据部分的长度
两个不一样的。
4.2 linkedlist编码
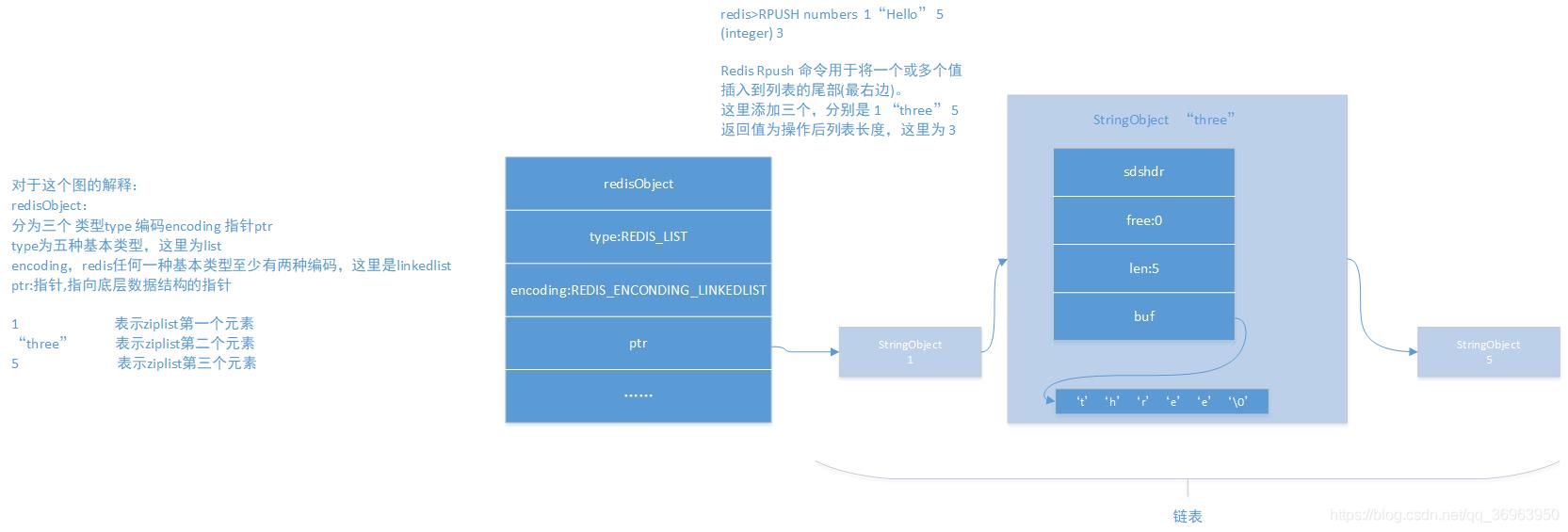
对于这个图的解释:
redisObject:
分为三个 类型type 编码encoding 指针ptr
type为五种基本类型,这里为list
encoding,redis任何一种基本类型至少有两种编码,这里是linkedlist
ptr:指针,指向底层数据结构的指针
1 表示ziplist第一个元素
“three” 表示ziplist第二个元素
5 表示ziplist第三个元素
list两种编码方式(ziplist和linkedlist区别)
选用:当列表对象保存的所有字符串元素的长度都小于64字节,并且列表对象保存的元素数量小于512时,list使用ziplist编码;不能满足这两种情况就是用linkedlist编码。
优缺点:ziplist的特点是节省内存,但是插入速度慢;linkedlist是一个双向列表,特点就是插入速度快,但是占内存。
参考:https://blog.csdn.net/weixin_33775572/article/details/92675537
五、哈希对象hash(map)
由上面的编码表可以知道,字符串编码包括两种:ziplist hashtable
5.1 ziplist编码

对于这个图的解释:
redisObject:
分为三个 类型type 编码encoding 指针ptr
type为五种基本类型,这里为list
encoding,redis任何一种基本类型至少有两种编码,这里是ziplist
ptr:指针,指向底层数据结构的指针
zlbytes: 表示整个ziplist的字节数(总长度)
zltail: 表示整个ziplist的头部
zllen: 表示整个ziplist 数据部分的长度
(key,value)=(name,Tom) 表示ziplist第一个元素
(key,value)=(age,25) 表示ziplist第二个元素
(key,value)=(career,Programmer) 表示ziplist第三个元素
zlled 表示整个ziplist的尾部
5.2 hashtable编码
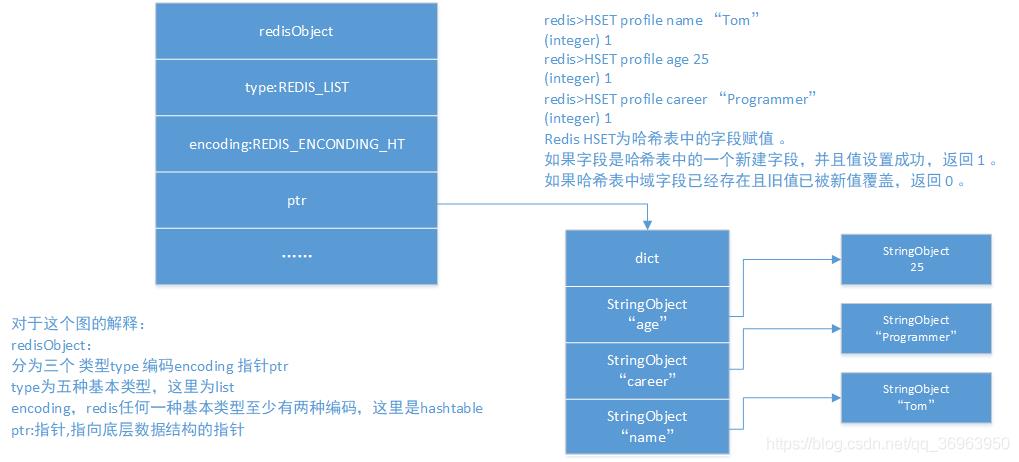
对于这个图的解释:
redisObject:
分为三个 类型type 编码encoding 指针ptr
type为五种基本类型,这里为list
encoding,redis任何一种基本类型至少有两种编码,这里是hashtable
ptr:指针,指向底层数据结构的指针
hash对象的ziplist编码和hashtable编码
(参考:https://blog.csdn.net/zwx900102/article/details/109707329)
当一个哈希对象可以满足以下两个条件中的任意一个,哈希对象会选择使用ziplist编码来进行存储:1、哈希对象中的所有键值对总长度(包括键和值)小于64字节(这个阈值可以通过参数hash-max-ziplist-value 来进行控制)。
2、哈希对象中的键值对数量小于512个(这个阈值可以通过参数hash-max-ziplist-entries 来进行控制)。
一旦不满足这两个条件中的任意一个,哈希对象就会选择使用hashtable来存储。
六、集合对象set
由上面的编码表可以知道,字符串编码包括两种:intset hashtable
6.1 intset编码
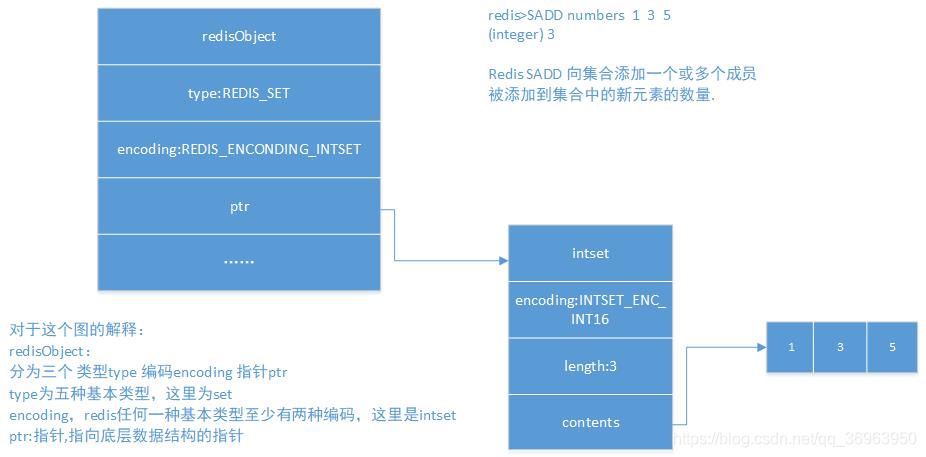
对于这个图的解释:
redisObject:
分为三个 类型type 编码encoding 指针ptr
type为五种基本类型,这里为set
encoding,redis任何一种基本类型至少有两种编码,这里是intset
ptr:指针,指向底层数据结构的指针
set对象inset和hashtable编码转换:
当Set对象可以同时满足以下两个条件时, 对象使用 intset 编码:
1.Set对象保存的所有元素都是整数值;
2.Set对象保存的元素数量不超过 512 个;
不能满足这两个条件的Set对象需要使用 hashtable 编码。
参考:https://blog.csdn.net/chongfa2008/article/details/118754079
6.2 hashtable编码
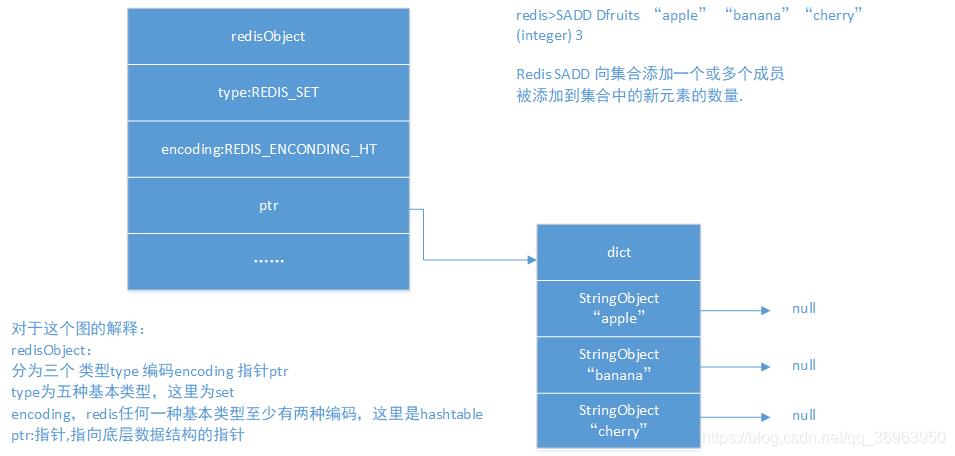
对于这个图的解释:
redisObject:
分为三个 类型type 编码encoding 指针ptr
type为五种基本类型,这里为set
encoding,redis任何一种基本类型至少有两种编码,这里是hashtable
ptr:指针,指向底层数据结构的指针
七、有序集合对象sortedset
有序集合是list和set的一种居中,如下:

由上面的编码表可以知道,字符串编码包括两种:ziplist skiplist
7.1 ziplist编码
ziplist编码的有序集合对象使用压缩列表作为底层实现。每个集合使用2个紧挨在一起的压缩列表节点来保存,第一个保存元素的成员,第二个保存元素的分值。压缩列表内的集合按分值从小到大排序,分值较小的元素被放置在靠近表头的位置,分值较大的元素在靠近表尾的位置。
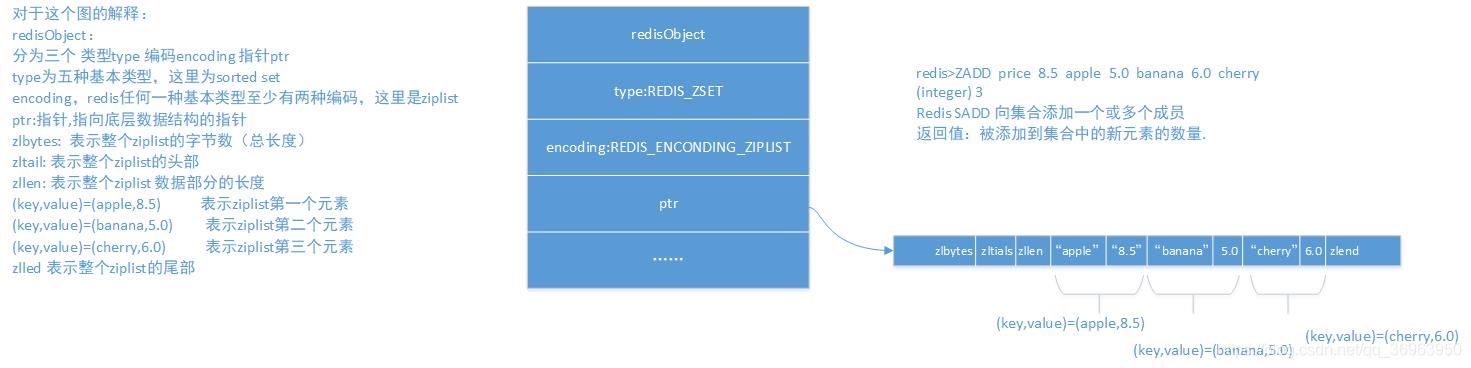
对于这个图的解释:
redisObject:
分为三个 类型type 编码encoding 指针ptr
type为五种基本类型,这里为sorted set
encoding,redis任何一种基本类型至少有两种编码,这里是ziplist
ptr:指针,指向底层数据结构的指针
zlbytes: 表示整个ziplist的字节数(总长度)
zltail: 表示整个ziplist的头部
zllen: 表示整个ziplist 数据部分的长度
(key,value)=(apple,8.5) 表示ziplist第一个元素
(key,value)=(banana,5.0) 表示ziplist第二个元素
(key,value)=(cherry,6.0) 表示ziplist第三个元素
zlled 表示整个ziplist的尾部
7.2 skiplist编码
skiplist编码的有序集合对象使用 zset结构作为底层实现,zset结构同时包含一个字典和一个跳跃表。如下:
typedef struct zset
dict *dict; // 字典dict
zskiplist *zsl; // 跳跃表zsl
zset; //zset是有序集合,同时由字典dict和跳跃表zsl实现
为什么有序集合zset(sorted set)要同时由字典dict和跳跃表实现?
跳跃表利于执行范围操作(跳跃表是排好序的),而字典有利于执行分值查找操作。同时由于Redis里的跳跃表和字典元素很多都是用指针实现的,所以不会浪费内存。
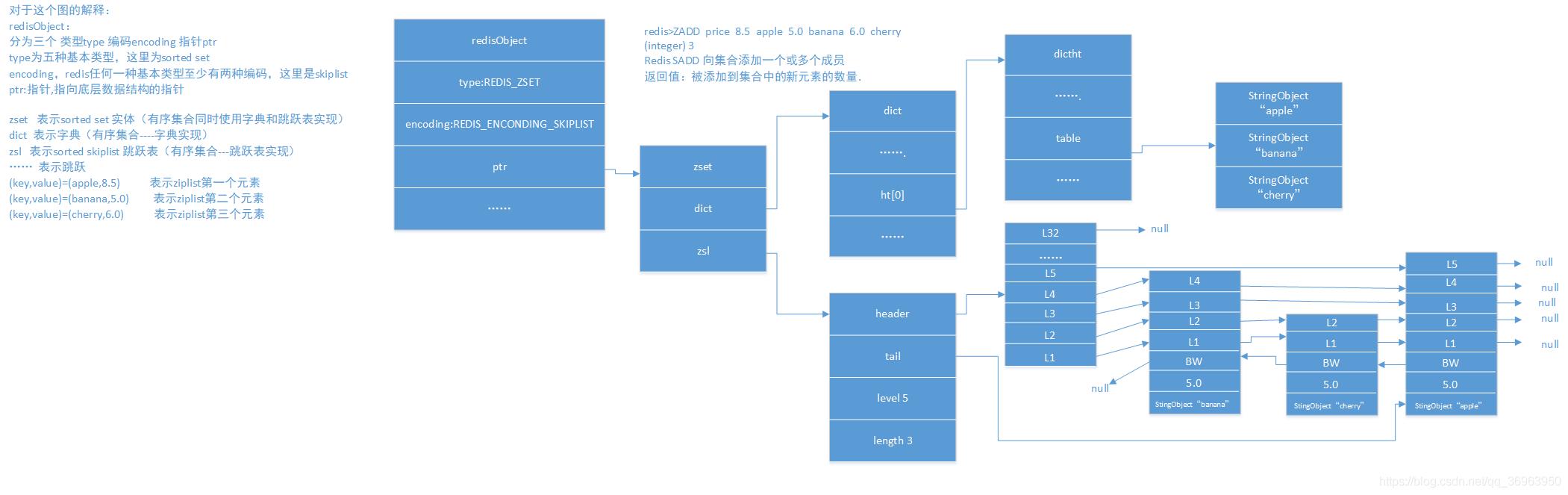
对于这个图的解释:
redisObject:
分为三个 类型type 编码encoding 指针ptr
type为五种基本类型,这里为sorted set
encoding,redis任何一种基本类型至少有两种编码,这里是skiplist
ptr:指针,指向底层数据结构的指针
zset 表示sorted set 实体
dict 表示字典
zsl 表示sorted skiplist 跳跃表
…… 表示跳跃
(key,value)=(apple,8.5) 表示ziplist第一个元素
(key,value)=(banana,5.0) 表示ziplist第二个元素
(key,value)=(cherry,6.0) 表示ziplist第三个元素
有序集合zset两个编码类型
问题:ziplist数据结构是如何保证zset有序的?
回答:通过value值,ziplist要保证集合中的数据有序,会将key放在前面一位,然后将key所对应value放在key的后一位,这样就能够保证集合的有序。
问题:skiplist数据结构是如何保证zset有序的?
回答:跳跃链表本来就是有序的,直接使用即可
问题:ziplist和skiplist的编码转换?
回答: 当有序集合对象同时满足以下两个条件时,对象使用压缩链表编码:
(1) 有序集合保存的元素数量小于128个;
(2) 有序集合保存的所有元素成员的长度都小于64字节;
如果不满足上述两个条件,那么ZipList会转化为SkipList,同时,当后面的SkipList的元素数量和元素成员的长度满足要求时,也不会回退为ZipList。
参考:https://blog.csdn.net/ABOOMMMMM/article/details/117607126
八、五种基本类型的特点与应用
8.1 String数据类型的特点与应用
String的特点:最简单的类型,就是普通的 set 和 get,做简单的 KV 缓存。
String的应用
第一,缓存功能,数据库缓存用redis的string类型实现
因为String字符串是各种语言都支持的、最常用的数据类型,不仅仅是Redis;因此,在redis连接各种语言的时候,利用Redis作为缓存,配合其它数据库作为存储层,利用Redis支持高并发的特点,可以大大加快系统的读写速度、以及降低后端数据库的压力。
金手指:redis中String作为缓存,也是String的最常用的,redis最常用的。
第二,计数器,计数用redis的string类型实现
许多系统都会使用Redis作为系统的实时计数器,可以快速实现计数和查询的功能。而且最终的数据结果可以按照特定的时间落地到数据库或者其它存储介质当中进行永久保存。
金手指:redis持久化包括AOF热备份和RDB冷备份。
第三,共享用户Session,共享用户session放到redis的String中存储
用户重新刷新一次界面,可能需要访问一下数据进行重新登录,或者访问页面缓存Cookie,但是可以利用Redis将用户的Session集中管理,在这种模式只需要保证Redis的高可用,每次用户Session的更新和获取都可以快速完成,大大提高效率。
注意:真实的开发环境中,很多人可能会把很多比较复杂的结构也统一转成String去存储使用,比如有的人就喜欢把对象或者List转换为JSONString进行存储,拿出来再反序列化,但是啥都是用的String不够优雅。但是,总原则还是:在最合适的场景使用最合适的数据结构,对象找不到最合适的但是类型可以选最合适的。
8.2 Hash数据类型的特点与应用
Hash的特点
这个是类似 Map 的一种结构,这个一般就是可以将结构化的数据,比如一个对象(前提是这个对象没嵌套其他的对象)给缓存在 Redis 里,然后每次读写缓存的时候,可以就操作 Hash 里的某个字段。
Hash的应用
hash的应用场景很少,因为现在很多对象都是比较复杂的,比如你的商品对象可能里面就包含了很多属性,其中也有对象,单一hash无法满足。
8.3 List数据类型的特点与应用
List特点
有序列表,有序,元素可以重复
List应用
(1)列表型数据item-detail:比如可以通过 List 存储一些列表型的数据结构,类似粉丝列表、文章的评论列表之类的东西。比如,对于csdn博客网站的文章列表,当用户量越来越多时,而且每一个用户都有自己的文章列表。
(2)分页数据存储:比如可以通过 lrange 命令,读取某个闭区间内的元素,可以基于 List 实现分页查询,这个是很棒的一个功能,基于 Redis 实现简单的高性能分页,可以做类似微博那种下拉不断分页的东西,性能高,就一页一页走。比如:对于csdn博客网站,当文章多时,item需要分页展示,这时可以考虑使用Redis的列表,列表不但有序同时还支持按照范围内获取元素,可以完美解决分页查询功能,大大提高查询效率。
(3)消息队列:比如可以搞个简单的消息队列,从 List 头怼进去,从 List 屁股那里弄出来。Redis的链表结构,可以轻松实现阻塞队列,可以使用左进右出的命令组成来完成队列的设计。比如:数据的生产者可以通过Lpush命令从左边插入数据,多个数据消费者,可以使用BRpop命令阻塞的“抢”列表尾部的数据。
8.4 Set数据类型的特点与应用
Set特点:无序集合,不保证顺序但是提供自动去重的功能,我们最重要的是使用他这个去重功能,下面两个实例都是。
Set应用:
(1)分布式多服务器全局数据去重:直接基于 Set 将系统里需要去重的数据扔进去,自动就给去重了,如果你需要对一些数据进行快速的全局去重,你当然也可以基于 JVM 内存里的 HashSet 进行去重,但是如果你的某个系统部署在多台机器上呢?得基于Redis进行全局的 Set 去重。
(2)集合的交并补运算:可以基于 Set 玩儿交集、并集、差集的操作,比如交集吧,我们可以把两个人的好友列表整一个交集,可以得到俩人的共同好友是谁,比如qq中你和一个人有多少个共同好友。
8.5 SortedSet数据类型的特点与应用
SortedSet的特点: 是排序的 Set,去重但可以排序,我们最重要的使用它这个自定义排序的功能。
SortedSet的应用:
(1) 当前item排序:写进去的时候给一个分数,自动根据分数排序:有序集合的使用场景与集合类似,但是set集合不是自动有序的,而Sorted set可以利用分数进行成员间的排序,而且是插入时就排序好。所以当你需要一个有序且不重复的集合列表时,就可以选择Sorted set数据结构作为选择方案。
(2) 各种排行榜:有序集合经典使用场景。例如视频网站需要对用户上传的视频做排行榜,榜单排序依据可能是多方面:按照时间、按照播放量、按照获得的赞数等。微博热搜榜,就是有个后面的热度值,前面就是名称。为什么不用list来做排行榜?list无法自定义顺序比较,无法保证无重复元素。
(3) 权重排序:用Sorted Sets来做带权重的队列:比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。
sortedSet和list都排序,两者区别:
(1) 特点不同:sortedSet元素自动去重,list无法完成;sortedSet自定义排序器,list无法完成。
(2) 应用不同:sortedSet用于对当前item排序,排行榜,权重排序,都是一样的;list用于制作item,lrange制作item分页,消息队列FIFO.
8.6 在最合适的场景使用最合适的数据结构
Redis基础数据类型有五种,总原则就是:在最合适的场景使用最合适的数据结构,不要什么都用string去实现。一般来说,一个好的面试题,是对于不同层级的人可以给出不同深度的答案,就比如redis五种基本类型,一定要从底层结构图和项目实践在什么地方使用这个数据类型两方面来说,同时兼顾底层和项目。
另外,这里有必要提一句,在Redis五种基本类型中,其实所有类型都有“key-value键值对”,key永远使用String类型,我们所说的五种类型仅仅是指value具有五种类型, String类型表示value是String类型,Hash类型表示value是Hash类型(即 key-value 键值对),list类型表示value是list类型,set类型表示value是set类型,sorted set类型表示value是sorted set有序集合类型。
九、尾声
本文介绍了Redis服务器中的数据库是如何存放五种基本类型的,顺便介绍五种基本类型的使用。
以上是关于Redis_17_Redis服务器中的数据库(五种基本类型底层存放)的主要内容,如果未能解决你的问题,请参考以下文章