知识蒸馏基本原理
Posted zhiyong_will
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了知识蒸馏基本原理相关的知识,希望对你有一定的参考价值。
1. 概述
蒸馏是一个化学上的词汇,百科上对于蒸馏的解释为:“蒸馏是一种热力学的分离工艺,它利用混合液体或液-固体系中各组分沸点不同,使低沸点组分蒸发,再冷凝以分离整个组分的单元操作过程,是蒸发和冷凝两种单元操作的联合”。原理如下图所示:
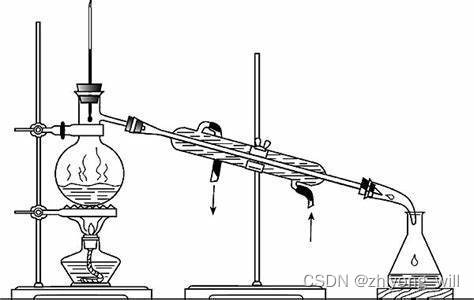
蒸馏的目的是在不同的温度下提出了特定的成分。说回到知识蒸馏(knowledge distillation),其是模型压缩的一种常用的方法,最早得到推广的版本是由Hinton在2015年[1]提出并应用在分类任务上。与蒸馏的目的一致,在知识蒸馏中,希望通过提取性能更好的大模型的监督信息,构建一个小模型,同时使得小模型具有较好的性能和精度,而此处的大小模型成为Teacher,小模型称为Student。
2. 知识蒸馏的基本原理
2.1. 知识蒸馏原理
随着计算能力的不断提升,现在的模型也越来越大,网络也越来越深,结构变得异常复杂,这带来了模型准确率的提升,同时,计算复杂度也随之提升。知识蒸馏就是一种有效的模型压缩的方法,同时能够使得压缩后的模型的效果并未下降太多。
在知识蒸馏中,首先需要有一个大模型,也称为Teacher模型,该模型的特点是模型复杂,此时需要对该模型压缩,得到一个较小的模型,也称为Student模型,在蒸馏的过程中,将Teacher模型中学习到的“知识”迁移到Student模型中,以使得Student模型具有与Teacher模型一致的效果。具体的过程如下图所示:
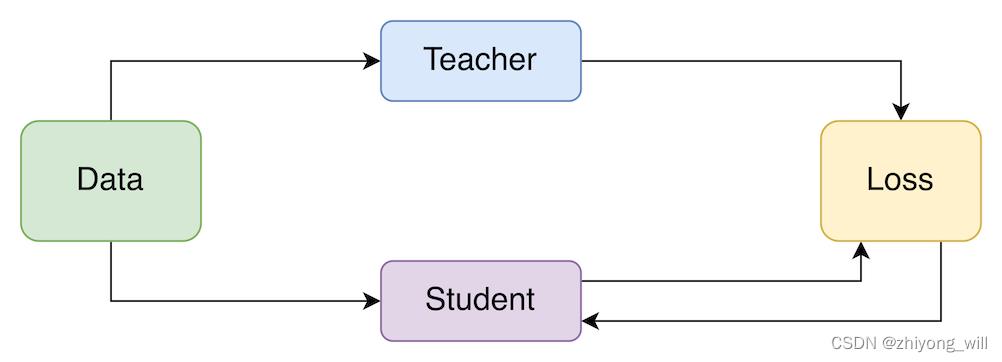
2.2. 知识蒸馏学习过程
对于一个完整的知识蒸馏过程,有两个模型,分别为Teacher模型和Student模型,通过学习将已经训练好的Teacher模型中的知识迁移到小的Student模型中。其具体过程如下图所示[2]:

对于Student模型,其目标函数有两个,分别为蒸馏的loss(distillation loss)和自身的loss(student loss),其最终的损失函数为:
L = α L s o f t + β L h a r d L=\\alpha L_soft+\\beta L_hard L=αLsoft+βLhard
其中, L h a r d L_hard Lhard为student模型自身的损失,对于分类问题来说,可以通过交叉熵计算 L h a r d L_hard Lhard:
L h a r d = − ∑ i = 1 n c i l o g ( q i ) L_hard=-\\sum_i=1^nc_ilog\\left ( q_i \\right ) Lhard=−i=1∑ncilog(qi)
其中, c i c_i ci为样本的真实标签,对于分类问题来说即为0或者1, q i q_i qi为Student模型的输出。通常, q i q_i qi可以通过softmax计算得到:
q i = e x p ( z i ) ∑ j e x p ( z j ) q_i=\\fracexp\\left ( z_i \\right )\\sum _jexp\\left ( z_j \\right ) qi=∑jexp(zj)exp(zi)
对于softmax的计算,是在网络的logits结果 z i z_i zi上,在softmax计算后得到的概率分布毁放大logits,会使得类目之间的差异变大。因此在知识蒸馏中,通常在logits的基础上加上一个温度变量 T T T,来对logits结果缩放:
q i = e x p ( z i / T ) ∑ j e x p ( z j / T ) q_i=\\fracexp\\left ( z_i/T \\right )\\sum _jexp\\left ( z_j/T \\right ) qi=∑jexp(zj/T)exp(zi/T)
当 T = 1 T=1 T=1时即为正常的输出,上述的 L h a r d L_hard Lhard即在 T = 1 T=1 T=1的情况下计算得到。对于 L s o f t L_soft Lsoft的计算,通常有两种方式,一种是计算softmax输出结果的差异,另一种是直接比较logits结果的差异。
对于softmax结果的差异,由于softmax的结果是概率分布,因此可通过交叉熵计算分布之间的差异:
L s o f t = − ∑ i = 1 n p i l o g ( q i ) L_soft=-\\sum_i=1^np_ilog\\left ( q_i \\right ) Lsoft=−i=1∑npilog(qi)
其中, p i p_i pi为Teacher模型的输出, q i q_i qi为Student模型的输出。且输出是在 T = t T=t T=t的情况下计算得到。
对于logits结果的差异,可以直接比较Teacher网络和Student网络输出logits的平方差,即:
L s o f t = ∑ i = 1 n ( v i − z i ) 2 L_soft=\\sum_i=1^n\\left ( v_i-z_i \\right )^2 Lsoft=i=1∑n(vi−zi)2
其中, v i v_i vi为Teacher模型的logits输出, z i z_i zi为Student模型的logits输出。
3. 总结
知识蒸馏通过对Teacher模型的压缩得到效果接近的Student模型,由于网络模型复杂度的减小,使得压缩后的Student模型的性能得到较大提升。
参考文献
[1] Hinton G , Vinyals O , Dean J . Distilling the Knowledge in a Neural Network[J]. Computer Science, 2015, 14(7):38-39.
[3] 【经典简读】知识蒸馏(Knowledge Distillation) 经典之作
以上是关于知识蒸馏基本原理的主要内容,如果未能解决你的问题,请参考以下文章