C 语言学习笔记:编程基础
Posted Amo Xiang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C 语言学习笔记:编程基础相关的知识,希望对你有一定的参考价值。
目录
一、冯诺依曼模型
1945 年冯诺依曼和一些科学家提出了一份报告,报告遵循了图灵机的设计,并提出用电子元件构造计算机,约定了用二进制进行计算和存储,并且将计算机结构分成 运算器,控制器、存储器、输入设备、输出设备 等5个部分。这几个部分组成了计算机的硬件。
存储程序的思想 :系统的运行过程就是按照一定的顺序不断执行存储器中的程序指令的过程
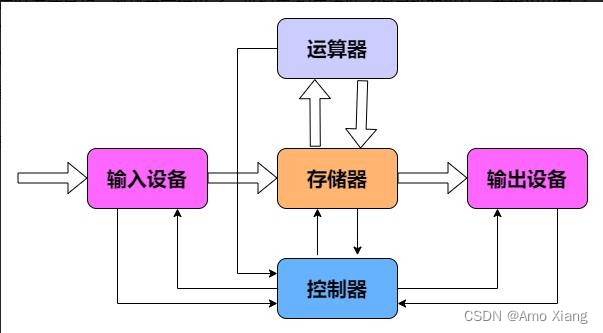
存储器的分类:
- 主存储器: 我们也叫内存,程序中待处理的数据和处理的结果都存储在内存中。

- 外存储器: 常用就是硬盘,是用来长期保存数据的大容量存储器。

- 寄存器: CPU内部的高速存储器,速度快,数目少。

二、程序语言发展历史
我们平时生活中说的是汉语,是 中国语言,只要把我们的要求告诉朋友们或者父母,他们就会知道我们表达的意思,进而满足我们的要求,用 中国语言 来让他人明白、理解我们要做的事情。
中国语言 有固定的格式,每个汉字代表的意思不同(中国文化博大精深,暗语),我们必须正确的表达,别人才能理解我们的意思。如下:
例如: 刘老师,你真的好帅呀!
如果我们说 的好帅呀真你,老刘师,刘老师听了之后就会觉得奇怪,听不懂我们的意思,或者理解错误,责备我们。我们通过有固定格式和固定词汇的 语言 来 "控制" 他人,让他人为我们做事情。语言有很多种,包括汉语、英语、法语、韩语等,虽然他们的词汇和格式都不一样,但是可以达到同样的目的,我们可以选择任意一种语言去 "控制" 他人。同样,我们也可以通过 "语言" 来控制计算机,让计算机为我们做事情,这样的语言就叫做 编程语言(Programming Language)。
编程语言也有固定的格式和词汇,我们必须经过学习才会使用,才能控制计算机。历史:
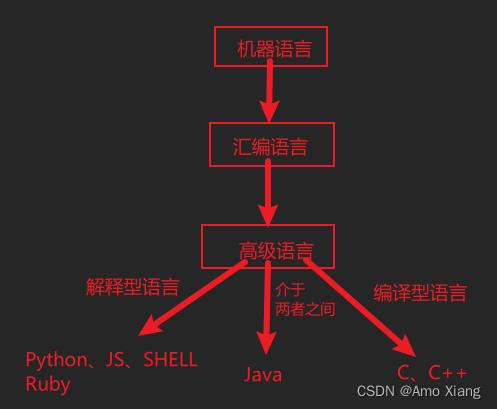
机器语言: 因为计算机只认指令,在早些年前,就有机器语言,它以一种指令集体系结构存在,数据能够被计算机CPU直接解读,不需要进行任何的翻译。计算机使用的是由 0和1二进制数 组成的一串指令,如下图所示:
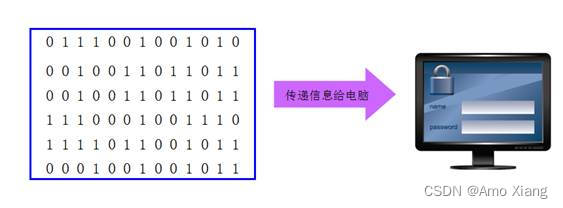
和自然语言完全不同,难于记忆和理解,工作量大,效率低,无法移植。
汇编语言: 机器语言的存在正好满足了计算机的要求。但是编程人员使用机器语言很痛苦,于是汇编语言就应运而生了。汇编语言是用英文字母或符号串来替代机器语言的二进制码 (即通过一组简单的的符号来表示机器指令,更接近于自然语言,更容易理解和使用),这样就把不易理解和使用的机器语言变成了汇编语言。因此,使用汇编语言就比机器语言便于阅读和理解程序。如下所示是汇编指令:
mov ax,2000
mov ss,ax
mov sp,10
mov ax,3213
push ax
mov ax,3366
push ax
高级语言: 汇编语言也有弊端,它的助记符多且难记(开发工作量大、难度高),而且汇编语言依赖于硬件系统(无法移植),于是,人们又发明了高级语言,高级语言的语法和格式类似于英文,远离了对硬件的直接操作。高级语言并不是某一种具体的语言,如下图所示:
包括流行的C语言、Java、C++、Python等,本专栏我们不深入探讨其他编程语言,只谈C语言,这里简单了解下每种语言擅长的方面,例如:
| 编程语言 | 主要用途 |
|---|---|
| C/C++ | C++ 是在C语言的基础上发展起来的,C++ 包含了C语言的所有内容,C语言是C++的一个部分,它们往往混合在一起使用,所以统称为 C/C++。C/C++主要用于PC软件开发、Linux开发、游戏开发、单片机和嵌入式系统。 |
| Java | Java 是一门通用型的语言,可以用于网站后台开发、android 开发、PC软件开发,近年来又涉足了大数据领域(归功于 Hadoop 框架的流行)。 |
| C# | C# 是微软开发的用来对抗 Java 的一门语言,实现机制和 Java 类似,不过 C# 显然失败了,目前主要用于 Windows 平台的软件开发,以及少量的网站后台开发。 |
| Python | Python 也是一门通用型的语言,主要用于系统运维、网站后台开发、数据分析、人工智能、云计算等领域,近年来势头强劲,增长非常快。 |
| php | PHP 是一门专用型的语言,主要用来开发网站后台程序。 |
| javascript | JavaScript 最初只能用于网站前端开发,而且是前端开发的唯一语言,没有可替代性。近年来由于 Node.js 的流行,JavaScript 在网站后台开发中也占有了一席之地,并且在迅速增长。 |
| Go语言 | Go语言是 2009 年由 Google 发布的一款编程语言,成长非常迅速,在国内外已经有大量的应用。Go 语言主要用于服务器端的编程,对 C/C++、Java 都形成了不小的挑战。 |
| Objective-C Swift | Objective-C 和 Swift 都只能用于苹果产品的开发,包括 Mac、MacBook、iPhone、iPad、iWatch 等。 |
| 汇编语言 | 汇编语言是计算机发展初期的一门语言,它的执行效率非常高,但是开发效率非常低,所以在常见的应用程序开发中不会使用汇编语言,只有在对效率和实时性要求极高的关键模块才会考虑汇编语言,例如操作系统内核、驱动、仪器仪表、工业控制等。 |
可以将上表中不同的编程语言比喻成各国语言,为了表达同一个意思,可能使用不同的语句。例如,表达 刘老师你好 的意思:
汉语: 刘老师你好
英语: Hello, Miss Liu
韩语: 유 선생님, 안녕하세요.
在编程语言中,同样的操作也可能使用不同的语句。例如,在屏幕上显示 刘老师你好,C语言:
puts("刘老师你好");
JavaScript:
console.log("刘老师你好");
Java:
System.out.println("刘老师你好");
Python:
print("刘老师你好")
高级语言类似于人类语言,由直观的词汇组成,我们很容易就能理解它的意思,例如在C语言中,我们使用 puts(puts 是 output string(输出字符串) 的缩写) 这个词让计算机在屏幕上显示出文字;使用 puts 在屏幕上显示 刘老师你好:
puts("刘老师你好");
我们把要显示的内容放在 ("和") 之间,并且在最后要有 ;。你必须要这样写,这是固定的格式。
总结: 编程语言是用来控制计算机的 一系列指令(Instruction),它有固定的格式和词汇(不同编程语言的格式和词汇不一样),必须遵守,否则就会出错,达不到我们的目的。
拓展:编译型语言和解释型语言的区别?
我们常常使用的计算机是不能理解高级语言的,更不能直接执行高级语言,它只能直接理解机器语言,所以使用任何高级语言编写的程序若想被计算机运行,都必须将其转换成计算机语言,也就是机器码。操作系统提供了两种转换方法:1. 编译 2. 解释。
所以高级语言也分为 编译型语言和解释型语言。 主要区别在于,前者源程序编译后即可在该平台运行,后者是在运行期间才编译。所以前者运行速度快,后者跨平台性好。
编译性语言特点: 针对不同的平台,需要使用对应的编译器,它可以将高级语言源代码一次性的编译成可被该平台硬件执行的机器码,并包装成该平台所能识别的可执行性程序的格式。总结: 与特定的平台有关,在其他平台使用,需要想办法移植。可以编译程平台相关的机器语言文件,运行时脱离开发环境,运行效率高;
解释性语言特点: 解释器是对源程序逐行解释成特定平台的机器码并立即执行。是代码在执行时才被解释器一行行动态翻译和执行,而不是在执行之前就完成翻译。总结: 解释型语言每次运行都需要将源代码解释称机器码并执行,效率行对较低,但是书写简单。不同的平台只要提供相应的解释器,就可以运行源代码,所以可以方便源程序移植;
程序设计的步骤:
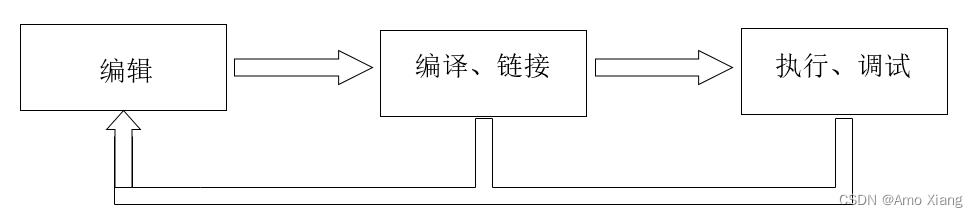
说明:无论是高级程序设计语言还是专用程序设计语言,都不能被计算机系统直接识别,用这些语言所编写的程序代码称为源程序,源程序需要通过预先设计好的专用程序进行转换,转换为计算机系统可以识别的机器指令,然后才能交由计算机系统执行。
C语言(C Language) 是高级程序设计语言的一种,学习C语言,主要是学习它的格式和词汇。下面是一个C语言的完整例子,它会让计算机在屏幕上显示 刘老师,您好!。这个例子主要演示C语言的一些固有格式和词汇,看不懂的读者不必深究,也不必问为什么是这样,后续会逐步给大家讲解。
#include <stdio.h>
int main()
puts("刘老师,您好!");
return 0;
这些具有 特定含义的词汇、语句,按照特定的格式组织在一起,就构成了源代码(Source Code),也称 源码或代码(Code)。
那么,C语言肯定规定了源代码中每个词汇、语句的含义,也规定了它们 该如何组织在一起,这就是语法(Syntax)。 它与我们学习英语时所说的 语法 类似,都规定了如何将特定的词汇和句子组织成能听懂的语言。
编写源代码的过程就叫做编程(Program)。从事编程工作的人叫程序员(Programmer)。程序员也很幽默,喜欢自嘲,经常说自己的工作辛苦,地位低,像农民一样,所以称自己是 码农,就是写代码的农民。也有人自嘲称是 程序猿/程序媛。
三、进制
我们平时使用的数字都是由 0~9 共十个数字组成的,例如 1、9、10、297、952 等,一个数字最多能表示九,如果要表示十、十一、二十九、一百等,就需要多个数字组合起来。
例如表示 6+9 的结果,一个数字不够,只能 进位,用 15 来表示;这时 进一位 相当于十,进两位 相当于二十。
因为逢十进一(满十进一),也因为只有 0~9 共十个数字,所以叫做 十进制(Decimalism)。 十进制是在人类社会发展过程中自然形成的,它符合人们的思维习惯,例如人类有十根手指,也有十根脚趾。
进制也就是进位制。进行加法运算时 逢X进一(满X进一), 进行减法运算时 借一当X, 这就是X进制,这种进制也就包含X个数字,基数为X。十进制有 0~9 共10个数字,基数为10,在加减法运算中,逢十进一,借一当十。
3.1 二进制
我们不妨将思维拓展一下,既然可以用 0~9 共十个数字来表示数值,那么也可以用 0、1 两个数字来表示数值,这就是 二进制(Binary)。 例如,数字 0、1、10、111、100、1000001 都是有效的二进制。
在计算机内部,数据都是以二进制的形式存储的,二进制是学习编程必须掌握的基础。
二进制加减法和十进制加减法的思想是类似的:
对于十进制,进行加法运算时逢十进一,进行减法运算时借一当十
对于二进制,进行加法运算时逢二进一,进行减法运算时借一当二
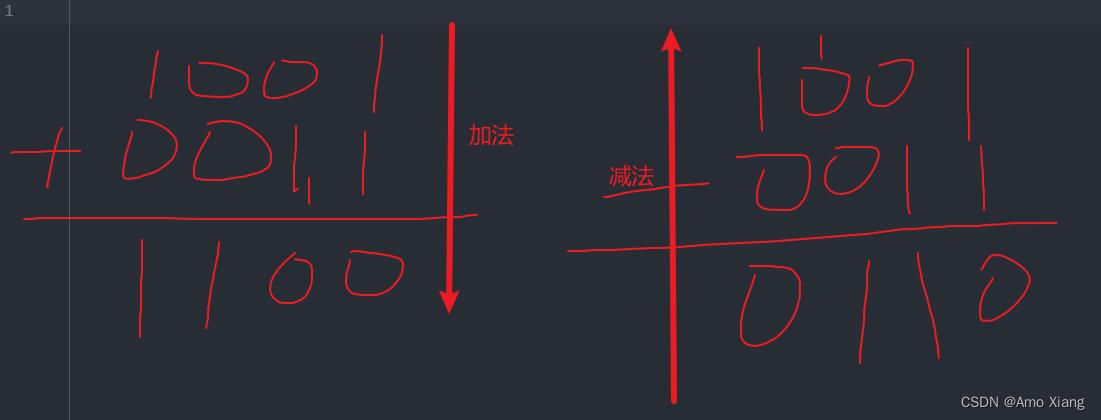
下面两张示意图详细演示了二进制加减法的运算过程
(1) 二进制加法:1+0=1、1+1=10、11+10=101、111+111=1110

(2) 二进制减法:1-0=1、10-1=1、101-11=10、1100-111=101

3.2 八进制
除了二进制,C语言还会使用到八进制。
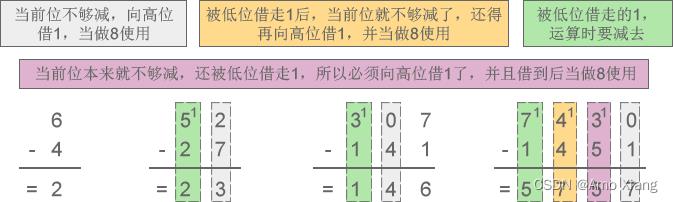
八进制有 0~7 共8个数字,基数为8,加法运算时逢八进一,减法运算时借一当八。例如,数字 0、1、5、7、14、733、67001、25430 都是有效的八进制。
下面两张图详细演示了八进制加减法的运算过程
(1) 八进制加法:3+4=7、5+6=13、75+42=137、2427+567=3216

(2) 八进制减法:6-4=2、52-27=23、307-141=146、7430-1451=5757
3.3 十六进制
除了二进制和八进制,十六进制也经常使用,甚至比八进制还要频繁。
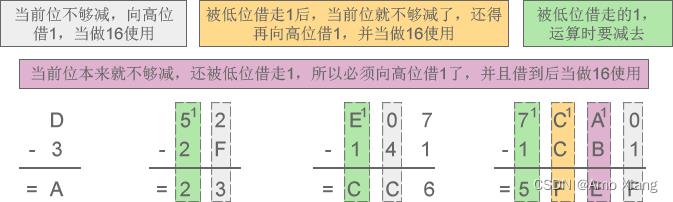
十六进制中,用A来表示10,B表示11,C表示12,D表示13,E表示14,F表示15,因此有 0~F 共16个数字,基数为16,加法运算时逢16进1,减法运算时借1当16。例如,数字 0、1、6、9、A、D、F、419、EA32、80A3、BC00 都是有效的十六进制。
注意,十六进制中的字母不区分大小写,ABCDEF 也可以写作 abcdef。
下面两张图详细演示了十六进制加减法的运算过程:
(1) 十六进制加法:6+7=D、18+BA=D2、595+792=D27、2F87+F8A=3F11
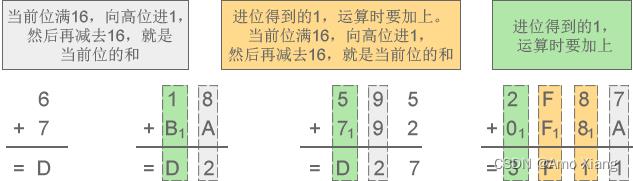
(2) 十六进制减法:D-3=A、52-2F=23、E07-141=CC6、7CA0-1CB1=5FEF
3.4 进制转换:二进制、八进制、十六进制、十进制之间的转换
学习链接:https://blog.csdn.net/xw1680/article/details/104928911
前面我们对二进制、八进制和十六进制进行了说明,本节重点讲解不同进制之间的转换,这在编程中经常会用到,尤其是C语言。
3.4.1 将二进制、八进制、十六进制转换为十进制
二进制、八进制和十六进制向十进制转换都非常容易,就是 按权相加。所谓 权,也即 位权。
假设当前数字是 N 进制,那么:
- 对于整数部分,从右往左看,第 i 位的位权等于 Ni-1
- 对于小数部分,恰好相反,要从左往右看,第 j 位的位权为 N-j
更加通俗的理解是,假设一个多位数(由多个数字组成的数)某位上的数字是 1,那么它所表示的数值大小就是该位的位权。
(1) 整数部分。 例如,将八进制数字 53627 转换成十进制:
53627 = 5×84 + 3×83 + 6×82 + 2×81 + 7×80= 22423(十进制)
从右往左看,第1位的位权为 80=1,第2位的位权为 81=8,第3位的位权为 82=64,第4位的位权为 83=512,第5位的位权为 84=4096 …… 第n位的位权就为 8n-1。将各个位的数字乘以位权,然后再相加,就得到了十进制形式。
注意,这里我们需要以十进制形式来表示位权。
再如,将十六进制数字 9FA8C 转换成十进制:9FA8C = 9×164 + 15×163 + 10×162 + 8×161 + 12×160 = 653964(十进制)
可以使用在线网站验证结果:https://jisuan5.com/hexadecimal-to-decimal/
从右往左看,第1位的位权为 160=1,第2位的位权为 161=16,第3位的位权为 162=256,第4位的位权为 163=4096,第5位的位权为 164=65536 …… 第n位的位权就为 16n-1。将各个位的数字乘以位权,然后再相加,就得到了十进制形式。
将二进制数字转换成十进制也是类似的道理:11010 = 1×24 + 1×23+ 0×22 + 1×21 + 0×20 = 26(十进制)
从右往左看,第1位的位权为 20=1,第2位的位权为 21=2,第3位的位权为 22=4,第4位的位权为 23=8,第5位的位权为 24=16 …… 第n位的位权就为 2n-1。将各个位的数字乘以位权,然后再相加,就得到了十进制形式。
(2) 小数部分。 例如,将八进制数字 423.5176 转换成十进制:423.5176 = 4×82 + 2×81 + 3×80 + 5×8-1 + 1×8-2 + 7×8-3 + 6×8-4 = 275.65576171875(十进制)
小数部分和整数部分相反,要从左往右看,第1位的位权为 8-1=1/8,第2位的位权为 8-2=1/64,第3位的位权为 8-3=1/512,第4位的位权为 8-4=1/4096 …… 第m位的位权就为 8-m。
再如,将二进制数字 1010.1101 转换成十进制:
1010.1101 = 1×23 + 0×22 + 1×21 + 0×20 + 1×2-1 + 1×2-2 + 0×2-3 + 1×2-4 = 10.8125(十进制)
小数部分和整数部分相反,要从左往右看,第1位的位权为 2-1=1/2,第2位的位权为 2-2=1/4,第3位的位权为 2-3=1/8,第4位的位权为 2-4=1/16 …… 第m位的位权就为 2-m。
更多转换成十进制的例子:
二进制:1001 = 1×23 + 0×22 + 0×21 + 1×20 = 8 + 0 + 0 + 1 = 9(十进制)
二进制:101.1001 = 1×22 + 0×21 + 1×20 + 1×2-1 + 0×2-2 + 0×2-3 + 1×2-4 = 4 + 0 + 1 + 0.5 + 0 + 0 + 0.0625 = 5.5625(十进制)
八进制:302 = 3×82 + 0×81 + 2×80 = 192 + 0 + 2 = 194(十进制)
八进制:302.46 = 3×82 + 0×81 + 2×80 + 4×8-1 + 6×8-2 = 192 + 0 + 2 + 0.5 + 0.09375= 194.59375(十进制)
十六进制:EA7 = 14×162 + 10×161 + 7×160 = 3751(十进制)
3.4.2 将十进制转换为二进制、八进制、十六进制
将十进制转换为其它进制时较为复杂,整数部分和小数部分的算法不一样,下面分别进行讲解。
3.4.2.1 常规方法
整数部分: 十进制整数转换为 N 进制整数采用 除 N 取余,逆序排列 法。具体做法是:
- 将 N 作为除数,用十进制整数除以 N,可以得到一个商和余数。
- 保留余数,用商继续除以 N,又得到一个新的商和余数。
- 仍然保留余数,用商继续除以 N,还会得到一个新的商和余数。
如此反复进行,每次都保留余数,用商接着除以 N,直到商为 0 时为止。把先得到的余数作为 N 进制数的低位数字,后得到的余数作为 N 进制数的高位数字,依次排列起来,就得到了 N 进制数字。下图演示了将十进制数字 36926 转换成八进制的过程:
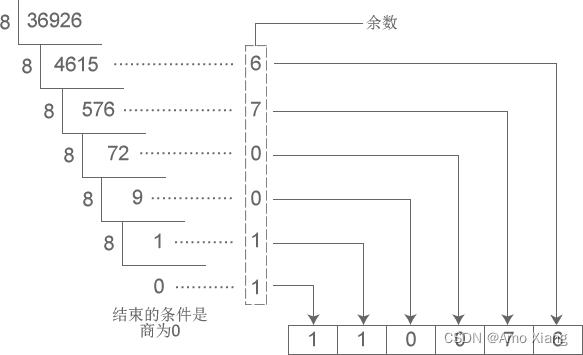
从图中得知,十进制数字 36926 转换成八进制的结果为 110076。下图演示了将十进制数字 42 转换成二进制的过程:
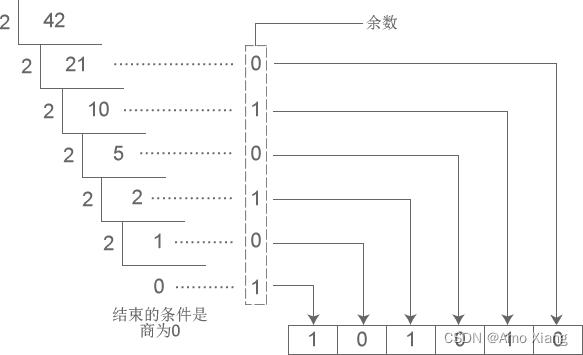
从图中得知,十进制数字 42 转换成二进制的结果为 101010。
小数部分: 十进制小数转换成 N 进制小数采用 乘 N 取整,顺序排列 法。具体做法是:
- 用 N 乘以十进制小数,可以得到一个积,这个积包含了整数部分和小数部分;
- 将积的整数部分取出,再用 N 乘以余下的小数部分,又得到一个新的积;
- 再将积的整数部分取出,继续用 N 乘以余下的小数部分;
如此反复进行,每次都取出整数部分,用 N 接着乘以小数部分,直到积中的小数部分为 0,或者达到所要求的精度为止。把取出的整数部分按顺序排列起来,先取出的整数作为 N 进制小数的高位数字,后取出的整数作为低位数字,这样就得到了 N 进制小数。下图演示了将十进制小数 0.930908203125 转换成八进制小数的过程:

从图中得知,十进制小数 0.930908203125 转换成八进制小数的结果为 0.7345。下图演示了将十进制小数 0.6875 转换成二进制小数的过程:

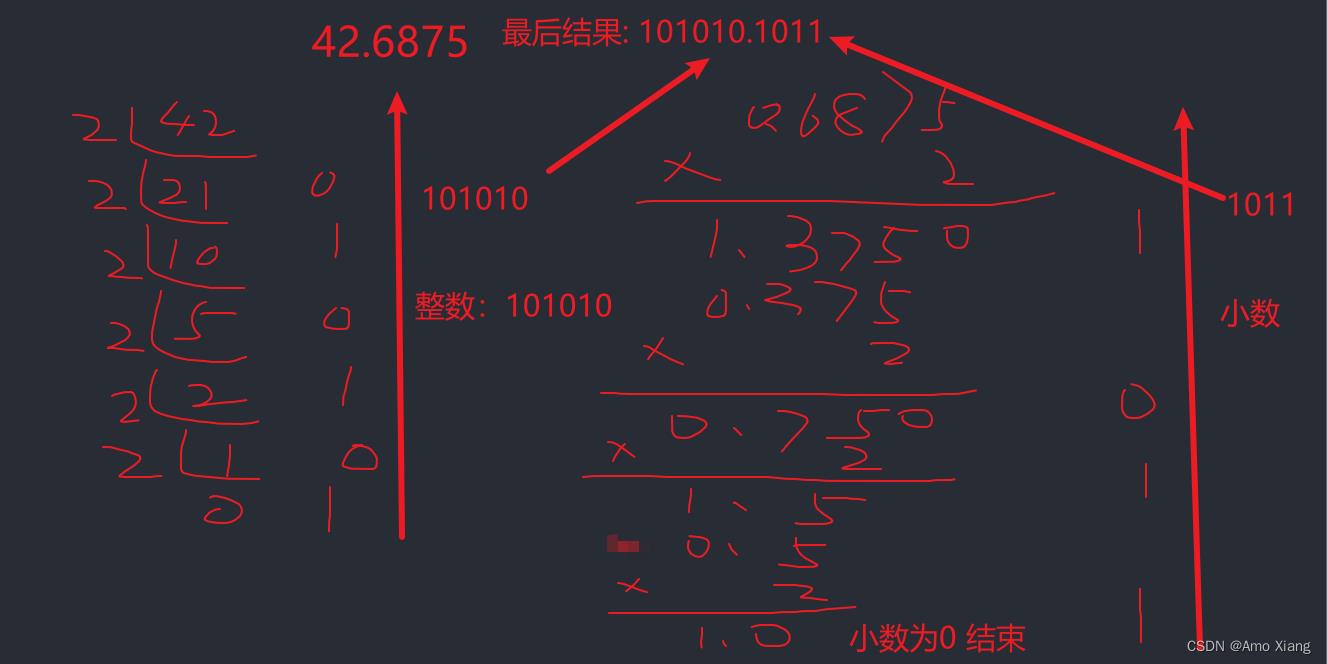
从图中得知,十进制小数 0.6875 转换成二进制小数的结果为 0.1011。如果一个数字既包含了整数部分又包含了小数部分,那么将整数部分和小数部分开,分别按照上面的方法完成转换,然后再合并在一起即可。例如:
十进制数字 36926.930908203125 转换成八进制的结果为 110076.7345
十进制数字 42.6875 转换成二进制的结果为 101010.1011
42.6875 演算结果如下图所示:
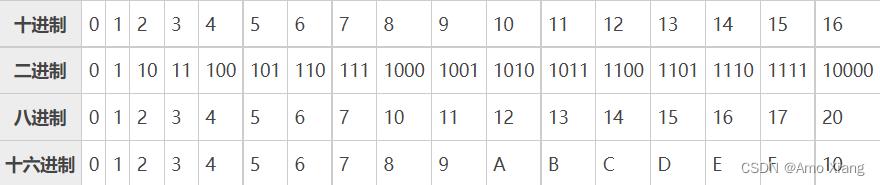
下表列出了前 17 个十进制整数与二进制、八进制、十六进制的对应关系:
注意,十进制小数转换成其他进制小数时,结果有可能是一个无限位的小数。请看下面的例子:
十进制 0.51 对应的二进制为 0.100000101000111101011100001010001111010111..., 是一个循环小数
十进制 0.72 对应的二进制为 0.1011100001010001111010111000010100011110..., 是一个循环小数
十进制 0.625 对应的二进制为 0.101, 是一个有限小数
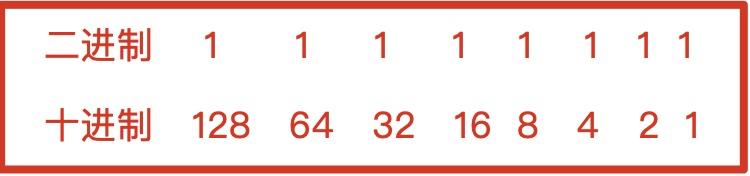
3.4.2.2 8421码
8421码是一种编码方式,又为8421BCD编码,是一种用4位二进制码的组合代表1位十进制数的编码 方法。因为是4位二进制,转换为十进制,每位的权分别为:23、22、21、20,也就是 8,4,2,1,因而得名。
二进制转换为十进制:
十进制数 0 1 2 3 4 5 6 7 8 9
8421BCD码 0000 0001 0010 0011 0100 0101 0110 0111 1000 1001
11001000
128
十进制转换为二进制:
位 0 1 2 3 4 5 6 7 8
二进制位位权 2^0 2^1 2^2 2^3 2^4 2^5 2^6 2^7 2^8
数值 1 2 4 8 16 32 64 128 256
使用方法: 把一个十进制数拆分位上述最后一排的数值相加,然后把二进位从高到列排列。若是用到了对应的数值,二进制位设置为1,否则设置为0,书写完毕后,对应的二进制位排列就是该十进制转换为二进制的值。
题目: 求十进制200对应的二进制数
位 7 6 5 4 3 2 1 0
数值 128 64 32 16 8 4 2 1
200 = 128 + 64 + 8
位 7 6 5 4 3 2 1 0
二进制位 1 1 0 0 1 0 0 0
所以最后的结果为:11001000
补充:8421码,是 bcd 码的一种。它表达的意思是每一个二进制位上的数据对应一个固定的值,只需要把对应的1位置的数据值给相加,即可得到该二进制对应的十进制的值。如下图所示:
二进制到十进制的转换:
1010100 = 64 + 16 + 4 = 84
十进制到二进制的转换:
100 = 64 + 32 + 4 = 0b1100100
3.4.3 二进制和八进制、十六进制的转换
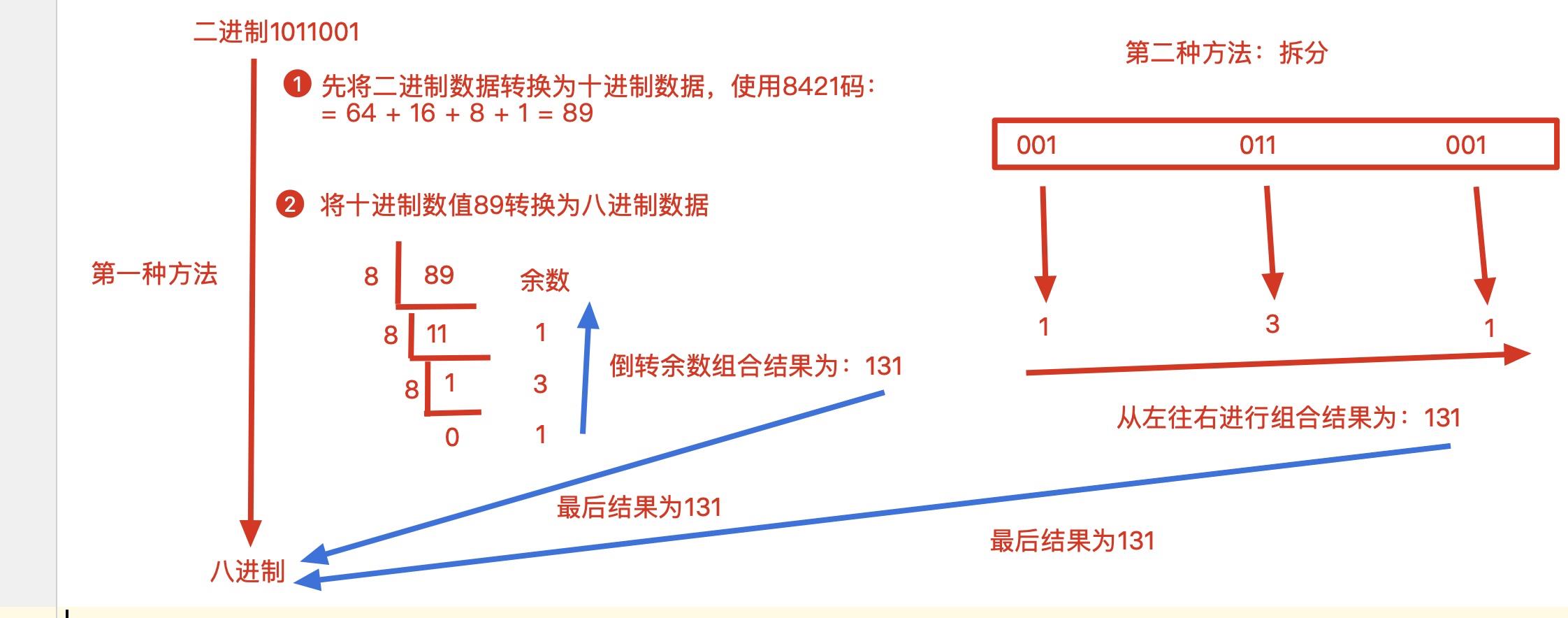
问题:任意的 x 进制到 y 进制的转换,该怎么办呢?步骤如下:
x进制 --> 十进制
十进制 --> y进制
二进制到八进制,十六进制,方法如下:
A: 二进制到十进制,十进制到八或者十六进制
B: 拆分组合法
这里拿二进制到八进制举例子,二进制到十六进制的练习自己做。如下图所示:
补充说明:
1、二进制整数和八进制整数之间的转换。 二进制整数转换为八进制整数时,每三位二进制数字转换为一位八进制数字,运算的顺序是从低位向高位依次进行,高位不足三位用零补齐。下图演示了如何将二进制整数 1110111100 转换为八进制:
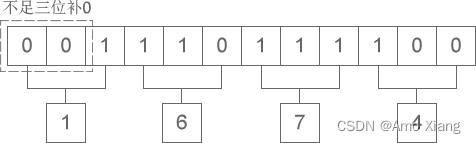
从图中可以看出,二进制整数 1110111100 转换为八进制的结果为 1674。八进制整数转换为二进制整数时,思路是相反的,每一位八进制数字转换为三位二进制数字,运算的顺序也是从低位向高位依次进行。下图演示了如何将八进制整数 2743 转换为二进制:
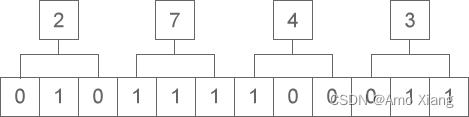
从图中可以看出,八进制整数 2743 转换为二进制的结果为 10111100011。
2、二进制整数和十六进制整数之间的转换。 二进制整数转换为十六进制整数时,每四位二进制数字转换为一位十六进制数字,运算的顺序是从低位向高位依次进行,高位不足四位用零补齐。下图演示了如何将二进制整数 10 1101 0101 1100 转换为十六进制:
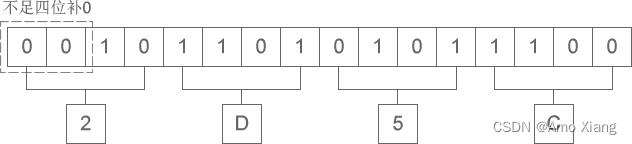
从图中可以看出,二进制整数 10 1101 0101 1100 转换为十六进制的结果为 2D5C。十六进制整数转换为二进制整数时,思路是相反的,每一位十六进制数字转换为四位二进制数字,运算的顺序也是从低位向高位依次进行。下图演示了如何将十六进制整数 A5D6 转换为二进制:

从图中可以看出,十六进制整数 A5D6 转换为二进制的结果为 1010 0101 1101 0110。在C语言编程(其他语言也一样)中,二进制、八进制、十六进制之间几乎不会涉及小数的转换,所以这里只讲整数的转换,大家学以致用足以。另外,八进制和十六进制之间也极少直接转换,这里也不再讲解了。
总结:本节前面两部分讲到的转换方法是通用的,任何进制之间的转换都可以采用,只是有时比较麻烦而已。二进制和八进制、十六进制之间的转换有非常简洁的方法,所以没有采用前面的方法。
3.5 练习
3.5.1 练习1 计算下列的结果
二进制加法运算:1001 + 0011
二进制减法运算:1001 - 0011
3.5.2 练习2 计算二进制数据转换成⼗进制之后的值
二进制 10011.01 转换成十进制
整数部分: 16 + 2 + 1 --> 19
小数部分: 1*2^-2 --> 0.25
最终结果为: 整数部分+小数部分 --> 19+0.25 -->19.25
3.5.3 练习3 计算下列数据的结果
十进制 35.64 转换为二进制数据,要求精度为小数点后五位
整数部分: 32 + 2 + 1 --> 100011
小数部分: 0.64*2 --> 1.28 --> 1 0.28 * 2 ---> 0.56 --> 0
0.56 * 2 ---> 1.12 ---> 1 0.12 * 2 ---> 0.24 ---> 0
0.24 * 2 ---> 0.48 ---> 0 保留5位 即小数部分为: 10100
所以最后结果为: 100011.10100
四、数据在内存中的存储(二进制形式存储)
计算机要处理的信息是多种多样的,如数字、文字、符号、图形、音频、视频等,这些信息在人们的眼里是不同的。但对于计算机来说,它们在内存中都是一样的,都是以 二进制的形式 来表示。要想学习编程,就必须了解二进制,它是计算机处理数据的基础。
内存条是一个非常精密的部件,包含了上亿个电子元器件,它们很小,达到了纳米级别。这些元器件,实际上就是电路;电路的电压会变化,要么是 0V,要么是 5V,只有这两种电压。5V 是通电,用1来表示,0V 是断电,用0来表示。所以,一个元器件有2种状态,0 或者 1。
我们通过电路来控制这些元器件的通断电,会得到很多0、1的组合。例如,8个元器件有 28=256 种不同的组合,16个元器件有 216=65536 种不同的组合。虽然一个元器件只能表示2个数值,但是多个结合起来就可以表示很多数值了。
我们可以给每一种组合赋予特定的含义,例如,可以分别用 110001000010001、111001000110001、100111101100000 来表示我、爱、你这几个字,那么结合起来 110001000010001 111001000110001 100111101100000 就表示 我爱你。
一般情况下我们不一个一个的使用元器件,而是将8个元器件看做一个单位,即使表示很小的数,例如 1,也需要8个,也就是 00000001。1个元器件称为1比特(Bit)或1位,8个元器件称为1字节(Byte),那么16个元器件就是2Byte,32个就是4Byte,以此类推:8×1024个元器件就是1024Byte,简写为1KB、8×1024×1024个元器件就是1024KB,简写为1MB、8×1024×1024×1024个元器件就是1024MB,简写为1GB。
现在,你知道1GB的内存有多少个元器件了吧。我们通常所说的文件大小是多少 KB、多少 MB,就是这个意思。单位换算:
1Byte = 8 Bit
1KB = 1024Byte = 210Byte
1MB = 1024KB = 220Byte
1GB = 1024MB = 230Byte
1TB = 1024GB = 240Byte
1PB = 1024TB = 250Byte
1EB = 1024PB = 260Byte
我们平时使用计算机时,通常只会涉及到 KB、MB、GB、TB 这几个单位,PB 和 EB 这两个高级单位一般在大数据处理过程中才会用到。你看,在内存中没有 abc 这样的字符,也没有 gif、jpg 这样的图片,只有0和1两个数字,计算机也只认识0和1。所以,计算机使用二进制,而不是我们熟悉的十进制,写入内存中的数据,都会被转换成0和1的组合。
五、程序的运行
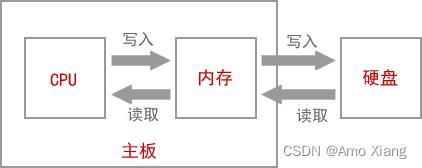
如果你的电脑上安装了微信,你希望和好友聊天,会双击微信图标,打开微信软件,输入账号和密码,然后登录就可以了。那么,微信是怎么运行起来的呢?首先,有一点你要明确,你安装的微信软件是保存在硬盘中的。双击微信图标,操作系统就会知道你要运行这个软件,它会在硬盘中找到你安装的微信软件,将数据(安装的软件本质上就是很多数据的集合)复制到内存。对!就是复制到内存!微信不是在硬盘中运行的,而是在内存中运行的。为什么呢?因为内存的读写速度比硬盘快很多。
对于读写速度,内存 > 固态硬盘 > 机械硬盘。机械硬盘是靠电机带动盘片转动来读写数据的,而内存条通过电路来读写数据,电机的转速肯定没有电的传输速度 (几乎是光速) 快。虽然固态硬盘也是通过电路来读写数据,但是因为与内存的控制方式不一样,速度也不及内存。
所以,不管是运行微信还是编辑 Word 文档,都是先将硬盘上的数据复制到内存,才能让CPU来处理,这个过程就叫作载入内存(Load into Memory)。完成这个过程需要一个特殊的程序(软件),这个程序就叫做加载器(Loader)。CPU直接与内存打交道,它会读取内存中的数据进行处理,并将结果保存到内存。如果需要保存到硬盘,才会将内存中的数据复制到硬盘。
例如,打开 Word 文档,输入一些文字,虽然我们看到的不一样了,但是硬盘中的文档没有改变,新增的文字暂时保存到了内存,Ctrl+S 才会保存到硬盘。因为内存断电后会丢失数据,所以如果你编辑完 Word 文档忘记保存就关机了,那么你将永远无法找回这些内容。
虚拟内存: 如果我们运行的程序较多,占用的空间就会超过内存(内存条)容量。例如计算机的内存容量为2G,却运行着10个程序,这10个程序共占用3G的空间,也就意味着需要从硬盘复制 3G 的数据到内存,这显然是不可能的。
操作系统(Operating System,简称 OS) 为我们解决了这个问题:当程序运行需要的空间大于内存容量时,会将内存中暂时不用的数据再写回硬盘;需要这些数据时再从硬盘中读取,并将另外一部分不用的数据写入硬盘。这样,硬盘中就会有一部分空间用来存放内存中暂时不用的数据。这一部分空间就叫做虚拟内存(Virtual Memory)。3G - 2G = 1G,上面的情况需要在硬盘上分配 1G 的虚拟内存。
硬盘的读写速度比内存慢很多,反复交换数据会消耗很多时间,所以如果你的内存太小,会严重影响计算机的运行速度,甚至会出现 卡死 现象,即使CPU强劲,也不会有大的改观。如果经济条件允许,建议将内存升级为 32G,在 win7、win8、win10 下运行软件就会比较流畅了。总结:CPU直接从内存中读取数据,处理完成后将结果再写入内存。CPU、内存、硬盘和主板的关系如下图所示:
六、编码
6.1 ASCII编码
计算机是以二进制的形式来存储数据的,它只认识 0 和 1 两个数字,我们在屏幕上看到的文字,在存储之前都被转换成了二进制(0和1序列),在显示时也要根据二进制找到对应的字符。
可想而知,特定的文字必然对应着固定的二进制,否则在转换时将发生混乱。那么,怎样将文字与二进制对应起来呢?这就需要有一套规范,计算机公司和软件开发者都必须遵守,这样的一套规范就称为 字符集(Character Set) 或者 字符编码(Character Encoding)。
严格来说,字符集和字符编码不是一个概念,字符集定义了文字和二进制的对应关系,为字符分配了唯一的编号,而字符编码规定了如何将文字的编号存储到计算机中。我们暂时先不讨论这些细节,姑且认为它们是一个概念,本节中也混用了这两个概念,未做区分。
字符集为每个字符分配一个唯一的编号,类似于学生的学号,通过编号就能够找到对应的字符。可以将字符集理解成一个很大的表格,它列出了所有字符和二进制的对应关系,计算机显示文字或者存储文字,就是一个查表的过程。在计算机逐步发展的过程中,先后出现了几十种甚至上百种字符集,有些还在使用,有些已经淹没在了历史的长河中,本小节要讲解的是一种专门针对英文的字符集—— ASCII 编码。
1、拉丁字母(开胃小菜)。 在正式介绍 ASCII 编码之前,我们先来说说什么是拉丁字母。估计也有不少读者和我一样,对于拉丁字母、英文字母和汉语拼音中的字母的关系不是很清楚。拉丁字母也叫罗马字母,它源自希腊字母,是当今世界上使用最广的字母系统。基本的拉丁字母就是我们经常见到的 ABCD 等26个英文字母。拉丁字母、阿拉伯字母、斯拉夫字母(西里尔字母)被称为世界三大字母体系。拉丁字母原先是欧洲人使用的,后来由于欧洲殖民主义,导致这套字母体系在全球范围内开始流行,美洲、非洲、澳洲、亚洲都没有逃过西方文化的影响。中国也是,我们现在使用的拼音其实就是拉丁字母,是不折不扣的舶来品。
后来,很多国家对 26 个基本的拉丁字母进行了扩展,以适应本地的语言文化。最常见的扩展方式就是加上变音符号,例如汉语拼音中的 ü,就是在u的基础上加上两个小点演化而来;再如,áà 就是在a的上面标上音调。总起来说: 基本拉丁字母就是 26 个英文字母;扩展拉丁字母就是在基本的 26 个英文字母的基础上添加变音符号、横线、斜线等演化而来,每个国家都不一样。
2、ASCII 编码。 计算机是美国人发明的,他们首先要考虑的问题是,如何将二进制和英文字母(也就是拉丁文)对应起来。当时,各个厂家或者公司都有自己的做法,编码规则并不统一,这给不同计算机之间的数据交换带来不小的麻烦。但是相对来说,能够得到普遍认可的有 IBM 发明的 EBCDIC 和此处要谈的 ASCII。我们先说 ASCII。ASCII 是 American Standard Code for Information Interchange 的缩写,翻译过来是 美国信息交换标准代码。看这个名字就知道,这套编码是美国人给自己设计的,他们并没有考虑欧洲那些扩展的拉丁字母,也没有考虑韩语和日语,我大中华几万个汉字更是不可能被重视。但这也无可厚非,美国人自己发明的计算机,当然要先解决自己的问题
ASCII 的标准版本于 1967 年第一次发布,最后一次更新则是在 1986 年,迄今为止共收录了 128 个字符,包含了基本的 拉丁字母(英文字母)、阿拉伯数字(也就是1234567890)、标点符号(,.!等)、特殊符号(@#$%^&等) 以及一些具有控制功能的字符(往往不会显示出来)。
在 ASCII 编码中,大写字母、小写字母和阿拉伯数字都是连续分布的(见 https://baike.baidu.com/item/ASCII?fromModule=lemma_search-box),这给程序设计带来了很大的方便。例如要判断一个字符是否是大写字母,就可以判断该字符的 ASCII 编码值是否在 65~90 的范围内。
EBCDIC 编码正好相反,它的英文字母不是连续排列的,中间出现了多次断续,给编程带来了一些困难。现在连 IBM 自己也不使用 EBCDIC 了,转而使用更加优秀的 ASCII。ASCII 编码已经成了计算机的通用标准,没有人再使用 EBCDIC 编码了,它已经消失在历史的长河中了。
标准 ASCII 编码共收录了 128 个字符,其中包含了 33 个控制字符(具有某些特殊功能但是无法显示的字符) 和 95 个可显示字符,查看:https://baike.baidu.com/item/ASCII?fromModule=lemma_search-box 该表列出的是标准的 ASCII 编码,它共收录了 128 个字符,用一个字节中较低的 7 个比特位(Bit)足以表示(27 = 128),所以还会空闲下一个比特位,它就被浪费了。如果还想了解每个控制字符的含义,请转到:http://c.biancheng.net/c/ascii/
6.2 GB2312编码和GBK编码
计算机是一种改变世界的发明,很快就从美国传到了全球各地,得到了所有国家的认可,成为了一种不可替代的工具。计算机在广泛流行的过程中遇到的一个棘手问题就是字符编码,计算机是美国人发明的,它使用的是 ASCII 编码,只能显示英文字符,对汉语、韩语、日语、法语、德语等其它国家的字符无能为力。
为了让本国公民也能使用上计算机,各个国家(地区) 也开始效仿 ASCII,开发了自己的字符编码。这些字符编码和 ASCII 一样,只考虑本国的语言文化,不兼容其它国家的文字。这样做的后果就是,一台计算机上必须安装多套字符编码,否则就不能正确地跨国传递数据,例如在中国编写的文本文件,拿到日本的电脑上就无法打开,或者打开后是一堆乱码。下表列出了常见的字符编码:

由于 ASCII 先入为主,已经使用了十来年了,现有的很多软件和文档都是基于 ASCII 的,所以后来的这些字符编码都是在 ASCII 基础上进行的扩展,它们都兼容 ASCII,以支持既有的软件和文档。兼容 ASCII 的含义是,原来 ASCII 中已经包含的字符,在国家编码(地区编码)中的位置不变(也就是编码值不变),只是在这些字符的后面增添了新的字符。
标准 ASCII 编码共包含了 128 个字符,用一个字节就足以存储(实际上是用一个字节中较低的 7 位来存储),而日文、中文、韩文等包含的字符非常多,有成千上万个,一个字节肯定是不够的(一个字节最多存储 28 = 256 个字符),所以要进行扩展,用两个、三个甚至四个字节来表示。在制定字符编码时还要考虑内存利用率的问题。我们经常使用的字符,其编码值一般都比较小,例如字母和数字都是 ASCII 编码,其编码值不会超过 127,用一个字节存储足以,如果硬要用多个字节存储,就会浪费很多内存空间。为了达到 既能存储本国字符,又能节省内存 的目的,Shift-Jis、Big5、GB2312 等都采用变长的编码方式:
对于原来的 ASCII 编码部分,用一个字节存储足以
对于本国的常用字符(例如汉字、标点符号等),一般用两个字节存储
对于偏远地区,或者极少使用的字符(例如藏文、蒙古文等),才使用三个甚至四个字节存储
总起来说,越常用的字符占用的内存越少,越罕见的字符占用的内存越多。
中文编码方案: GB2312 --> GBK --> GB18030 是中文编码的三套方案,出现的时间从早到晚,收录的字符数目依次增加,并且向下兼容。GB2312 和 GBK 收录的字符数目较少,用 1~2个字节存储;GB18030 收录的字符最多,用 1、2、4 个字节存储。
从整体上讲,GB2312 和 GBK 的编码方式一致,具体为:对于 ASCII 字符,使用一个字节存储,并且该字节的最高位是 0,这和 ASCII 编码是一致的,所以说 GB2312 完全兼容 ASCII。对于中国的字符,使用两个字节存储,并且规定每个字节的最高位都是 1。例如对于字母A,它在内存中存储为 01000001;对于汉字中,它在内存中存储为 11010110 11010000。由于单字节和双字节的最高位不一样,所以字符处理软件很容易区分一个字符到底用了几个字节。
GB18030 为了容纳更多的字符,并且要区分两个字节和四个字节,所以修改了编码方案,具体为:对于 ASCII 字符,使用一个字节存储,并且该字节的最高位是 0,这和 ASCII、GB2312、GBK 编码是一致的。对于常用的中文字符,使用两个字节存储,并且规定第一个字节的最高位是 1,第二个字节的高位最多只能有一个连续的 0(第二个字节的最高位可以是 1 也可以是 0,但是当它是 0 时,次高位就不能是 0 了)。注意对比 GB2312 和 GBK,它们要求两个字节的最高位为都必须为 1。对于罕见的字符,使用四个字节存储,并且规定第一个和第三个字节的最高位是 1,第二个和第四个字节的高位必须有两个连续的 0。例如对于字母A,它在内存中存储为 01000001;对于汉字中,它在内存中存储为 11010110 11010000;对于藏文གྱུ,它在内存中的存储为 10000001 00110010 11101111 00110000。
字符处理软件在处理文本时,从左往右依次扫描每个字节:
如果遇到的字节的最高位是 0,那么就会断定该字符只占用了一个字节
如果遇到的字节的最高位是 1,那么该字符可能占用了两个字节,也可能占用了四个字节,不能妄下断论,所以还要继续往后扫描
如果第二个字节的高位有两个连续的 0,那么就会断定该字符占用了四个字节
如果第二个字节的高位没有连续的 0,那么就会断定该字符占用了两个字节
可见,当字符占用两个或者四个字节时,GB18030 编码要检测两次,处理效率比 GB2312 和 GBK 都低。GBK 编码最牛掰: GBK 于 1995 年发布,这一年也是互联网爆发的元年,国人使用电脑越来越多,也许是 GBK 这头猪正好站在风口上,它就飞起来了,后来的中文版 Windows 都将 GBK 作为默认的中文编码方案。注意,这里我说 GBK 是默认的中文编码方案,并没有说 Windows 默认支持 GBK。Windows 在内核层面使用的是 Unicode 字符集(严格来说是 UTF-16 编码),但是它也给用户留出了选择的余地,如果用户不希望使用 Unicode,而是希望使用中文编码方案,那么这个时候 Windows 默认使用 GBK(当然,你可以选择使用 GB2312 或者 GB18030,不过一般没有这个必要)。实际上,中文版 Windows 下的很多程序默认使用的就是 GBK 编码,例如用记事本程序创建一个 txt 文档、在 cmd 或者控制台程序(最常见的C语言程序)中显示汉字、用 Visual Studio 创建的源文件等,使用的都是 GBK 编码。可以说,GBK 编码在中文版的 Windows 中大行其道。
6.3 Unicode字符集
ASCII、GB2312、GBK、Shift_Jis、ISO/IEC 8859 等地区编码都是各个国家为了自己的语言文化开发的,不具有通用性,在一种编码下开发的软件或者编写的文档,拿到另一种编码下就会失效,必须提前使用程序转码,非常麻烦。人们迫切希望有一种编码能够统一世界各地的字符,计算机只要安装了这一种文字编码,就能支持使用世界上所有的文字,再也不会出现乱码,再也不需要转码了,这对计算机的数据传递来说是多么的方便呀!就在这种呼吁下,Unicode 诞生了。Unicode 也称为统一码、万国码;看名字就知道,Unicode 希望统一所有国家的字符编码。Unicode 于 1994 年正式公布第一个版本,现在的规模可以容纳 100 多万个符号,是一个很大的集合。
有兴趣的读取可以转到 https://unicode-table.com/cn/ 查看 Unicode 包含的所有字符,以及各个国家的字符是如何分布的。
Windows、Linux、Mac OS 等常见操作系统都已经从底层(内核层面) 开始支持 Unicode,大部分的网页和软件也使用 Unicode,Unicode 是大势所趋。不过由于历史原因,目前的计算机仍然安装了 ASCII 编码以及 GB2312、GBK、Big5、Shift-JIS 等地区编码,以支持不使用 Unicode 的软件或者文档。内核在处理字符时,一般会将地区编码先转换为 Unicode,再进行下一步处理。本节我们多次说 Unicode 是一套字符集,而不是一套字符编码,它们之间究竟有什么区别呢?
严格来说,字符集和字符编码不是一个概念:
- 字符集定义了字符和二进制的对应关系,为每个字符分配了唯一的编号。可以将字符集理解成一个很大的表格,它列出了所有字符和二进制的对应关系,计算机显示文字或者存储文字,就是一个查表的过程。
- 而字符编码规定了如何将字符的编号存储到计算机中。如果使用了类似 GB2312 和 GBK 的变长存储方案(不同的字符占用的字节数不一样),那么为了区分一个字符到底使用了几个字节,就不能将字符的编号直接存储到计算机中,字符编号在存储之前必须要经过转换,在读取时还要再逆向转换一次,这套转换方案就叫做字符编码。
有的字符集在制定时就考虑到了编码的问题,是和编码结合在一起的,例如 ASCII、GB2312、GBK、BIG5 等,所以无论称作字符集还是字符编码都无所谓,也不好区分两者的概念。而有的字符集只管制定字符的编号,至于怎么存储,那是字符编码的事情,Unicode 就是一个典型的例子,它只是定义了全球文字的唯一编号,我们还需要 UTF-8、UTF-16、UTF-32 这几种编码方案将 Unicode 存储到计算机中。Unicode 可以使用的编码方案有三种,分别是:
UTF-8: 一种变长的编码方案,使用 1~6 个字节来存储
UTF-32: 一种固定长度的编码方案,不管字符编号大小,始终使用 4 个字节来存储
UTF-16: 介于 UTF-8 和 UTF-32 之间,使用 2 个或者 4 个字节来存储,长度既固定又可变
UTF 是 Unicode Transformation Format 的缩写,意思是 Unicode转换格式,后面的数字表明至少使用多少个比特位(Bit)来存储字符。
1、UTF-8,UTF-8 的编码规则很简单:如果只有一个字节,那么最高的比特位为 0,这样可以兼容 ASCII;如果有多个字节,那么第一个字节从最高位开始,连续有几个比特位的值为 1,就使用几个字节编码,剩下的字节均以 10 开头。具体的表现形式为:
0xxxxxxx: 单字节编码形式,这和 ASCII 编码完全一样,因此 UTF-8 是兼容 ASCII 的
110xxxxx 10xxxxxx: 双字节编码形式(第一个字节有两个连续的 1)
1110xxxx 10xxxxxx 10xxxxxx: 三字节编码形式(第一个字节有三个连续的 1)
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx: 四字节编码形式(第一个字节有四个连续的 1)
xxx 就用来存储 Unicode 中的字符编号。下面是一些字符的 UTF-8 编码实例(绿色部分表示本来的 Unicode 编号):
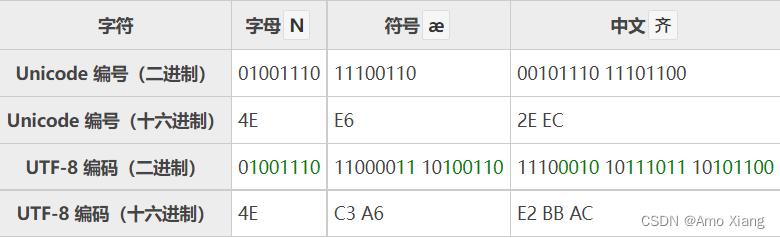
对于常用的字符,它的 Unicode 编号范围是 0 ~ FFFF,用 1~3 个字节足以存储,只有及其罕见,或者只有少数地区使用的字符才需要 4~6 个字节存储。
2、UTF-32, UTF-32 是固定长度的编码,始终占用 4 个字节,足以容纳所有的 Unicode 字符,所以直接存储 Unicode 编号即可,不需要任何编码转换。浪费了空间,提高了效率。
3、UTF-16, UFT-16 比较奇葩,它使用 2 个或者 4 个字节来存储。对于 Unicode 编号范围在 0 ~ FFFF 之间的字符,UTF-16 使用两个字节存储,并且直接存储 Unicode 编号,不用进行编码转换,这跟 UTF-32 非常类似。对于 Unicode 编号范围在 10000~10FFFF 之间的字符,UTF-16 使用四个字节存储,具体来说就是:将字符编号的所有比特位分成两部分,较高的一些比特位用一个值介于 D800~DBFF 之间的双字节存储,较低的一些比特位(剩下的比特位) 用一个值介于 DC00~DFFF 之间的双字节存储。如果你不理解什么意思,请看下面的表格:

以上是关于C 语言学习笔记:编程基础的主要内容,如果未能解决你的问题,请参考以下文章