性能优化方法论系列五实际案例分析
Posted 明明如月学长
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了性能优化方法论系列五实际案例分析相关的知识,希望对你有一定的参考价值。
性能优化方法论系列目录
《一、性能优化的本质》
《二、性能优化方法论的思想源泉》
《三、性能优化的核心思想(1)》
《三、性能优化的核心思想(2)》
《三、性能优化的核心思想(3)》
《四、性能优化的注意事项》
《五、实际案例分析》
《六、总结》
5.1 案例描述
下面给出一个模拟的业务场景,大家可以结合上面给出的性能优化核心思路,自己先设计一个性能优化的方案再和给出的方案进行对比,如果自己设计的方案更好,为你点赞;如果设计的方案没有给出去的方案更好,对比下差异。
注:本文给出的方案未必是最佳,只是希望帮助大家理解性能优化思想如何应用。
功能描述:
用户浏览活动时根据是否订阅过该活动,来决定是否展示 “订阅提醒” 按钮。
用户可以通过点击 “订阅提醒” 进行订阅,用户订阅后活动开始前 10 分钟发送微信公众号消息提醒用户参与活动。
用户量可能较大,预计每个活动最大可能有几十万甚至上百万。
同一个活动可以开展多轮,下一轮订阅的时候只发送当前轮次订阅的这一批人。
需要思考的问题:
- 数据存在哪里?
- 如何尽快把消息发出去?
- 大量的消息发送会不会超过下游承载能力?
- 每次浏览活动时都要查询当前用户是否订阅过该活动,如果瞬间涌入大量流量怎么办?
- 如何保证查询的性能?
- 大量发送完毕的订阅数据如何清除?
- …
5.2 设计分析
问题1:数据存在哪里?
单个活动就可能上百万的数据量,如果使用 mysql 存储就要考虑分库分表,外加读写分离。
如果存储到 Redis,会造成大 key, 就需要采用化整为零的思想,采用类似多级索引的方式,将订阅数据分拆到多级 key 中,实现起来很麻烦。
如果使用 MySQL 表来存储当前订阅的轮数,代价有点大。可以使用 Redis 存储某个活动当前订阅的轮数,发送完提醒后轮数 +1。
订阅数据可以使用 HBase 进行存储,将 活动id(activityId), 用户id(userId), 批次id(batchId) 作为 rowkey 。
为了尽可能消除热点的影响,并加快 scan 速度,将每个活动的 rowkey 再拆分到 16个桶中。如将用户 ID %16 得到 0 到 15 称为 bucketId, 最终 rowkey 结构类似如下:
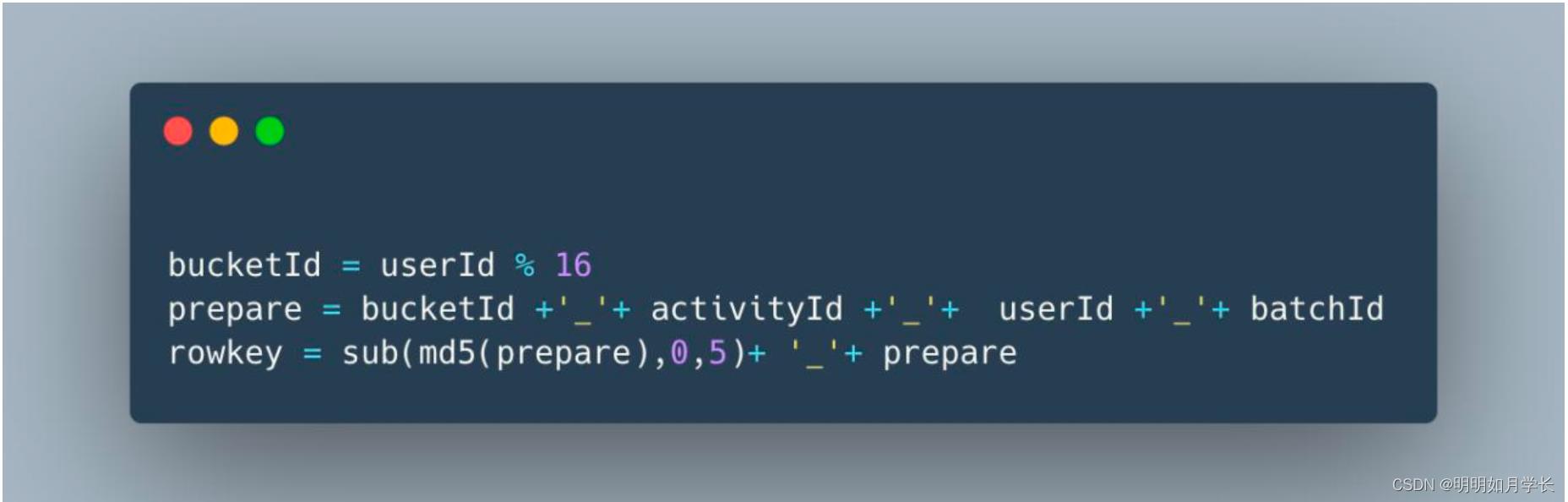
HBase 开启布隆过滤器,在判断当前用户是否订阅时,如果没有订阅,可以快速得到结果。
同时为了灵活性,桶的数量是通过 Apollo 来读取,如果有性能问题可以动态增加桶。
问题2:如何保证消息尽快发出去?
我们使用定时消息,活动开启前 10分钟回调过来,执行发送逻辑。
拼接 16 个桶的 scan 所需的 rowkey_start 和 rowkey_end ,发送到消息队列中,通过消息队列分发到多台机器并行 scan 每一个桶的数据。
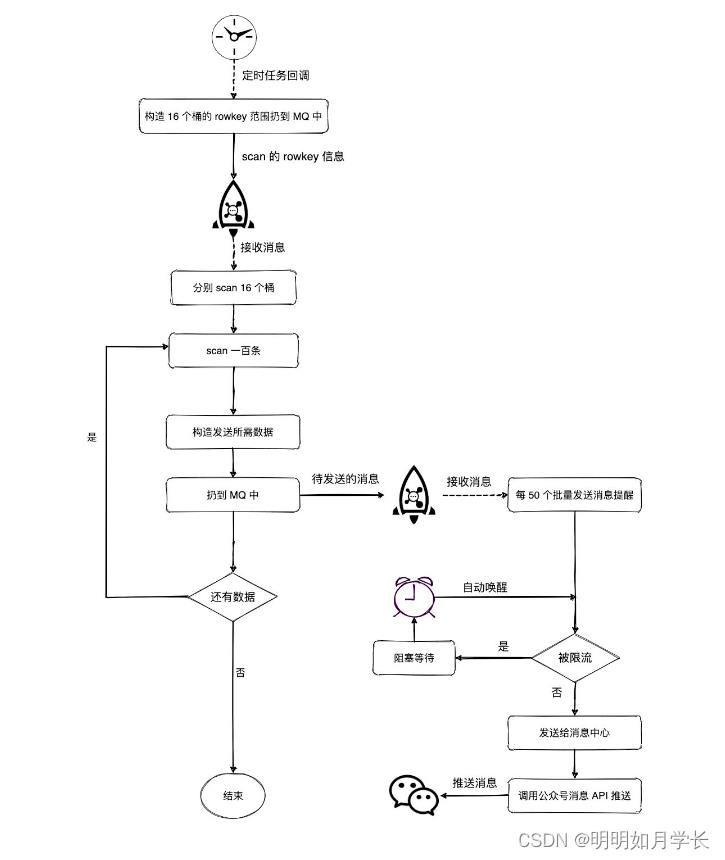
每次 scan 100 条扔到 MQ 中等待下游消费。
下游接收到消息后,每 50 个为一批发送给消息中心(消息中心负责消息的统一封装,并且提供了批量接口并限制一次 RPC 调用最多参数中传入 50 个消息)。
为了避免将消息中机器打爆,对消息的发送做了限流控制,将速率控制在每秒 6000 QPS 以内。
问题3:过期如何清除?
通过调研,发现公司的 HBase 架构目前还存在一些问题,调用 API 删除数据时不能确保百分比清除。
最终和产品交流加了限制条件,确定活动可以选的最长提醒时间为 1年,HBase 设置数据自动清空时间为 1 年。这样就不需要再重新 scan 调用 API 去清空数据,同时也减少了资源占用。
5.3 案例总结
在上述的设计案例中,用到了化整为零、同步转异步、合并操作 的优化思想;用到了根据存储框架(MySQL、Redis、HBase)的特点和算法(布隆过滤器)进行性能优化的思路。
设计中也有一些 加限制条件的地方:
(1)技术方面:下游的消息中心对上游有 QPS 限制,对批量接口的大小也做了限制。
(2)产品方面:为了配合技术方案,产品对发送消息的有效期做了限制,并且不支持用户取消订阅。
整个方案都是在不断权衡中确定下来的。还有一些其他细节上的考虑,在这里就不详细论述。
希望大家可以通过这个案例,能够实实在在地体会到性能优化思想在实际项目中的应用。能够在未来的实践中,更好地利用性能优化方法论来解决问题。
创作不易,如果本文对你有帮助,欢迎点赞、收藏加关注,你的支持和鼓励,是我创作的最大动力。

以上是关于性能优化方法论系列五实际案例分析的主要内容,如果未能解决你的问题,请参考以下文章