备战数学建模49-深度学习之长短期记忆网络LSTM(RNN)(攻坚战14)
Posted nuist__NJUPT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了备战数学建模49-深度学习之长短期记忆网络LSTM(RNN)(攻坚战14)相关的知识,希望对你有一定的参考价值。
我们今天学习一个长短期记忆网络,就是LSTM,它是循环神经网络的一种。在使用深度学习处理时序问题时,RNN是最常使用的模型之一。RNN之所以在时序数据上有着优异的表现是因为RNN在 t 时间片时会将 t−1 时间片的隐节点作为当前时间片的输入。这样有效的原因是之前时间片的信息也用于计算当前时间片的内容,而传统模型的隐节点的输出只取决于当前时间片的输入特征。LSTM的全称是Long Short Term Memory,顾名思义,它具有记忆长短期信息的能力的神经网络。LSTM首先在1997年由Hochreiter & Schmidhuber 提出,由于深度学习在2012年的兴起,LSTM又经过了若干代大牛的发展,由此便形成了比较系统且完整的LSTM框架,并且在很多领域得到了广泛的应用。本文着重介绍深度学习时代的LSTM。
目录
二、MATLAB深度学习之LSTM时间序列预测(单输入->单输出)
三、MATLAB深度学习之LSTM时间序列预测(多输入->单输出)
四、MATLAB深度学习之LSTM时间序列预测(多输入->多输出)
一、长短期记忆网络LSTM理论
1.1、LSTM基本结构
长短时记忆网络(Long Short Term Memory Network, LSTM),是一种改进之后的循环神经网络,可以解决RNN无法处理长距离的依赖的问题,目前比较流行。
长短期记忆网络的设计思路如下:
原始 RNN 的隐藏层只有一个状态,即h,它对于短期的输入非常敏感。再增加一个状态,即c,让它来保存长期的状态,称为单元状态(cell state)。

上面的是一个粗略的表示形式,下面我们剖析LSTM的结构图,看一下基本结构:
在 t 时刻,LSTM 的输入有三个:当前时刻网络的输入值 Xt、上一时刻 LSTM 的输出值 ht-1、以及上一时刻的单元状态 Ct-1;
LSTM 的输出有两个:当前时刻 LSTM 输出值 ht、和当前时刻的单元状态 Ct.

相比RNN,LSTM加入了一个长期单元C,那么怎样控制长期单元C呢,一般使用三个控制开关进行控制;具体如下:第一个控制开关控制继续保留C的状态,第二个控制把当前状态输入到长期状态C,第三个是控制把长期状态C作为当前LSTM的输出。

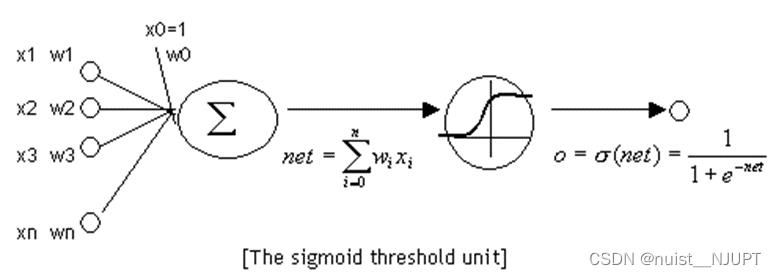
上面我们知道使用控制开关可以实现控制长期状态C,那么怎么在算法中实现上述三个开关呢,是通过门的方式实现的。定义:门(gate) 实际上就是一层全连接层,输入是一个向量,输出是一个 0到1 之间的实数向量。公式为:

方法:用门的输出向量按元素乘以我们需要控制的那个向量
原理:门的输出是 0到1 之间的实数向量
当门输出为 0 时,任何向量与之相乘都会得到 0 向量,这就相当于什么都不能通过;
输出为 1 时,任何向量与之相乘都不会有任何改变,这就相当于什么都可以通过。
1.2、LSTM的计算公式
1)向前计算公式
遗忘门(forget gate)
它决定了上一时刻的单元状态 Ct-1 有多少保留到当前时刻 Ct
输入门(input gate)
它决定了当前时刻网络的输入 Xt 有多少保存到单元状态 Ct
输出门(output gate)
控制单元状态 Ct 有多少输出到 LSTM 的当前输出值 ht
其中遗忘门的计算如下所示,遗忘门的计算公式中:
Wf 是遗忘门的权重矩阵,[ht-1, Xt] 表示把两个向量连接成一个更长的向量,bf是遗忘门的偏置项,σ 是 sigmoid 函数。

下面看输入门的计算,首先第一块的输入门是决定当前网络的输入xt有多少保存到记忆单元ct,可以避免无关紧要的内容进入记忆单元。

根据上一次的输出ht-1和本次的输入xt计算当前输入的状态,具体如下所示:

当前时刻的单元状态 Ct 的计算:由上一次的单元状态 Ct-1 按元素乘以遗忘门 ft,再用当前输入的单元状态 Ct 按元素乘以输入门 it,再将两个积加和:
这样,就可以把当前记忆 Ct 和长期记忆 Ct-1 组合在一起,形成了新的单元状态 Ct。
由于遗忘门的控制,它可以保存很久很久之前的信息,由于输入门的控制,它又可以避免当前无关紧要的内容进入记忆。

我们最后看一下输出门的计算,就是控制单元状态ct有多少记忆输出到LSTM的当前输出ht。
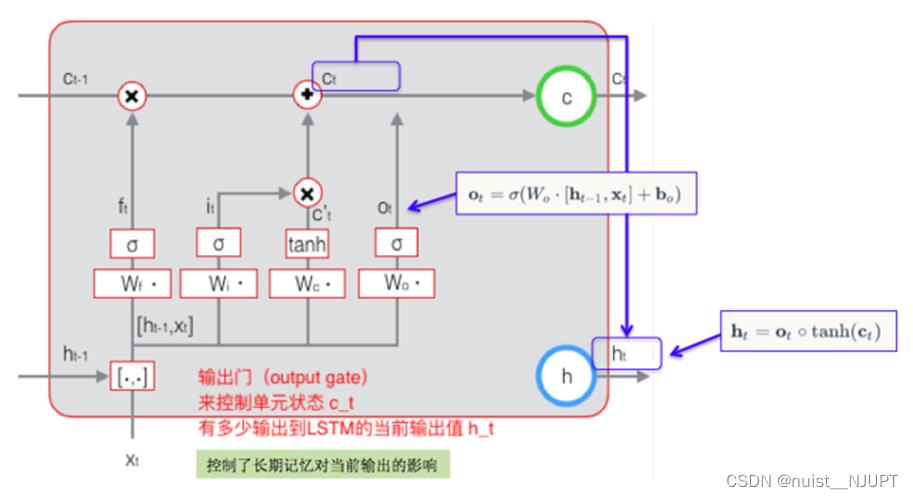
总结一下,向前计算公式一共包含如下,i、f、c、o分别为输入门、遗忘门、细胞状态,输出门,W 和 b 分别为对应的权重系数矩阵和偏置项;σ 和 tanh 分别为 sigmoid 和双曲正切激活函数。

2)反向传播训练算法
LSTM 模型训练过程采用的是与经典的反向传播(Back Propagation,BP) 算法原理类似的
BPTT 算法。大致可以分为 4 个步骤:①按照前向计算方法计算 LSTM 细胞的输出值;②反向计算每个 LSTM 细胞的误差项,包括按时间和网络层级 2 个反向传播方向;③根据相应的误差项,计算每个权重的梯度;④应用基于梯度的优化算法更新权重。
①按照前向计算方法计算 LSTM 细胞的输出值,就是上面的5个公式,即正向计算的过程,主要有5个部分需要计算。

②反向计算每个 LSTM 细胞的误差项,包括按时间和网络层级 2 个反向传播方向; 反向计算每个神经元的误差项值。与 RNN 一样,LSTM 误差项的反向传播也是包括两个方向: 一个是沿时间的反向传播,即从当前 t 时刻开始,计算每个时刻的误差项;一个是将误差项向上一层传播。
③根据相应的误差项,计算每个权重的梯度;gate 的激活函数定义为 sigmoid 函数,输出的激活函数为 tanh 函数。权重矩阵 W 都是由两个矩阵拼接而成,这两部分在反向传播中使用不同的公式,因此在后续的推导中,权重矩阵也要被写为分开的两个矩阵。

我们继续看一下具体的两个方向误差的计算,以及权重梯度的计算。
首先定义t时刻的误差项,目的是要计算出 t-1 时刻的误差项,如下所示:
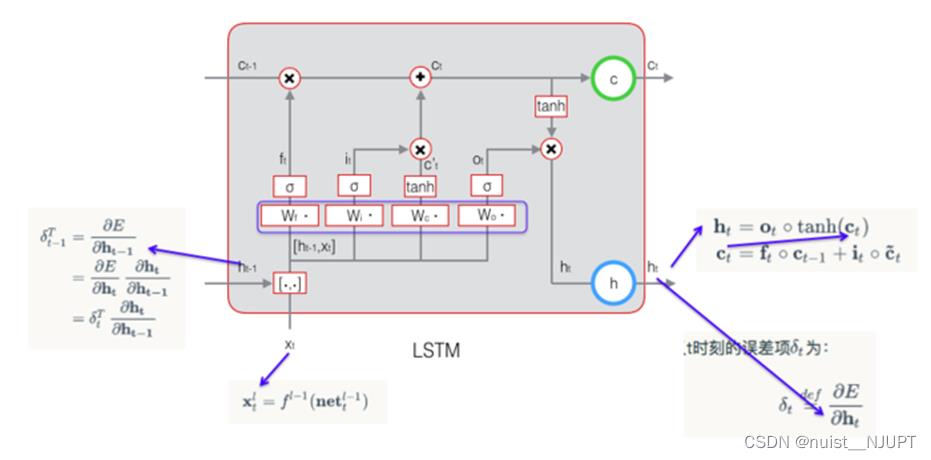
利用 ht Ct 的定义和全导数公式,可以得到将误差项向前传递到任意k时刻的公式:
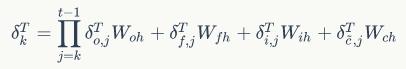
另外可以得到将误差项传递到上一层的公式,如下:
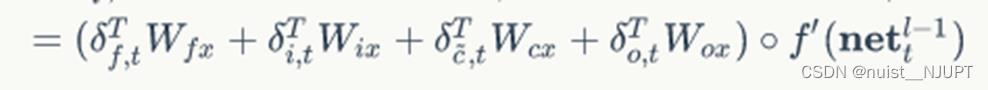
对于各个权重梯度的计算,具体的公式如下:

④应用基于梯度的优化算法更新权重。基于梯度的优化算法种类众多,用的比较多的就是随机梯
度下降 ( Stochastic Gradient Descent,SGD)。
二、MATLAB深度学习之LSTM时间序列预测(单输入->单输出)
2.1、数据集介绍
此示例说明如何使用长短期记忆(LSTM)网络预测时间序列数据。为了预测序列的未来时间步长的值,可以训练一个序列到序列回归LSTM网络,其中的响应是值移动了一个时间步长的训练序列。也就是说,在输入序列的每个时间步长,LSTM网络学习预测下一个时间步长的值。要预测未来多个时间点的值,请使用forectAndUpdateState函数一次预测一个时间点,并在每次预测时更新网络状态。
使用的数据集是股票数据,数据是out.txt文件,一共436组数据,数据共享在阿里云盘:阿里云盘分享
2.2、Matlab实现LSTM时间序列预测过程
1、加载数据
加载示例数据。某股票的收盘价,包含单个时间序列,时间步长为每日,值对应于每日收盘价。输出是一个单元数组,其中每个元素都是单个时间步长。将数据重塑为行矢量。
2、 数据拆分
划分训练和测试数据。在序列的前90%进行训练,在最后10%进行测试。
3、数据归一化
为了更好地匹配和防止训练发散,将训练数据标准化为零均值和单位方差。在预测时,您必须使用与训练数据相同的参数来标准化测试数据。
注意:要预测序列的未来时间步长的值,请将响应指定为值移位一个时间步长的训练序列。也就是说,在输入序列的每个时间步长,LSTM网络学习预测下一个时间步长的值。
4、 创建LSTM回归网络。将LSTM层指定为具有128个隐藏单元。训练参数可查看帮助,明白其中含义。
5、训练网络
使用TrainNetwork训练LSTM网络。
6、预测(使用预测值更新网络状态)
要预测未来多个时间点的值,请使用forectAndUpdateState函数一次预测一个时间点,并在每次预测时更新网络状态。对于每个预测,使用先前的预测作为函数的输入。使用与训练数据相同的参数对测试数据进行标准化。
为了初始化网络状态,首先对训练数据XTrain进行预测。接下来,使用训练响应YTrain的最后一个时间步长进行第一个预测(完)。循环其余的预测,并将先前的预测输入到forectAndUpdateState。
对于大型数据集合、长序列或大型网络,在GPU上计算预测通常比在CPU上计算预测快。否则,在CPU上进行预测的计算速度通常会更快。对于单时间步长预测,请使用CPU。要使用CPU进行预测,请将recrectAndUpdateState的‘ExecutionEnvironment’选项设置为‘CPU’
使用先前计算的参数来取消预测的标准化,即反归一化。 用预测值绘制训练时间序列。
7、预测(使用测试数据更新网络状态)
如果您可以访问预测之间时间步长的实际值,则可以使用观测值而不是预测值来更新网络状态。首先,初始化网络状态。要对新序列进行预测,请使用Reset State重置网络状态。重置网络状态可防止先前的预测影响对新数据的预测。重置网络状态,然后通过对训练数据进行预测来初始化网络状态。
2.3、matlab代码实现LSTM时序预测
实现上述单输入,单输出的时间序列预测的matlab代码如下:
clear;
clc
%% 加载数据,某股票的收盘价,包含单个时间序列,时间步长为每日,值对应于每日收盘价。
data = importdata('out.txt');
data = data';
figure()
plot(data);
%% 划分训练集和测试集,90%训练,10%测试
numTimeStepsTrain = floor(0.9*numel(data));
dataTrain = data(1:numTimeStepsTrain+1);
dataTest = data(numTimeStepsTrain+1:end);
%% 数据的归一化处理,数据标准化为0均值,单位方差
mu = mean(dataTrain);
sig = std(dataTrain);
dataTrainStandardized = (dataTrain - mu) / sig;
%% 定义预测序列的未来时间步长的值,请将响应指定为值移位一个时间步长的训练序列
XTrain = dataTrainStandardized(1:end-1);
YTrain = dataTrainStandardized(2:end);
%% 定义LSTM网络结构,将LSTM层指定为具有128个隐藏单元
% 定义网络结构
layers = [
sequenceInputLayer(1,'Name','input')
lstmLayer(128,'Name','lstm')
fullyConnectedLayer(1,'Name','fc')
regressionLayer];
% 定义训练参数
options = trainingOptions('adam', ...
'MaxEpochs',250, ...
'GradientThreshold',1, ...
'InitialLearnRate',0.005, ...
'LearnRateSchedule','piecewise', ...
'LearnRateDropPeriod',125, ...
'LearnRateDropFactor',0.2, ...
'Verbose',0, ...
'Plots','training-progress');
% 训练网络
net = trainNetwork(XTrain,YTrain,layers,options);
%% 预测,使用预测值更新网络状态
% 测试集归一化
dataTestStandardized = (dataTest - mu) / sig;
XTest = dataTestStandardized(1:end-1);
% 预测
net = predictAndUpdateState(net,XTrain);
[net,YPred] = predictAndUpdateState(net,YTrain(end));
numTimeStepsTest = numel(XTest);
for i = 2:numTimeStepsTest
[net,YPred(:,i)] = predictAndUpdateState(net,YPred(:,i-1),'ExecutionEnvironment','cpu');
end
YPred = sig*YPred + mu; %反归一化
%% 绘图
figure
plot(dataTrain(1:end-1))
hold on
idx = numTimeStepsTrain:(numTimeStepsTrain+numTimeStepsTest);
plot(idx,[data(numTimeStepsTrain) YPred],'k.-'),hold on
plot(idx,data(numTimeStepsTrain:end-1),'r'),hold on
hold off
xlabel('Day')
ylabel('P')
title('Forecast')
legend('Observed', 'Forecast')
%% 预测,使用测试数据更新网络状态
net = resetState(net);
net = predictAndUpdateState(net,XTrain);
YPred = [];
numTimeStepsTest = numel(XTest);
for i = 1:numTimeStepsTest
[net,YPred(:,i)] = predictAndUpdateState(net,XTest(:,i),'ExecutionEnvironment','cpu');
end
YPred = sig*YPred + mu;
%% 绘图
figure
plot(dataTrain(1:end-1))
hold on
idx = numTimeStepsTrain:(numTimeStepsTrain+numTimeStepsTest);
plot(idx,[data(numTimeStepsTrain) YPred],'k.-'),hold on
plot(idx,data(numTimeStepsTrain:end-1),'r'),hold on
hold off
xlabel('Day')
ylabel('P')
title('Forecast')
legend('Observed', 'Forecast') 原始数据的时间序列图如下:

训练的过程如下:

使用预测数据更新网络进行预测的效果如下:

使用测试数据更新网络的预测效果如下:

三、MATLAB深度学习之LSTM时间序列预测(多输入->单输出)
3.1数据集准备
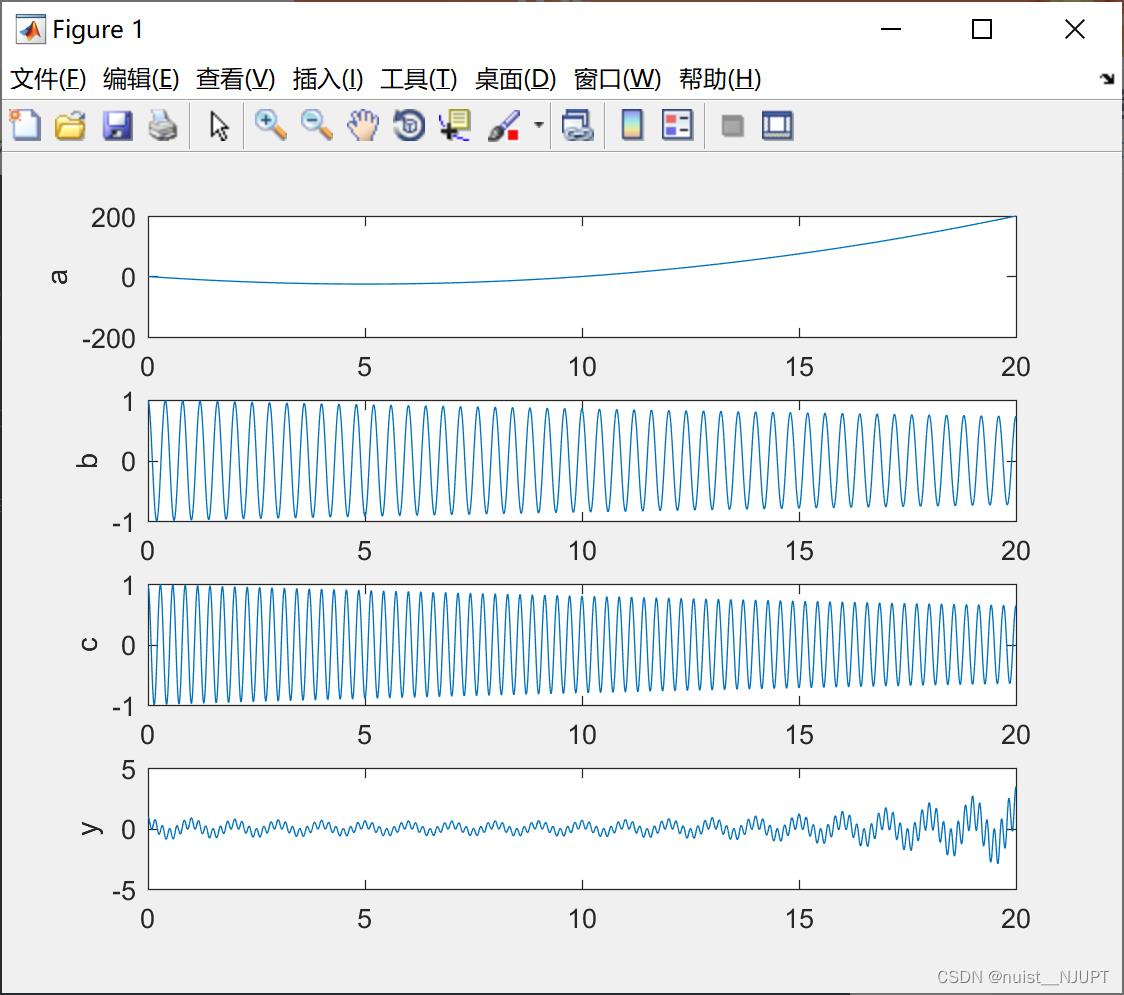
我们使用matlab模拟输入和输出数据,进行预测,输入三组数据,输出一组数据,即多输入和单输出的数据集。
clear,clc
t = (0.01:0.01:20)';
a = (t.^2 - 10 * t);
b = cos(5*pi*t).*exp(-5*pi*0.001*t);
c = cos(7*pi*t).*exp(-7*pi*0.001*t);
% y = a*0.001 + b + c; % 线性
% y = a*0.001 + b.^2 + c; % 二次非线性
% y = a.*b + c; % 非线性
y = exp(a*0.01).*c.*b; % 高度非线性
subplot(4,1,1)
plot(t,a)
ylabel('a')
subplot(4,1,2)
plot(t,b)
ylabel('b')
subplot(4,1,3)
plot(t,c)
ylabel('c')
subplot(4,1,4)
plot(t,y)
ylabel('y')如下a,b,c模拟三组输入信号,y模拟一组输出信号,我们根据三组输入数据完成相应的预测。
3.2、matlab实现lstm模型的多输入单输出预测
下面使用lstm模型进行划分数据集并进行预测,matlab代码如下:
clear,clc
%% 模拟数据
t = (0.01:0.01:20)';
a = (t.^2 - 10 * t);
b = cos(5*pi*t).*exp(-5*pi*0.001*t);
c = cos(7*pi*t).*exp(-7*pi*0.001*t);
% y = a*0.001 + b + c; % 线性
% y = a*0.001 + b.^2 + c; % 二次非线性
% y = a.*b + c; % 非线性
y = exp(a*0.01).*c.*b; % 高度非线性
subplot(4,1,1)
plot(t,a)
ylabel('a')
subplot(4,1,2)
plot(t,b)
ylabel('b')
subplot(4,1,3)
plot(t,c)
ylabel('c')
subplot(4,1,4)
plot(t,y)
ylabel('y')
%% 数据集分割与标准化
% 定义测试与训练长度
data = [a,b,c,y];
numTimeStepsTrain = floor(0.9*numel(y));
dataTrain = data(1:numTimeStepsTrain+1,:);
dataTest = data(numTimeStepsTrain+1:end,:);
% 归一化
mu = mean(dataTrain);
sig = std(dataTrain);
dataTrainStandardized = (dataTrain - ones(length(dataTrain(:,1)),1)*mu) ./ (ones(length(dataTrain(:,1)),1)*sig);
% 生成训练集输入与输出
XTrain = dataTrainStandardized(:,1:3)';
YTrain = dataTrainStandardized(:,4)';
%% 建立网络层,配置训练参数
layers = [
sequenceInputLayer(3,"Name","input")
lstmLayer(200,"Name","lstm")
dropoutLayer(0.1,"Name","drop")
fullyConnectedLayer(1,"Name","fc")
regressionLayer("Name","regressionoutput")];
options = trainingOptions('adam', ...
'MaxEpochs',250, ...
'GradientThreshold',1, ...
'InitialLearnRate',0.005, ...
'LearnRateSchedule','piecewise', ...
'LearnRateDropPeriod',125, ...
'LearnRateDropFactor',0.2, ...
'Verbose',0, ...
'Plots','training-progress');
%% 测试数据归一化
% 测试集归一化
dataTestStandardized = (dataTest - ones(length(dataTest(:,1)),1)*mu) ./ (ones(length(dataTest(:,1)),1)*sig);
% XTest = dataTestStandardized(1:end-1);
XTest = dataTestStandardized(:,1:3)';
%% 多步预测
net = predictAndUpdateState(net,XTrain);
numTimeStepsTest = numel(XTest(1,:));
YPred = [];
for i = 1:numTimeStepsTest
[net,YPred(i)] = predictAndUpdateState(net,XTest(:,i),'ExecutionEnvironment','cpu');
end
YPred = sig(4)*YPred + mu(4);
%% 可视化
% 绘图
idx = (numTimeStepsTrain+1):(numTimeStepsTrain+numTimeStepsTest);
figure
set(gcf,'position',[1,1,1500,1000])
set(gca,'position',[0.1,0.1,0.8,4])
subplot(2,1,1)
plot(data(1:end,4))
hold on
plot(idx, YPred,'-.k',LineWidth=1.5)
hold off
xlabel("t")
ylabel("y")
% xlim([1800,2000])
subplot(2,1,2)
plot(data(1:end,4))
hold on
plot(idx, YPred,'-.^k')
hold off
xlabel("t")
ylabel("y")
xlim([1800,2000])
title("Forecast")
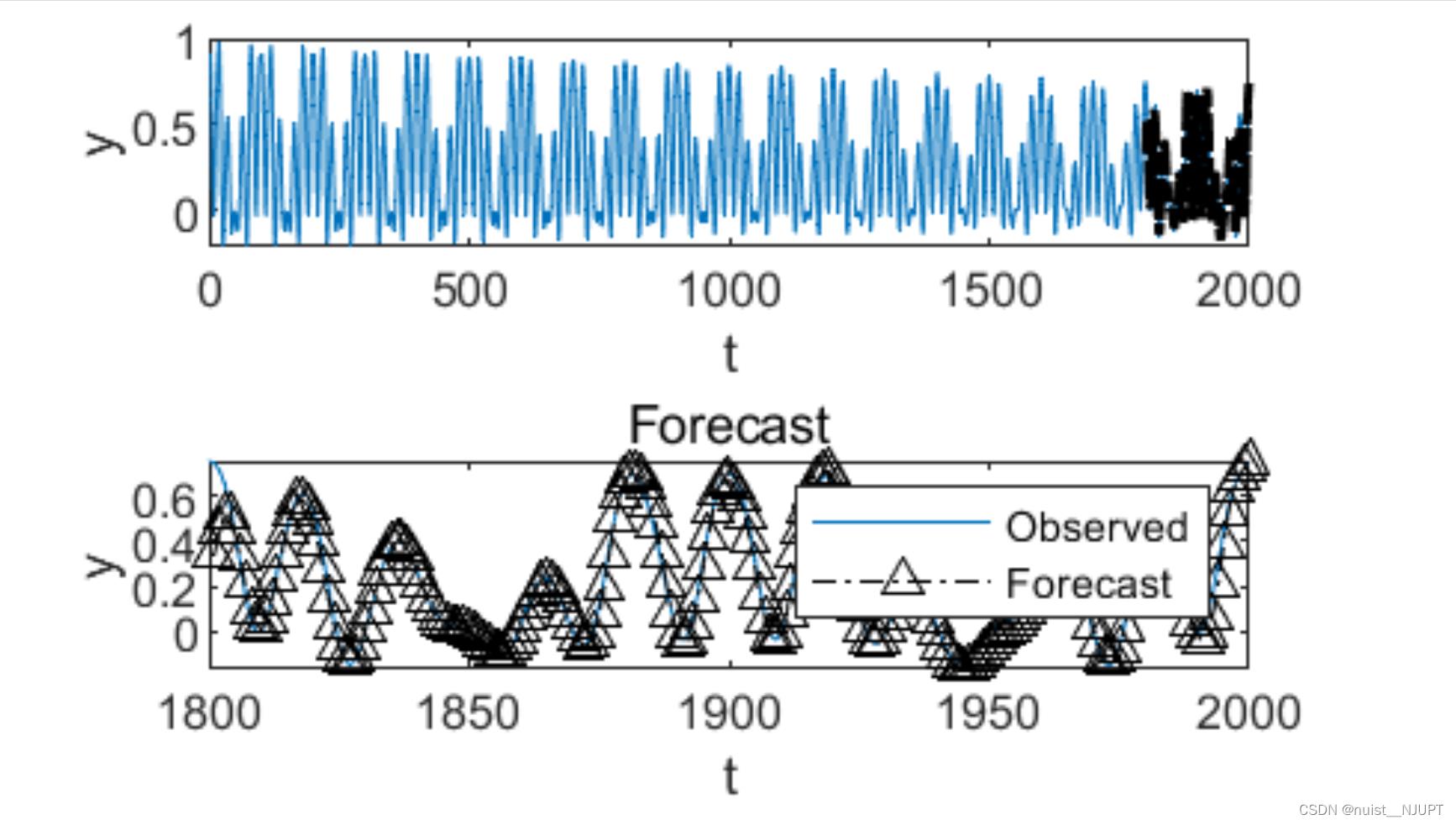
legend(["Observed" "Forecast"]) 预测结果的可视化如下:

四、MATLAB深度学习之LSTM时间序列预测(多输入->多输出)
4.1、数据集准备
使用matlab模拟出三组输入和三组输出作为预测的数据集。
4.2、matlab实现lstm模型的多输入多输出预测
%% 模拟数据
clear,clc,close all
t = (0.01:0.01:20)';
a = (t.^2 - 10 * t);
b = cos(5*pi*t).*exp(-5*pi*0.001*t);
c = cos(7*pi*t).*exp(-7*pi*0.001*t);
x = a*0.001 + b + c; % 线性
% x = a*0.001 + b.^2 + c; % 二次非线性
% x = a.*b + c; % 非线性
% x = exp(a*0.01).*c.*b; % 高度非线性
y = b .* sin(x);
z = (a + b + c) .* cos(x + y);
figure
subplot(3,1,1)
plot(t,a)
ylabel('a')
subplot(3,1,2)
plot(t,b)
ylabel('b')
subplot(3,1,3)
plot(t,c)
ylabel('c')
figure
subplot(3,1,1)
plot(t,x)
ylabel('x')
subplot(3,1,2)
plot(t,y)
ylabel('y')
subplot(3,1,3)
plot(t,z)
ylabel('z')
%% 数据的预处理
% 定义测试与训练长度
data = [a,b,c,x,y,z];
numTimeStepsTrain = floor(0.9*numel(y));
dataTrain = data(1:numTimeStepsTrain+1,:);
dataTest = data(numTimeStepsTrain+1:end,:);
% 归一化
mu = mean(dataTrain);
sig = std(dataTrain);
dataTrainStandardized = (dataTrain - ones(length(dataTrain(:,1)),1)*mu) ./ (ones(length(dataTrain(:,1)),1)*sig);
% 生成训练集输入与输出
XTrain = dataTrainStandardized(:,1:3)';
YTrain = dataTrainStandardized(:,4:6)';
%% 建立网络结构,训练网络
layers = [
sequenceInputLayer(3,"Name","input")
lstmLayer(200,"Name","lstm")
dropoutLayer(0.1,"Name","drop")
lstmLayer(200,"Name","lstm")
dropoutLayer(0.1,"Name","drop")
fullyConnectedLayer(50,"Name","fc")
fullyConnectedLayer(3,"Name","fc")
regressionLayer("Name","regressionoutput")];
options = trainingOptions('adam', ...
'MaxEpochs',250, ...
'GradientThreshold',1, ...
'InitialLearnRate',0.005, ...
'LearnRateSchedule','piecewise', ...
'LearnRateDropPeriod',125, ...
'LearnRateDropFactor',0.2, ...
'Verbose',0, ...
'MiniBatchSize',3, ...
'Plots','training-progress');
net = trainNetwork(XTrain,YTrain,layers,options);
%% 预测
% 测试集归一化
dataTestStandardized = (dataTest - ones(length(dataTest(:,1)),1)*mu) ./ (ones(length(dataTest(:,1)),1)*sig);
% XTest = dataTestStandardized(1:end-1);
XTest = dataTestStandardized(:,1:3)';
% 数据存放内存
adsXTrain = arrayDatastore(XTrain,'OutputType','cell','IterationDimension',3);
adsYTrain = arrayDatastore(YTrain,'OutputType','cell','IterationDimension',3);
cdsTrain = combine(adsXTrain,adsYTrain);
net = trainedNetwork_1;
% net = predictAndUpdateState(net,XTrain);
numTimeStepsTest = numel(XTest(1,:));
YPred = [];
for i = 1:numTimeStepsTest
[net,YPred(:,i)] = predictAndUpdateState(net,XTest(:,i),'ExecutionEnvironment','cpu');
end
YPred = diag(sig(4:6))*YPred + ones(length(YPred(:,1)),1).*mu(4:6)';
%% 可视化
idx = (numTimeStepsTrain+1):(numTimeStepsTrain+numTimeStepsTest);
label = ['x','y','z'];
for num=1:3
figure
set(gcf,'position',[1,1,1500,1000])
set(gca,'position',[0.1,0.1,0.8,4])
subplot(2,1,1)
plot(data(1:end,num+3))
hold on
plot(idx, YPred(num,:),'-.k',LineWidth=1.5)
hold off
xlabel("t")
ylabel(label(num))
% xlim([1800,2000])
subplot(2,1,2)
plot(data(1:end,num+3))
hold on
plot(idx, YPred(num,:),'-.^k')
hold off
xlabel("t")
ylabel(label(num))
xlim([1800,2000])
title("Forecast")
legend(["Observed" "Forecast"])
end预测结果如下: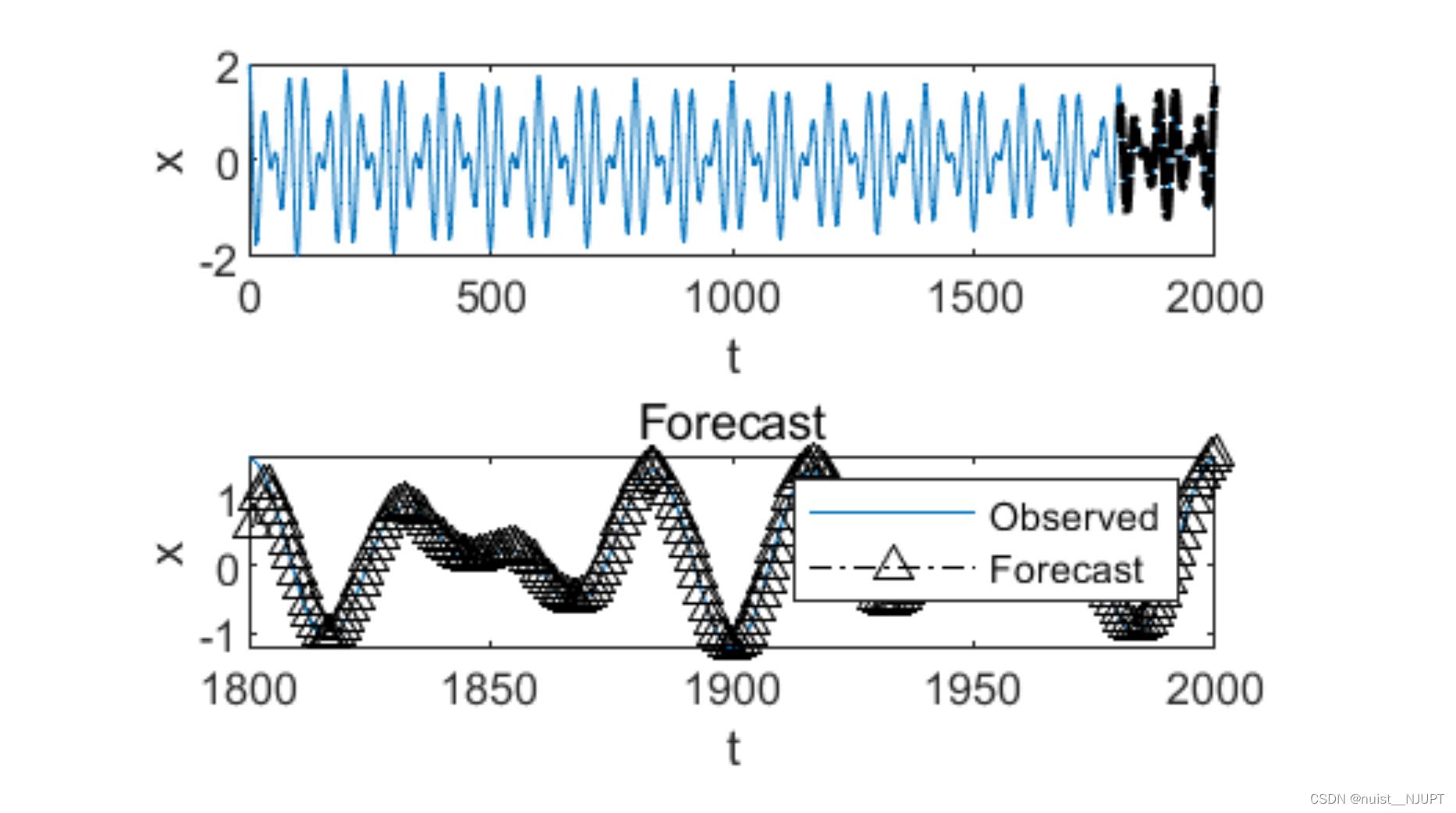

以上是关于备战数学建模49-深度学习之长短期记忆网络LSTM(RNN)(攻坚战14)的主要内容,如果未能解决你的问题,请参考以下文章