Elasticsearch - IK分词器;文档得分机制
Posted MinggeQingchun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch - IK分词器;文档得分机制相关的知识,希望对你有一定的参考价值。
阅读本文前可先参考
Elasticsearch - Kibana(四)_MinggeQingchun的博客-CSDN博客
https://blog.csdn.net/MinggeQingchun/article/details/126768243
一、IK分词器
中文分词
ES 的默认分词器无法识别中文中测试、单词这样的词汇,而是简单的将每个字拆完分为一 个词

解决方案: 采用IK分词器
(一)IK分词器下载安装
官网下载地址:
Releases · medcl/elasticsearch-analysis-ik · GitHub
找到对应Elasticsearch对应版本下载即可
将解压后的后的文件夹放入 ES 根目录下的 plugins 目录下,重启 ES 即可使用
(二)IK分词器使用
IK 分词器提供了两个分词算法:
ik_smart:最少切分
Ik_max_word:最细粒度划分
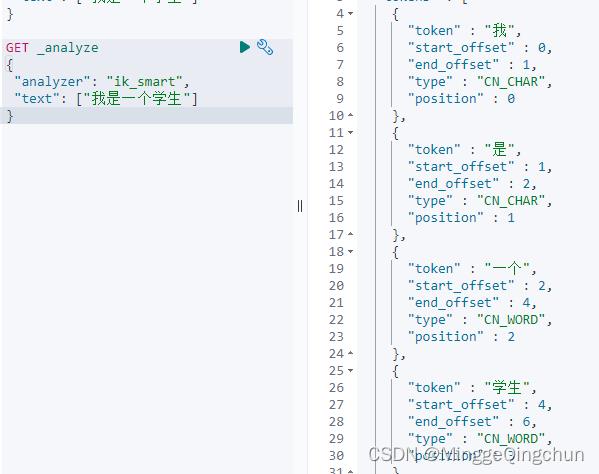
1、使用 ik_smart 算法对之前得中文内容进行分词
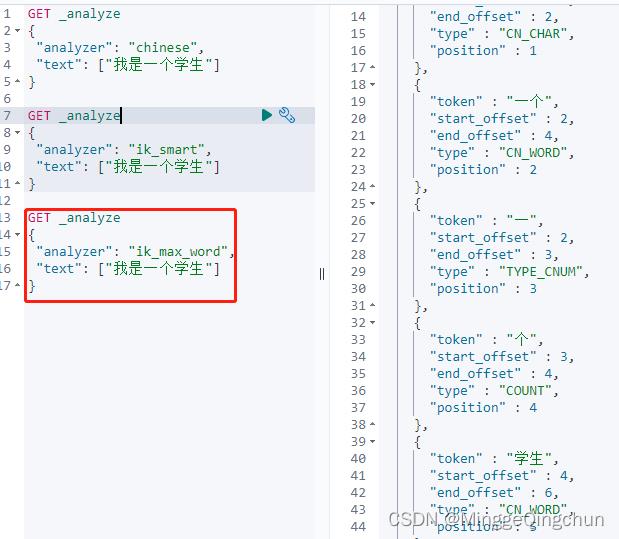
2、ik_max_word 算法分词
(三)自定义分词器
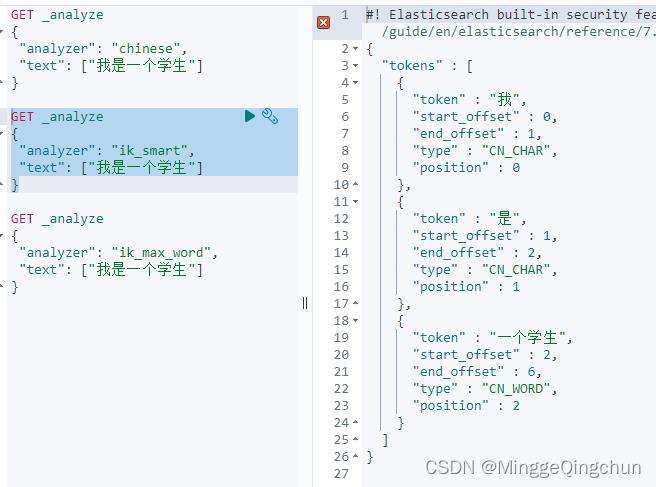
1、首先进入 ES 根目录中的 plugins 文件夹下的 ik 文件夹,进入 config 目录,创建 custom.dic 文件,写入"一个学生"

2、打开 IKAnalyzer.cfg.xml 文件,将新建的 custom.dic 配置其中, 重启 ES 服务器

重启服务器,测试效果
二、文档得分机制
Lucene 和 ES 的得分机制是一个基于词频和逆文档词频的公式,简称为 TF-IDF(term frequency–inverse document frequency) 公式

TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency)
TF (词频)
Term Frequency : 搜索文本中的各个词条(term)在查询文本中出现了多少次,出现次数越多,就越相关,得分会比较高
IDF(逆文档频率)
Inverse Document Frequency : 搜索文本中的各个词条(term)在整个索引的所有文档中出现了多少次,出现的次数越多,说明越不重要,也就越不相关,得分就比较低
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TFIDF实际上是:TF * IDF,TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)。TF表示词条在文档d中出现的频率。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。这就是IDF的不足之处.
词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的频率
这个数字是对词数(term count)的归一化,以防止它偏向长的文
(一)打分机制
1、基础数据
# 创建索引
PUT /myindex
# 增加文档数据
# 此时索引中只有这一条数据
PUT /myindex/_doc/1
"text":"hello"
2、查询匹配条件的文档数据
GET /myindex/_search
"query":
"match":
"text": "hello"
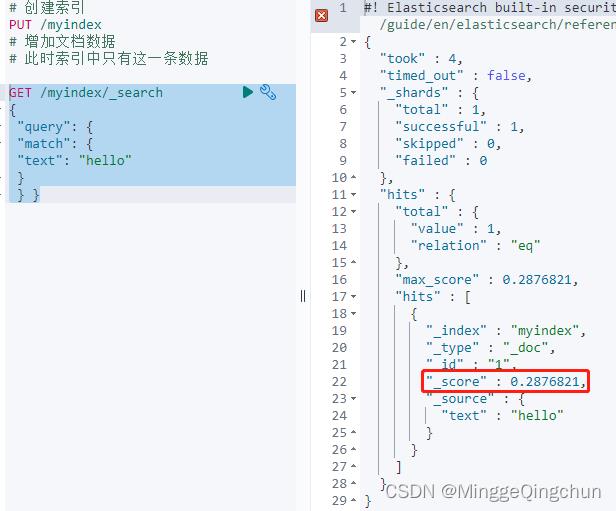
这里文档的得分为:0.2876821
3、分析文档数据打分过程
# 增加分析参数
GET /myindex/_search?explain=true
"query":
"match":
"text": "hello"
返回输出
"took" : 2,
"timed_out" : false,
"_shards" :
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
,
"hits" :
"total" :
"value" : 1,
"relation" : "eq"
,
"max_score" : 0.2876821,
"hits" : [
"_shard" : "[myindex][0]",
"_node" : "cbR5pVsVS1q0NR3kt24wzg",
"_index" : "myindex",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" :
"text" : "hello"
,
"_explanation" :
"value" : 0.2876821,
"description" : "weight(text:hello in 0) [PerFieldSimilarity], result of:",
"details" : [
"value" : 0.2876821,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
"value" : 2.2,
"description" : "boost",
"details" : [ ]
,
"value" : 0.2876821,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
"value" : 1,
"description" : "n, number of documents containing term",
"details" : [ ]
,
"value" : 1,
"description" : "N, total number of documents with field",
"details" : [ ]
]
,
"value" : 0.45454544,
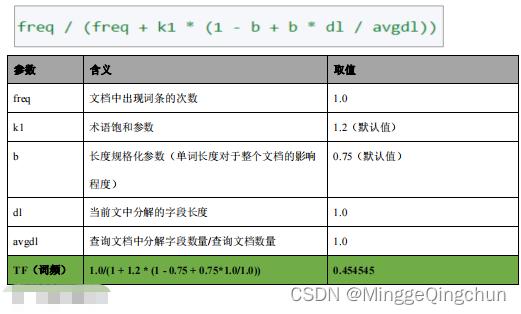
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
,
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
,
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
,
"value" : 1.0,
"description" : "dl, length of field",
"details" : [ ]
,
"value" : 1.0,
"description" : "avgdl, average length of field",
"details" : [ ]
]
]
]
]
打分机制中有 2 个重要阶段:计算 TF 值和 IDF 值

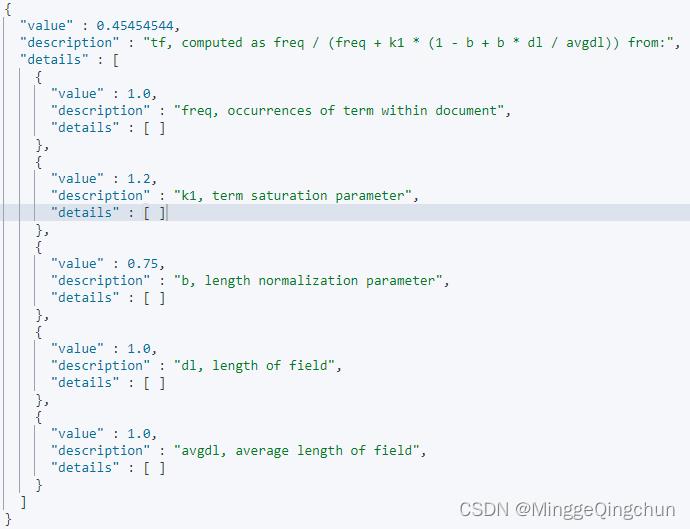
最后的分数

4、计算TF值

5、计算IDF值


6、计算文档得分

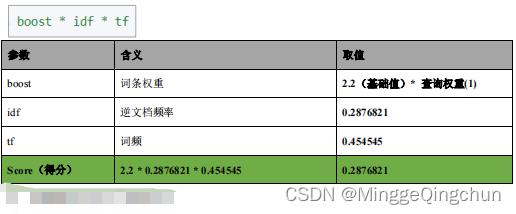
7、增加新的文档,测试得分
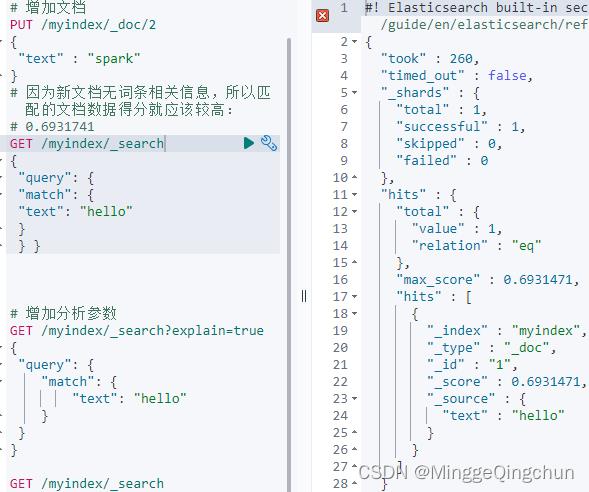
(1)增加一个毫无关系的文档
# 增加文档
PUT /myindex/_doc/2
"text" : "spark"
# 因为新文档无词条相关信息,所以匹配的文档数据得分就应该较高:
# 0.6931741
GET /myindex/_search
"query":
"match":
"text": "hello"
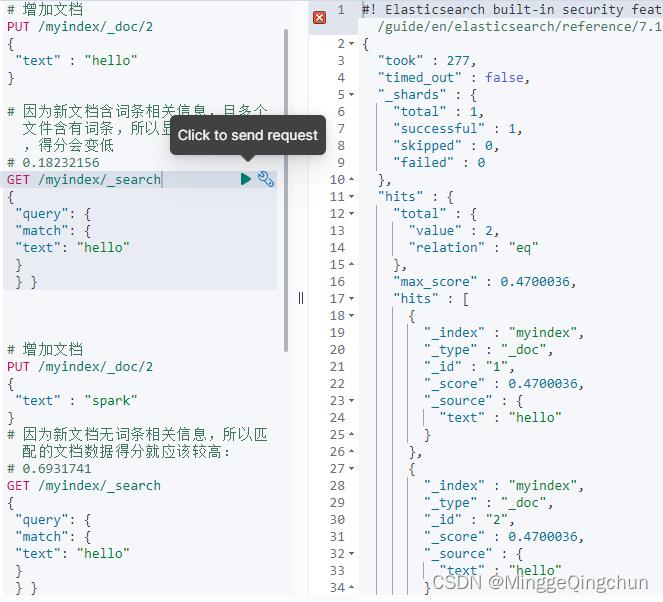
(2)增加一个完全一样的文档
# 增加文档
PUT /myindex/_doc/2
"text" : "hello"
# 因为新文档含词条相关信息,且多个文件含有词条,所以显得不是很重要,得分会变低
# 0.18232156
GET /myindex/_search
"query":
"match":
"text": "hello"
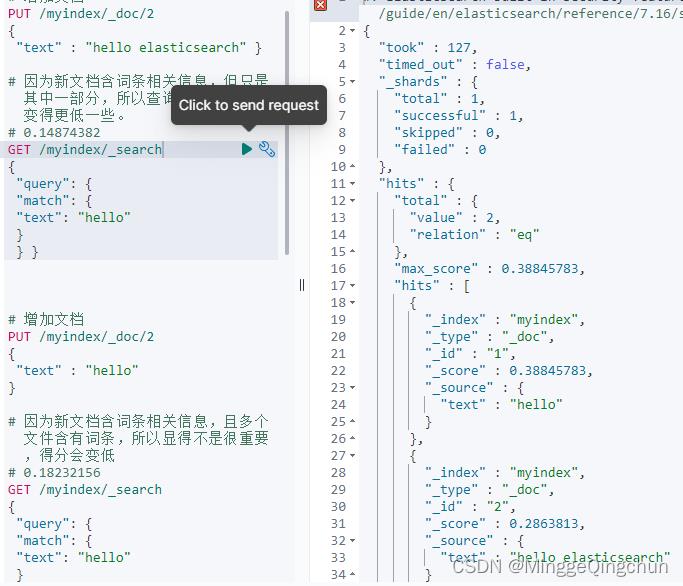
(3)增加一个含有词条,但是内容较多的文档
# 增加文档
PUT /myindex/_doc/2
"text" : "hello elasticsearch"
# 因为新文档含词条相关信息,但只是其中一部分,所以查询文档的分数会变得更低一些。
# 0.14874382
GET /myindex/_search
"query":
"match":
"text": "hello"
8、测试
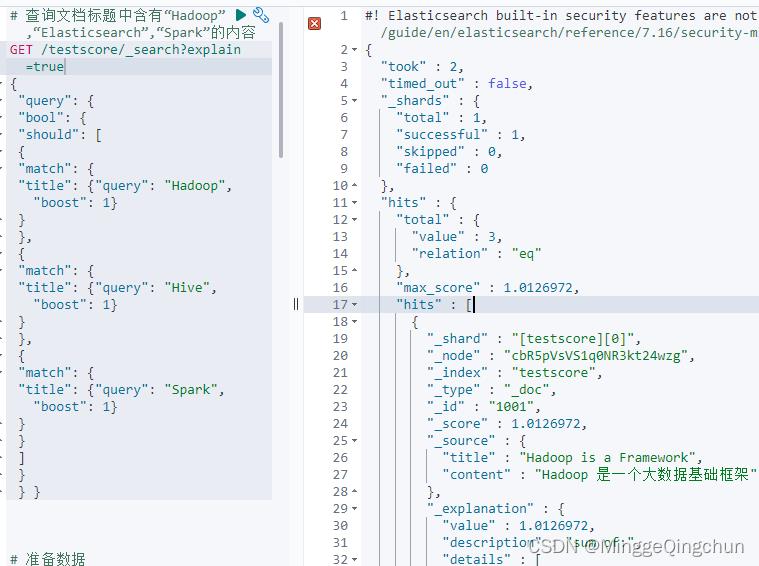
查询文档标题中含有“Hadoop”,“Elasticsearch”,“Spark”的内容;优先选择“Spark”的内容
(1)准备数据
# 准备数据
PUT /testscore/_doc/1001
"title" : "Hadoop is a Framework",
"content" : "Hadoop 是一个大数据基础框架"
PUT /testscore/_doc/1002
"title" : "Hive is a SQL Tools",
"content" : "Hive 是一个 SQL 工具"
PUT /testscore/_doc/1003
"title" : "Spark is a Framework",
"content" : "Spark 是一个分布式计算引擎"
(2)查询数据,Spark 的结果并不会放置在最前面
以上是关于Elasticsearch - IK分词器;文档得分机制的主要内容,如果未能解决你的问题,请参考以下文章