预训练语言模型入门
Posted CSU迦叶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了预训练语言模型入门相关的知识,希望对你有一定的参考价值。
Pre-trained Language Models(PLMs)
Language Modeling
语言模型(LM)很简单,可以认为是给定前面tokens预测下一个token。语言模型是最基础&最重要的NLP任务。LM包含大量需要用于语言理解的知识,例如语言知识和事实知识。并且训练语料是纯文本的,不需要人工注释。此外,LM学到的语言知识可以被轻易迁移到其他的NLP任务中。
历史上出现过的有代表性的语言模型有
-
Word2vec
-
Pre-trained RNN
-
GPT&BERT(基于transformer的预训练)
Pre-trained Language Models(PLMs)
预训练模型可以分成Feature-based和Fine-tuning这两种范式。
Feature-based
这种PLM将预训练当作是feature的提取过程,在大规模的语料上训练好模型参数后,将其编码表示作为固定的faeture交给下游做集体任务的模型,i.e. PLMs的输出作为下游任务models的输入,代表模型:Word2vec, ElMo。
Fine-tuning
把整个模型中的参数迁移到了下游任务中,是当前主流范式,相对上一种灵活性好很多,代表模型是BERT和GPT。
Fine-tuning Based PLMs
GPT 2018 OpenAI
-
由transformer decoder block组成
-
是非常强大的生成式模型
-
迁移到下游任务中也有很好的效果
-
成功的关键在于large unsupervised corpus和deep neural model的结合。
BERT
GPT之后的模型,目前最受欢迎的PLM,主要的改进是从单向到双向。
Masked LM <-> left-to-right LM
Unidirectional的问题是:语言理解是bidirectional。
那为何还用unidirectional?理由如下
-
生成一个符合语法规范的概率分布时方向时必要
-
在bidirectional的encoder中words can "see themselves"(发生信息泄露)
如下所示,在预测a这个token的时候由于可以看到下一个token,那么直接走shortcut就能够得到,模型就不会去做深度的推理,学到的有用知识减少了,这是bidirectional存在的天然问题。
BERT解决这个问题的方式是随机盖住(mask)一些token,然后在最后一层让模型还原masked tokens,也就是做一种基于cloze的训练。
BERT给了一个重要的启发:bigger == better 。
BERT并不完美(略)。
PLMs after BERT
RoBERTa
结构几乎不变,改进了BERT的预训练,更加稳健,收敛得更好的BERT,并且做了大量的实验。
ELECTRA
用了一个辅助的判别模型。
更多见GitHub - thunlp/PLMpapers: Must-read Papers on pre-trained language models.
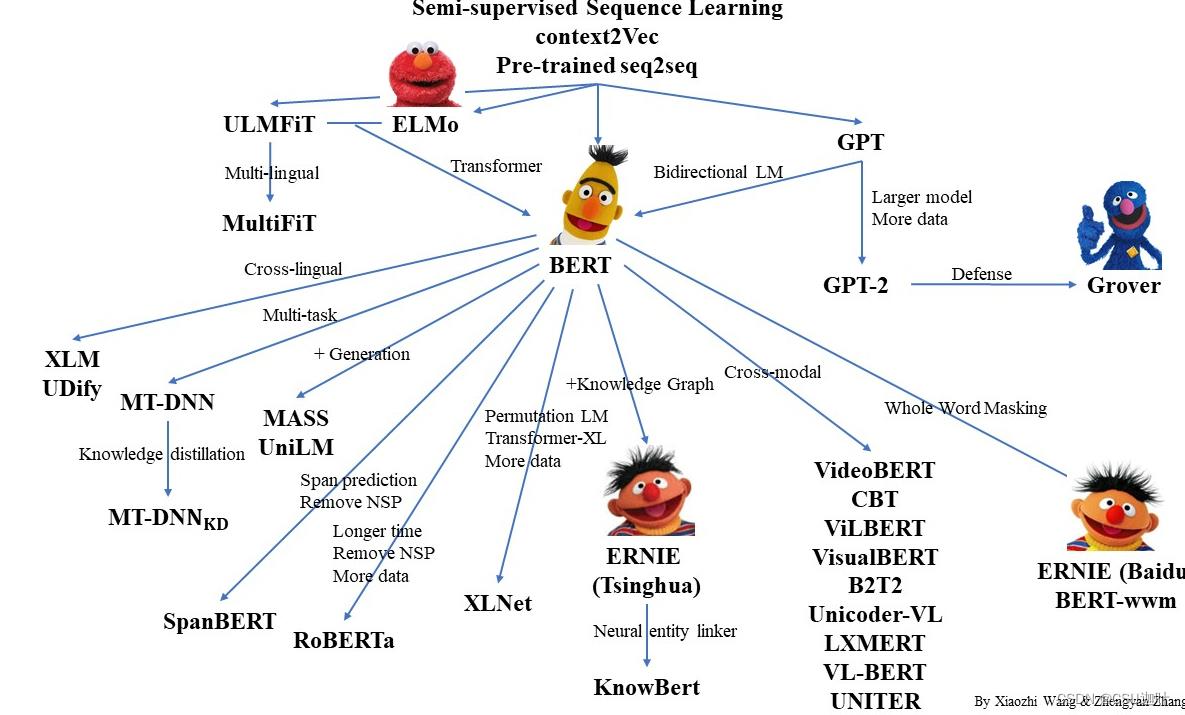
Applications of Masked LM
Masked LM在跨语言和跨模态场景下都有很多应用。
关键词:对齐(align)。
Frontiers of PLMs
GPT-3在单独的GPU上需要预训练 90 years
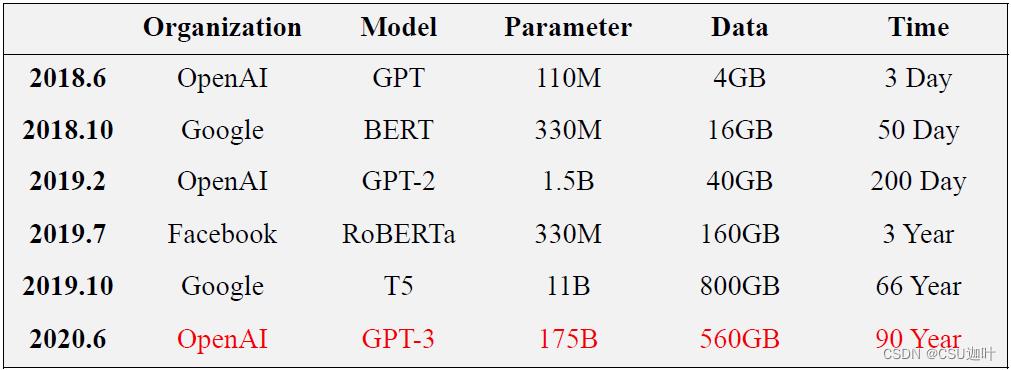
当PLM的参数量和预训练语料库的规模增大以后,观察到in-context学习的情况下few-shot的效果非常好,即不给或给很少的有监督数据(example),再加一个任务描述,模型就可以完成任务。

使用MoE(Mixture of Experts)的方式增大模型的参数。
参考
b站 刘知远团队大模型公开课 P32-35
以上是关于预训练语言模型入门的主要内容,如果未能解决你的问题,请参考以下文章