基于 Mixup 数据增强的 LSTM-FCN 时间序列分类学习记录
Posted 彭祥.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于 Mixup 数据增强的 LSTM-FCN 时间序列分类学习记录相关的知识,希望对你有一定的参考价值。
摘要
在时间序列分类任务中,针对时间序列数据少和多样性导致深度学习模型准确率不高的问题,提出 Mixup 数据增强的长短期记忆网络–全卷积网络LSTM-FCN)时间序列分类算法。该算法首先使用 Mixup对原始数据进行数据增强,通过简单的线性插值对时序数据进行混合,得到新的混合之后的增强数据;然后使用增强数据训练 LSTM-FCN,并进行分类。在 30 UCRArchive2018 数据集上的实验结果表明,使用 Mixup 数据增强的 LSTM-FCN在 26 数据集上取得了比LSTM-FCN 好的分类准确率,最高提高了 4.79%。实验结果说明了本文方法可以提高深度学习模型的分类准确率。
关于时间序列分类的相关研究:
Wang 等提出了全卷积网络(fully convolutional network,FCN)和 ResNet模型,实现了端到端的训练过程,避免了复杂的特征工程。
金海波 针对传统 Shapelets算法时间复杂度高的问题,提出一种快速发现算法,完成了算法的并行化。
张国豪等提出了一种结合卷积神经网络 (convolutional neural networks,CNN) 和双向门控循环单元(gate recurrent unit,GRU)的模型结构,用于提取时间序列数据的卷积特征和时序特征,该模型利用了2 种特征信息完成了对时序数据的分类。
胡紫音等利用注意力机制在多元时序数据中进行特征选择,解决了高维数据特征提取问题。
王会青等利用反向传播神经网络提取时间序列特征用朴素贝叶斯分类,解决了有限数据集的分类问题。
Iwana 等提出 5 种原型选择算法,并利用动态时间归(dynamic time warping,DTW)计算序列与原型之间的局部距离特征作为 CNN的输入,充分探索了局部距离特征的分类潜力。
姜逸凡等利用孪生网络衡量序列之间的相似性进行分类。
Karim 等尝试将长短时记忆网络(long short-term memory,LSTM)和全卷积网络结合提出了LSTM-FCN模型,该模型同时提取时间序列的局部特征和长期依赖关系,在多个数据集上取得了优于 FCN、ResNet 等模型的结果。
研究出发角度
上述都是在模型层面对序列分类进行优化,除此之外,我们也可以考虑其他的性能提升方法,本文便是从数据角度出发,针对许多应用中的标记数据存在局限性,例如数据量小、类别不平衡等,进而影响模型的分类性能。
初始模型:
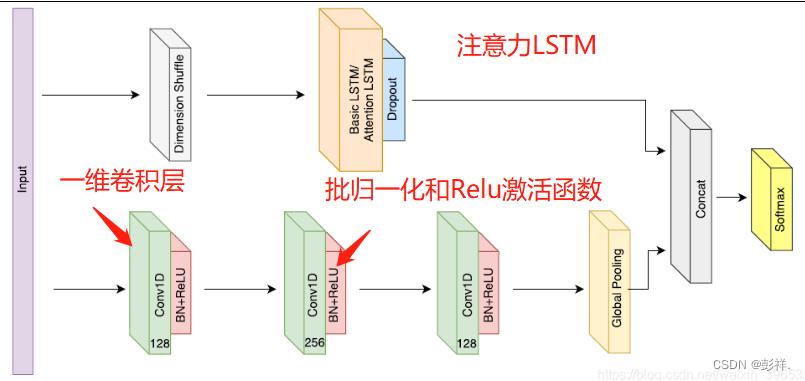
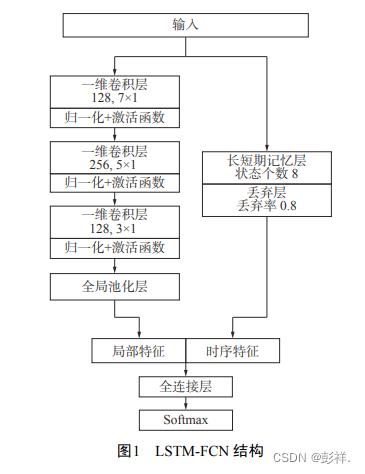
该模型由 2 个分支组成,分别为时序卷积分支和长短时记忆分支。其中,时序卷积分支采用了全卷积网络模型,该部分包含 3 个卷积块,每 一 块 都 由 一 个 一 维 卷 积 层 、 块 归 一 化 和ReLU 激活函数组成,最后一层由全局平均池化取代全连接层以减少模型参数;长短时记忆分支使用了一层 LSTM 网络,同时加入 Dropout 缓解模型的过拟合情况。最后拼接 2 个分支的输出,并使用 Softmax 对得到的特征进行分类。
多尺度卷积神经网络(MCNN),全卷积网络(FCN)和残差网络(ResNet)是利用卷积神经网络(CNN)进行端到端的深度学习方法变量时间序列的末端分类。 MCNN使用下采样,跳过采样和滑动窗口对数据进行预处理。 MCNN分类器的性能高度依赖于应用于数据集的预处理以及对该模型的大量超参数的调整。另一方面,FCN和ResNet不需要对数据或要素工程进行任何繁重的预处理。使用称为LSTM-FCN的长期短期递归神经网络(LSTM RNN)子模块或称为ALSTM-FCN的LSTM RNN扩展FCN模块来提高FCN的性能。另外,Attention LSTM也可以用于检测输入序列的区域,这些区域通过Attention LSTM单元的上下文向量对类别标签有贡献。
创新点
数据增强作为深度学习中常用的技术手段,可以通过扩充数据集提高模型性能,并在图像处理等领域得到了广泛的使用,然而类似的方法却不能很好地应用到时序数据,例如添加随机噪声、随机形变等增强方法。
Mixup是一种基于邻域风险原则的数据增强方法,该算法利用线性插值的方式对 2 个样本和标签进行混合,一定程度上扩展了训练数据的分布空间,从而使模型的泛化能力得到提高。
Mixup主要思想

实验应用


实验过程
具体来说,Mixup 在训练阶段首先对批量数据及其独热 (one-hot) 编码形式的标签进行混合 ,生成新的增强数据 ;然后将增强数据作为LSTM-FCN 的输入,训练 LSTM-FCN 并输出分类结果。训练过程中使用混合标签计算交叉熵损失而不用原始标签。混合之后的标签以概率的形式表达了样本的类别,使得模型在预测结果时得到更平滑的估计。
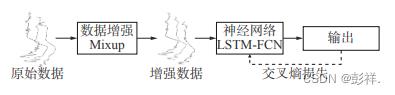
伪代码

实验环境
本文实验在 Windows10 环境下完成,CPU 为Intel® Core™ i5-8300H CPU @ 2.30 GHz,
GPU 为 NVIDIA GeForce GTX 1050 Ti,代码使用Pytorch 编写,使用分类准确(Accuracy)Raccuracy 和平均排名 (Average rank)Raverage来评估模型的性能。
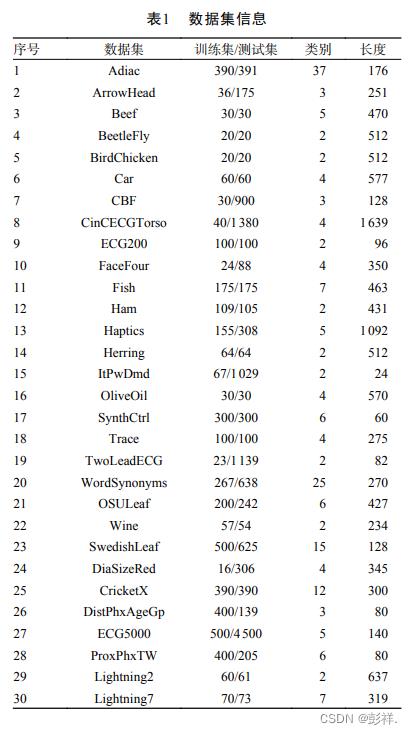
数据集
此外关于模型参数的设置,与其他增强方法的对比,在这里我便不一一赘述了,详情可自行查阅该论文。
基于 Mixup 数据增强的 LSTM-FCN 时间序列分类
以上是关于基于 Mixup 数据增强的 LSTM-FCN 时间序列分类学习记录的主要内容,如果未能解决你的问题,请参考以下文章