VLDB‘22 HiEngine极致RTO论文解读
Posted 华为云开发者联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了VLDB‘22 HiEngine极致RTO论文解读相关的知识,希望对你有一定的参考价值。
摘要:《Index Checkpoints for Instant Recovery in In-Memory Database Systems》是由华为云数据库创新Lab一作发表在数据库领域顶级会议VLDB'2022的学术论文。
本文分享自华为云社区《VLDB'22 HiEngine极致RTO论文解读》,作者:云数据库创新Lab 。
1. HiEngine简介
HiEngine是华为云自研的一款面向云原生环境的OLTP型数据库, HiEngine在标准TPC-C事务模型下, 端到端单节点(华为2488H V5机型)性能可以达到663w+的tpmC, 多节点扩展性线性度超过0.8。 其核心架构关键词如下:
- 计算,内存,存储三层分离式云原生架构
- 华为云原生的分布式内存数据库
- 同时包含分离式内存池和分离式存储池
具体HiEngine详细的技术架构和性能表现,可以参考我们团队发表在SIGMOD2022 [1]的论文工作。
2. HiEngine对日志恢复的优化
此外, HiEngine还拥有极致的RTO恢复性能,在100GB数据集下,可以达到10s级别的恢复时间。 本文将详细阐述HiEngine在追求极致RTO过程中提出的若干技术。
2.1 内存数据库的经典恢复流程
回溯学术界现有的工作, 我们可以把内存数据库的恢复大体划分为几大步骤:
- STEP1: 加载最近一次成功执行的元组检查点数据;
- STEP2: 回放检查点到故障点期间的日志数据;
- STEP3: 扫描元组数据,重建内存索引结构;
我们团队充分结合HiEngine架构的特点和学术界State of the art的一些工作, 提出了结合HiEngine Indirection array结构特点的dataless checkpoint和indexed logging恢复技术。 因此需要首先介绍一下什么是HiEngine的Indirection array。
2.2 Indirection Array
与大多数工业/学术系统一般, HiEngine内部采用多版本的方式维护Tuple元组数据, 并且Tuple并没有按页面进行组织,而是按照版本链的方式组织。 每个逻辑元组用一个全局唯一的RowID标识, 所有的RowID以一个全局的数组进行组织, 该数组我们姑且称作Indirection Array。 并且, HiEngine索引中每个叶子节点存储的是RowID而不是具体的tuple address。

Indirection Array的设计有如下几点好处:
- 更新操作不用修改索引;
- 非唯一索引可以通过添加RoWID后缀转换为唯一索引;
- 内存元组和日志记录统一编址, Indirection Array中存放的address既可以是内存元祖的头指针地址, 也可以是record对应的log record的offset地址;
- Indexed-Logging;
- Dataless Checkpoint;
下一章节我们将对Indexed logging和Dataless checkpoint展开描述。
2.3 Indexed-logging
HiEngine继承了"the log is the database"日志即数据库的概念, 具体来说Indirection Array中存放的地址既可以是内存的tuple,也可以是一个对应在内存中的log offset。 (我们使用uint64的最高一个bit标识是内存地址还是磁盘偏移。 因为对于64bit的操作系统的指针高12bit都为0)。
另一方面, 多版本系统在恢复后, 只需要恢复最新版本的数据即可, 因为旧版本的数据在系统重启后对事务不再可见。 因此, 在系统一旦故障时, HiEngine只需要并行扫描日志流, 把对应的log record的offset偏移设置到Indirection array的对应位置即可。 注意这一过程中还可以对多个日志流采用并行扫描和并行设置log offset的方式加速。
一旦系统恢复时,把最新版本的log offset设置到对应的Indirection Array的TID位置后。 HiEngine系统即可开始工作, 对于首次访问到某一TID时, 系统会加载offset位置的record, 在线生成一个新版本的tuple数据。 我们称作为bringOnline Lazily。
并且在系统运行期间, HiEngine可以识别冷Tuple数据, 对Tuple数据进行冻结并转存成log record, 同时修改对应RoWID的address为log record的offset
2.4 Dataless checkpoint
检查点执行的频率决定了需要恢复的日志量的上限, 因此为了追求尽可能快的恢复时间, 检查点执行的频度必须得高。 这就对检查点算法本身提出了更高的性能需求:(1) 单次检查点执行时间必须要快; (2) 检查点不能导致前端事务性能明显的抖动;
因为内存元组支持多版本的优势, 可以极其容易获取事务一致性的快照数据, 常规的检查点算法是获取该快照数据并对快照存盘。 但常规的方式必然导致需要存盘的快照数据量大, 进而导致checkpoint时间较长。
而HiEngine的做法不甚相同, (1) HiEngine在事务预提交阶段, 把存盘日志的offset反向回填到对应tuple数据的header中存放。 (2) 因此在Checkpoint获取事务一致性快照后, 并不是把快照中的tuple数据存盘, 而是把对应tuple header中的offset进行持久化, 并且以一个序列化的Indirection Array存盘。
总结: HiEngine这种将快照对应的log offset存盘的checkpoint方法叫做DataLess Checkpoint, 其相比于对快照进行存盘的方式, 需要序列化存盘的数据量少, 对前端事务影响的时间也更短, 恢复时加载检查点的时间也更短。
2.5 阶段性优化与遗留瓶颈
Indexed Logging和Dataless checkpoint只是解决了章节2.1提到的STEP1和STEP2的性能瓶颈, 这也是当下很多学术工作关注的优化重心。 我们通过实验对比, 在百GB规模的TPCC数据集下, 没采用Indexed logging和Dataless checkpoint技术的恢复时间在310s左右, 采用了Indexed logging和Dataless checkpoint技术后,可以把恢复时间减少到50+ s。
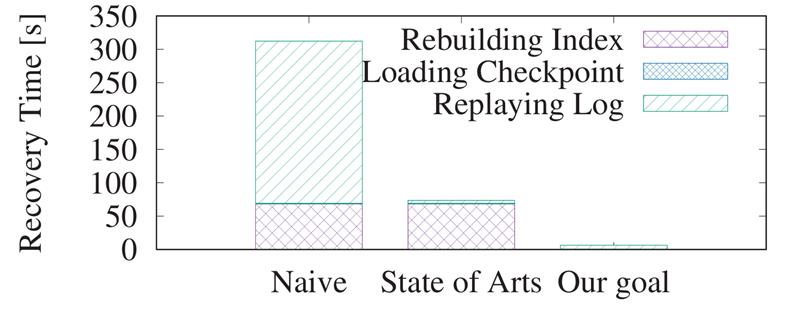
但是50+ s离HiEngine期望的目标仍有距离, 因此我们的工作重心需要聚焦到如何优化STEP3中索引重建的时间, 进一步追求极致的RTO时间目标。
3. HiEngine对索引恢复的优化
3.1 索引检查点的必要性
首先, 需要指出的是元组数据可以通过加载检查点并回放日志的方式得以恢复, 但索引数据则需要重建的方式才能得以恢复。
必要性: 主要原因在于索引并没有检查点, 如果索引也存在索引检查点数据, 索引数据的恢复也可以加载索引检查点数据, 然后通过重做insert和delete的log record恢复checkpoint之后的index索引项。
因此宏观朴素的想法是通过索引检查点对HiEngine索引重建的耗时问题进行优化。 但是:
(1) 索引本身并不支持多版本, 因此无法无阻塞的获取事务一致性的快照数据。 换句话说, 索引检查点必然是模糊Fuzzy类型的检查点。
(2) 而HiEngine的日志只有redo没有undo, 如何保证恢复出来的数据没有脏数据,并且不丢失索引项。 总之, 如何保证数据的正确性。
(3) 并且由于索引不支持快照隔离, 如何无阻塞的获取索引检查点也是一项重要的性能问题。VLDB这篇论文针对正确性和性能两个维度展开讨论HiEngine的索引检查点。
3.2 索引检查点的正确性
我们通过一个示例展示, HiEngine如何保证检查点数据的正确性。
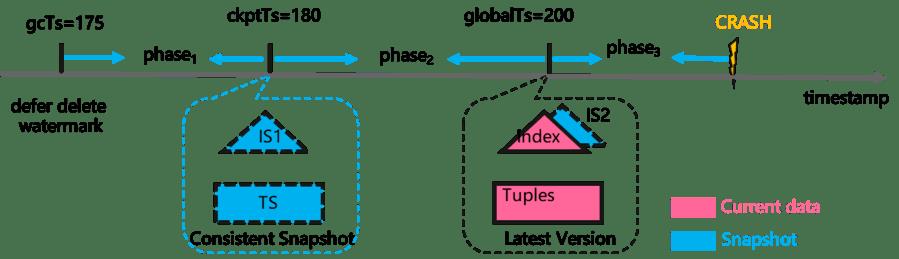
如图所示, 我们假设存在一个理想化的算法能够获取快照隔离级别并且事务一致性的索引检查点数据, 对应的元组检查点和快照检查点分别标识为TS和IS1。 此种情况数据元祖检查点和索引检查点获取的都是时间戳在180时刻的事务一致性的快照数据, 恢复后很容易保证数据的正确性。
但是现实的情况是索引只能"尝试"捕获当前触发检查点时刻的数据, 此时在索引中必然存在尚未提交事务的索引项, 因此捕获到的检查点数据必然是非事务一致的, 或者说是模糊的(Fuzzy checkpoint)。 我们用IS2标识。
对比IS1和IS2可以发现, IS2相比于IS1差异的索引项是来自于phase2阶段的操作。 前文已经说过, 因为Indirection array的设计, update操作不会修改索引, 因此我们需要针对insert和delete操作提出数据正确性保证的措施:
(1) 插入操作: 对于在phase2阶段的插入操作, 一旦系统恢复时加载检查点后, 我们应该能识别出phase2节点插入的脏数据。 因为tuple数据是可以保证事务一致性和数据正确性的。 在系统访问index时,我们需要对index和对应tuple不匹配的索引认定为"脏数据", 并触发补偿性删除动作, 同时给客户端返回不存在该索引项。
(2) 删除操作: 对于在phase2阶段删除的索引项, 因为恢复时只回放检查点之后日志, 该索引项必将在恢复后丢失lost了。 因此我们应该需要阻止phase2阶段的index删除动作的执行。 刚好, HiEngine和很多MVCC系统一样, delete当做是交给GC模块延后执行的。 我们只需要确保gc的watermark在检查点触发时滞后于checkpoint时间戳即可。也就是说 gc timestamp = minminStartTs-1, minEndTs-1。 详细可以翻阅论文。
3.3 索引检查点的性能目标
上一章节, 我们通过"恢复后识别并删除脏索引数据"和"阻止滞后gc"的方式能够保证的正确性, 但如何保证索引检查点的性能仍是一个问题。
朴素的想法是停掉前端事务并复制索引数据, 但这肯定会导致很长时间的阻塞。 因此, 我们首先给出一个优化的索引检查点算法应该满足一下4个条件:(1) Wait Free processing; (2) Efficient index operations; (3) Fast and frequent checkpoints; (4) Load friendly checkpoint file format。 具体对性能需求的描述, 可以查阅我们的论文。 并且, 我们提出了三种Index checkpoint的算法。
3.4 ChainIndex
ChainIndex通过多颗物理索引树维护一个逻辑索引, 其按照每次checkpoint产生一个新的索引树的方式产生一颗新的索引树, 索引树组织成一个链表的形式, 链表头的索引作为写入索引, 维护一个检查点周期内的增量索引树。 非链表头的索引树都作为只读结构存储。 并且ChainIndex会在后台合并若干个delta树。
检查点过程: 在每次检查点执行触发时, HiEngine首先冻结链表头的索引树, 与此同时原子性产生一个新的索引结构用于接受新启动事务的索引修改操作。 对于尚未结束的索引操作仍然写入到冻结的索引树, 待所有尚未提交的索引操作结束后, 我们采用后序遍历的方式产生一个mmap友好的checkpoint文件。
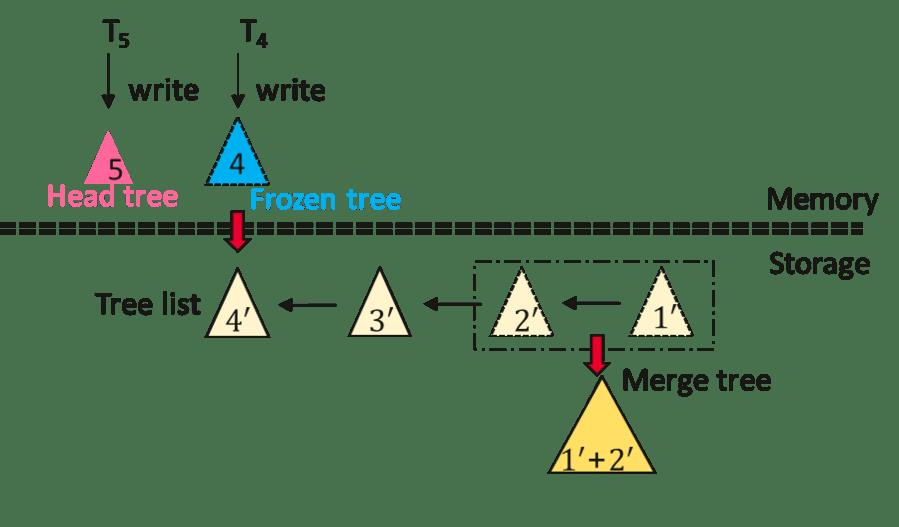
恢复过程: 每次恢复时HiEngine只需通过mmap的方式加载checkpoint文件; 然后, 回放日志恢复checkpoint之后的索引项。
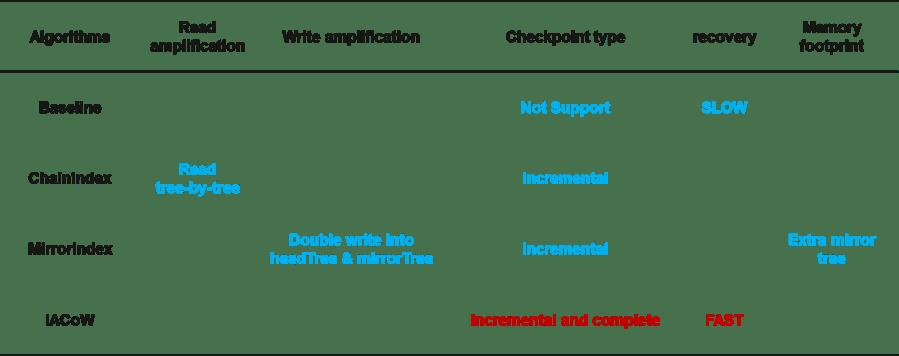
总结: ChainIndex总体架构启发来自于LSM, 对写操作友好, 但(1)存在严重的读放大问题。 (2) 并且ChainIndex只支持增量检查点,不支持全量检查点。
3.5 MirrorIndex
MirrorIndex在ChainIndex的基础上, 通过引入一个额外的full tree或者说是mirror tree, 从而解决ChainIndex的读放大缺点。 其在每一次insert或delete时, 同时对headTree和mirror tree进行修改, 可以确保headtree包含一个检查点周期的增量数据, mirror tree包含全量数据。 因此, 读操作直接访问mirror index即可。

MirrorIndex的checkpoint流程和ChainIndex一样。 但恢复流程有很大不同。 其恢复流程如下
- mmap映射增量检查点文件到内存中
- 回放日志恢复headTree的数据
- 步骤2完成后, 系统便可以接受服务了,但此时性能表现和ChainIndex类似, 有严重的读放大问题。 与此同时, HiEngine触发后台rebuild mirror index的过程, 待mirrorIndex重建完成后, 读放大问题消失
总结: MirrorIndex相比ChainIndex消除了读放大的问题, 但却(1)存在一定的读放大。 (2)并且MirrorIndex需要引入额外的树结构, 内存占用很多。 (3) MirrorIndex只支持增量检查点。(4)恢复后,有一个短暂的性能"爬坡"阶段。
3.6 Indirection Array CoW
ChainIndex和MirrorIndex总体思想都是采用delta数据的思想,维护增量检查点。 另一大类的策略是采用Copy On Write的思想, 针对树结构的CoW算法是Path Copying, 其修改拷贝节点时会导致父节点的指针发生修改, 从而导致级联修改。 这会导致性能下降很多, 并且路径拷贝会导致索引并发的lock free算法需要适配, 工作量大。

因此我们放弃了Path Copying的策略, 通过引入Indirection array的方式引入"逻辑索引节点"的概念, 从而消除级联拷贝的问题。 IACoW对每个index node分配一个唯一的node ID, 并且parent node的child pointer存放的不在是内存指针地址, 而是修改为子节点的node id, 此时修改拷贝节点时不需要修改父节点指针。

另外我们引入checkpoint epoch number来识别index node的新旧版本。 具体来说, 每次checkpoint全局epoch自动加一, 不同checkpoint周期因为copy on write产生的新版本用不同epoch number标识。 checkpoint执行流程中, 我们通过扫描Indirection array, 并根据epoch number可以捕获增量和全量两种类型的检查点数据。 恢复时, 通过mmap的方式即可恢复checkpoint数据。 具体的node版本管理, node的gc以及checkpoint数据组织形式等细节问题,可以查阅论文。
总结: IACoW同时支持增量和全量检查点, 并且IACoW引入的额外内存并不多。 但是IACoW会因为pointer chasing导致少许读放大。
4. HiEngine恢复性能评估
实验过程中, 我们首先评估checkpoint对性能抖动的影响, 结果展示MirrorIndex和IACoW在checkpoint期间性能影响并不大, 但ChainIndex由于读放大问题性能抖动严重。

同时我们测试了在相同配置下, 不同算法的恢复时间。 结果显示在异常下点时, IACoW可以保证在10s的时间内完成恢复。
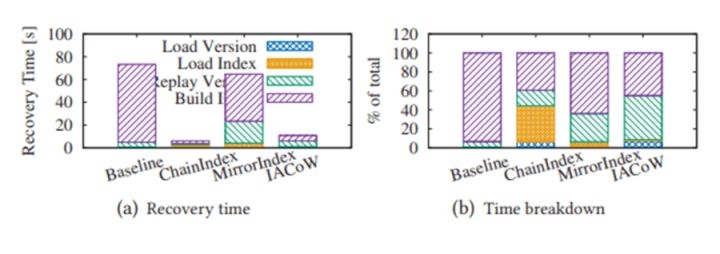
在正常下电时, IACoW可以保证在2s的时间内完成恢复。
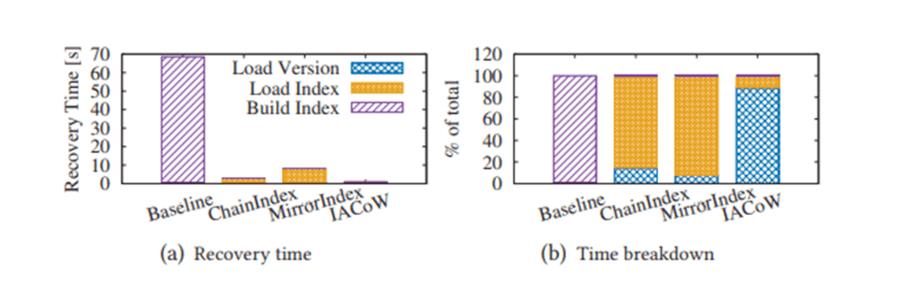
并且我们在TPC-C和microbench负载下, 实验反应MirrorIndex和IACoW对端到端性能的影响在10%以内, 但却可以换取10s级别的RTO保障。

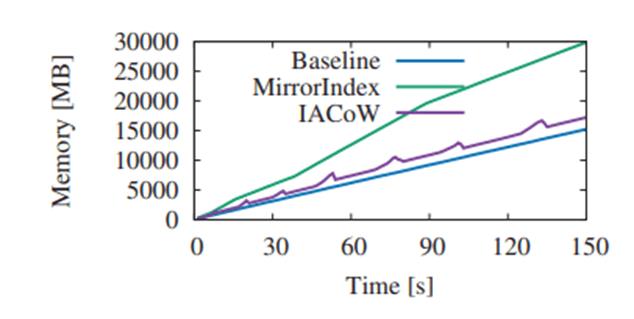
我们在控制相同事务性能的前提下, 测试各自的索引内存空间开销。 实验表明, IACoW的额外内存开销很小, 但MirrorIndex需要x2的内存开销。
我们总结对比各种方案的优缺点如下:
5. 总结
论文首先发现内存数据库的索引重建是一个性能瓶颈点, 并得到了评委们的一致认可, 摘录VLDB Reviewers对论文的选题评价。
The authors observed that, in today’s systems, the performance bottleneck in recovery is in restoring indexes. This is a cute observation which I consider important to the system community.
Overall, it is an important contribution to point out index restoration as the new performance bottleneck - I wasn’t aware of this before.
As the techniques have been improved with database recovering, this work claims that index rebuilding becomes a bottleneck of in-memory database recovering. This observation is very interesting, and it motivates the need of fast index recovering (instead of fast index reconstruction).
针对索引重建的瓶颈点, 本文探讨了索引正确性的保证,并提出了3个索引检查点算法。 最终在端到端的HiEngine系统中,对比评估了各自的优缺点。 实验结果表明, IACoW算法在100GB规模下可以达到10s级的恢复时间, 对于有极致RTO需求的场景, 可以引入该算法提速恢复。
参考文献:
[1] Yunus Ma, Siphrey Xie, Henry Zhong, Leon Lee, and King Lv. 2022. HiEngine: How to Architect a Cloud-Native Memory-Optimized Database Engine. In Proceedings of the 2022 International Conference on Management of Data (SIGMOD '22). Association for Computing Machinery, New York, NY, USA, 2177–2190. https://doi.org/10.1145/3514221.3526043
展现领先科研实力,华为云数据库创新LAB三篇论文入选国际数据库顶级会议VLDB'2022
华为云数据库创新lab官网:云数据库创新Lab-主页-华为云
We Are Hiring:云数据库创新Lab_Career_华为云 ,简历发送邮箱:xiangyu9@huawei.com
华为云数据库创新Lab 时序数据库openGemini正式开源,开源地址:https://github.com/openGemini,诚邀开源领域专家加入!
以上是关于VLDB‘22 HiEngine极致RTO论文解读的主要内容,如果未能解决你的问题,请参考以下文章
前沿 | VLDB论文解读:阿里云超大规模实时分析型数据库AnalyticDB