Elasticsearch:从零开始构建一个定制的分词器
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:从零开始构建一个定制的分词器相关的知识,希望对你有一定的参考价值。
Elasticsearch 提供了大量的 analyzer 和 tokenizer 来满足开箱即用的一般需求。 有时,我们需要通过添加新的分析器来扩展 Elasticsearch 的功能。尽管 Elastic 提供了丰富的分词器,但是在很多的时候,我们希望为自己的语言或一种特殊的需求来定制一个属于自己的分词器。通常,你可以在需要执行以下操作时创建分析器插件:
- 添加 Elasticsearch 未提供的标准 Lucene 分词器/标记器(tokenizer)。
- 集成第三方分析器。
- 添加自定义分析器。
针对中文的处理,有很多非常有名的分词器:
上述这些分词器都是开源的分词器。它们专为中文而构建的。如果你想了解更多关于分词器的使用,请参阅文章 “Elastic:开发者上手指南” 中的 “中文分词器” 章节。
在今天的文章中,我们将添加一个新的自定义英语分析器,类似于 Elasticsearch 提供的分析器。在今天的练习中,我们将以最新的 Elastic Stack 8.4.0 来构建一个定制的分词器。
安装
如果你还没有安装好自己的 Elastic Stack,请参考如下的文章来安装 Elasticsearch 及 Kibana:
- 如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
- Elastic:使用 Docker 安装 Elastic Stack 8.0 并开始使用
- Kibana:如何在 Linux,MacOS 及 Windows上安装 Elastic 栈中的 Kibana
创建插件模板
在我之前的文章
我已经展示了如何为 ingest pipeline 创建 processors。在上面的第二篇文章中,我使用了一个叫做 elasticsearch-plugin-archtype 的插件。我们可以使用如下的命令来创建一个最为基本的插件模板:
mvn archetype:generate \\
-DarchetypeGroupId=org.codelibs \\
-DarchetypeArtifactId=elasticsearch-plugin-archetype \\
-DarchetypeVersion=6.6.0 \\
-DgroupId=com.liuxg \\
-DartifactId=elasticsearch-plugin \\
-Dversion=1.0-SNAPSHOT \\
-DpluginName=analyzer 
上面已经帮我们创建了一个最为基本的插件模板。它在当前的目录下创建了一个叫做 elasticsearch-plugin 的目录。我们首先进入到该目录中:
$ pwd
/Users/liuxg/java/plugins/elasticsearch-plugin
$ tree -L 8
.
├── pom.xml
└── src
└── main
├── assemblies
│ └── plugin.xml
├── java
│ └── com
│ └── liuxg
│ ├── analyzerPlugin.java
│ └── rest
│ └── RestanalyzerAction.java
└── plugin-metadata
└── plugin-descriptor.properties由于上面的模板最初是为 REST handler 而设计的,所以,我们修改它的文档架构为如下的结构:
$ pwd
/Users/liuxg/java/plugins/elasticsearch-plugin
$ tree -L 8
.
├── pom.xml
└── src
└── main
├── assemblies
│ └── plugin.xml
├── java
│ └── com
│ └── liuxg
│ ├── index
│ │ └── analysis
│ │ └── RestanalyzerAction.java
│ └── plugin
│ └── analysis
│ └── analyzerPlugin.java
└── plugin-metadata
└── plugin-descriptor.properties上面是它的文件结构。因为我们想为 Elastic Stack 8.4.0 构建插件,所以,我们必须在 pom.xml 中修改相应的版本信息:
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<name>elasticsearch-plugin</name>
<modelVersion>4.0.0</modelVersion>
<groupId>com.liuxg</groupId>
<artifactId>elasticsearch-plugin</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<description>elasticsearch analyzer plugin</description>
<inceptionYear>2019</inceptionYear>
<licenses>
<license>
<name>The Apache Software License, Version 2.0</name>
<url>http://www.apache.org/licenses/LICENSE-2.0.txt</url>
<distribution>repo</distribution>
</license>
</licenses>
<properties>
<elasticsearch.version>8.4.0</elasticsearch.version>
<elasticsearch.plugin.classname>com.liuxg.analyzerPlugin</elasticsearch.plugin.classname>
<log4j.version>2.11.1</log4j.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>$maven.compiler.source</source>
<target>$maven.compiler.target</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.1</version>
<configuration>
<includes>
<include>**/*Tests.java</include>
</includes>
</configuration>
</plugin>
<plugin>
<artifactId>maven-source-plugin</artifactId>
<version>3.0.1</version>
<executions>
<execution>
<id>attach-sources</id>
<goals>
<goal>jar</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<outputDirectory>$project.build.directory/releases/</outputDirectory>
<descriptors>
<descriptor>$basedir/src/main/assemblies/plugin.xml</descriptor>
</descriptors>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>$elasticsearch.version</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>$log4j.version</version>
<scope>provided</scope>
</dependency>
</dependencies>
</project>在上面,我们把 elasticsearch.version 设置为 8.4.0。其它的保持不变。
接下来,我们来修改 analyzerPlugin.java 文件:
analyzerPlugin.java
package com.liuxg.plugin.analysis;
import org.elasticsearch.plugins.Plugin;
import org.apache.lucene.analysis.Analyzer;
import org.elasticsearch.index.analysis.AnalyzerProvider;
import com.liuxg.index.analysis.CustomEnglishAnalyzerProvider;
import org.elasticsearch.indices.analysis.AnalysisModule;
import java.util.HashMap;
import java.util.Map;
public class analyzerPlugin extends Plugin implements org.elasticsearch.plugins.AnalysisPlugin
@Override
public Map<String, AnalysisModule.AnalysisProvider<AnalyzerProvider<? extends Analyzer>>> getAnalyzers()
Map<String, AnalysisModule.AnalysisProvider<AnalyzerProvider<? extends Analyzer>>> analyzers = new HashMap<>();
analyzers.put(CustomEnglishAnalyzerProvider.NAME, CustomEnglishAnalyzerProvider::getCustomEnglishAnalyzerProvider);
return analyzers;
在上面的代码中,我们在插件中注册我们的分词器。
我们接下来修改上面的文件 RestanalyzerAction.java 为 CustomEnglishAnalyzerProvider.java:
CustomEnglishAnalyzerProvider.java
package com.liuxg.index.analysis;
import org.apache.lucene.analysis.en.EnglishAnalyzer;
import org.apache.lucene.analysis.CharArraySet;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.env.Environment;
import org.elasticsearch.index.IndexSettings;
import org.elasticsearch.index.analysis.AbstractIndexAnalyzerProvider;
import org.elasticsearch.index.analysis.Analysis;
public class CustomEnglishAnalyzerProvider extends AbstractIndexAnalyzerProvider<EnglishAnalyzer>
public static String NAME = "custom_english";
private final EnglishAnalyzer analyzer;
public CustomEnglishAnalyzerProvider(IndexSettings indexSettings, Environment env, String name, Settings settings,
boolean ignoreCase)
super(name, settings);
analyzer = new EnglishAnalyzer(
Analysis.parseStopWords(env, settings, null, ignoreCase),
Analysis.parseStemExclusion(settings, CharArraySet.EMPTY_SET));
public static CustomEnglishAnalyzerProvider getCustomEnglishAnalyzerProvider(IndexSettings indexSettings,
Environment env, String name,
Settings settings)
return new CustomEnglishAnalyzerProvider(indexSettings, env, name, settings, true);
@Override
public EnglishAnalyzer get()
return this.analyzer;
请注意,在上面,我们定义了分词器的名字为 custom_english。为了区分正常的 english 分词器,我们在实例化 analyzer 时,特意把它的 stop words 设置为 null:
analyzer = new EnglishAnalyzer(
Analysis.parseStopWords(env, settings, null, ignoreCase),
Analysis.parseStemExclusion(settings, CharArraySet.EMPTY_SET));正常的 english 分词器为:
analyzer = new EnglishAnalyzer(
Analysis.parseStopWords(env, settings, EnglishAnalyzer.getDefaultStopSet(), ignoreCase),
Analysis.parseStemExclusion(settings, CharArraySet.EMPTY_SET));也就是说我们定制的 cusom_english 分词器是没有任何 stop words 的。
经过这样的修改,我们的文件架构变为:
$ pwd
/Users/liuxg/java/plugins/elasticsearch-plugin
$ tree -L 8
.
├── pom.xml
└── src
└── main
├── assemblies
│ └── plugin.xml
├── java
│ └── com
│ └── liuxg
│ ├── index
│ │ └── analysis
│ │ └── CustomEnglishAnalyzerProvider.java
│ └── plugin
│ └── analysis
│ └── analyzerPlugin.java
└── plugin-metadata
└── plugin-descriptor.properties由于我们已经修改了文件的架构,我们需要重新修改 pom.xml 的如下的这个部分:
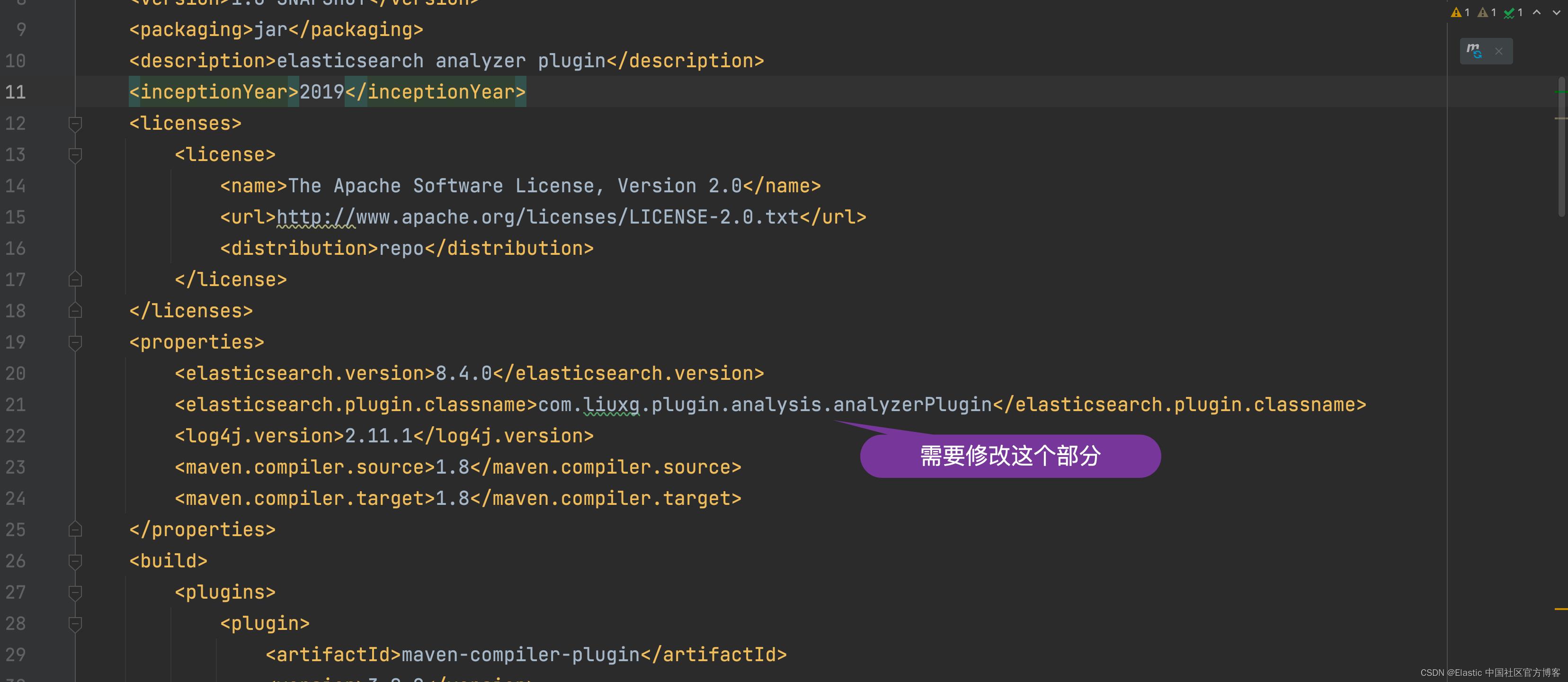
编译
我们在项目的根目录下使人如下的命令来进行编译:
mvn clean install$ pwd
/Users/liuxg/java/plugins/elasticsearch-plugin
$ mvn clean install
[INFO] Scanning for projects...
[INFO]
[INFO] -------------------< com.liuxg:elasticsearch-plugin >-------------------
[INFO] Building elasticsearch-plugin 1.0-SNAPSHOT
[INFO] --------------------------------[ jar ]---------------------------------
[INFO]
[INFO] --- maven-clean-plugin:2.5:clean (default-clean) @ elasticsearch-plugin ---
[INFO]
[INFO] --- maven-resources-plugin:2.6:resources (default-resources) @ elasticsearch-plugin ---
[WARNING] Using platform encoding (UTF-8 actually) to copy filtered resources, i.e. build is platform dependent!
[INFO] skip non existing resourceDirectory /Users/liuxg/java/plugins/elasticsearch-plugin/src/main/resources
[INFO]
[INFO] --- maven-compiler-plugin:3.8.0:compile (default-compile) @ elasticsearch-plugin ---
[INFO] Changes detected - recompiling the module!
[INFO] Compiling 2 source files to /Users/liuxg/java/plugins/elasticsearch-plugin/target/classes
[INFO]
[INFO] --- maven-resources-plugin:2.6:testResources (default-testResources) @ elasticsearch-plugin ---
[WARNING] Using platform encoding (UTF-8 actually) to copy filtered resources, i.e. build is platform dependent!
[INFO] skip non existing resourceDirectory /Users/liuxg/java/plugins/elasticsearch-plugin/src/test/resources
[INFO]
[INFO] --- maven-compiler-plugin:3.8.0:testCompile (default-testCompile) @ elasticsearch-plugin ---
[INFO] No sources to compile
[INFO]
[INFO] --- maven-surefire-plugin:2.22.1:test (default-test) @ elasticsearch-plugin ---
[INFO] No tests to run.
[INFO]
[INFO] --- maven-jar-plugin:2.4:jar (default-jar) @ elasticsearch-plugin ---
[INFO] Building jar: /Users/liuxg/java/plugins/elasticsearch-plugin/target/elasticsearch-plugin-1.0-SNAPSHOT.jar
[INFO]
[INFO] >>> maven-source-plugin:3.0.1:jar (attach-sources) > generate-sources @ elasticsearch-plugin >>>
[INFO]
[INFO] <<< maven-source-plugin:3.0.1:jar (attach-sources) < generate-sources @ elasticsearch-plugin <<<
[INFO]
[INFO]
[INFO] --- maven-source-plugin:3.0.1:jar (attach-sources) @ elasticsearch-plugin ---
[INFO] Building jar: /Users/liuxg/java/plugins/elasticsearch-plugin/target/elasticsearch-plugin-1.0-SNAPSHOT-sources.jar
[INFO]
[INFO] --- maven-assembly-plugin:3.1.0:single (default) @ elasticsearch-plugin ---
[INFO] Reading assembly descriptor: /Users/liuxg/java/plugins/elasticsearch-plugin/src/main/assemblies/plugin.xml
[WARNING] The following patterns were never triggered in this artifact exclusion filter:
o 'org.elasticsearch:elasticsearch'
[INFO] Building zip: /Users/liuxg/java/plugins/elasticsearch-plugin/target/releases/elasticsearch-plugin-1.0-SNAPSHOT.zip
[INFO]
[INFO] --- maven-install-plugin:2.4:install (default-install) @ elasticsearch-plugin ---
[INFO] Installing /Users/liuxg/java/plugins/elasticsearch-plugin/target/elasticsearch-plugin-1.0-SNAPSHOT.jar to /Users/liuxg/.m2/repository/com/liuxg/elasticsearch-plugin/1.0-SNAPSHOT/elasticsearch-plugin-1.0-SNAPSHOT.jar
[INFO] Installing /Users/liuxg/java/plugins/elasticsearch-plugin/pom.xml to /Users/liuxg/.m2/repository/com/liuxg/elasticsearch-plugin/1.0-SNAPSHOT/elasticsearch-plugin-1.0-SNAPSHOT.pom
[INFO] Installing /Users/liuxg/java/plugins/elasticsearch-plugin/target/elasticsearch-plugin-1.0-SNAPSHOT-sources.jar to /Users/liuxg/.m2/repository/com/liuxg/elasticsearch-plugin/1.0-SNAPSHOT/elasticsearch-plugin-1.0-SNAPSHOT-sources.jar
[INFO] Installing /Users/liuxg/java/plugins/elasticsearch-plugin/target/releases/elasticsearch-plugin-1.0-SNAPSHOT.zip to /Users/liuxg/.m2/repository/com/liuxg/elasticsearch-plugin/1.0-SNAPSHOT/elasticsearch-plugin-1.0-SNAPSHOT.zip
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 5.266 s
[INFO] Finished at: 2022-09-07T13:54:06+08:00
[INFO] ------------------------------------------------------------------------编译成功后,我们可以在 target 目录先看到如下的安装文件:
$ pwd
/Users/liuxg/java/plugins/elasticsearch-plugin
$ ls target/releases/
elasticsearch-plugin-1.0-SNAPSHOT.zip上面显示的 elasticsearch-plugin-1.0-SNAPSHOT.zip 就是我们可以安装的插件文件。
安装插件并测试插件
我们接下来换到 Elasticsearch 的安装目录下,并打入如下的命令:
$ pwd
/Users/liuxg/elastic0/elasticsearch-8.4.0
$ bin/elasticsearch-plugin install file:Users/liuxg/java/plugins/elasticsearch-plugin/target/releases/elasticsearch-plugin-1.0-SNAPSHOT.zip
-> Installing file:Users/liuxg/java/plugins/elasticsearch-plugin/target/releases/elasticsearch-plugin-1.0-SNAPSHOT.zip
-> Downloading file:Users/liuxg/java/plugins/elasticsearch-plugin/target/releases/elasticsearch-plugin-1.0-SNAPSHOT.zip
[=================================================] 100%
-> Installed analyzer
-> Please restart Elasticsearch to activate any plugins installed
$ ./bin/elasticsearch-plugin list
analyzer从上面的显示中,我们可以看出来 analyzer 插件已经被成功地安装。我们接下来需要重新启动 Elasticsearch。这个非常重要!
我们打开 Kibana,并打入如下的命令:
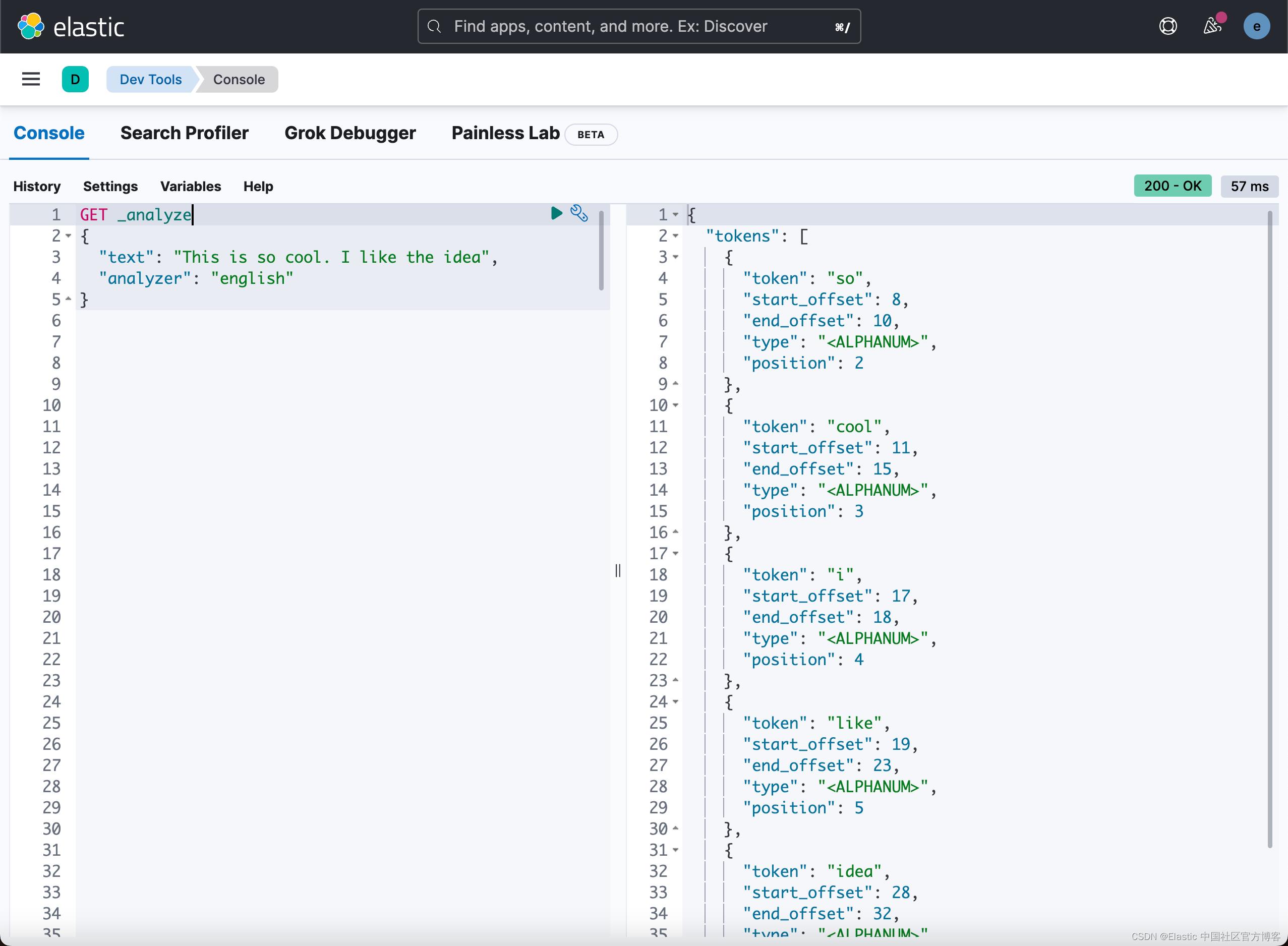
在正常的情况下,我们使用命令:
GET _analyze
"text": "This is so cool. I like the idea",
"analyzer": "english"
在上面,我们使用了 english 分词器。它将返回上面的结果。从上面我们可以看出来,this, is, the 都是 stop words。它们都不在返回的 token 之列。
我们可以使用如下的命令来调用我们刚才所生产的 custom_english 分词器:
GET _analyze
"text": "This is so cool. I like the idea",
"analyzer": "custom_english"
在上面,我们使用了我们刚才创建的 custom_english 分词器,它返回的结果如下:
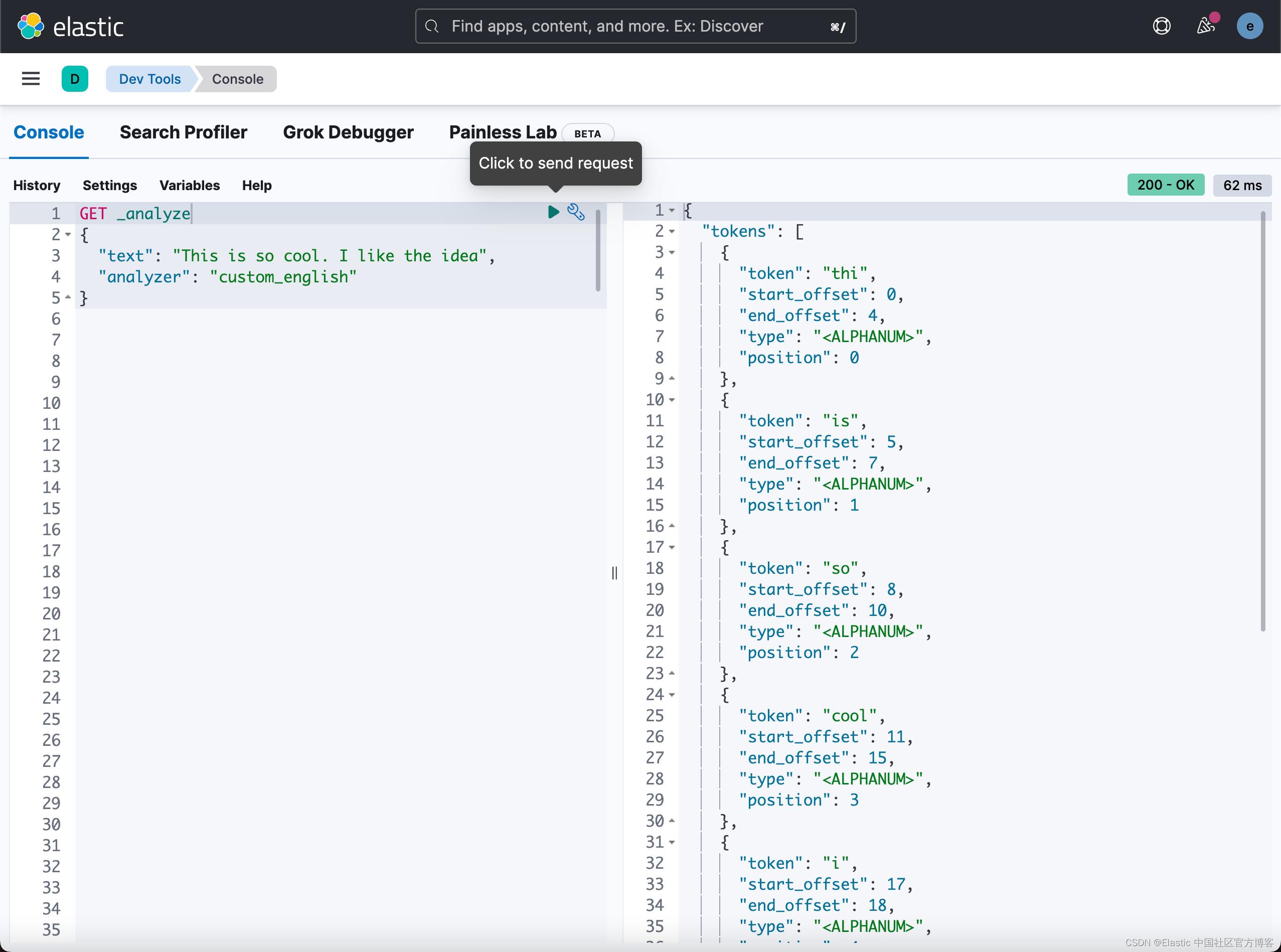
从上面,我们可以看出来 is,the, 及 thi 都变成了 token,这个是因为在我们定制的分词器中,我们没有设置 stop words 的缘故。虽然这个在实际的使用中并没有多大的用处,但是它显示了我们定制的分词器是可以工作的。
整个代码可以在地址 GitHub - liu-xiao-guo/analyzer_plugin 下载。
以上是关于Elasticsearch:从零开始构建一个定制的分词器的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch:从零开始创建一个 REST handler 插件
Elasticsearch:从零开始创建一个 ingest pipeline 处理器
Elasticsearch:从零开始到搜索 - 使用 Elasticsearch 摄取管道玩转你的数据