AI时代的视频云转码移动端化——更快更好,更低,更广
Posted LiveVideoStack_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI时代的视频云转码移动端化——更快更好,更低,更广相关的知识,希望对你有一定的参考价值。
编者按: AI技术的落地是渐渐地从服务器端、云端落地,逐步到移动端及边缘设备上。这些年随着AI技术的进步,轻量级算法模型开始在移动端实时跑起来,并且移动端算法也在不断进行迭代和完善,而对于实时直播场景,也有越来越多的AI算法落地。ZEGO即构科技提出了一套极轻量级AI算法模型,结合移动端硬件特性,差异化优化前馈推理库,让算法模型、推理库、硬件成为一体,使得视频云转码移动端化成为可能。LiveVideoStackCon 2022音视频技术大会上海站邀请到了即构科技的李凯老师,为我们分享产品架构、移动端视频转码、移动端智能视频处理、四位一体网络模型设计以及具体实施Demo。
文/李凯
整理/LiveVideoStack

这是我第二次在LiveVideoStackCon分享,第一次时本人肚子还没有这么大,疫情三年肚子长大了,但我们的模型会变得越来越小、越来越快、效果越来越好,这就是“更快、更好、更低、更广”。
快 —— 速度越来越快,好 —— 效果越来越好,低 —— 耗费很低的码率,广 —— 尽可能覆盖更多的机型。曾经在云端转码遇到大批量的任务,本次探讨在移动端如何处理,分享内容更侧重在移动端如何把任务快速跑起来,把服务器端的事情放在手机端做,对 ToB 厂商的用户来说是非常开心的。

本次分享按以下方向逐一展开:一是 ZEGO 产品概貌;二是要在移动端去做的理由,这是帮助解决客户提出的需求问题;三是在移动端可以做到哪种程度,能不能面对用户提出的苛刻需求,解决客户问题;四是如何解决行业内难题,这是任何一个做音视频厂商、做视频前后处理都孜孜不倦追求的问题;五是简单实验结果分享。
1、产品架构
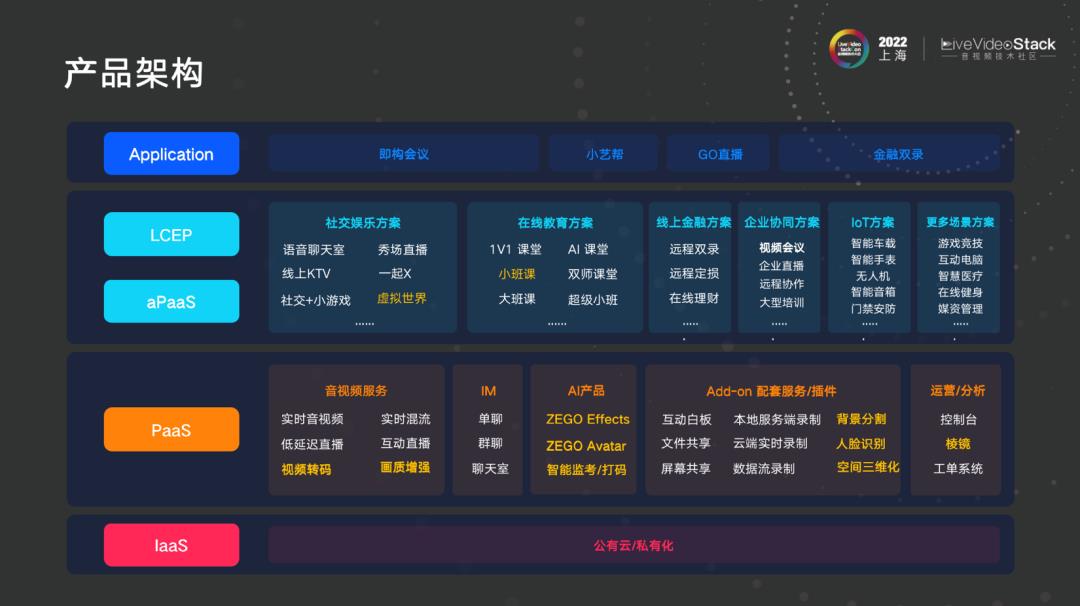
产品应用方面,会议端的小艺帮主要针对考试类的应用;直播类有游戏直播,KTV唱歌等;方案有社交娱乐、泛娱乐、以及这几年很火的在线教育。目前也会给小艺帮考试类的做应用,不限于在线教育的方案。我们同时会提供基础技术服务,比如视频转码、画质增强、美颜特效、Avatar 元宇宙底层技术、背景分割等。
1.1视频处理
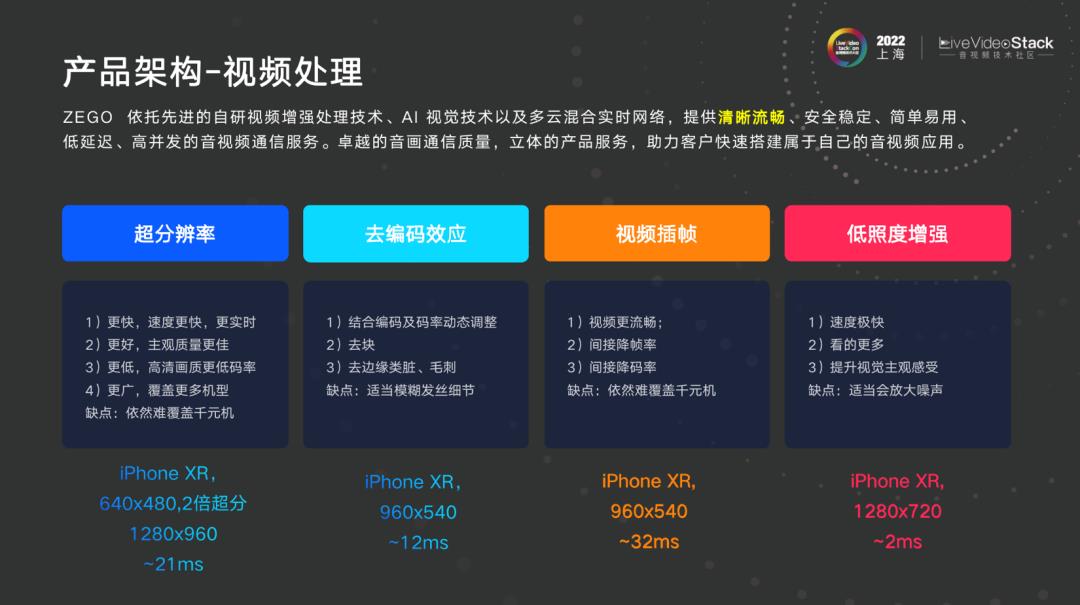
本次分享的重点是视频处理。上图是我们很直观的数据。
在 iPhoneXR 这样的中端机型上,超分辨率 640*480 两倍率做 AI 超分到 1280*960,21ms 可以搞定。同时也测试了安卓机型,大概可以覆盖 2500 款,1000 元以上机型基本能够覆盖。如果机型好一点,超分到 1080p 没有问题,但国家政策鼓励出海去东南亚、印度、非洲。这些国家市场非常大,但最大的现状为使用者大多为千元机以下,这就面临一个很大的难题,千元机难做超分。
去编码速度比超分速度快很多,超分天然的数据量很大,不能把图片缩小,将图片原始分辨率不做改动的情况下放大。去编码效应的优势在原始分辨率上做,处理速度比超分快很多,基本可覆盖千元机。而在印度、东南亚、非洲这些带宽很低的地方,这时做去编码效应比超分,更具实际价值。
最难的点是视频插帧,两帧插一帧,基础数据是在 IPhoneXR 上 960*540,32ms,这一部分依然面临难覆盖千元机,也是我们一直去追求的点,后续可以演示插帧在移动端上手机具体效果。
随后也会与大家分享如何实现低照度增强,大家也可以跟着这个思路复现低照度增强,速度可以覆盖到 2ms,很低端的机型例如 2015 年的机型小米2S,2ms 可以实现。道理很简单,就是 3D或 2D 查找表,非常快,效果在最后一部分演示。但低照度会有个问题,这也是业界难题,在极度暗的情况下出现噪点放大。那我们为什么走低照度增强?
给大家讲个小故事,我们有一个东南亚客户之前提出需求,“需要 1280*720 的分辨率,要求 30 帧率不能下降、灯全关掉、手机屏幕亮度调到最低,但对方可以清晰看到我的脸”。在与客户沟通时,问能不能把屏幕亮度调亮一点点,对方不乐意,他就需要这个效果,但我们努力帮助其解决问题他还是很开心的,虽然不能否认会给他带来噪点问题,但亮度调高一点点,噪点问题将被适度放大。如果使用长曝光 1280*720,帧率很低,长曝光只能 10 帧,用户做很多动作想要 30 帧,也会不开心。
1.2其他AI技术产品

技术人员要经常与销售打交道,面对一线用户,技术人员就能了解是否要解决此问题,知道需求在哪儿,做的技术有无价值。当然我们也会做其他的应用。一是抠图,其中有隐私反向打码,例如小米摄像头监控功能,老人在家监控但不放心,就可以把老人反向打码,将老人虚化而背景不虚化,或只虚化老人身体的一部分,反向抠图,关键看你怎么去做去用。二是小目标检测,曾经有用户给一个条件:小分辨率在 640*360,只有 10 像素的手机,考场监控场景下,看拿手机作弊的小动作能否被检测出。这样的难题是实际中碰到过的很多基础应用。
2、移动端视频转码

第二部分是移动端视频转码。
2.1 移动端转码
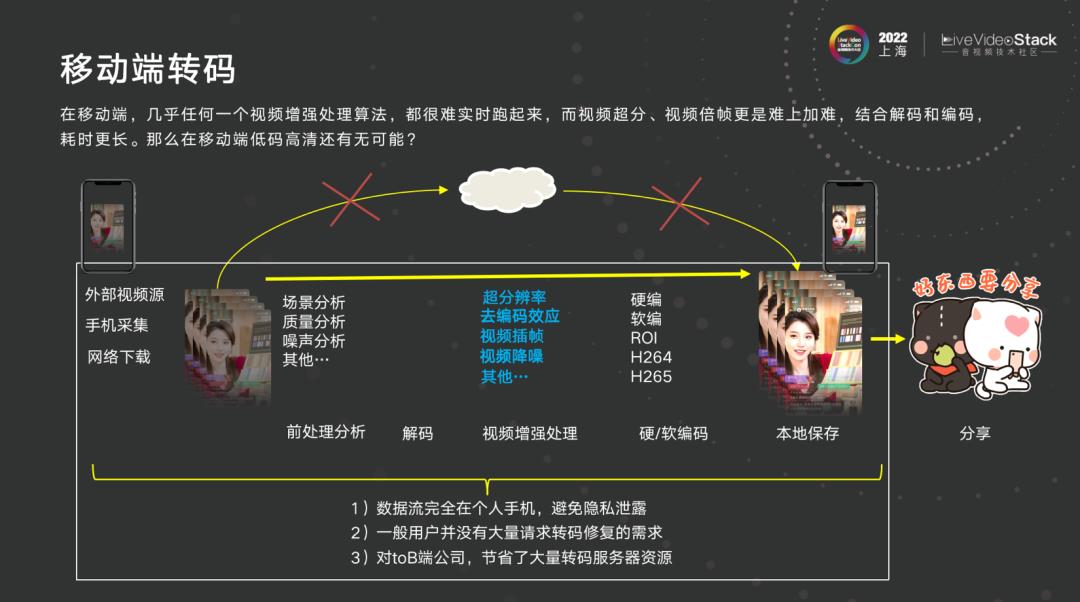
关于移动端视频转码,也有一个来自于真实用户提出的需求:为什么要将视频上传至云服务,云服务下载后又要转一遍,用户自己拍的视频或是转的视频不愿意上传至服务器,那么移动端是否能将视频修复呢?
视频修复需要做很多任务,首先要从云转码角度分析是什么场景下的视频,游戏、体育或是日常生活,质量如何、块的效应如何、编码状态如何。一个视频块很多,但也许是录屏的,初步分析后考虑是否要做超分、做编码块效应、做降噪,那这一整套能不能在手机端做到?用户提出此问题后,如果可以解决用户就愿意付费,但用户不想放在云端,ToB 公司不乐意放在云端为单个服务器付费,在用户的手机将事情落地对于 ToB 公司来说是乐意付费的。所以我们很多的技术实现都是源自于具体生活。到底能不能实现,实现到什么程度,后面会分享具体一些数据,看能否支撑能否做到。
2.2 移动端 AI 技术性能一览
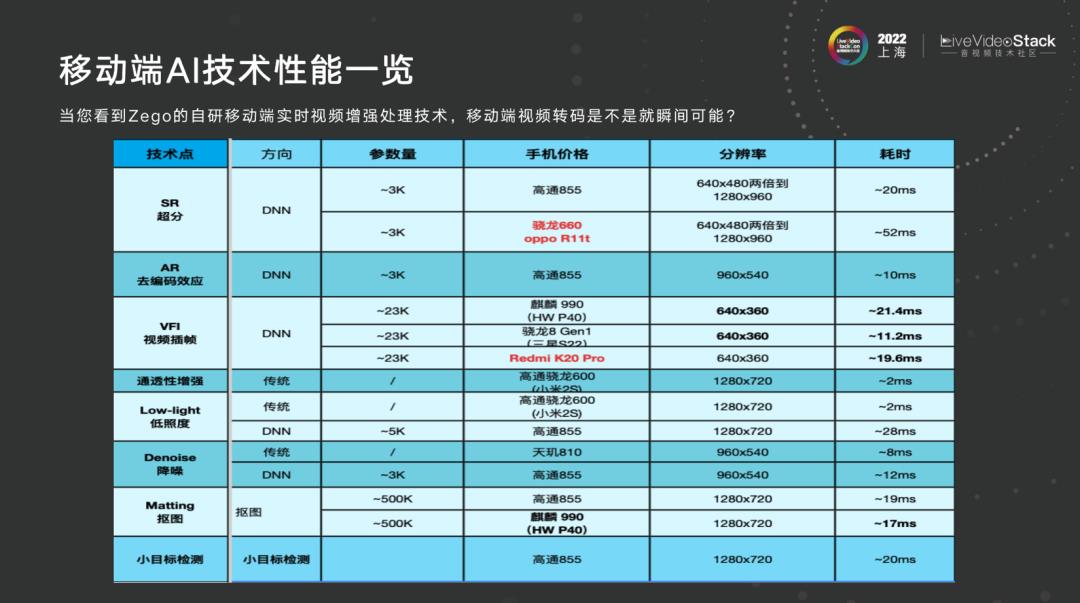
在上图的超分性能数据中可以看到,我们可以覆盖 2500 款机型,业界能敢喊出这个数字的不多,这是公开的,能给到厂商实测。最难的是移动端实时视频插帧,需要解决人物不扭曲、大运动不虚、字幕不花等场景,并且机型覆盖程度仍在努力中,不会停下脚步。刚才提到的低照度增强,提升通道通透性指的是视频进入编码之后,会有朦朦一层,没有深度参差,将其处理,使之纵深变强,立体感更强,而不是像有一层雾,当然也可以用去雾通道处理此问题。在降噪方面,我们本身也在做各种优化。抠图和小目标检测在前文中也有提到,我们主要做安卓端,ios 端有 MPU 和 ANE 会好做很多。
3、移动端智能视频处理

第三部分是移动端智能视频处理。
3.1 全链路自研可控
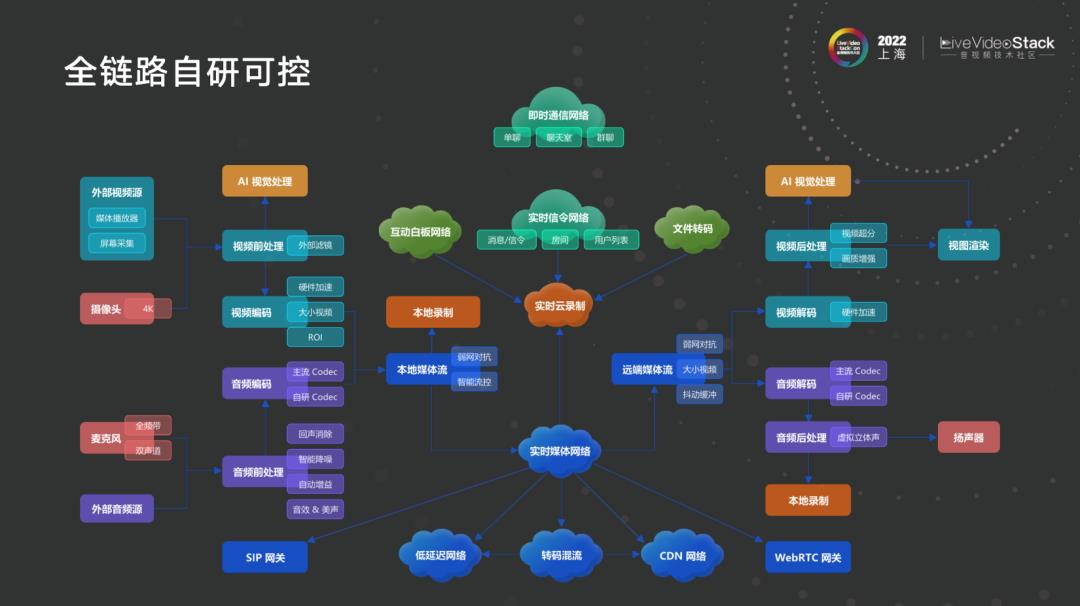
上图中是我们公司大型团队端到端做的事情。我所负责的是与视频相关的业务,包括视频前后处理部分、麦克风采集、涉及端到端的网络,以及部分编解码。我相信这个流程每个做 RTC 的技术人员都能画得出,搞技术的即使是做视频前处理也要会画,这是整个公司每个同事负责盯在哪一块的概貌。
3.2 移动端视频处理
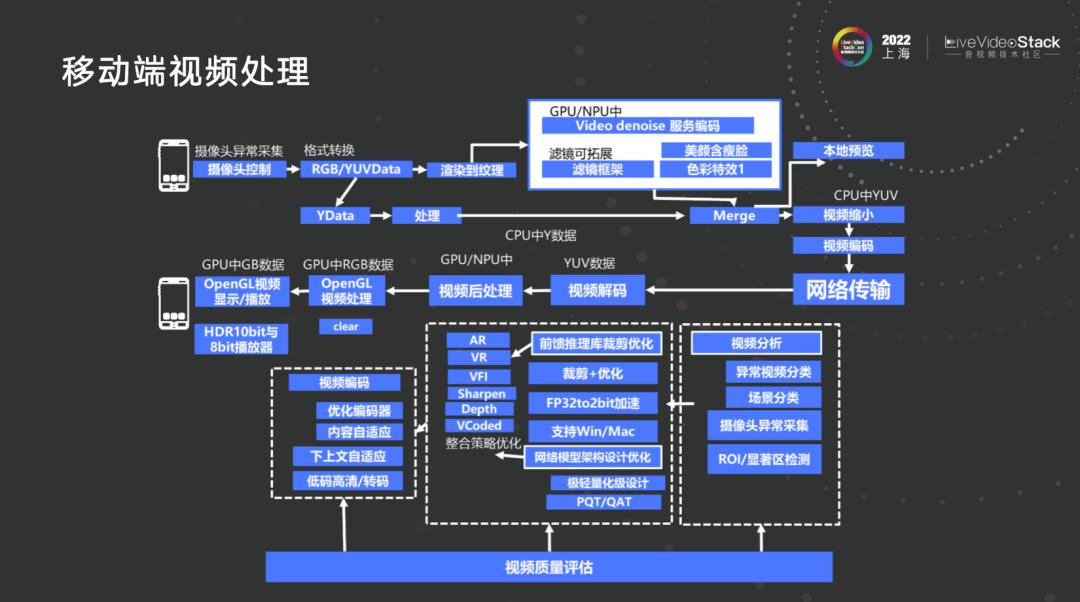
上图是本人整个职业生涯所要做的事情,当然也不仅仅只有这些。现在也做关于教育的东西,技术是相通的,整个数据流是这样走的,核心重点还是在视频后处理或视频前处理上,包括前端推理库的优化,后续会讲到前端推理库的一部分优化和网络模型如何设计得更加小型化。
3.3 移动端超分辨率

再看一下移动端超分辨率具体技术细节。
- 超分辨率-性能PK

超分是我们去年上半年做的事情,与行业内进行 PK,在上图数据上做测试,越向左模型越小越好,越往上效果越好,左下角都是一些小模型的效果。上图中PAN 在2020年模型参数量最小,效果排第二。RFDN 在 2020 年效果第一,与之作初步对比,大模型的位置如图,但实际覆盖大概 2500 款机型使用不同的模型。
- 超分辨率网络模型-设计
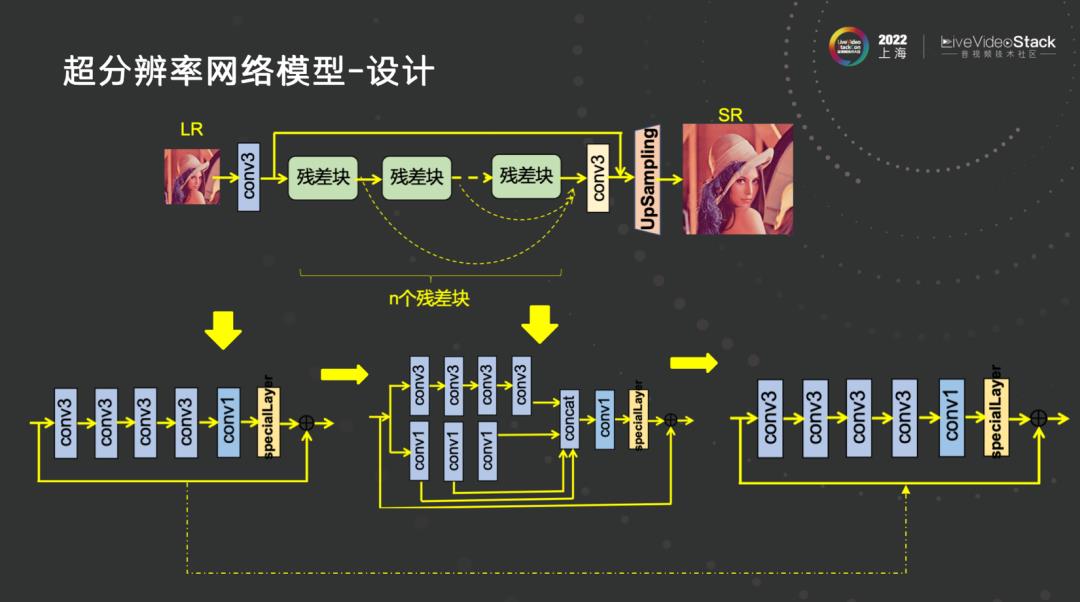
上图是超分很简单的网络模型设计,期初花了很多心思精力阅读大量文章加上自己的奇思妙想、胡思乱想,我们做了一些通道处的处理,包括通道注意力机制,但最终发现流程越多,模型加速可能性越低。后来回到初衷,原始设计出来的模型,最后还是这样的,这样做加速会非常容易。如果模型效果好但没法加速也不行,结构比较复杂。这一部分我们也发了一篇文章,影响因子5.9(https://doi.org/10.1016/j.neucom.2022.07.050)。模型怎么训练,其中就有一些弯弯绕绕,涉及到后续会统一提到的技术点。
3.4 移动端低照度

- 低照度设计
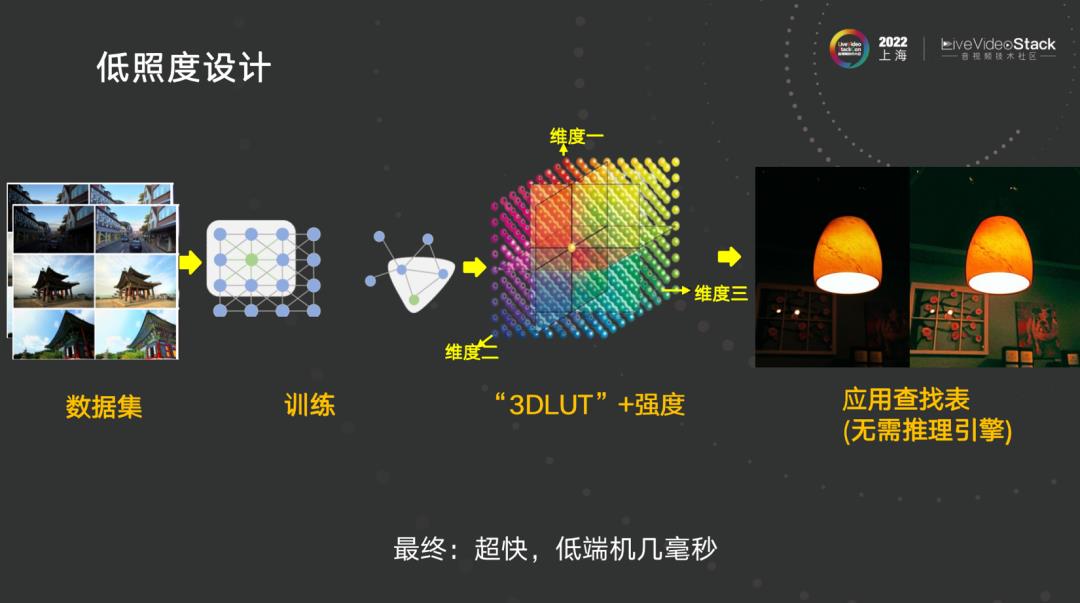
低照度方面,第一版是用 2D 查找表方式,发现其维度不够,后改用 3D 查找表,用网络模型训练得到查找表本身,而不是模型,后续将推理库丢掉,只要进来数据,有三个维度分别是图像输入的原始像素点、当前像素点周围邻域的均值、根据自己定义例如当前像素点Y通道的亮度与周边像素点亮度差异值,在 0-1 之间。将其变成 0-255,此表最大为 255*255*255,最终结果是几毫秒。
- 网络模型-设计指导方向
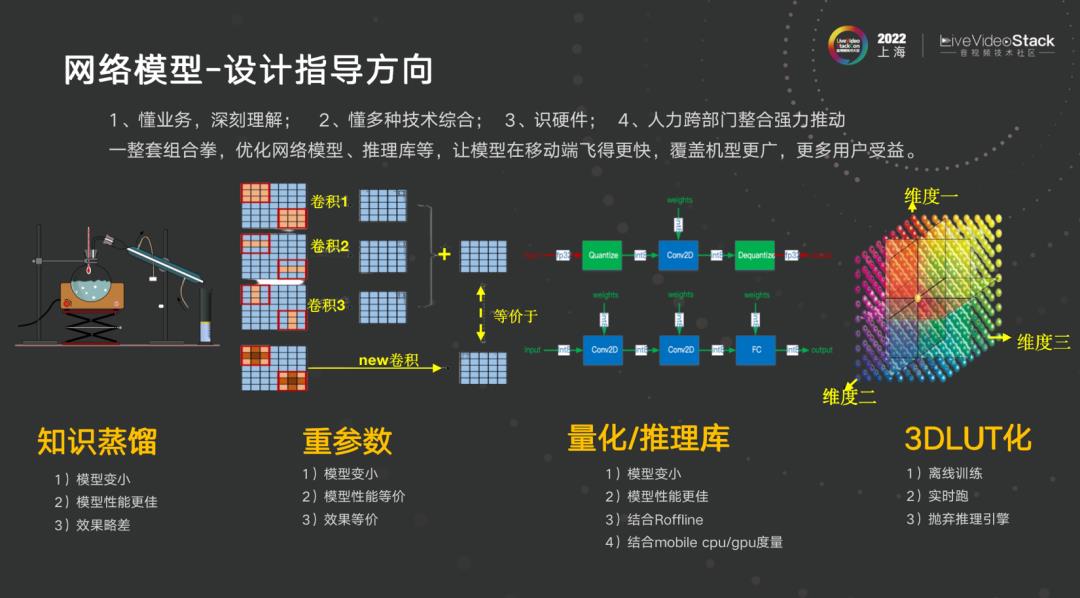
回到视频超分辨率的问题,如何将视频超分辨率模型变小,可以做知识蒸馏;重参数,这在最近几年很火,我们用在很多领域,还会放在目标检测中,美团的 YOLOv6 就用了重参数、台湾的YOLOv7 同样使用重参数,重参数同样变成了在 CV 基础业务领域的骨干网络,重参数的意思是训练中模型非常大,推理模型非常小,但训练模型和推理模型是等价的,最终效果一样,推理速度更快,依据这个可以看更多的论文。
还有就是做量化 PQT 和 QAT,训练前和训练后量化会带来不同效果,后续会提到一个模型的设计是否可以转换成量化,是否适合,精度是否下降,模型本身与推理库是否紧密耦合,模型在硬件上借助推理库能否达到最佳,这是个考验人的事情。对所有底层计算机视觉视频增强任务大部分可以用查找表来做,例如锐化,二维三维都可以实现,对照度、对比度增强,甚至做得好可以做 8bit 到 10bit 转换,速度性能非常快。这里仅仅是给了大致的方向。
4、四位一体网络模型设计

第四部分比较关键,四位一体网络模型设计。
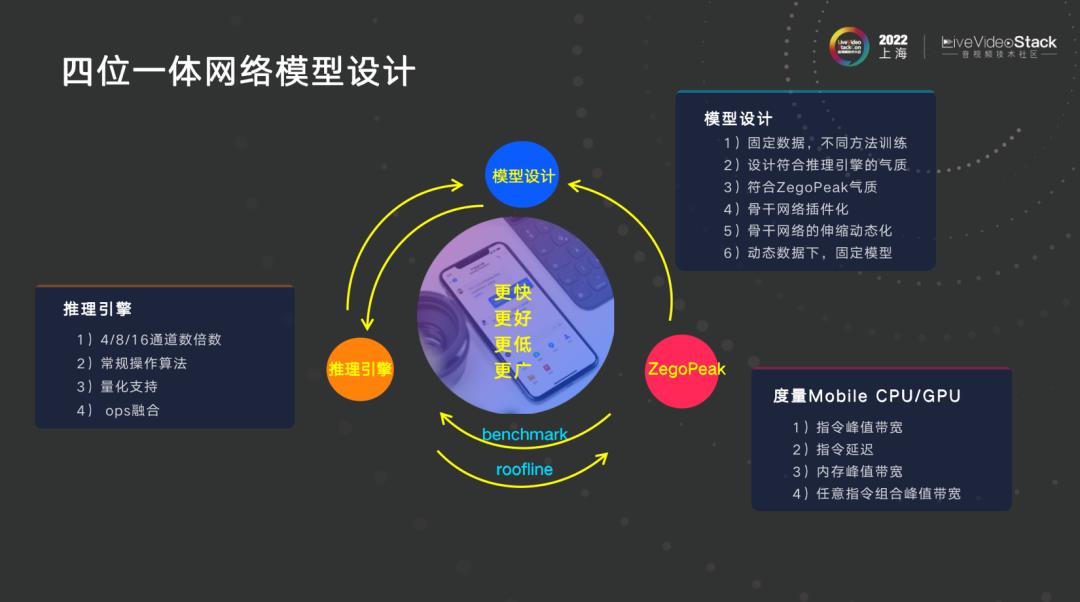
四位一体网络模型设计,虽然是四个,但上图中只有三个,大家可以猜一下还有哪一个。
第一维度是模型设计;第二维度是模型推理引擎,例如 TNN、NCNN、MNN 等很多,基于别人的推理引擎去改和优化,推理引擎与网络模型是否能很好结合,模型本身在不同的推理引擎上速度差别大,模型在 iPhone 上是跑在 CPU 还是 GPU 还是 NPU上,iPhone 的 Core ML 是个黑盒子,如果 OPS 不适合在 NPU上跑,数据就有可能一会儿在 GPU,一会儿在 NPU,模型效率低;第三维度是 Peak,意思是需要去度量模型,操作算子在指定硬件上,例如指定的硬件如高通、联发科、华为芯片上,它的性能到底如何,一个模型在同一时代的机型上跑出的数据效率不同,最重要的是要将 roofline 模型图画出,反向指导我们设计模型。
还差一个维度是什么?我们做所有的事情所要实现的目标就是快和效果,我认为第四个维度是数据,我一直认为基于业务做需求,数据占了功效的 60%。举个例子,超分可以刷榜刷得很厉害,但到实际场景就效果不好,一定是要根据业务指定场景强相关。我们做了一个测试,所有东西从零开始,用自定义数据集,标注好的 3 万张图片,将所有 YOLO 系列的模型参数全部设置在差不多的数量级,初始化一样,训练结果发现 YOLOv5 执行度较高。但在 YOLOv7 文章中开门见山表示从零开始直接训练比多次训练效果好,这表明可能是在特定场景效果好,但在另外场景下是不一定的。
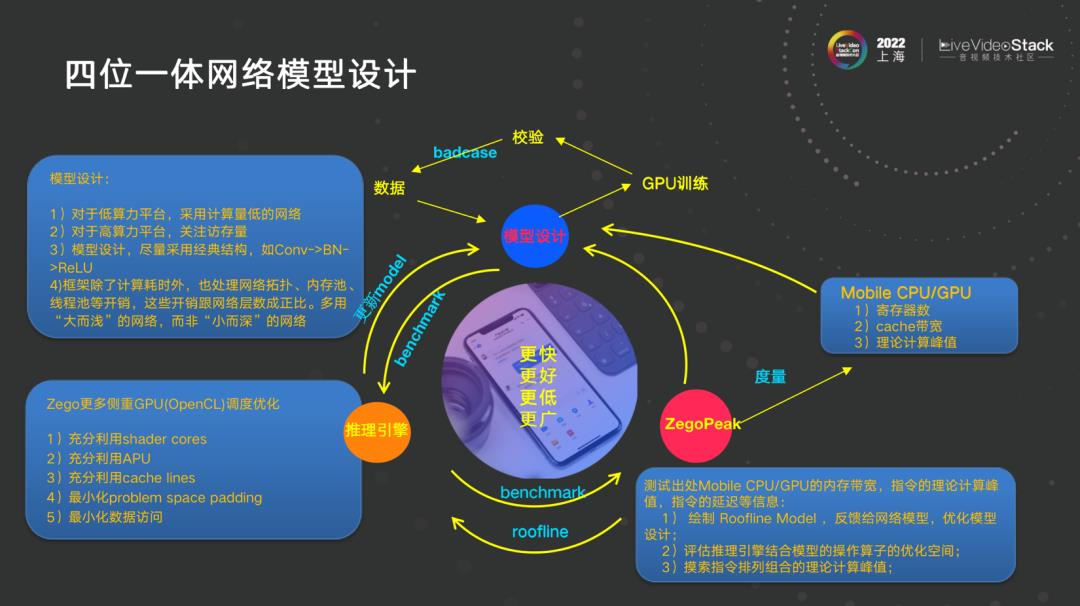
这里更细致地讲一下在推理引擎端,模型设计尽可能运用到硬件算力本身,尽可能将其发挥出来。推理引擎、模型设计大家应该不会忽略,相信大家做多了也知道如何并行、状态信息化。上图右下角绝对会被忽略,这是三个部门做的事情,看似毫不相干,但每个人做的应该与其他两个相关。早期 CL、Peak 和 RAMMER 做了硬件 CPU、GPU 在移动端 NPU 的性能度量,还有旷视的 MegPeak 也在 6 月刚好做了同一件事情,都在做说明这个方向是对的。

我认为数据是最重要的,数据不稳定,模型根本不用去想设计。数据要保证百分之百准确,比如做目标检测的标注,首先运用大模型预标注,人工筛检,再训练,再预标注,反复几次。标注的时候只标注一类,比如生成部署标注十类,实际上做的时候一类一类标注,这样就保证每一类精度非常高,但没人愿意标注,觉得是粗活脏活,但这是把数值刷最高最有效直接快速的方法,丢给外包质量不好,包括算法同事标注质量也差。所以要想出各种办法通过算法本身将数据筛选出来做更多的事情,达到效率提升。

上面分享的效率、速度需要同时上升,主观感受质量不能下降,但模型可以裁剪。
5、演示Demo
低照度增强示例视频
上述视频是低照度增强示例,视频前后分别为原始视频和渐变处理后的视频。明暗程度可以在查找表中动态调整,实例中达到渐变效果,网络生成出来的模型调整程度是固定的。这里没有用噪点视频,不可否认在低照度增强中会把噪点放大。
以上是我的全部分享,谢谢!


以上是关于AI时代的视频云转码移动端化——更快更好,更低,更广的主要内容,如果未能解决你的问题,请参考以下文章