大厂都是如何处理重复消息的?
Posted JavaEdge.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大厂都是如何处理重复消息的?相关的知识,希望对你有一定的参考价值。
消息消费失败,很多框架会自动执行重试,而重试就产生了重复消息。
MQTT协议给出三种传递消息时能够提供的
1 服务质量(Quality of Service)
从低到高:
1.1 QoS 0:At most once
消息最多传递一次,如果当时客户端不可用,则会丢失该消息。即消息在传递时,最多被送达一次。无消息可靠性保证,允许丢消息。
一种 “fire and forget” 的消息发送模式:Sender (Publisher 或 Broker) 发送一条消息之后,就不再关心它有没有发送到对方,也不设置任何重发机制。
消息分发依赖于底层网络能力。发布者只会发布一次消息,接收者不会应答消息,发布者也不会储存和重发消息。该等级具有最高传输效率,但可能送达一次也可能根本没送达。
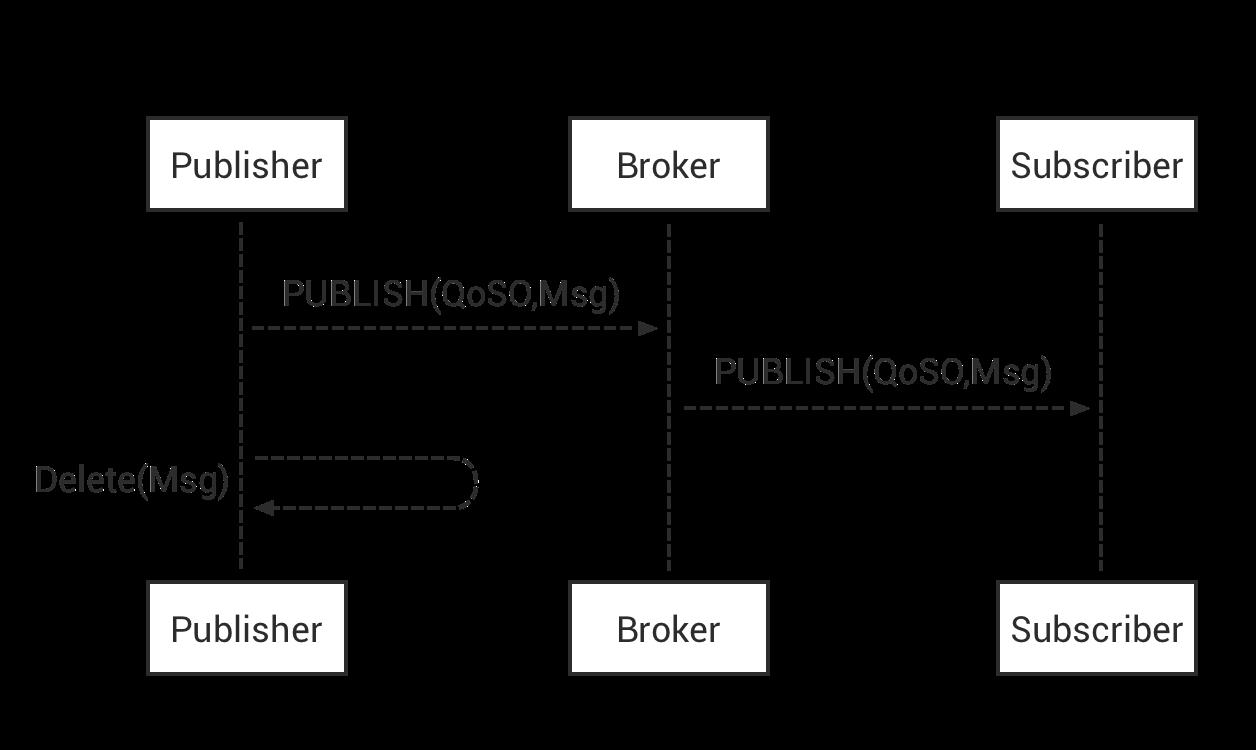
一般都是一些对消息可靠性要求不太高的监控场景使用,如每s上报一次司机乘客地理位置,可接受数据少量丢失。
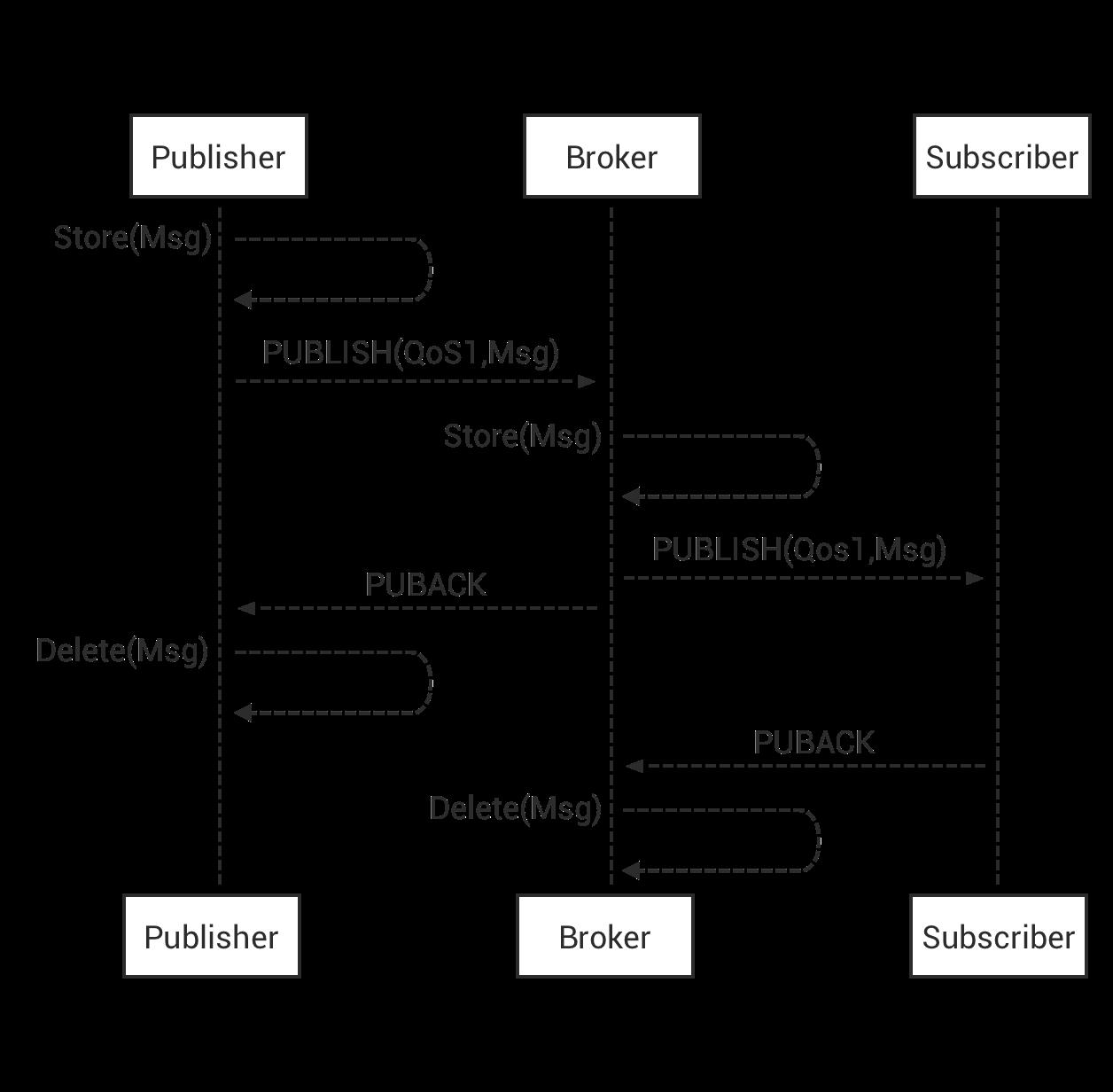
1.2 QoS 1:At least once
消息传递至少 1 次。消息在传递时,至少会被送达一次。即不允许丢消息,但允许重复消息。
包含简单的重发机制,Sender 发送消息之后等待接收者的 ACK,若没收到 ACK,则重发消息。这种模式能保证消息至少能到达一次,但无法保证消息重复。
MQTT 通过简单的 ACK 机制保证 QoS 1。发布者会发布消息,并等待接收者的 PUBACK 报文的应答,若规定时间内没收到 PUBACK 应答,发布者会将消息的 DUP 置为 1 并重发。接收者接收到 QoS 为 1 的消息时应该回应 PUBACK 报文,接收者可能会多次接受同一个消息,无论 DUP 标志如何,接收者都会将收到的消息当作一个新的消息并发送 PUBACK 报文应答。
1.3 QoS 2:Exactly once
恰好一次。消息在传递时,只会被送达一次,不允许丢失、重复。设计了重发和重复消息发现机制,保证消息到达对方并且严格只到达一次。最高等级服务质量,消息丢失和重复都不可接受。使用该等级有额外开销。
发布者发布 QoS 为 2 的消息之后,会将发布的消息储存起来并等待接收者回复 PUBREC 的消息,发送者收到 PUBREC 消息后,它就可以安全丢弃掉之前的发布消息,因为它已经知道接收者成功收到了消息。发布者会保存 PUBREC 消息并应答一个 PUBREL,等待接收者回复 PUBCOMP 消息,当发送者收到 PUBCOMP 消息之后会清空之前所保存的状态。
当接收者接收到一条 QoS 为 2 的 PUBLISH 消息时,他会处理此消息并返回一条 PUBREC 进行应答。当接收者收到 PUBREL 消息之后,它会丢弃掉所有已保存的状态,并回复 PUBCOMP。
无论在传输过程中何时出现丢包,发送端都负责重发上一条消息。不管发送端是 Publisher 还是 Broker,都是如此。因此,接收端也需要对每一条命令消息都进行应答。

1.4 QoS 在发布与订阅中的区别
MQTT 发布与订阅操作中的 QoS 代表不同含义:
-
发布时的 QoS,消息发送到服务端时使用的 QoS
-
订阅时的 QoS,服务端向自己转发消息时可使用的最大 QoS
-
当客户端 A 的发布 QoS 大于客户端 B 的订阅 QoS 时,服务端向客户端 B 转发消息时使用的 QoS 为客户端 B 的订阅 QoS。
-
当客户端 A 的发布 QoS 小于客户端 B 的订阅 QoS 时,服务端向客户端 B 转发消息时使用的 QoS 为客户端 A 的发布 QoS。
不同情况下客户端收到的消息 QoS 可参考下表:

1.5 QoS 等级选型
QoS 级别越高,流程越复杂,系统资源消耗越大。应用程序可以根据自己的网络场景和业务需求,选择合适级别。
QoS 0
- 可以接受消息偶尔丢失。
- 在同一个子网内部的服务间的消息交互,或其他客户端与服务端网络非常稳定的场景。
QoS 1
- 对系统资源消耗较为关注,希望性能最优化。
- 消息不能丢失,但能接受并处理重复的消息。
QoS 2
- 不能忍受消息丢失(消息的丢失会造成生命或财产的损失),且不希望收到重复的消息。
- 数据完整性与及时性要求较高的银行、消防、航空等行业。
大部分MQ都是At least once,如RocketMQ、RabbitMQ和Kafka,即MQ本身并不保证消息不重复。
1.6 Kafka文档说支持Exactly once的呀?
Kafka的确支持Exactly once,但Kafka “Exactly once”和消息传递服务质量标准中的“Exactly once”不同,它是Kafka提供的另一特性,Kafka中支持的事务也和通常理解的事务有差异。Kafka中的事务和Excactly once主要为配合流计算。
现在我们知道MQ无法保证消息不重复,那就得消费代码接受“消息可能重复”事实,只能通过业务代码解决重复消息的业务副作用。
2 幂等性
在消费端,让消费消息的操作具备幂等性(Idempotence):
描述一个操作、方法或者服务,其任意多次执行所产生的影响均与一次执行的影响相同。
一个幂等的方法,使用同样参数,对它进行多次调用和一次调用,对系统产生影响一样。所以,对幂等方法,无需担心重复执行会改变系统。
示例
不考虑并发,“将账户X的余额设为100元”,执行一次后对系统的影响是,账户X的余额变成了100元。只要提供参数100元不变,执行多少次,账户X余额始终100,这操作就是个幂等操作。
“将账户X余额加100元”,这操作就不是幂等,每执行次,账户余额增加100,执行多次和执行一次对系统的影响(即账户余额)不同。
若系统消费消息的业务逻辑具幂等性,那就不用担心消息重复,因为同一消息,消费一次和多次对系统影响一样。即消费多次等于消费一次。
从对系统影响结果:At least once + 幂等消费 = Exactly once。
3 幂等实现方案
最好从业务逻辑入手,将消费业务设计成具备幂等性的操作。但也不是所有业务都天然幂等,需要一些技巧。
3.1 数据库唯一约束
比如对于:将账户X余额加100。
可限制对每个转账单,每个账户只能执行一次变更操作。最简单的,在DB中建一张【转账流水表】:
- 转账单ID
- 账户ID
- 变更金额
然后给【转账单ID,账户ID】联合起来创建唯一约束,这样相同转账单ID、账户ID,表里至多只存在一条记录。
消费消息逻辑可变为:“在【转账流水表】增加一条转账记录,再根据转账记录,异步更新用户余额。”
在转账流水表加条转账记录操作中,由于【转账单ID,账户ID】唯一约束,对同一转账单,同一账户只能插一条记录,后续重复插入操作都会失败,这就实现了幂等。
所以,只要是支持类似“INSERT IF NOT EXIST”语义的存储系统都可实现幂等。
比如,可用
Redis的SETNX
替代数据库中的唯一约束,实现幂等消费。
该种方案需要消费者基于消息类型,去感知此消息类型所要处理的业务,在业务上的唯一约束,不同业务的唯一约束不一样,对消费者实现幂等不友好。
但解决不了主动的重试问题吧,比如插入流水,执行业务,返回MQ逻辑错误,触发重新消费,这时会发现流水已存在。所以这里插流水和业务逻辑也得在一个事务里,这跟方法按区别看来只是怎么去控制唯一性而已。只要流水正确写入了,后续根据流水计算余额的业务逻辑可不与写入流水在同一个事务,即使计算余额失败,也能根据流水重新计算。
3.2 为更新的数据设前置条件(类似CAS)
给数据变更设置一个前置条件:
-
满足条件就更新数据
-
否则拒绝更新数据
更新数据时,同时变更前置条件中需要判断的数据。于是,重复执行该操作时,由于第一次更新数据时,已变更前置条件中的判断数据,不满足前置条件,则不会再执行更新。
“将账户X的余额增加100元”,这操作加个前置条件,变为:“若账户X当前余额为500元,将余额加100元”就具备幂等性。对应到MQ消息,在消息体中带上当前余额,消费时判断DB中当前余额==消息中的余额,相等时才执行更新。
但要更新数据不是数值,或要做个复杂的更新操作咋办?前置判断条件是啥呢?
当余额为500时,执行加100,若当前消息被消费前,下一条消息到来时,数据库余额还是500,这时设置更新条件也是500,这种问题怎么解决?
这种场景就得保证消息的严格顺序。
MVCC
更通用的,是给数据增加版本号version属性,每次更新数据前,比较
当前数据version == 消息中的version
- 不一致,拒绝更新
- 一致,更新数据同时将版本号+1,一样则可实现幂等更新
3.3 记录并检查操作
若前两种方案都不适用,还有通用性最强、适用范围最广方案:记录并检查操作,也称“Token机制或GUID(全局唯一ID)机制”,执行数据更新操作前,先检查是否执行过这更新操作。
- 发消息时,给每条消息指定全局唯一ID
- 消费时,先根据ID检查消息是否被消费过,若没有,才更新数据并将消费状态置为已消费
但分布式系统下很难实现:
- 首先,给每个消息指定一个全局唯一ID,方法很多,但都不太好同时满足简单、高可用和高性能,或多或少都有牺牲
- 更麻烦的,“检查消费状态,然后更新数据并设置消费状态”,三个操作必须作为一组操作,保证原子性,才能真正实现幂等,否则就是Bug
比如对于同一消息:“全局ID为8,操作为:给ID为666账户增加100元”,可能出现这样情况:
- t0时刻:Consumer A 收到条消息,检查消息执行状态,发现消息未处理过,开始执行“账户增加100元”
- t1时刻:Consumer B 收到条消息,检查消息执行状态,发现消息未处理过,因这时刻,Consumer A还未来得及更新消息执行状态
- 这样就导致账户被错误地增加了两次100元,这是一个在分布式系统中非常容易犯的错误
对此,可以用事务实现,也可以锁,但在分布式系统下,分布式事务、分布式锁都会引入高复杂度。所以一般不推荐。
由生产者将不同业务的不同唯一约束(如A业务是a+b字段须唯一,B业务是a+c字段须唯一),统一处理成对消费者友好的全局唯一ID,如A业务是md5(a+b),B业务是md5(a+c),生成全局唯一ID,可以是上面举例的本地md5计算,也可以是包装成服务接口,但其本身也必须幂等,如此Con不管处理什么业务消息,都只需针对"全局唯一ID"保证幂等。
4 总结
这些幂等方案不仅可用于解决重复消息问题,也可解决重复请求或重复调用问题。比如:
- 将HTTP服务设计成幂等的,解决前端或APP重复提交表单数据的问题
- 将一个微服务设计成幂等的,解决RPC框架自动重试导致的重复调用问题
4.1 为何MQ只提供At least once,而非Exactly once
若MQ实现exactly once,会引发:
- 消费端pull时,需检测此消息是否被消费,这检测机制无疑拉低消息消费速度。随消息剧增,消费性能势必急剧下降,导致消息积压
- 检查机制还需业务端去配合实现,若一条消息长时间未返回ack,MQ需要去回调看下消费结果(类似事务消息的回查机制)。这就增加业务端的压力与未知因素。
- 为了确保消息没有被丢失或者重复,队列需采取一定的类似回查的手段,检测消费者是否有收到消息进行处理,在一定程度上会导致队列堆积等一系列问题,并且队列实现的复杂度上升
- 从消费者的角度而言,因为消费者端和Broker Service端都是会各自集群,消费者端可能会存在网络抖动,导致Broker Service为了确保消息不丢失和重复,需要一直进行回查类似的操作,但是由于网络问题,导致队列堆积
exactly once实现有性能损耗,并发高时易出现消息堆积;消息队列设计初衷是解决解耦,而解耦的对象往往是高并发,对性能要求较高的:
- 从产品需求层面讲,MQ设计更注重性能,而非精准(exactly once)
- 基础架构角度来说,关注点是占比大的需求(不能不发,但可以重发),占比极小的需求(敏感型,只能触发一次)可单独抽出来另外实现
所以,MQ不实现exactly once,而是at least once + 幂等性,而幂等性我们消费端业务代码自己处理。
MQ即使做到Exactly once级别,Con也要做幂等。因为Con从MQ取消息时,若Con消费成功,但ack失败,Con还是会取到重复消息,所以MQ费力做成Exactly once无法避免业务侧消息重复问题。
4.2 使用DB的唯一索引防止消息被重复消费,若业务系统存在分库分表,消费消息被路由到不同库或表,还是会存在问题?
一般也不会有问题,因为使用我们的方法,一条具体消息,总会落到确定的库表,其重复消息也会落地同样库表。
4.3 若队列实现At least once,为了不丢消息,Broker Service会进行一定重试,但不可能一直重试,若就是一直重试还是失败怎么处理?
rabbitmq有个特殊队列保存这些总是消费失败的“坏消息”,然后继续消费之后的消息,避免这些坏消息卡死队列。这种坏消息一般不是因为网络原因或消费者宕机导致,大多都是因为消息数据本身有问题,消费者的业务逻辑无法处理。
只支持At least once:是不是与以下几种情况相关:
1.硬件异常或者系统异常导致的数据丢失:消息队列为何不能做成像数据库一样的用undo log和redo log去避免硬件的这种异常,出于性能考虑
为何网络协议中一样TCP和UDP的区别:消息反馈可能不是每一个反馈一次,有时是一批反馈异常,传输中可能会出现丢包或者顺序不一致。
大部分MQ都是批量收发,但采用基于位置的确认机制,可保证顺序。
kafka就算用事务,也不能保证没有重复消费,它有可能发生rebalance时,消费了数据没有提交
关于幂等的情况,像设置帐户余额为100元,或者给余额为500的加100,如果有中间状态的变更或者ABA问题,也能算是幂等操作吗?
确实这个例子解决不了ABA问题,如果要解决这个问题,只能使用版本号方式。
因为目前消息队列,在发送消息给客户端的时候,一般需要客户端ack之后才能确定,这条消息是不是真的被消费了:
-
如果客户端设置的是自动ack,那么mq就能保证只发送一次,但是这样会因为客户端消费消息不成功,而导致消息丢失
-
如果客户端都设置手动ack,若MQ发消息给客户端成功,客户端也消费完成,就在准备ack时,和MQ失去联系,这时MQ不知道这条消息是否真的被消费,只能选择重发消息
所以若MQ保证了只发一次,则MQ就无法保证消息由于客户端消费失败而不丢失,就好像分布式系统中的cap理论,只能保证其中的两种,而无法三个都保证。架构设计就是在取舍之间选择最合适的实现方式。
“如果账户 X 当前的余额为 500 元,将余额加 100 元"和“检查消息执行状态,发现消息未处理过,开始执行账户增加 100”,这两者有啥区别,不都是消费端compareAndUpdate吗,都可以用普通数据库事务就能实现。
主要是检查的内容不一样:
-
前者检查余额,容易实现,但适用范围比较窄
-
后者检查消息执行状态,难实现,但适用范围更广泛
-
如何解决方案一和方案二日益增多的存储日志呀,有合适的删除策略吗?
这种流水一般不能删除,若数量太多影响查询消息,可考虑按照账户ID来分表存储。
参考
- [MQTT QoS(服务质量)介绍 | EMQ (emqx.com)](
以上是关于大厂都是如何处理重复消息的?的主要内容,如果未能解决你的问题,请参考以下文章