TCP Westwood 更新(性能牛逼 )
Posted dog250
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TCP Westwood 更新(性能牛逼 )相关的知识,希望对你有一定的参考价值。
我很喜欢 AIMD,神奇的自然收敛。可它总被诟病性能低。
今晚状态不好,因为关联涉疫,怕被拉走。我个人不怕被带走,住店也不用再任何家务,也是不错。但我的孩子们我会觉得对不住,他们是那么希望体验新的初中,新的幼儿园生活,以至于连早饭都不肯在家里吃得好,看着他们的兴奋,如果他们在兑现兴奋前失望,如果因为我被带走他们没法上学,失去了青春 or 童年,这便是一辈子都补不回来的,所以我惶恐。我写此文,以表示我稍微会一点代码。
不过上周,有网友评论说 “拥塞控制乃社会学问题,关键在资源分配与竞争。但是现在的 paper 很多都在死磕端到端的吞吐量,路子越走越歪”。我觉得说到点子上了,但凡社会博弈问题就需要一种收敛到公平的内在机制,不然最终鸡飞蛋打,都没得玩了。对于拥塞控制,就是拥塞崩溃,所以范雅各布森才引入 AIMD。
我每周都重复上面这种观点,需写些实际代码自洽。这周我更新下 westwood,加入鲁棒性,不求超高吞吐,比 CUBIC 稍好,但吞吐的提升并不以损害公平性或增加重传率为代价,也算对得起本文。
BBR 的鲁棒性由 10 rounds window 的 max-filtered bandwidth 保证。引用 Neal 的原话:
Once you allow for short flows (like web pages, RPCs, etc) to dynamically enter and leave a bottleneck, the considerations become different. As is well-known, Reno/CUBIC will starve themselves if new flows enter and cause loss too frequently. For CUBIC, for a somewhat typical 30ms broadband path with a flow fair share of 25 Mbit/sec, if new flows enter and cause loss more frequently than roughly every 2 seconds then CUBIC will not be able to utilize its fair share. For a high-speed WAN path, with 100ms RTT and fair share of 10 Gbit/sec, if new flows enter and cause loss more frequently than roughly every 40 seconds then CUBIC will not be able to utilize its fair share. Basically, loss-based CC can starve itself in some very typical kinds of dynamic scenarios that happen in the real world.
BBR is not trying to maintain a higher throughput than CUBIC in these kinds of scenarios with steady-state bulk flows. BBR is trying to be robust to the kinds of random packet loss that happen in the real world when there are flows dynamically entering/leaving a bottleneck.
简言之就是 BBR 可以抵抗背景流的突发行为。
这种鲁棒性本质上是 “坚持一段时间”,不像 CUBIC 一碰即退,鲁棒性源自摊平的时间。但坚持的代价是丢包,BBR 高重传率来源于此。
此外,BBR MIMD 也是高重传率的原因,我有种有效的方法上周已展出:TCP BBR 降本增效,但这并不改变 BBR 测不准的本质。
依赖 ACK 的带宽采集的信息分辨率存在上限,既然怎么都不准,又何必去挣扎细节。所以我并不认同 BBR 那些 1,or 2,or 4 segs 之类的细致纠结,我甚至认为这种纠结是不正确的。统计量是精确不起来的。
既然测不准又何必假设理想化,还是那句话,不确定的且不能确定的,要统计,别假设别猜。
BBR 在多种实验室环境被推演,公式化 Buffer 与背景流的收敛关系,但现实环境中,总 Buffer 的效果是串联 Buffer 的 “与” ,即漏桶效应,最小 Buffer 决定丢包。加上背景流的影响,现实环境本身就是测不准的,只能用统计的方法去描述,这点和量子物理学很像,也和足球很像,没人能预测足球的精确轨迹,但某些球队就是强。
BBR 发布之前,我一直围绕 westwood 修改,它不精确,但它能相对公平地收敛。它的一个简单变体(我仍叫它 westwood),既公平,也简单高效,体现在下图:
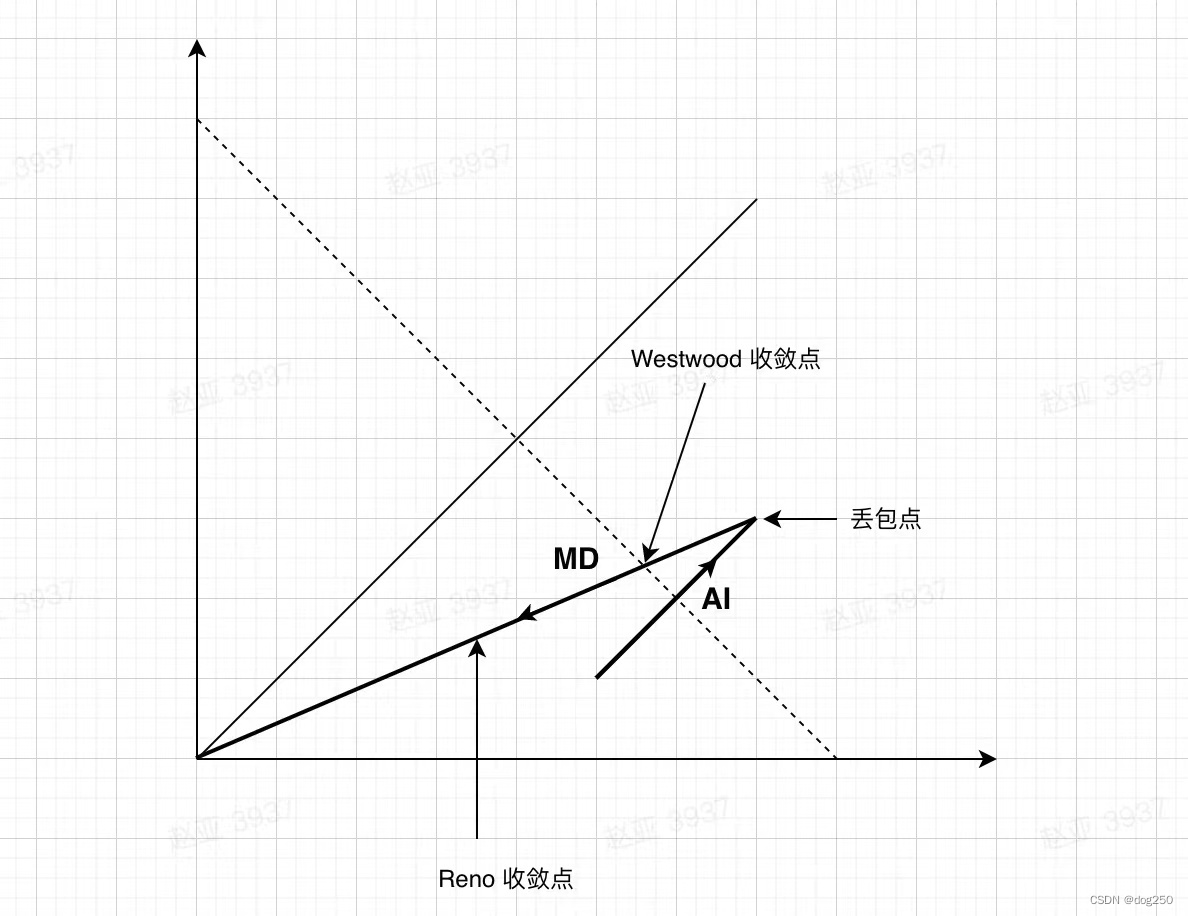
westwood 收敛在瓶颈带宽,而 Reno/CUBIC 收敛在 inflight 固定百分比,显然 westwood 和 BBR 收敛点是一致的。仅从上图来看,westwood 带宽利用率就比 Reno/CUBIC 高。
然而 Linux tcp_westwood 并没能完整实现它,原因大致有二:
- Linux TCP 拥塞状态机给 westwood 的控制权太少。
- Linux TCP 没有提供高精度时间戳用来测量带宽。
BBR 引入 Linux TCP 之后,上面两个问题均已解决,但 westwood 算法却没有更新。但现在可以尝试更新一下,很简单,实现上图即可。
为了给 westwood 增加一些鲁棒性,我并没用丢包时的即时带宽作收敛带宽,而采用 “一段时间内的最大带宽” 作收敛带宽,这是关键,即 “将鲁棒性交给时间”。
代码修改自多年前职业做 CDN 传输优化时的 westwood++ 版本,加入鲁棒性后,命名为 westwood-:
https://github.com/marywangran/westwood-sub (暂发布 prr 版本,为了收敛,大家都好。)
这个 westwood- 实际上是借用了 BBR 里测量带宽的那套代码,加了个 windowed max-filter,以修正老式 westwood 里 “理是那个理,但实现不理想“。按照之前老式儿的实现,基于 una 数 ACK 数量估算低通滤波带宽,是大大不准的,比 BBR 还不准。
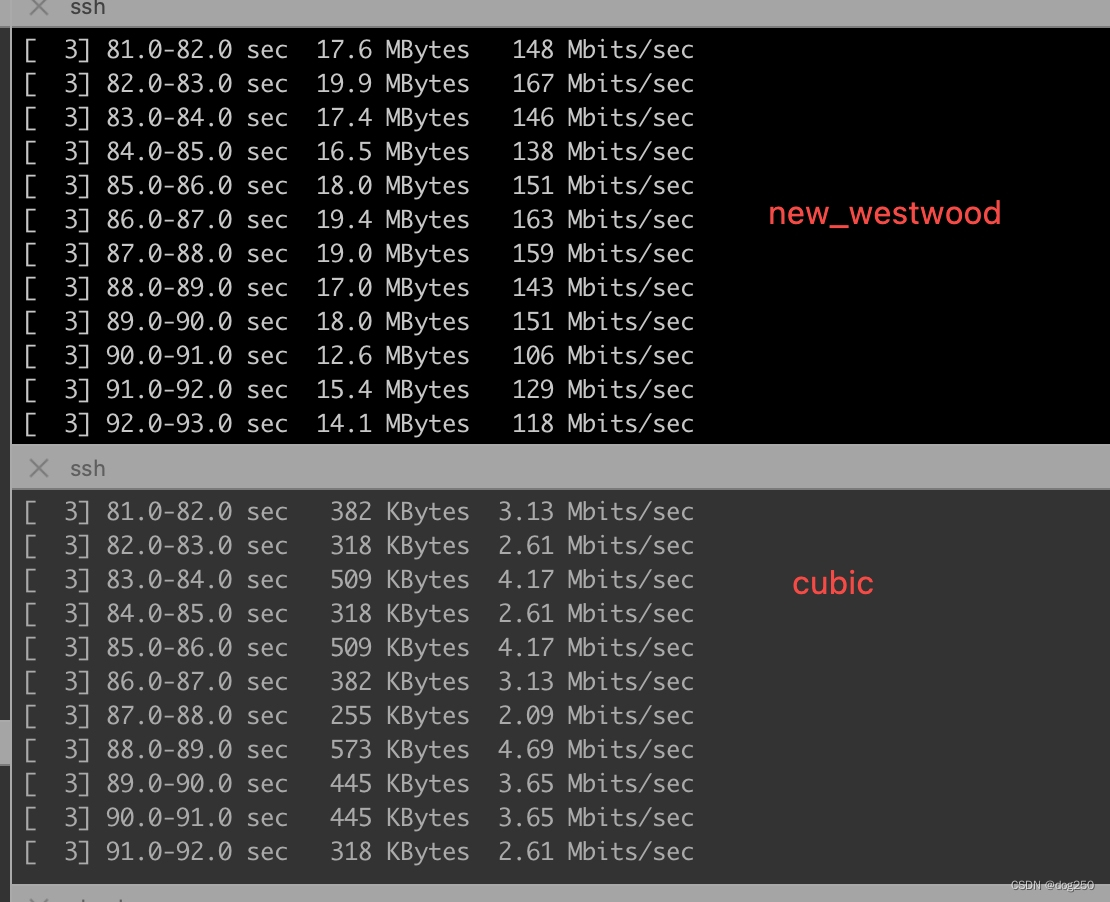
丢包 8%,延时 20ms。下面是不使用 prr(Proportional Rate Reduction,也就是 Linux 内核 tcp_cwnd_reduction 函数) 算法的:
下图是使用 prr 算法的:
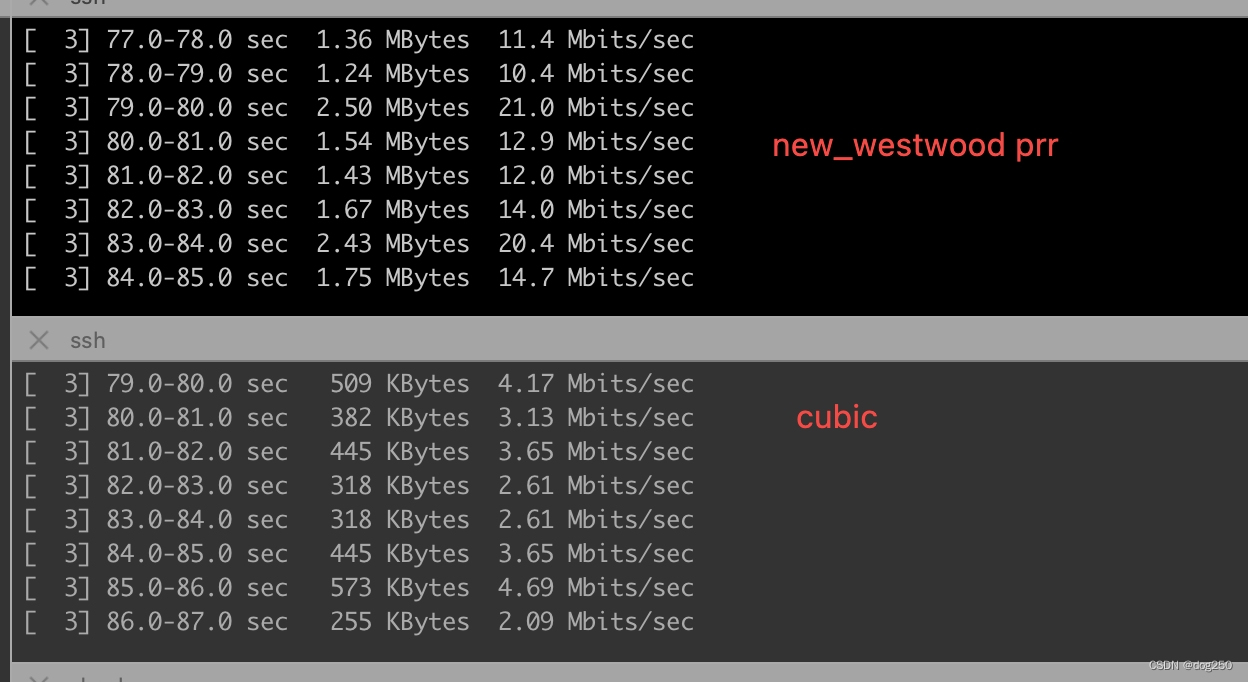
我选择 prr 版本,因为它几乎没有增加重传率,但带宽却大大增加。同时多流测试,公平性亦佳。
如果单纯追求高带宽,那简单。固定 cwnd 硬怼就是,参考:最快的 TCP 拥塞控制算法,又何必如此周折,但这是最低级的,这不高尚。
拥塞控制的目标是保障网络可用性,避免拥塞崩溃,提高带宽利用率并不是拥塞控制的本职。另外,端系统听不听话,带宽利用率的高低,如果不听话,限速,整形,pacing 都是 QoS 的事,中间网络 AQM 该丢就丢。
谈到广域网单流传输优化,本与拥塞控制无关,单流优化是单流行为,猛发便是,但没有任何单流可以导致广域网拥塞,拥塞是群体行为,因此拥塞控制属于社会学博弈范畴。对任何单流,任何退避行为都会导致自身吞吐下降,但对所有单流而言,如果都不退避,整个广域网将不可用。因此,无论对于单流优化还是拥塞控制,合理的收敛点都是核心。本文强调并实现 westwood 算法新样式儿。
浙江温州皮鞋湿,下雨进水不会胖。
以上是关于TCP Westwood 更新(性能牛逼 )的主要内容,如果未能解决你的问题,请参考以下文章