2022 全球 AI 模型周报
Posted Zilliz Planet
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2022 全球 AI 模型周报相关的知识,希望对你有一定的参考价值。
本周介绍了 5 个计算机视觉领域的 SoTA 模型,均于最近发表于2022年顶会 CPVR 和 ECCV: RepLKNet 特立独行专门研究大卷积核, PoolFormer 表示 Transformer 的核心在于架构,Shunted Transformer 提出能够分流的新型注意力机制,QnA 用学习查询加速视觉模型, CoOp 第一个在计算机视觉领域里探索可学习的提示。
如果你觉得我们分享的内容还不错,请不要吝啬给我们一些免费的鼓励:点赞、喜欢、或者分享给你的小伙伴。 https://github.com/towhee-io/towhee/tree/main/towhee/models https://github.com/towhee-io/towhee/tree/main/towhee/models
https://github.com/towhee-io/towhee/tree/main/towhee/models
卷积模型里的清流 RepLKNet ,大卷积核也有春天!
出品人:Towhee 技术团队 顾梦佳
由清华和旷视提出,收录于 CVPR2022,RepLKNet 专注于优化大卷积核的应用。增加卷积核尺寸可以带来更大的感受野,同时能够提取到更加深层的语义信息,有助于确定目标的位置,因此擅长精细的像素级分割任务。此外,实验证明大卷积核也能够有效改进小特征图。在一些经典图像下游任务中(图像分类、语义分割等),RepLKNet 以纯卷积的架构超过 Swin Transformer 在大型公开图像数据集 ImageNet 上的表现,甚至拥有更小的延迟。
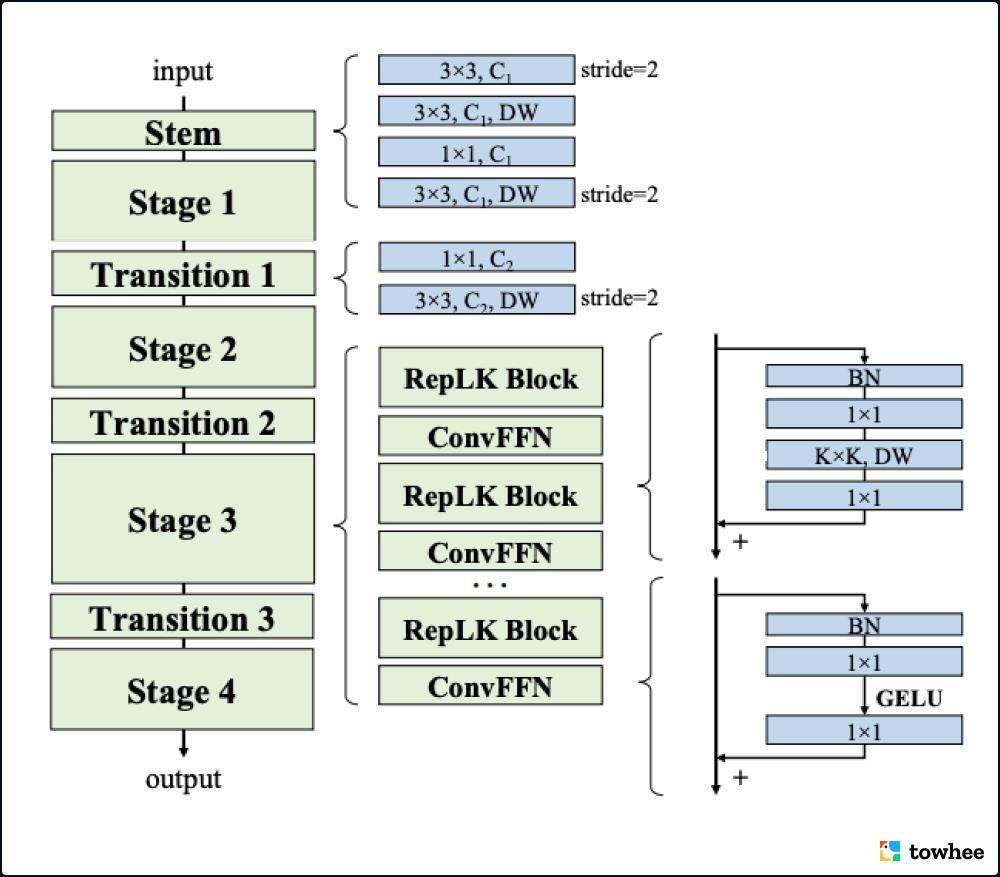
Flow of RepLKNet
RepLKNet 将不同尺寸的深度可分离卷积 (DepthWise convolution) 引入到卷积神经网络中,每个卷机拥有从 3×3 到 31×31 大小不等的卷积核。大卷积核难免会带来大量的算力需求,而深度可分离卷积的加入能够有效解决这一问题。另外,残差结构对大卷积核来说也至关重要,其收益远大于小卷积核。RepLKNet 虽然主要使用了大卷积核,但也利用小卷积核进行重参数化,用于提高模型性能。
更多资料:
PoolFormer 引起 Transformer 的架构与模块之争
出品人:Towhee 技术团队 顾梦佳
一直以来,注意力机制都被认为是 Transformer 框架模型的核心之一。虽然最近有研究表明使用 Spatial MLP 也能达到类似的性能,但是 PoolFormer 却用非常简单的空间池化操作取代了注意力模块,甚至在多个计算机视觉任务上都取得了具有竞争力的表现。这一结果不禁让人思考,难道 Transformer 的核心竞争力其实来自于其架构,与模块不甚有关?

MetaFormer Architectures: Transformer, MLPs, PoolFormer
PoolFormer 的作者认为以往的 Transformer 与近来改进的 MLP 模型之所以能够成功,是因为采用了一种通用的架构(MetaFormer)。为了证明这一理论,PoolFormer 在尽量不改变模型架构的情况下,只将 Token Mixer 部分替换成简单的空间池化。由于该部分没有可学习的参数,PoolFormer 采用类似传统卷积神经网络的分阶段方法和层级 Transformer 结构,将模型分为四个阶段,逐步加倍下采样。
更多资料:
新加坡国立大学 & 字节跳动联合提出 Shunted Transformer
出品人:Towhee 技术团队 张晨、顾梦佳
NUS 和字节跳动联合改进了视觉 Transformer,提出一种新的网络结构 —— Shunted Transformer,其论文被收录于 CVPR 2022 Oral。基于分流自注意力(Shunted Self-Attention)的 Transformer 在公开的图像数据集 ImageNet 上达到了 84.0%的 Top-1 准确率,而且减少了一半模型大小和计算成本。

Shunted Transformer 网络架构
视觉 Transformer 模型 (ViT) 在各种计算机视觉任务中表现出现,主要归功于自注意力能过模拟图像 patches(或token)的长距离依赖关系。然而,该能力需要指定每一层每个 token 特征的相似感受区,不可避免地限制了每个自注意力层捕捉多尺度特征的能力,从而导致在处理具有不同尺度的多个物体的图像时性能下降。为了解决这个问题,Shunted Transformer 使用分流自注意力(SSA),允许 ViT 系列网络在每个注意力层的混合尺度上建立注意力模型。SSA 的关键思想是将异质性的感受野大小注入 token。在计算自注意矩阵之前,它会有选择地合并 token 来代表较大的物体特征,同时保留某些 token 以保持细粒度的特征。这种新颖的合并方案使自注意力能够学习不同大小的物体之间的关系,并同时减少 token 数量和计算成本。
更多资料:
-
更多资料: CVPR 2022 Oral | 全新视觉Transformer主干!NUS&字节跳动提出Shunted Transformer_Amusi(CVer)的博客-CSDN博客; Shunted Transformer 飞桨权重迁移体验_AI Studio的博客-CSDN博客
CVPR 2022 Oral: 高效局部注意力的学习查询 QnA
出品人:Towhee 技术团队 王翔宇、顾梦佳
分层视觉模型 —— Query and Attention (QnA)的核心是一种具有线性复杂性且平移不变的局部注意力层。其结构类似卷积,但是比卷积具有更强的表征能力。实验证明,引入学习查询的视觉模型不仅性能媲美其他 SoTA 模型,还显著地改进了内存复杂度,加速了模型推理。

QnA Overview
视觉 Transformer 可以捕获数据中的长期依赖,但是其中重要的组成部分——自注意力机制,会受制于高延迟以及低效的内存利用方式,使其不适合于高分辨率的输入图片。为了减缓这这些缺点,层次视觉模型会在不重叠的窗口区域进行自注意力。这种方法虽然提高了效率,但是限制了跨窗口的交互,降低了模型的性能。为了解决这些问题,QnA 作为一种新的局部注意力层,以一种重叠的方式局部的汇聚输入数据。其核心思想是引入学习查询,从而实现快速高效的实现。通过将其合并到分层视觉模型中来验证我们层的有效性。
更多资料:
CV 领域的新探索,CoOP 将可学习提示应用到视觉-语言模型
出品人:Towhee 技术团队 王翔宇、顾梦佳
通常视觉-语言预训练会在一个共同特征空间中对齐图片与文本,通过提示的方式在下游任务进行零样本迁移。其中提示工程一直面临着一些挑战:对建模领域的高要求,以及大量的时间成本。提示工程在 NLP 中得到了更好地应用和发展,而 CoOp 率先基于 CLIP 开始探索可学习的提示在计算机视觉领域中的可行性。它提出上下文优化的策略,能够简单地将此类大规模训练的视觉-语言模型应用于下游的图像识别任务。通过在11个下游任务上的验证,CoOp 证明了该策略的有效性,改善后的模型性能够超越原始预训练模型。

Overview of Context Optimization (CoOp)
CoOp 将视觉-语言模型中的提示部分从手工设计替换成自动学习,旨在通过上下文找到最优的提示。它利用可学习的向量构建一个提示的上下文,并且只需要一两个示例就可以大幅度超越手工设计的提示。CoOp 提出两个种提示学习方法:第一种是 unified context,所有类别的样本学习的上下文都是一样的;第二种是 class-specific context,每个类别都有特定的上下文。
更多资料:
-
模型代码:GitHub - KaiyangZhou/CoOp: Prompt Learning for Vision-Language Models (IJCV'22, CVPR'22)
-
更多资料:【CLIP系列Paper解读】CoOp: Learning to Prompt for Vision-Language Models - 知乎
如果你觉得我们分享的内容还不错,请不要吝啬给我们一些鼓励:点赞、喜欢或者分享给你的小伙伴!
活动信息、技术分享和招聘速递请关注:你好👋,数据探索者 https://zilliz.gitee.io/welcome/
https://zilliz.gitee.io/welcome/
如果你对我们的项目感兴趣请关注:
以上是关于2022 全球 AI 模型周报的主要内容,如果未能解决你的问题,请参考以下文章
华为开启2022全球校园AI算法精英赛道 百万奖金等你来挑战算法极限
华为开启2022全球校园AI算法精英大赛 百万奖金等你来挑战算法极限
华为开启2022全球校园AI算法精英大赛 百万奖金等你来挑战算法极限
中美AI领跑全球,《2021-2022中国人工智能计算力发展评估报告》