Flink从Kafka消费并统计结果写入Kafka
Posted 愚者oO
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink从Kafka消费并统计结果写入Kafka相关的知识,希望对你有一定的参考价值。
Flink从Kafka消费并统计结果写入Kafka
Source 端模拟写入数据脚本
此处需要faker第三方依赖制造一些假数据
<dependency>
<groupId>com.github.javafaker</groupId>
<artifactId>javafaker</artifactId>
<version>0.17.2</version>
</dependency>
现在自己部署的集群中创建出所需的两个 Topic 来模拟kafka => kafka的过程
# 第一个Topic test:Source端(脚本所需要写入的目标Topic)
$KAFKA_HOME/bin/kafka-topics.sh --create --topic test --partitions 3 --replication-factor 2 --zookeeper node01:2181,node02:2181,node03:2181
# 第二个Topic result:Sink端(将 test 中统计的数据写入的目标Topic)
$KAFKA_HOME/bin/kafka-topics.sh --create --topic result --partitions 3 --replication-factor 2 --zookeeper node01:2181,node02:2181,node03:2181
插入脚本【faker假数据】
faker使用手册————————>链接
import scala.language.postfixOps
import com.github.javafaker.Faker
import java.util.Locale, Properties
import scala.collection.mutable.ListBuffer
import org.apache.kafka.common.serialization.StringSerializer
import org.apache.kafka.clients.producer.KafkaProducer, ProducerRecord
object KafkaFakerDataShell
def main(args: Array[String]): Unit =
val data: ListBuffer[String] = createKafkaData()
// 目标Topic
val producerTopic: String = "test"
val producerProp: Properties = new Properties()
producerProp.setProperty("bootstrap.servers", "node01:9092,node02:9092,node03:9092")
producerProp.setProperty("key.serializer", classOf[StringSerializer].getName)
producerProp.setProperty("value.serializer", classOf[StringSerializer].getName)
// 事务超时等待时间默认为15分钟(这里只能比15分钟小)
producerProp.setProperty("transaction.timout.ms", 5 * 60 * 1000 + "")
val myProducer: KafkaProducer[String, String] = new KafkaProducer[String, String](producerProp)
for (item <- data )
myProducer.send(new ProducerRecord[String,String](producerTopic,item))
Thread.sleep(300)
// 数据工厂
def createKafkaData(): ListBuffer[String] =
lazy val lst: ListBuffer[String] = ListBuffer()
val f: Faker = new Faker(Locale.US)
for (i <- 1 to 1200)
val id = i.toInt
val name: String = f.name.fullName()
val age: Int = f.number().randomDouble(1, 18, 100).toInt
val score: Int = f.number().randomDouble(1, 1, 100).toInt
val timestamp: Long = System.currentTimeMillis()
val data = id + "," + name + "," + age + "," + score + "," + timestamp
// 数据样本:
// 1,Joel Armstrong,39,46,1661279479722
lst.append(data)
lst
以下模拟从 Topic test 中消费数据并将结果统计 写入到集群中另一个 Topic result中
import java.lang
import java.util.Properties
import org.apache.flink.api.scala._
import org.apache.flink.util.Collector
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.runtime.state.filesystem.FsStateBackend
import org.apache.flink.streaming.api.CheckpointingMode, TimeCharacteristic
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.scala.DataStream, OutputTag, StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer, FlinkKafkaProducer, KafkaSerializationSchema
import org.apache.flink.streaming.util.serialization.SimpleStringSchema
import org.apache.kafka.clients.producer.ProducerRecord
import java.nio.charset.StandardCharsets
/**
* 以下模拟从kafka (topic:huawei) => flink => kakfa (topic:result)
* result数据:我们以分数分组 统计每个窗口中各个分数的统计人数(也可以转为样例类输出)
* */
// Student样例类 id 名称 年龄 分数 时间戳(也是Event Time:Long类型)
// test 数据样本: 1,Joel Armstrong,39,46,1661279479722
case class Student(id: Int, name: String, age: Int, score: Int, timestamp: Long)
object ConsumerKafkaMsg
def main(args: Array[String]): Unit =
// Todo: 构建流处理环境
val environment = StreamExecutionEnvironment.getExecutionEnvironment
// Todo: 开启checkpoint(非重点)
// 默认checkpoint功能是disabled的,想要使用的时候需要先启用
// 每隔5000 ms进行启动一个检查点【设置checkpoint的周期】
environment.enableCheckpointing(5000)
// 高级选项:
// 设置模式为exactly-once (这是默认值)
environment.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// 确保检查点之间有至少500 ms的间隔【checkpoint最小间隔】
environment.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
// 检查点必须在一分钟内完成,或者被丢弃【checkpoint的超时时间】
environment.getCheckpointConfig.setCheckpointTimeout(60000)
// 同一时间只允许进行一个检查点
environment.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
// 表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint【详细解释见备注】
/**
* ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint
* ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION: 表示一旦Flink处理程序被cancel后,会删除Checkpoint数据,只有job执行失败的时候才会保存checkpoint
*/
// environment.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
// 设置statebackend
environment.setStateBackend(new FsStateBackend("hdfs://node01:8020/your_proj/checkpoints", true))
environment.setParallelism(1)
// Todo: 设置时间语义类型
environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// Todo: 配置kafka相关参数
val topic = "test"
val prop = new Properties()
prop.setProperty("bootstrap.servers", "node01:9092,node02:9092,node03:9092")
prop.setProperty("group.id", "huawei-consumer") // 消费者组名称
prop.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
prop.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
// flink开启自动检测kafkatopic新增的分区机制(动态的检测) 比如原来kafka的分区是3个 后来为了解决热点问题提高了分区变成了5个 那么我们可以通过本行的配置动态检测出现在的分区为5
prop.setProperty("flink.partition-discovery.interval-millis", "3000")
// 构建FlinkKafkaConsumer对象
val kafkaConsumer = new FlinkKafkaConsumer[String](topic, new SimpleStringSchema, prop)
// 在进行checkpoint的过程中是否保存offset到内置的topic【__consumer_offsets】中; true表示保存,false表示不保存
// 它会忽略在properties中配置的自动提交偏移量。
// kafkaConsumer.setCommitOffsetsOnCheckpoints(true)
// Todo: 接受kafka topic数据
val kafkaSource: DataStream[String] = environment.addSource(kafkaConsumer)
// Todo: 对数据进行处理
val stuObj: DataStream[Student] = kafkaSource.map(x => x.split(",")).map(x => Student(id = x(0).toInt,
name = x(1), age = x(2).toInt,
score = x(3).toInt, timestamp = x(4).toLong))
// 过滤掉60分以下的 然后用分数做分组
val filtedValue: DataStream[Student] = stuObj.filter(_.score > 60)
// Todo: 定义一个侧输出流 来存放迟到的数据(延伸:后续可以将迟到数据统计累加只结果表)
val lateTag = new OutputTag[Student]("late")
// Todo: 周期性添加watermark
val result: DataStream[(Int, Long)] = filtedValue.assignTimestampsAndWatermarks(
new AssignerWithPeriodicWatermarks[Student]
// 最大的乱序时间
val maxOutOfOrderness = 5000L
// 记录最大事件发生时间
var currentMaxTimestamp: Long = _
// Todo: watermark=消息事件生成的最大时间-延迟时间
override def getCurrentWatermark: Watermark =
val watermark = new Watermark(currentMaxTimestamp - maxOutOfOrderness)
watermark
// Todo: 抽取事件发生时间
override def extractTimestamp(element: Student, recordTimestamp: Long): Long =
// 获取事件发生时间
val currentElementEventTime: Long = element.timestamp
// 对比当前事件时间和历史最大事件时间, 将较大值重新赋值给currentMaxTimestamp
currentMaxTimestamp = Math.max(currentMaxTimestamp, currentElementEventTime)
println("接受到的事件:" + element + " |事件时间: " + currentElementEventTime)
currentElementEventTime
).keyBy(_.score)
.window(TumblingEventTimeWindows.of(Time.seconds(60))) // 定义滚动窗口 60秒滚动一次 并触发计算
.allowedLateness(Time.seconds(2)) // 允许等待数据2s【非必要】(超时等待时间:这里表示由于网络抖动会造成的延迟数据)
//.sideOutputLateData(lateTag) // 迟到的数据加入到lateTag侧输出流中(可扩展)
// 具体逻辑
/** Type parameters:
* IN – The type of the input value.
* OUT – The type of the output value.
* KEY – The type of the key.
* W – The type of the window. */
.process(new ProcessWindowFunction[Student, (Int, Long), Int, TimeWindow]
override def process(key: Int, context: Context, elements: Iterable[Student], out: Collector[(Int, Long)]): Unit =
val startTime: Long = context.window.getStart
//窗口的结束时间
val startEnd: Long = context.window.getEnd
//获取当前的 watermark
val watermark: Long = context.currentWatermark
var sum: Long = 0
val toList: List[Student] = elements.toList
for (eachElement <- toList)
sum += 1
println("窗口的数据条数:" + sum +
" |窗口的第一条数据:" + toList.head +
" |窗口的最后一条数据:" + toList.last +
" |窗口的开始时间: " + startTime +
" |窗口的结束时间: " + startEnd +
" |当前的watermark:" + watermark)
out.collect((key, sum))
)
// Todo: 打印延迟太多的数据 侧输出流:主要的作用用于保存延迟太久的数据(如果检测某个时间段网络抖动过与严重可以将测输出流中的计算结果和输出流合并以确保准确性)
result.getSideOutput(lateTag).print("late-----> ")
result.print("result: ========>")
// 转换结果为字符串
val resultObj: DataStream[String] = result.map(x => x._1 + "," + x._2)
// Todo: 创建kafka sink配置 并构建生产者对象
val producerTopic = "result"
val producerProp = new Properties()
producerProp.setProperty("bootstrap.servers", "node01:9092,node02:9092,node03:9092")
// 设置FlinkKafkaProducer里面的事务超时时间,默认broker的最大事务超时时间默认为15分钟,这里不能够超过该值(所以只能比15分钟小)
producerProp.setProperty("transaction.timeout.ms", 5 * 60 * 1000 + "")
val serializationSchema: KafkaSerializationSchema[String] = new KafkaSerializationSchema[String]
override def serialize(element: String, timestamp: lang.Long): ProducerRecord[Array[Byte], Array[Byte]] =
new ProducerRecord[Array[Byte],
Array[Byte]](
producerTopic, // target topic
element.getBytes(StandardCharsets.UTF_8)) // record contents
val myProducer: FlinkKafkaProducer[String] = new FlinkKafkaProducer[String](
producerTopic, // target topic
serializationSchema, // serialization schema
producerProp, // producer config
FlinkKafkaProducer.Semantic.EXACTLY_ONCE // fault-tolerance
)
resultObj.addSink(myProducer)
environment.execute("程序开始执行:>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>")
功能展示
-
首先运行KafkaFakerDataShell 产生数据到 test topic中
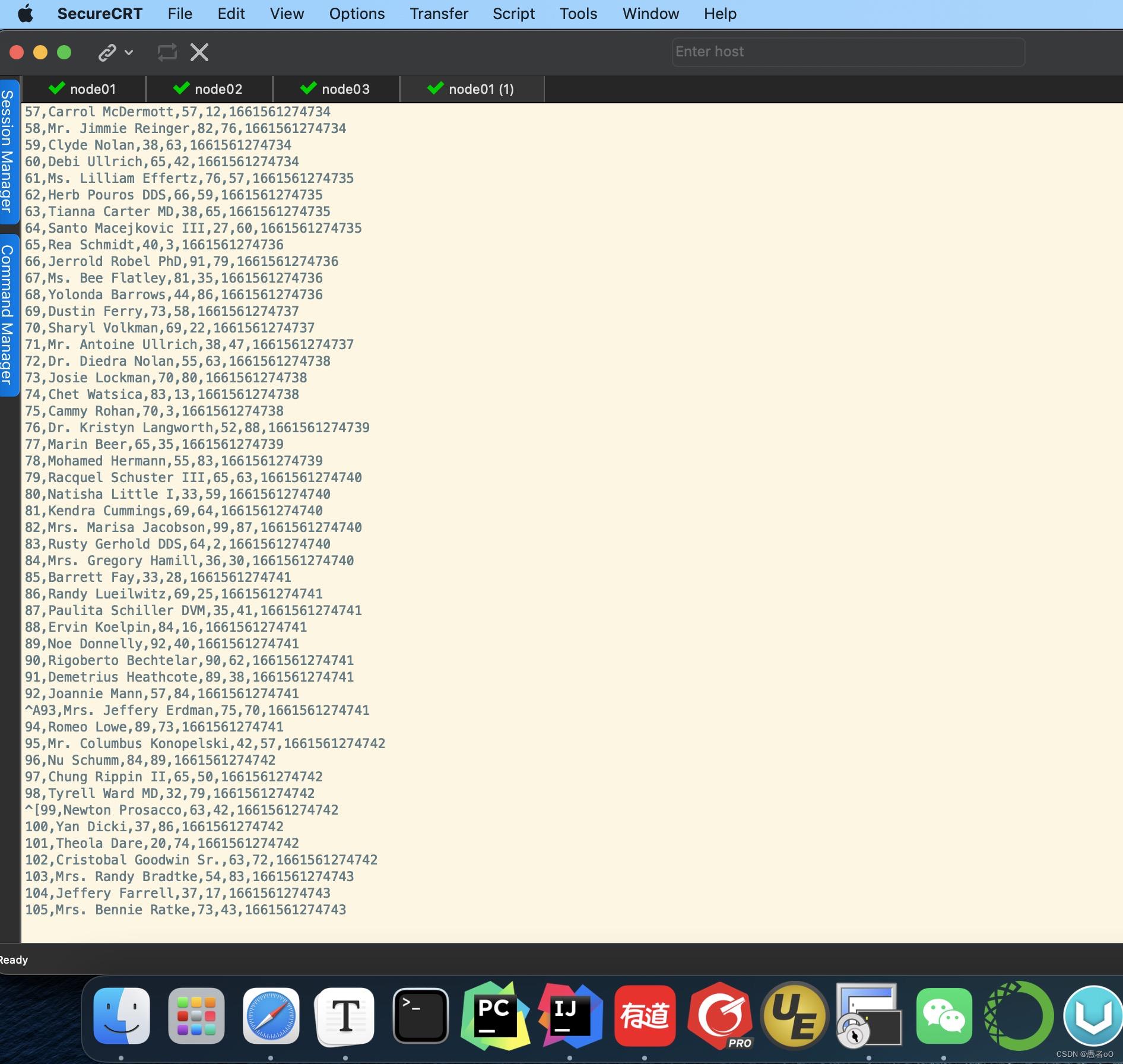
在运行ConsumerKafkaMsg.scala
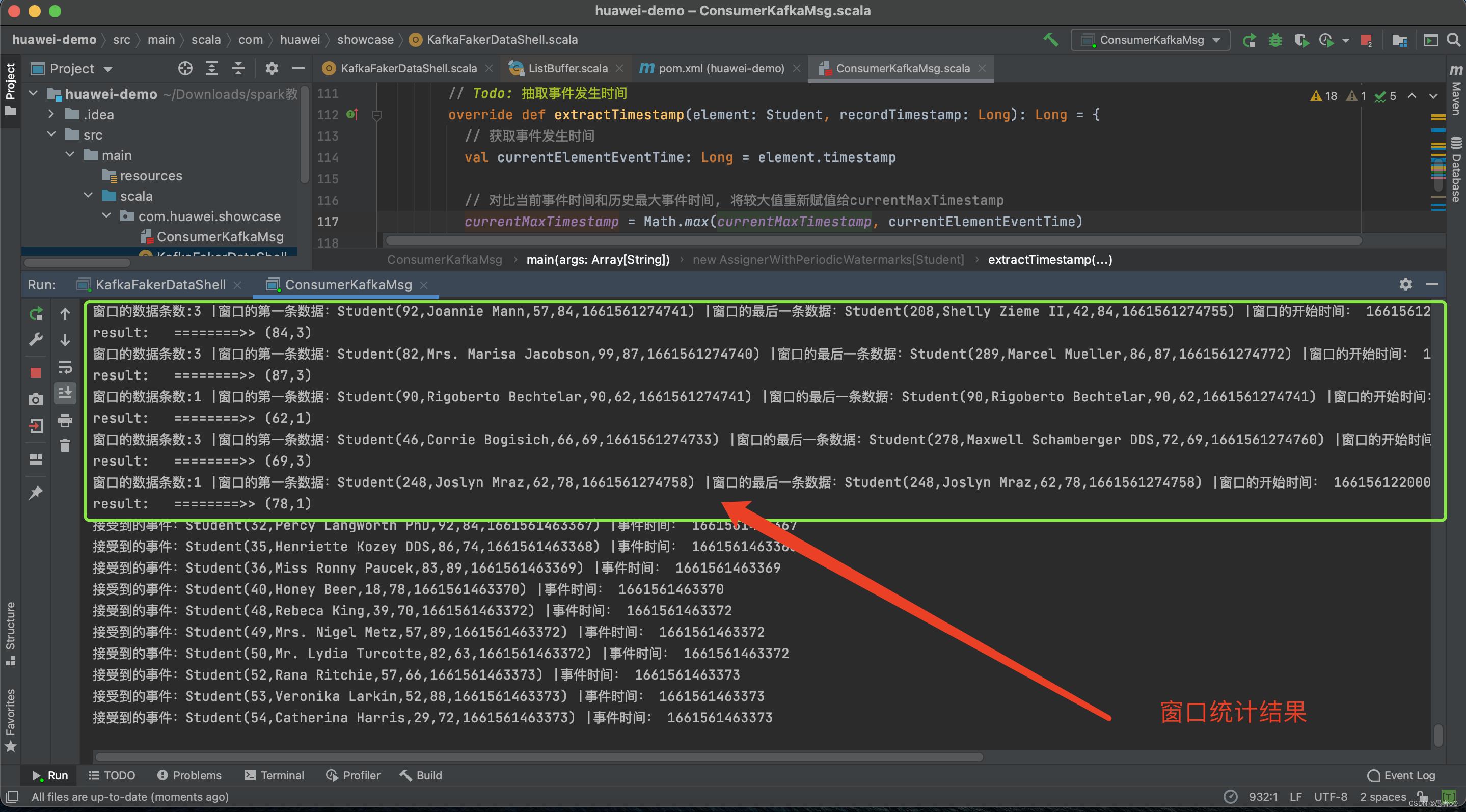
查看集群上的topic看是否插入了数据
shell kafka-console-consumer.sh --bootstrap-server node01:9092,node02:9092,node03:9092 --topic result查看结果
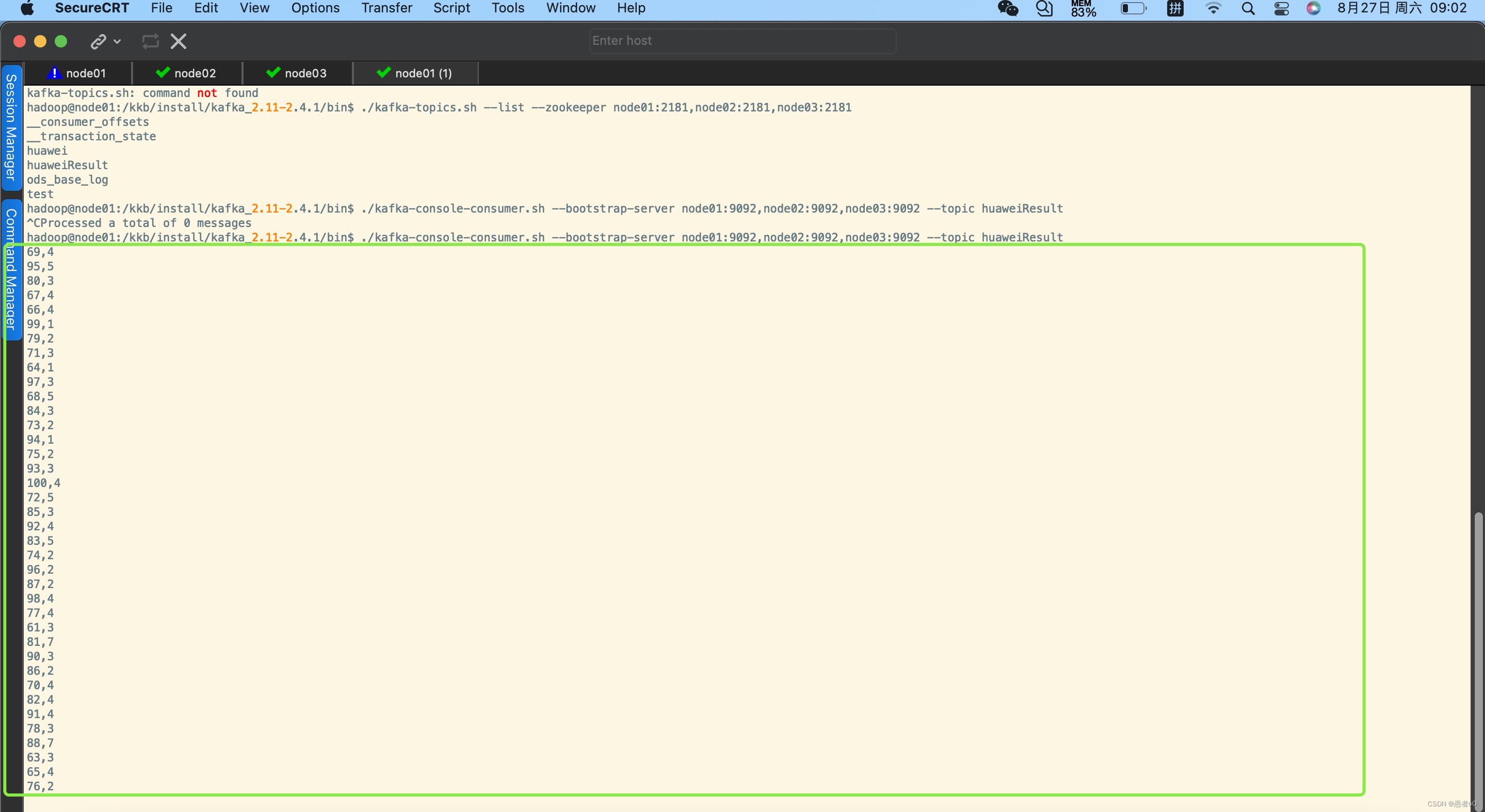
统计数据可正常插入
大功告成!!
以上是关于Flink从Kafka消费并统计结果写入Kafka的主要内容,如果未能解决你的问题,请参考以下文章
flinksql从kafka中消费mysql的binlog日志