1-Volcano火山:容器与批量计算的碰撞
Posted 琦彦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了1-Volcano火山:容器与批量计算的碰撞相关的知识,希望对你有一定的参考价值。
1-Volcano火山:容器与批量计算的碰撞
Volcano是基于Kubernetes的一个批处理调度系统,它为大数据、机器学习以及HPC等多种工作负载提供了作业生命周期的管理、调度以及资源管理一系列的功能,能够帮助弹性的工作负载以及批处理的工作负载更好的运行在云原生的环境里,同时能够提高性能、降低成本。
Volcano项目背景
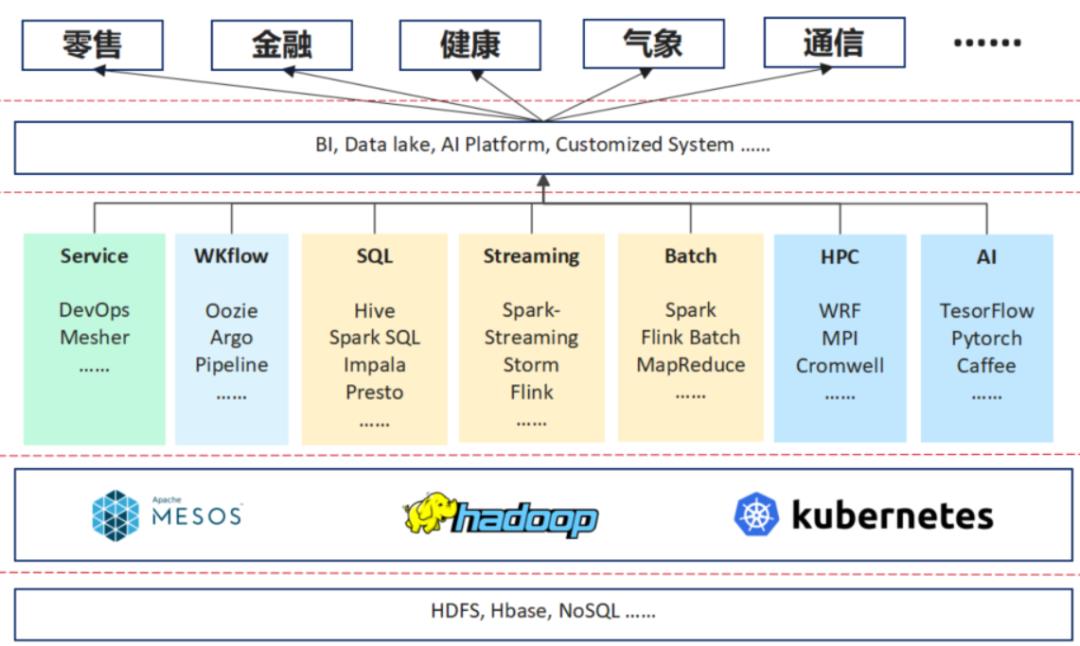
上图是我们做的一个分析,我们将其分为三层,最下面为资源管理层,中间为领域的框架,包括AI的体系、HPC、Batch, WKflow的管理以及像现在的一些微服务及流量治理等。再往上是行业以及一些行业的应用。
随着一些行业的应用变得复杂,它对所需求的解决方案的要求也越来越高。举个例子在10多年以前,在金融行业提供解决方案时,它的架构是非常简单的,可能需要一个数据库,一个ERP的中间件,就可以解决银行大部分的业务。
而现在,每天要收集大量的数据,需要spark去做数据分析,甚至需要一些数据湖的产品去建立数据仓库,然后去做分析,产生报表。同时它还会用 AI的一些系统,来简化业务流程等。
因此,现在的一些行业应用与10年前比,变得很复杂,它可能会应用到下面这些领域框架里面的一个或多个。其实对于行业应用,它的需求是在多个领域框架作为一个融合,领域框架的诉求是下面的资源管理层能够提供统一的资源管理。
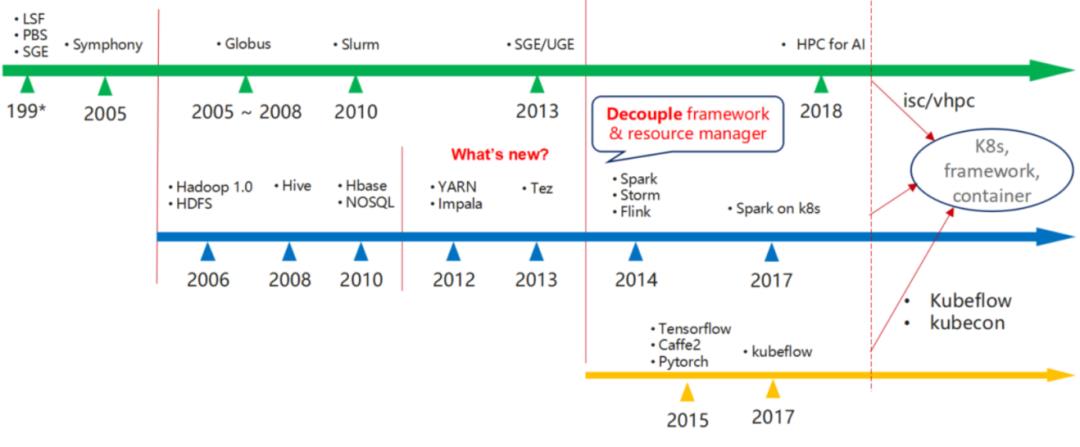
Kubernetes现在越来越多的承载了统一的资源管理的角色,它可以为 HPC这些行业领域框架提供服务,也可以作为大数据领域的资源管理层。Volcano主要是基于Kubernetes做的一个批处理系统,希望上层的HPC、中间层大数据的应用以及最下面一层AI能够在统一Kubernetes上面运行的更高效。
当前容器技术的使用已经非常广泛,相对于虚拟机来讲,它提供了更好的资源使用效率,可以实现秒级扩缩容,最重要的一点就是它解决了生产、开发、测试三个环境的统一,提供了一致性的运行环境。CNCF 2019年的调查数据也显示,容器在生产环境里面的应用增加了200%,在评估中的增加了接近400%,有40%的受访企业其实表示他们在生产环节里面一些正在使用Kubernetes。


虽然说容器已经成为批量计算场景的下一代基础设施层,越来越多的用户也开始把集群类任务迁移到Kubernetes平台上来。但当我们真正去做一些深度迁移的时候,发现存在很多问题。在调度上,Kubernetes很多方面还需要增强。目前的Kubernetes对于调度还是以Pod为单位,但是在批量计算的场景默认都是以作业为彼此去做调度,所以在调度上,其实还有很多地方需要加强的。
另外一个就是关于公平调度,我们知道其实在批量计算的场景,一般都是有队列的,多个作业之间,如何去共享使用集群资源,需要有公平调度的策略。举个简单的例子,如流媒体作业,多个作业在一个队列里面同时竞争资源的话,我们必须要提供公平调度的这机制,保证每一个流媒体的作业。
面临的**第二个挑战是目前Kubernetes在作业管理方面的功能其实还是有所欠缺。**我们知道Kubernetes下面有一个bach,bach下面有job。目前job提供的一些功能,无法描述像AI这类型比较复杂的作业。
第三个挑战在数据管理方面,我们知道在数据管理方面有一个典型的spark的Shuffle Service,他如何和Kubernetes比较好的去做集成?怎样去管理这些数据?当存储和计算分离以后,怎样设计计算测的缓存?
第四个挑战是在混合部署以及批量计算的场景里面,都有资源共享、分时共享。分时错峰可以通过调度器来解决,但资源回收问题就是Reclaim机制需要增强的。
**最后一个面临的挑战是现在的异构硬件越来越多,**各个厂家都有自己的硬件,如何通过统一的平台去管理这么多种的计算资源,实现计算的加速。

以上这些挑战都是Volcano试图去解决的问题。
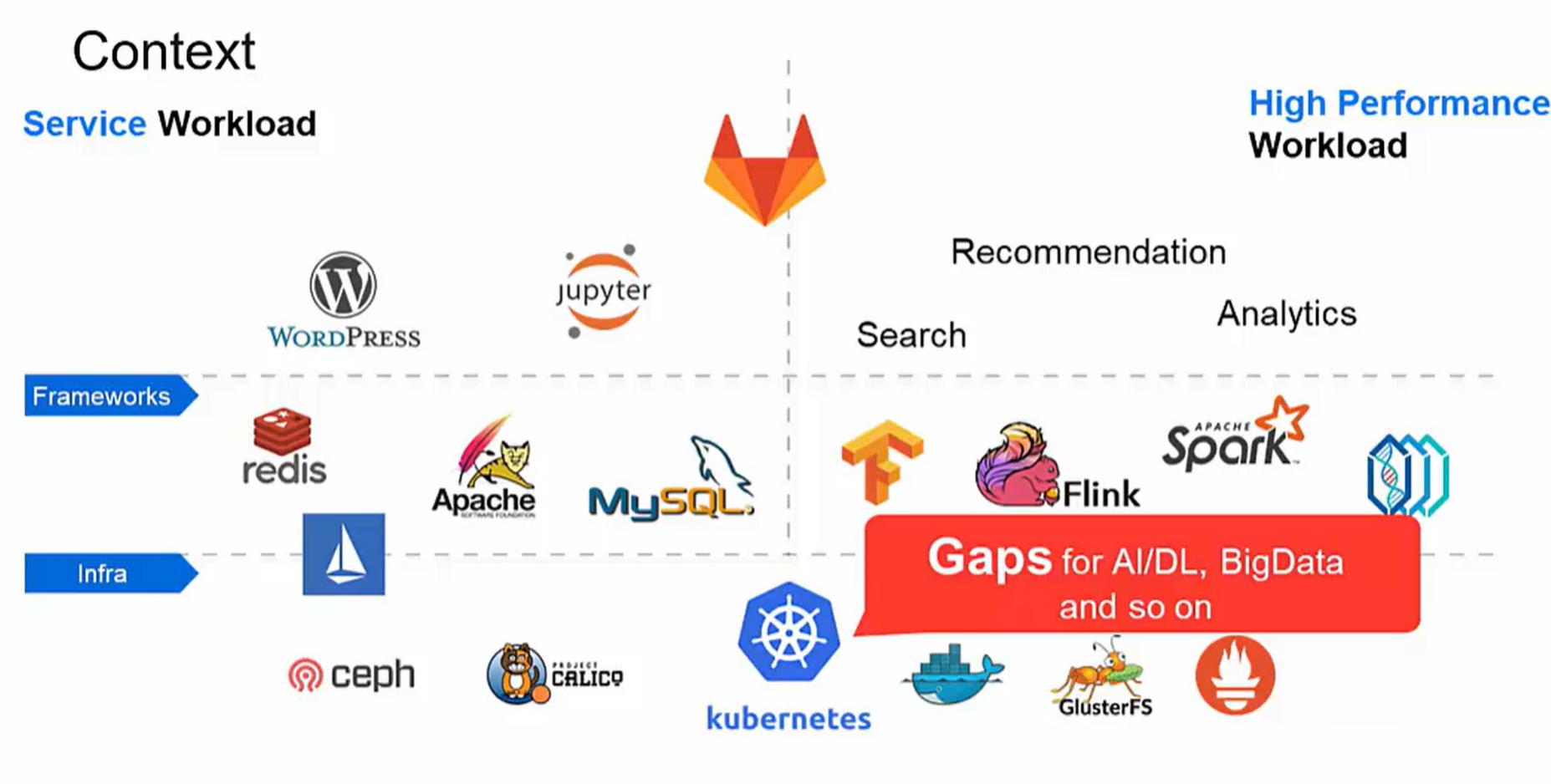
Kubernetes 是当前非常流行的容器编排框架,在其发展早期重点以微服务类应用为主。
但随着Kuberentes的用户越来越多,更多的用户希望在Kubernetes上运行BigData和AI框架,如Spark、TensorFlow等以构建统一的容器平台。但在Kubernetes运行这些高性能应用时,**Kubernetes的默认调度器无法满足高性能应用的需求,例如:公平调度、优先级、队列等高级调度功能。**由于Kubernetes的默认调度器是基于Pod进行调度,虽然在1.17中引入了调度框架,但仍无法满足高性能应用对作业级调度的需求。
针对云原生场景下的高性能应用场景,华为云容器团队推出了Volcano项目。Volcano是基于Kubernetes构建的一个通用批量计算系统,它弥补了Kubernetes在“高性能应用”方面的不足,支持TensorFlow、Spark、MindSpore等多个领域框架,帮助用户通过Kubernetes构建统一的容器平台。Volcano作为容器调度系统,不仅包括了作业调度,还包含了作业生命周期管理、多集群调度、命令行、数据管理、作业视图及硬件加速等功能。
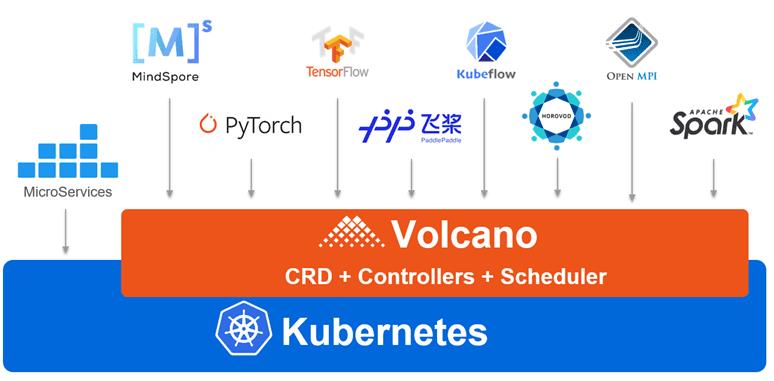
并行计算
而在调度方面,Volcano 又对场景进行了细分、归类,并提供了相关的方案及算法;同时也为这些功能提供了调度框架,方便用户对调度器进行扩展。对于分布式计算或是并行计算来说,根据场景和作业属性的不同,也可以对其进行细分;在 《并行计算导论》 中将并行计算大致分为三类:
1. 简单的并行
简单的并行指多个子任务(tasks)之间没有通信也不需要同步,可以完全的并行的执行。比较著名的例子应该就属MapReduce了,它的两个阶段都属于这种类型:mapper任务在执行时并不会彼此通信同步运行状态;另一个常见的例子是蒙特·卡罗方法 ,各个子任务在计算随机数时也无需彼此通信、同步。由于这种并行计算有比较广泛的应用,例如 数据处理、VatR 等,针对不同的场景也产生了不同的调度框架,例如 Hadoop、DataSynapse 和 Symphony。同时,由于子任务之间无需信息和同步,当其中某几个计算节点(workers)被驱逐后,虽然作业的执行时间可能会变长,但整个作业仍可以顺利完成;而当计算节点增加时,作业的执行时间一般都会缩短。因此,这种作业也常常被称作 Elastic Job。
2. 复杂的并行
复杂的并行作业指多个子任务 (tasks) 之间需要同步信息来执行复杂的并行算法,单个子任务无法完成部分计算。最近比较有名的例子应该算是 Tensorflow 的 “ps-work模式” 和 ring all-reduce 了,各个子任务之间需要大量的数据交换和信息同步,单独的子任务无法独立完成。正是由于作业的这种属性,对作业调度平台也提出了相应的调度要求,比如 gang-scheduling、作业拓扑等。由于子任务之间需要彼此通信,因此作业在启动后无法动态扩展子任务,在没有checkpoint的情况下,任一子任务失败或驱逐,整个作业都需要重启,这种作业也常常被称作 Batch Job,传统的HPC场景多属于这种类型的并行作业,针对这种场景的调度平台为 Slurm/PBS/SGE/HTCondor 等。
3. 流水线并行
流水线并行是指作业的多个子任务之间存在依赖关系,但不需要前置任务完全结束后再开始后续的任务;比如 Hadoop 里有相应的研究:在 Map 没有完全结束的时候就部分开始 Reduce 阶段,从而提高任务的并行度,提高整体的运行性能。符合这种场景的应用相对来说比较少,一般都做为性能优化;因此没有针对这种场景的作业管理平台。需要区分一下工作流与流水线并行,工作流一般指作业之间的依赖关系,而流水线并行一般指作业内部多个任务之间的依赖。由于工作流中的作业差异比较大,很难提前开始后续步骤。
值得一提的是"二次调度"。由于简单并行的作业一般会有大量的子任务,而且每个子任务所需要的资源相对一致,子任务之间也没有通信和同步;使得资源的复用率相对比较高,因此二次调度在这种场景下能发挥比较大的作用;**Hadoop的YARN,Symphony的EGO都属于这种类型。**但是在面对复杂并行的作业时,二次调度就显得有也吃力;复杂并行作业一般并没有太多的子任务,子任务之间还经常需要同时启动,子任务之间的通信拓扑也可能不同 (e.g. ps/worker, mpi),而且作业与作业之间对资源的需求差异较大,因此导致了资源的复用率较低。
虽然针对两种不同并行作业类型有不同的作业、资源管理平台,但是根本的目标都是为作业寻找最优的资源;因此,Volcano一直以支持以多种类型的作业为目标进行设计。目前,Volcano可以同时支持 Spark、TensorFlow和MPI等多种类型的作业。
常见调度场景
1. 组调度 (Gang-scheduling)
运行批处理作业(如Tensorflow/MPI)时,**必须协调作业的所有任务才能一起启动;**否则,将不会启动任何任务。如果有足够的资源并行运行作业的所有任务,则该作业将正确执行;但是,在大多数情况下,尤其是在prem环境中,情况并非如此。在最坏的情况下,由于死锁,所有作业都挂起。其中每个作业只成功启动了部分任务,并等待其余任务启动。
2 . 作业级的公平调度 (Job-based Fair-share)
当运行多个弹性作业(如流媒体)时,需要公平地为每个作业分配资源,以满足多个作业竞争附加资源时的SLA/QoS要求。在最坏的情况下,单个作业可能会启动大量的pod资源利用率低, 从而阻止其他作业由于资源不足而运行。为了避免分配过小(例如,为每个作业启动一个Pod),弹性作业可以利用协同调度来定义应该启动的Pod的最小可用数量。超过指定的最小可用量的任何pod都将公平地与其他作业共享集群资源。
3. 队列 (Queue)
队列还广泛用于共享弹性工作负载和批处理工作负载的资源。队列的主要目的是:
- 在不同的“租户”或资源池之间共享资源
- 为不同的“租户”或资源池支持不同的调度策略或算法
这些功能可以通过层次队列进一步扩展,在层次队列中,项目被赋予额外的优先级,这将允许它们比队列中的其他项目“跳转”。在kube批处理中,队列被实现为集群范围的CRD。这允许将在不同命名空间中创建的作业放置在共享队列中。队列资源根据其队列配置(kube batch#590)按比例划分。当前不支持分层队列,但正在进行开发。
集群应该能够在不减慢任何操作的情况下处理队列中的大量作业。其他的HPC系统可以处理成百上千个作业的队列,并随着时间的推移缓慢地处理它们。如何与库伯内特斯达成这样的行为是一个悬而未决的问题。支持跨越多个集群的队列可能也很有用,在这种情况下,这是一个关于数据应该放在哪里以及etcd是否适合存储队列中的所有作业或pod的问题。
4. 面向用户的, 跨队列的公平调度 (Namespace-based fair-share Cross Queue)
在队列中,每个作业在调度循环期间有几乎相等的调度机会,这意味着拥有更多作业的用户有更大的机会安排他们的作业,这对其他用户不公平。例如,有一个队列包含少量资源,有10个pod属于UserA,1000个pod属于UserB。在这种情况下,UserA的pod被绑定到节点的概率较小。
为了平衡同一队列中用户之间的资源使用,需要更细粒度的策略。考虑到Kubernetes中的多用户模型,使用名称空间来区分不同的用户, 每个命名空间都将配置一个权重,作为控制其资源使用优先级的手段。
5. 基于时间的公平调度 (Fairness over time)
对于批处理工作负载,通常不要求在某个时间点公平地分配资源,而是要求在长期内公平地分配资源。例如,如果有用户提交大作业,则允许用户(或特定队列)在一定时间内使用整个集群的一半, 这是可以接受的,但在下一轮调度(可能是作业完成后数小时)中,应惩罚此用户(或队列)而不是其他用户(或队列)。在 HTCondor 中可以看到如何实现这种行为的好例子。
6. 面向作业的优先级调度 (Job-based priority)
Pod优先级/抢占在1.14版本中被中断,它有助于确保高优先级的pod在低优先级的pod之前绑定。不过,在job/podgroup级别的优先级上仍有一些工作要做,例如高优先级job/podgroup应该尝试以较低优先级抢占整个job/podgroup,而不是从不同job/podgroup抢占几个pod。
7. 抢占 (Preemption & Reclaim)
通过公平分享来支持借贷模型,一些作业/队列在空闲时会过度使用资源。但是,如果有任何进一步的资源请求,资源“所有者”将“收回”。资源可以在队列或作业之间共享:回收用于队列之间的资源平衡,抢占用于作业之间的资源平衡。
8. 预留与回填 (Reservation & Backfill)
当一个请求大量资源的“巨大”作业提交给kubernetes时,当有许多小作业在管道中时,该作业可能会饿死,并最终根据当前的调度策略/算法被杀死。为了避免饥饿, 应该有条件地为作业保留资源,例如超时。当资源被保留时,它们可能会处于空闲和未使用状态。为了提高资源利用率,调度程序将有条件地将“较小”作业回填到那些保留资源中。保留和回填都是根据插件的反馈触发的:volcano调度器提供了几个回调接口,供开发人员或用户决定哪些作业应该被填充或保留。
Volcano总体架构
将从几个方面介绍Volcano的总体架构。我们看到这个图里,所有的蓝色的部分是Kubernetes自身的组件,绿色的部分则是Volcano新添加的组件。
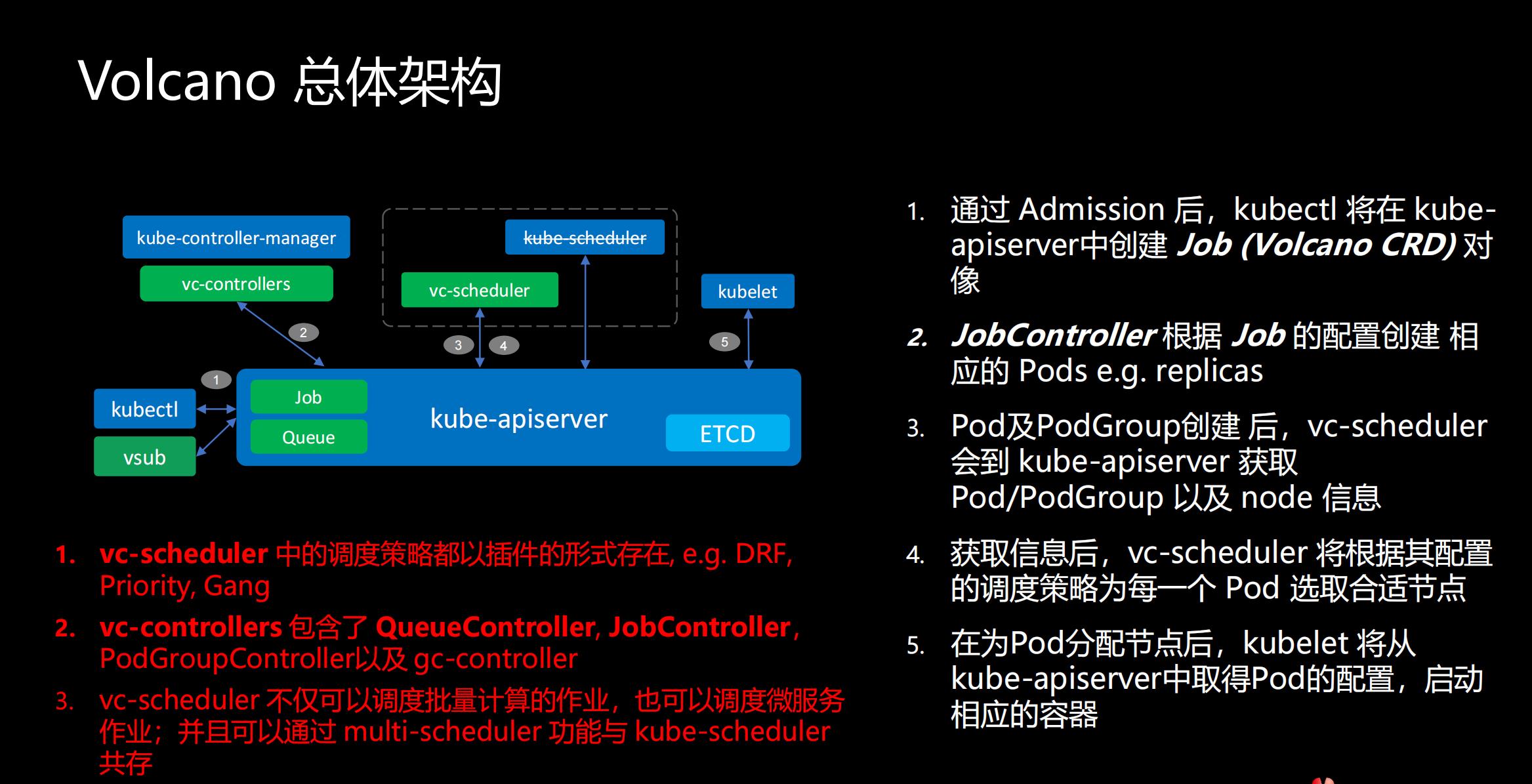
作业提交流程:
1)通过 Admission 后,kubectl 将在 kube-apiserver中创建 Job (Volcano CRD) 对象
2)JobController 根据 Job 的配置创建 相应的 Pods e.g. replicas
3)Pod及PodGroup创建 后,vc-scheduler 会到 kube-apiserver 获取Pod/PodGroup 以及 node 信息
4)获取信息后,vc-scheduler 将根据其配置的调度策略为每一个 Pod 选取合适节点
5)在为Pod分配节点后,kubelet 将从kube-apiserver中取得Pod的配置,启动相应的容器
需要强调的几点:
● vc-scheduler 中的调度策略都以插件的形式存在, e.g. DRF, Priority, Gang
● vc-controllers 包含了 QueueController, JobController,PodGroupController 以及 gc-controller
● vc-scheduler 不仅可以调度批量计算的作业,也可以调度微服务作业;并且可以通过 multi-scheduler 功能与 kube-scheduler 共存
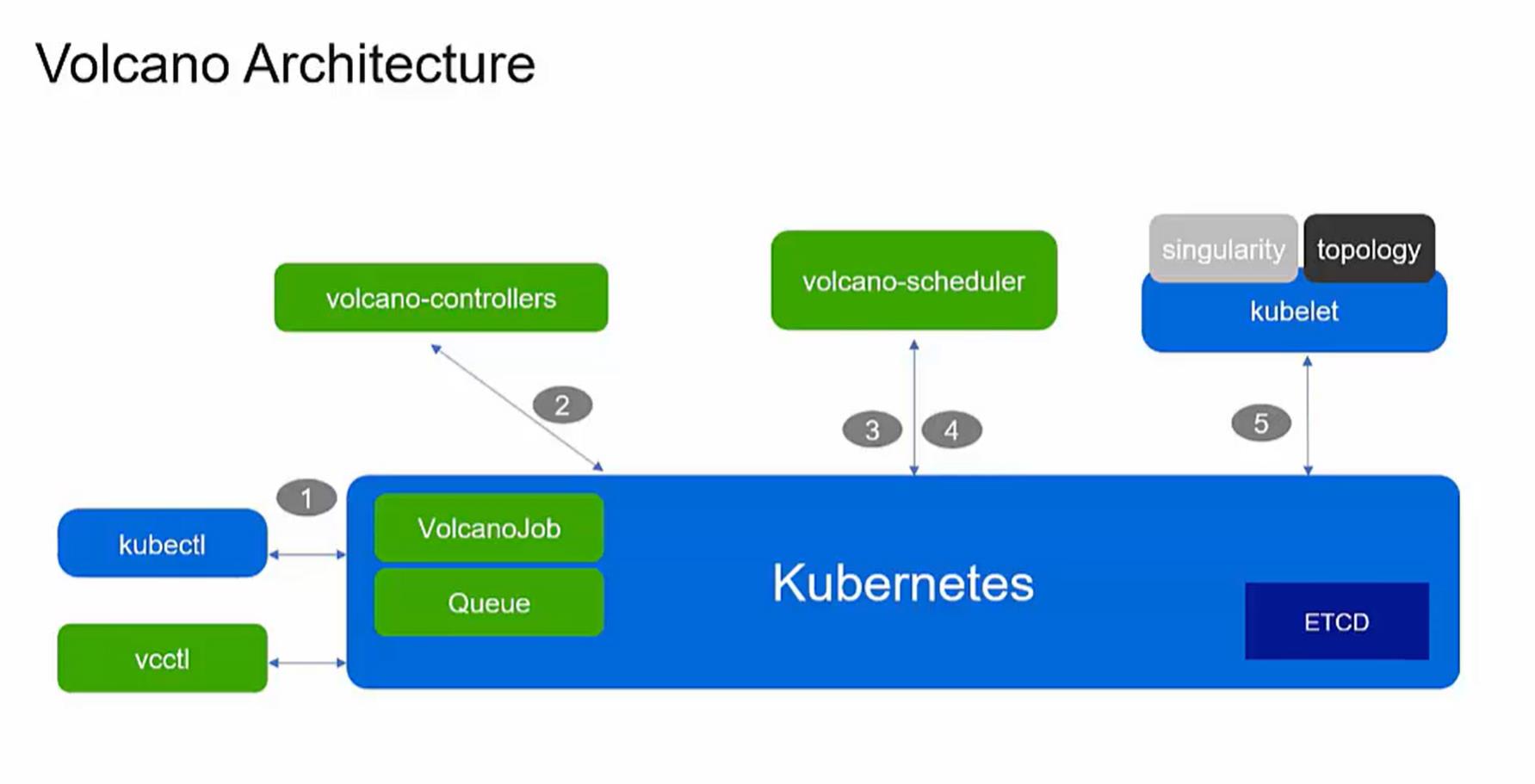
Volcano的设计其实得益于Kubernetes自身良好的可扩展性。Kubernetes支持多调度器,多调度器的支持,可以实现定制schedule,还支持自定义对象。Volcano在这里面创建了Job和Queue两种对象,也新添了vc-controllers,用于管理 Job和Queue的生命周期。同时Volcano还写了vsub命令行,可以兼容传统HPC应用。
右边的整个workflow,跟Kubernetes是非常接近的。我们通过命令行创建Volcano的 job,job-controller会根据不同的配置信息创建一批pod。下一步Volcano的schedule会从api-setver里面拿到这些pod以及关于调度相关的信息,根据用户配置的调度策略,去帮助pod去寻找一个最佳的node,后面的整个步骤交给kubelet主导。
在整个过程中有几点需要强调:
- Volcano的schedule支持多种调度策略,是通过插件的方式去提供。用户他可以自由配置插件,插件的机制是非常灵活的。
- vc-controllers里包含了QueueController, JobController,PodGroupController以及 gc-controller,生命周期的管理都在这里面完成。
- vc-scheduler 不仅可以调度批量计算的作业,也可以调度微服务作业;并且可以通过 multi-scheduler 功能与 kube-scheduler 共存。

Queue/Job Controller 总体架构
在这个图里面我们看到分左侧和右侧两部分。
- 左侧就是我们刚才说的Volcano的Job Controller,作业管理、生命周期管理、错误处理都是在左边的这一部分;
- 右侧是有些用户或者社区有自己的crd job,和Volcano的schedule集成走的就是右边这个流程。
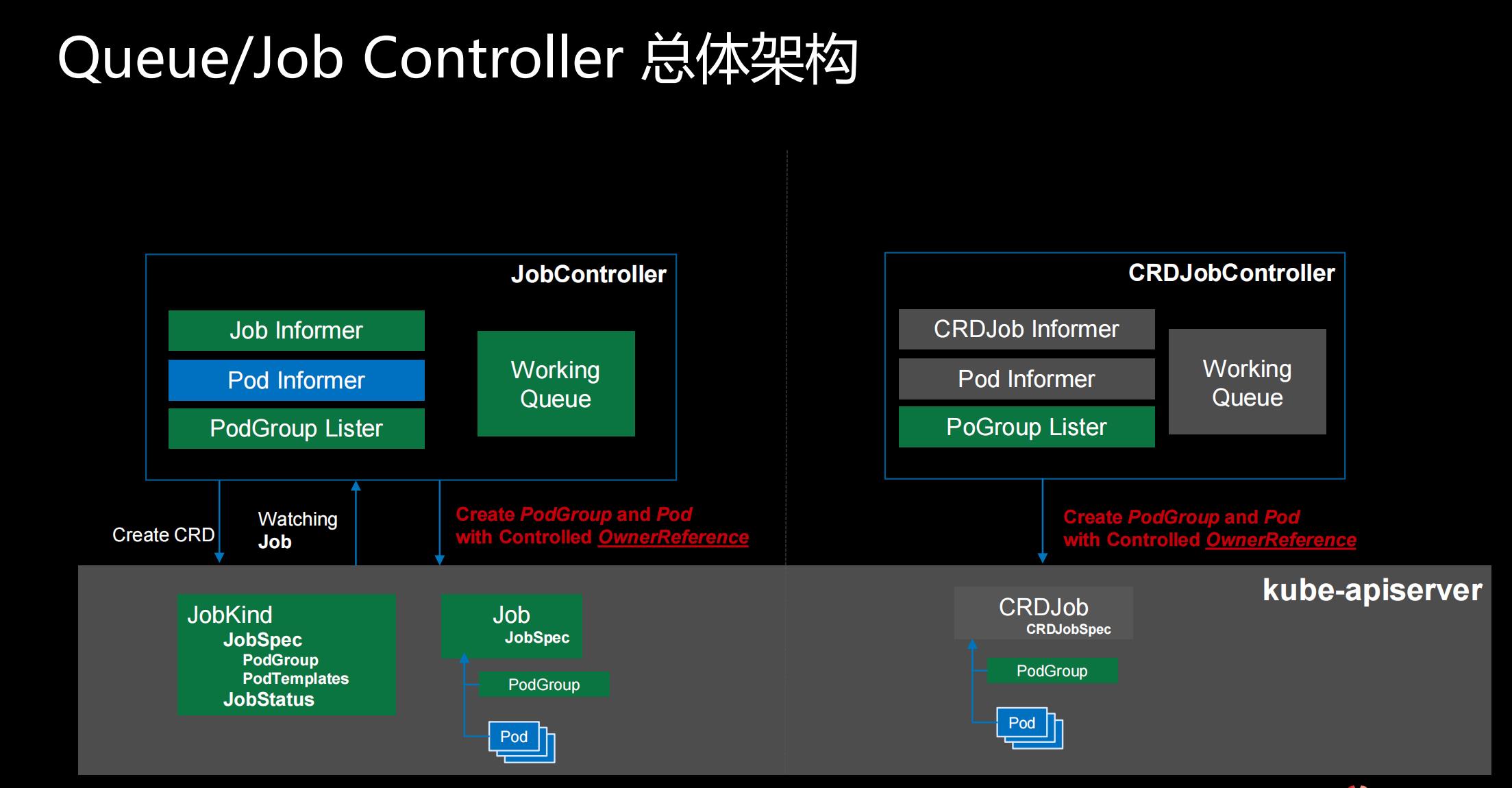
左边为Volcano Job Controller,不只调度使用的Volcano,Job的生命周期管理、作业管理都在这里面包含。我们提供了统一的作业管理,你只要使用Volcano,也不需要创建各种各样的操作,就可以直接运行作业。
右边为CRD Job Controller,通过下面的PodGroup去做集成。
我们来先看一下左侧的架构。在这个Controller里面,有Job Informer监听命令行创建的Volcano的job,监听到事件之后,会两创建pod 和 podgroup两种资源,podgroup我们新加的一个概念,它会会把调度相关的信息都给transfer到podgroup,然后通过podgroup再下放给schedule。通过这一系列的工作之后,在kube-apiserver里面我们就会看到job、pod以及podgroup的一些信息。这个时候schedule就会拉取pod和podgroup的信息去去进行调度的整个过程。右边其实也是非常类似的 。
在这里需要强调的是,在设计之初我们就把 job和podgroup两个概念分开。
所有跟作业相关的信息,都是放在 job里面;所有跟调度相关的信息都放在podgroup里面,这个设计与Kubernetes非常相像。
Scheduler 总体架构
介绍完了Controller之后,我们介绍一下 Schedule,虚线框里面就是我们整个 Schedule的部分。
整个 Schedule的架构分三层:首先是左边的cache,cache是整个资源的封装,它会从kube-apiserver里面拉取跟调度相关的信息,组装成 job,这里面我们叫jobinfo;第二部分就是中间这一块,每个调度是分调度周期的,创建session的时候,会把上一部分的信息做snapshot,同时把右边(第三部分)的plugin所注册的call back函数加载进来,session所有东西准备好了,我们就可以开始进入调度的整个流程。
Volcano调度器通过作业级的调度和多种插件机制来支持多种作业;Volcano的插件机制有效的支撑了针对不同场景算法的落地,从早期的gang-scheduling/co-scheduling,到后来各个级别的公平调度。
下图展示了Volcano调度器的总体架构:
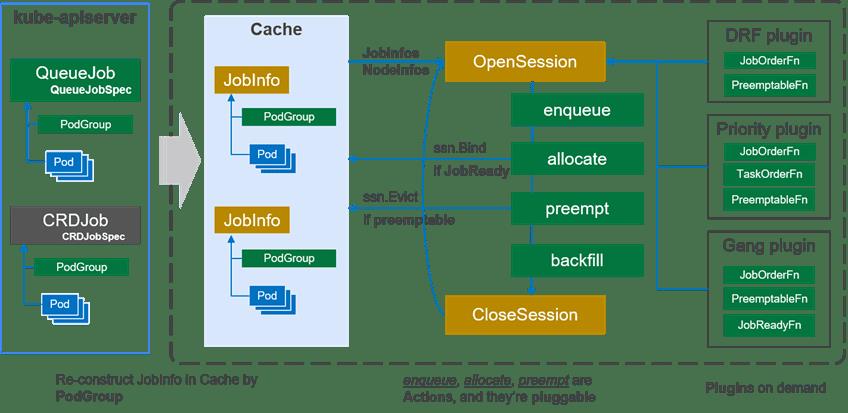
Scheduler支持动态配置和加载。
左边为apiserver,右边为整个Scheduler。
apiserver里有Job、Pod、Pod Group;
Scheduler分为三部分,第一层为Cache,中间层为整个调度的过程,右边是以插件形式存在的调度算法。
Cache会将apiserver里创建的Pod、Pod Group这些信息存储并加工为Jobinfors。
中间层的OpenSession会从Cache里拉取Pod、Pod Group,同时将右边的算法插件一起获取,从而运行它的调度工作。
Cache 缓存了集群中Node和Pod信息,并根据PodGroup的信息重新构建 Job (PodGroup) 和 Task (Pod) 的关系。由于在分布式系统中很难保证信息的同步,因此调度器经常以某一时间点的集群快照进行调度;并保证每个调度周期的决定是一致的。在每个调度周期中,Volcano 通过以下几个步骤派发作业:
**1、****在每个调度周期都会创建一个Session对象,用来存储当前调度周期的所需的数据,**例如,Cache 的一个快照。当前的调度器中仅创建了一个Session,并由一个调度线程执行;后续将会根据需要创建多个Session,并为每个Session分配一个线程进行调度;并由Cache来解决调度冲突。
**2、**在每个调度周期中,会按顺序执行 OpenSession, 配置的多个动作(action)和CloseSession。在 OpenSession中用户可以注册自定义的插件,例如gang、 drf,这些插件为action提供了相应算法;多个action根据配置顺序执行,调用注册的插件进行调度;最后,CloseSession负责清理中间数据。
-
action是第一级插件,定义了调度周期内需要的各个动作;默认提供 enqueue、allocate、 preempt和backfill四个action。以allocate为例,它定义了调度中资源分配过程:根据 plugin 的 JobOrderFn 对作业进行排序,根据NodeOrderFn对节点进行排序,检测节点上的资源是否满足,满足作业的分配要求(JobReady)后提交分配决定。由于action也是基于插件机制,因此用户可以重新定义自己的分配动作,例如 基于图的调度算法firmament。
-
plugin是第二级插件,定义了action需要的各个算法;以drf插件为例,为了根据dominant resource进行作业排序,drf插件实现了 JobOrderFn函数。JobOrderFn函数根据 drf 计算每个作业的share值,share值较低代表当前作业分配的资源较少,因此会为其优先分配资源;drf插件还实现了EventHandler回调函数,当作业被分配或抢占资源后,调度器会通知drf插件来更新share值。
**3、****Cache 不仅提供了集群的快照,同时还提供了调度器与kube-apiserver的交互接口,**调度器与kube-apiserver之间的通信也都通过Cache来完成,例如 Bind。
Task/Pod 状态转换
第三部分我想介绍一下Task/Pod 状态转换。蓝色的部分是Kubernetes自己的一些pod状态,其他则是我们新添加的状态。
这里面我们简单看一下, Allocated、Pipelined这两个绿色的部分是一个session级别的状态,就是说当我跨了调度周期之后,session的数据就被清掉了,所以它是在一个调度周期之内有用的状态。黄色的Binding、Bound以及Releasing这三个部分存放在cache里边,可以跨调度周期,即便发生了重启,状态还是可以维护住。 蓝色部分为K8s自带的状态。
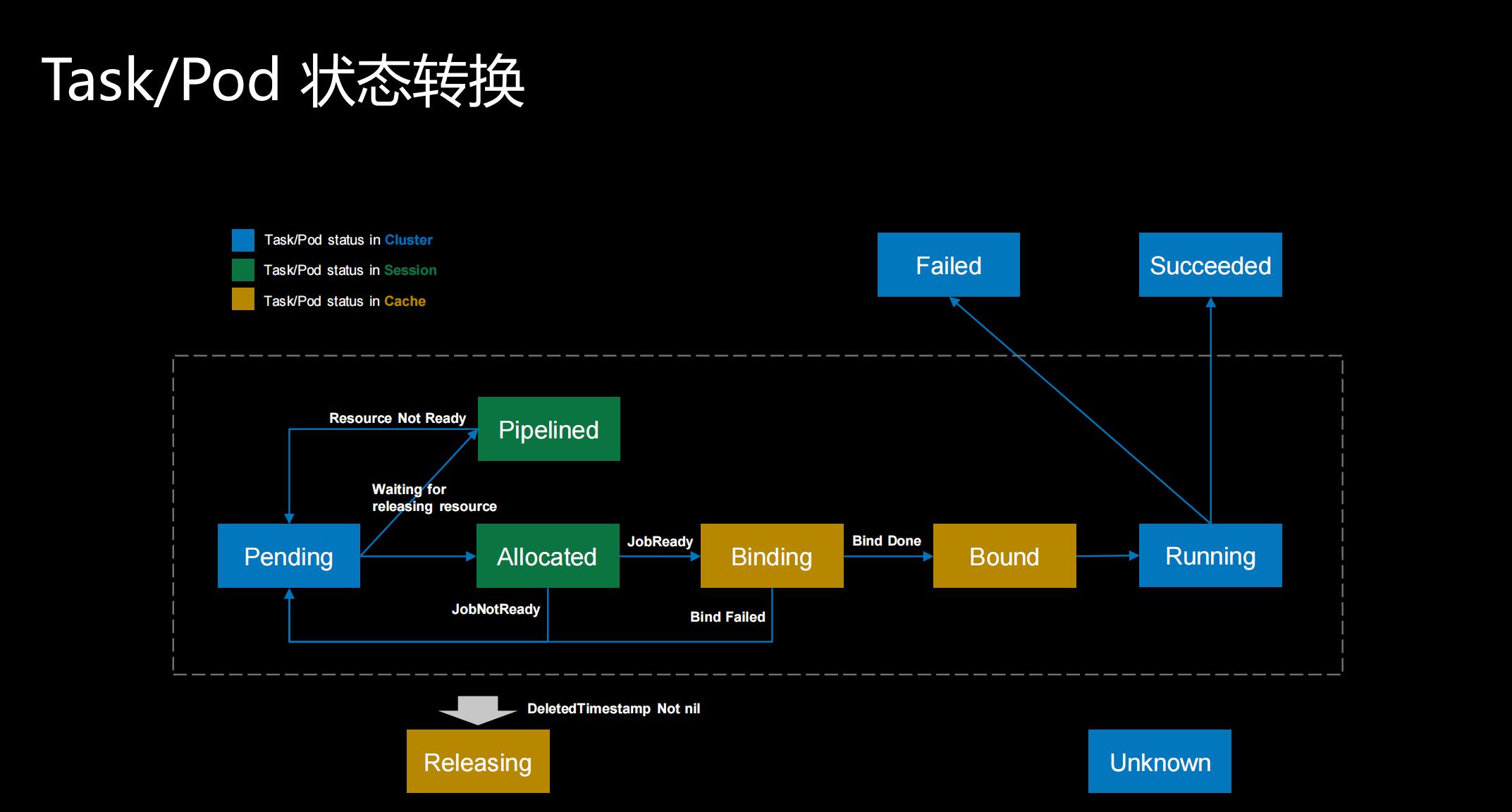
同时,为了支持上面这些场景,Volcano的调度器还增加了多个Pod状态以提高调度的性能:
- Pending: 当Pod被创建后就处于Pending状态,等待调度器对其进行调度;调度的主要目的也是为这些Pending的Pod寻找最优的资源
- Allocated: 当Pod被分配空闲资源,但是还没有向kube-apiserver发送调度决策时,Pod处于Allocated状态。Allocated状态仅存在于调度周期内部,用于记录Pod和资源分配情况。当作业满足启动条件时 (e.g. 满足minMember),会向kube-apiserver提交调度决策。如果本轮调度周期内无法提交调度决策,由状态会回滚为Pending状态。(相当于 default scheduler 中Assume状态)
- Pipelined: 该状态与Allocated状态相似,区别在于处**于该状态的Pod分配到的资源为正在被释放的资源 (Releasing)。**该状态主要用于等待被抢占的资源释放。该状态是调度周期中的状态,不会更新到kube-apiserver以减少通信,节省kube-apiserver的qps。
- Binding: 当作业满足启动条件时,调度器会向kube-apiserver提交调度决策,在kube-apiserver返回最终状态之前,Pod一直处于Binding状态。该状态也保存在调度器的Cache之中,因此跨调度周期有效。
- Bound: 当作业的调度决策在kube-apiserver确认后,该Pod即为Bound状态。
- Releasing: Pod等待被删除时即为Releasing状态。
- Running, Failed, Succeeded, Unknown: 与Pod的现有含义一致。
状态之间根据不同的操作进行转换,见下图。
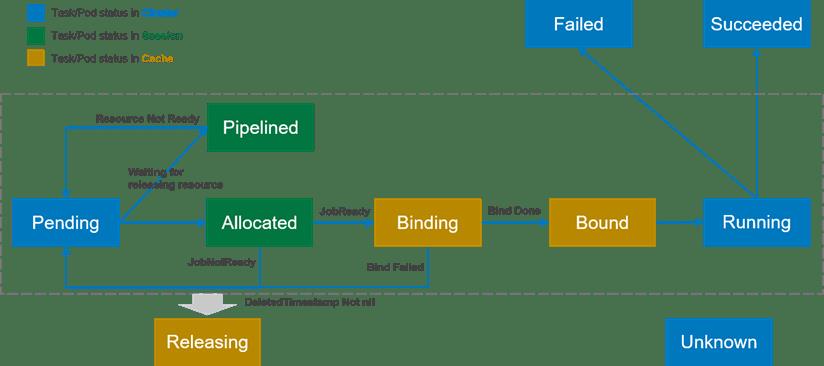
**Pod的这些状态为调度器提供了更多优化的可能。例如,当进行Pod驱逐时,驱逐在Binding和Bound状态的Pod要比较驱逐Running状态的Pod的代价要小 (思考:还有其它状态的Pod可以驱逐吗?);并且状态都是记录在Volcano调度内部,减少了与kube-apiserver的通信。但目前Volcano调度器仅使用了状态的部分功能,比如现在的preemption/reclaim仅会驱逐Running状态下的Pod;**这主要是由于分布式系统中很难做到完全的状态同步,在驱逐Binding和Bound状态的Pod会有很多的状态竞争。
Volcano调度实现
Volcano调度器在支持上面这些主要场景时,分别使用了action和plugin两级插件。
总体来讲,带有动作属性的功能,一般需要引入 action 插件;带有选择 (包括排序) 属性的功能,一般使用 plugin 插件。因此,这些常见场景中,fair-sharing、queue、co-scheduling都通过plugin机制来实现:都带有选择属性,比如“哪些作业应该被优先调度”;而preemption、reclaim、backfill、reserve 则通过 action 机制来实现:都带有动作属性,比如“作业A 抢占 作业B”。
这里需要注意的是,action 与 plugin 一定是一同工作的;fair-sharing 这些 plugin 是借助 allocate 发展作用,而 preemption 在创建新的 action 后,同样需要 plugin 来选择哪些作业应该被抢占。
通过job-based fairness (DRF) 和 preempt 两个功能的实现来介绍action 和 plugin 两种插件机制的使用,其它功能类似:
- Job-based Fairness (DRF): 目前的公平调度是基于DRF,并通过 plugin 插件来实现。在 OpenSession 中会先计算每个作业的 dominant resource和每个作业share的初始值;然后注册 JobOrderFn回调函数,JobOrderFn 中接收两个作业对象,并根据对像的 dominant resource 的 share值对作业进行排序;同时注册EventHandler, 当Pod被分配或抢占资源时,drf根据相应的作业及资源信息动态更新share值。其它插件的实现方案也基本相似,在OpenSession中注册相应的回调,例如 JobOrderFn, TaskOrderFn,调度器会根据回调函数的结果决定如何分配资源,并通过EventHandler来更新插件内的调度数。
- Preemption: preempt是在allocate之后的一个action,它会为“高”优先级的Pending作业选取一个或多个“低”优先级的作业进行驱逐。由于抢占的动作与分配的动作不一致,因此新创建了preempt action来处理相应的逻辑;同时,在选取高低优先级的作业时,preempt action还是依赖相应的plugin插件来实现。其它动作插件的实现方式也类似,即根据需要创建整体的流程;将带有选择属性的问题转换为算法插件。
Volcano主要场景及特性
在功能上面能带来哪些好处?
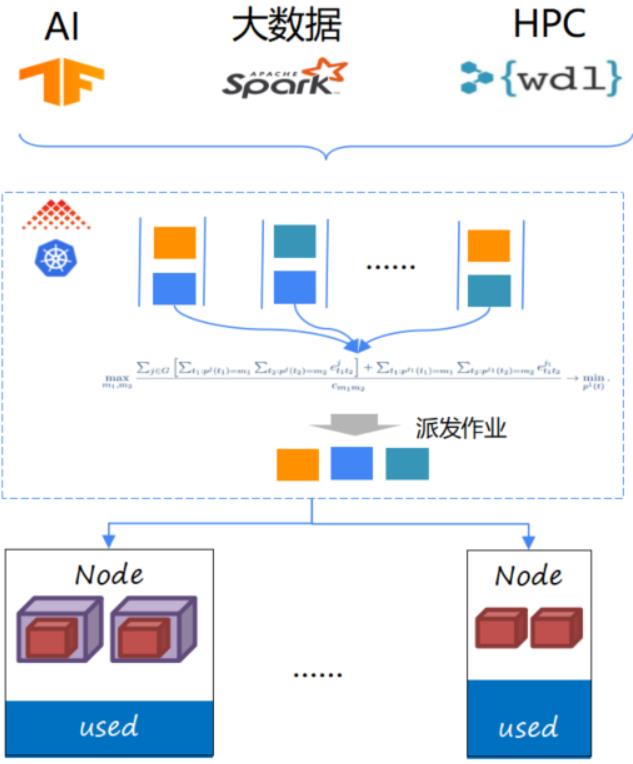
● 支持多种类型作业混合部署
● 支持多队列用于多租户资源共享,资源规划;
● 并分时复用资源
● 支持多种高级调度策略,有效提升整集群资源利用率
● 支持资源实时监控,用于高精度资源调度,例如 热点,网络带宽;容器引擎,网络性能优化, e.g. 免加载
下面大概介绍一下我们主要的场景以及特性。
分布式训练
这里面第一个就是分布式训练场景。在分布式训练里面,做了三组测试,单位是分钟。我们提交了三个case,在集群的资源我们规划是可以满足1 job with 2ps + 4workers的资源需求,但是不能同时满足两个作业的资源需求。
在跑第一个case的时候,因为资源足够,pod的平均运行时长是一样的。第二个case,当提交2个作业,因为资源不够,我们就会发现使用default schedule的平均运行时长是36分钟,Volcano还是24分钟。第三个case直接并发提交5个作业,这个时候我们发现使用 default schedule已经出现了完全的死锁,这个作业根本就跑不完。
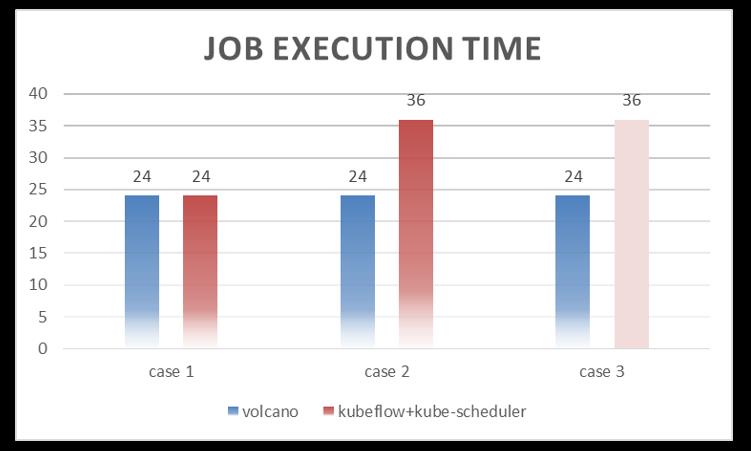
整个测试说明两个问题:
- 没有足够的资源同时运行两个作业; 如果没有 gang-scheduling,其中的一个作业会出现忙等 ;
- 当作业数涨到5后,很大概率出现死锁,一般只能完成2个作业
Task-Topology + Binpack
下边这个场景是Task-Topology的case。我们知道在分布式训练里面,ps和worker两种不同的角色,他们互相之间的数据传输都是不一样的。
这个特性我们考虑的点是如何提升网络的使用率。使用了Volcano Task-Topology之后,测试出的平均时间基本上稳定在185分钟左右。如果使用默认的调度器,非常不稳定。图中abc三种场景,如果运气好的话,如c,和Volcano运行时长差不多,但是运气不好的时候,测出最长会跑到300多分钟。平均值在270分钟左右。
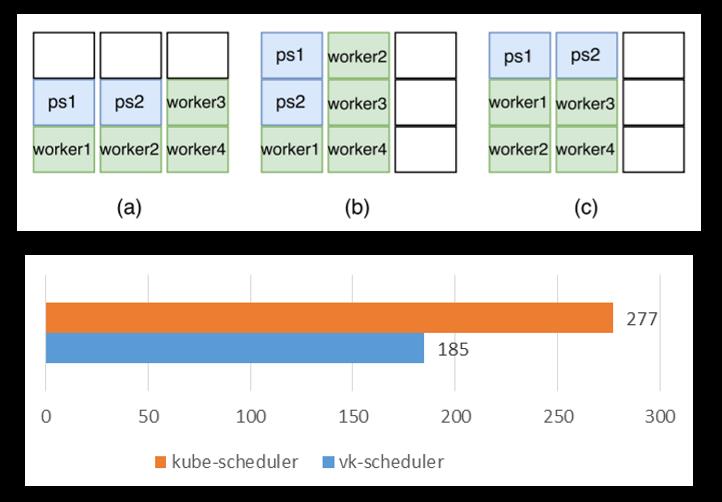
● 3个作业的执行时间总和; 每个作业带2ps + 4workers
● 默认调度器执行时间波动较大
● 执行时间的提高量依据数据在作业中的比例而定
● 减少 Pod Affinity/Anti-Affinity,提高调度器的整体性能
整个测试表明:
- 如果使用Kubernetes的默认调度器,作业的执行时间波动很大
- 作业执行时间受数据传输量影响较大
- 作业内部的亲和与反亲和同样去提高调度器的调度性能
Spark on Kubernetes
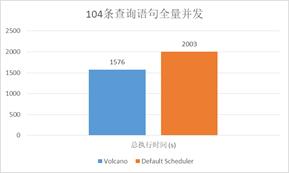
● Spark-sql-perf (TP-DCS, master)
● 104 queries concurrently
● (8cpu, 64G, 1600SSD) * 4nodes
● Kubernetes 1.13
● Driver: 1cpu,4G; Executor: (1cpu,4G)*5
第三个场景是大数据的场景。通过 spark提交104个并发的查询,发现整个作业完全相当于是没有任何进展。Volcano进行增强,在资源预留情况下,整体的性能提升30%。
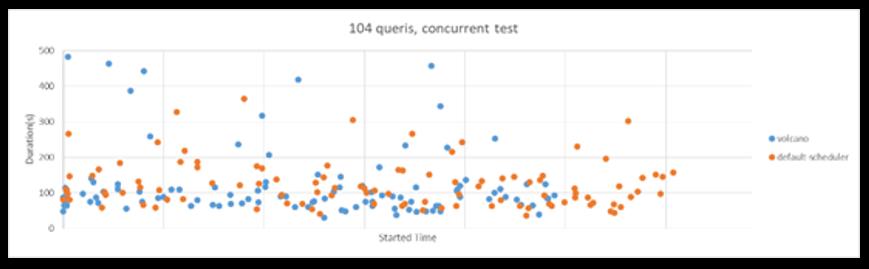
● 如果没有固定的driver节点,最多同时运行 26 条查询语句
● 由于Volcano提供了作业级的资源预留,总体性能提高了~30%
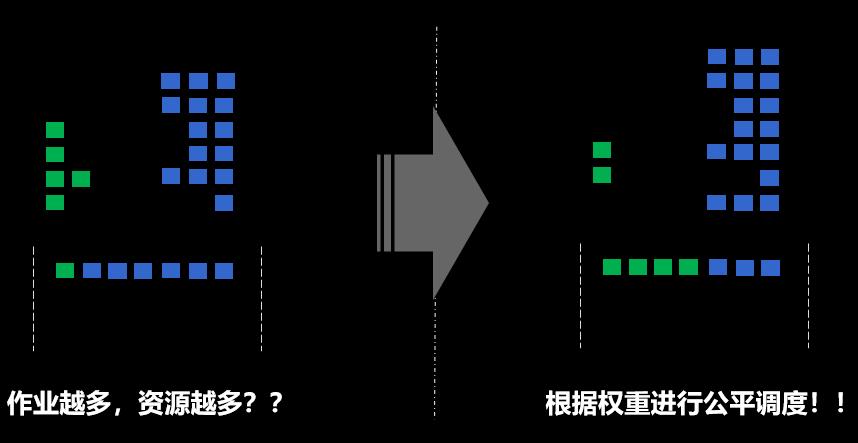
Fair-Share by Job, Namespace, Queue
对于场景四主要是公平调度。在默认Kubernetes里,当用户提交的pod越多,获得资源的概率就会越大但在管理员的角度对于资源的划分,保证不同用户之间的公平性,可以根据不同部门的权重进行资源的调配。
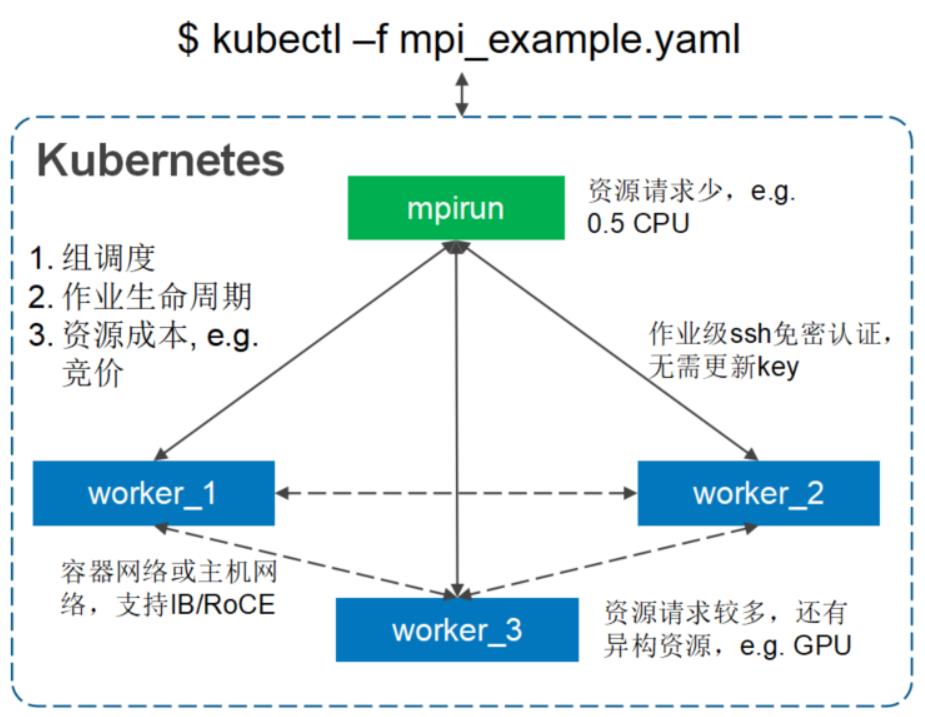
HPC场景—MPI on Volcano
GPU共享特性
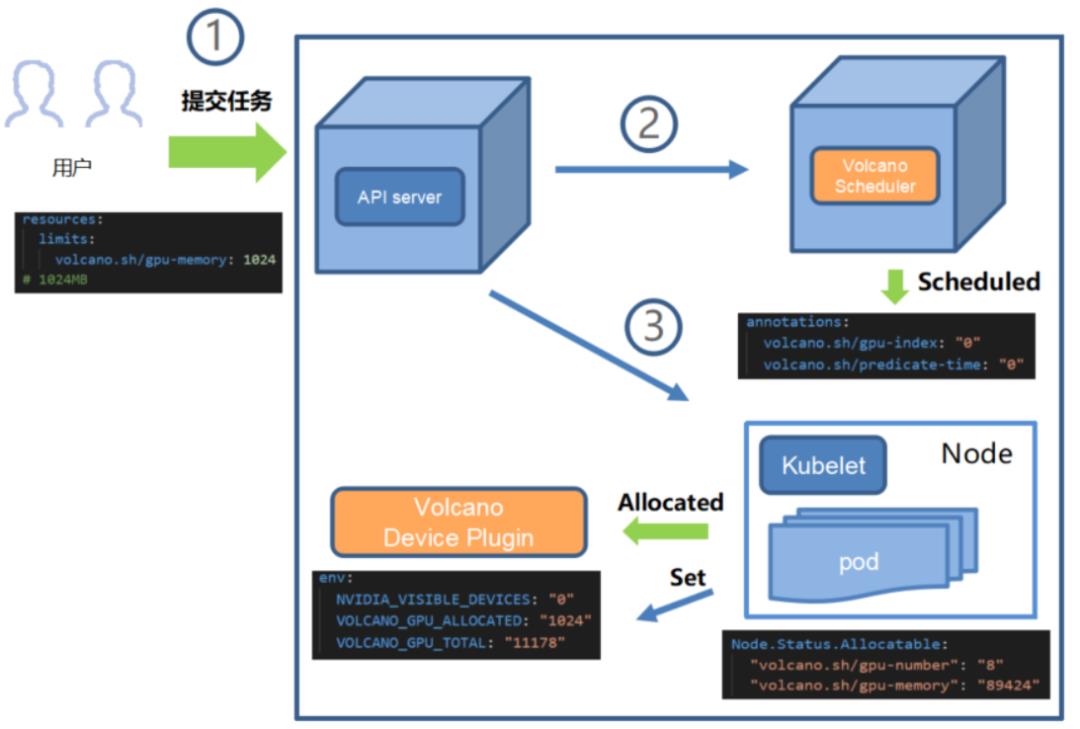
1)算力优化:
- GPU硬件加速,TensorCore
- GPU共享
- 昇腾改造
2)调度算法优化:
- Job/Task模型,提供AI类Job统一批量调度
- 多任务排队,支持多租户/部门共享集群
- 单Job内多任务集群中最优化亲和性调度、Gang Scheduling等
- 主流的PS-Worker、Ring AllReduce等分布式训练模型
3)流程优化
- 容器镜像
- CICD流程
- 日志监控
Volcano可以支持更大规模的一个集群调度,目前是1万个节点百万容器,调度的性能每秒达到2000个Pod。
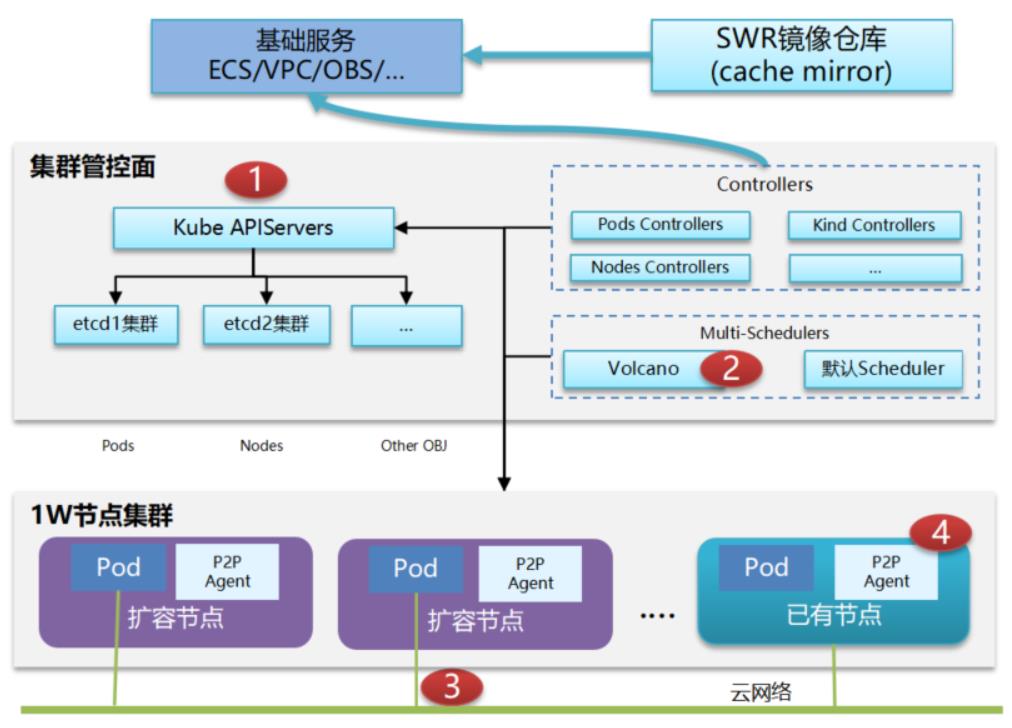
1)编排:
- Etcd 分库分表,e.g. Event 放到单独库,wal/snapshot 单独挂盘
- 通过一致性哈希分散处理,实现 controller-manager 多活
- Kube-apiserver 基于工作负载的弹性扩容
2)调度:
- 通过 EquivalenceCache,算法剪枝 等技术提升单调度器的吞吐性能
- 通过共享资源视图实现调度器多活,提升调度速率
3)网络:
- 通过trunkport提升单节点容器密度及单集群ENI容量
- 通过 Warm Pool 预申请网口,提升网口发放速度
- 基于eBPF/XDP 支持大规模、高度变化的云原生应用网络,e.g. Service, network policy
4)引擎:
- containerd 并发 启动优化
- 支持shimv2,提升单节点容器密度
- 镜像下载加速 Lazy loading
Cromwell社区集成
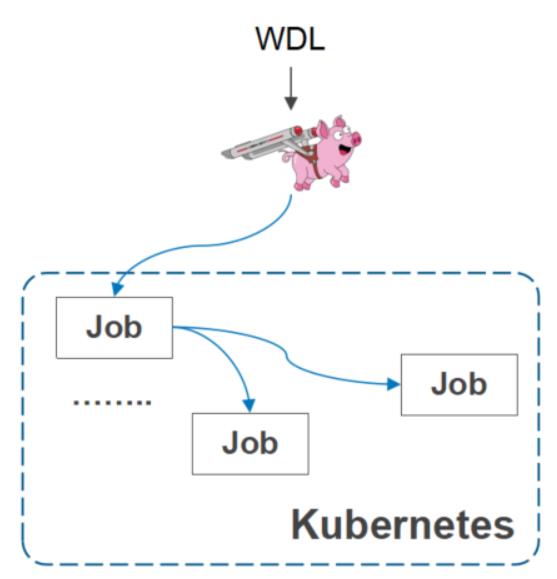
Cromwell是一个流程调度软件,它可以定义不同的作业,这个软件在基因测序以及基因计算领域里应用是比较广泛的。
- Cromwell 社区原生支持Volcano
- 企业版已经上线 华为云 GCS
- 通过 cromwell 支持作业依赖
- Volcano 提供面向作业、数据依赖的调度
Volcano CLI

KubeSim
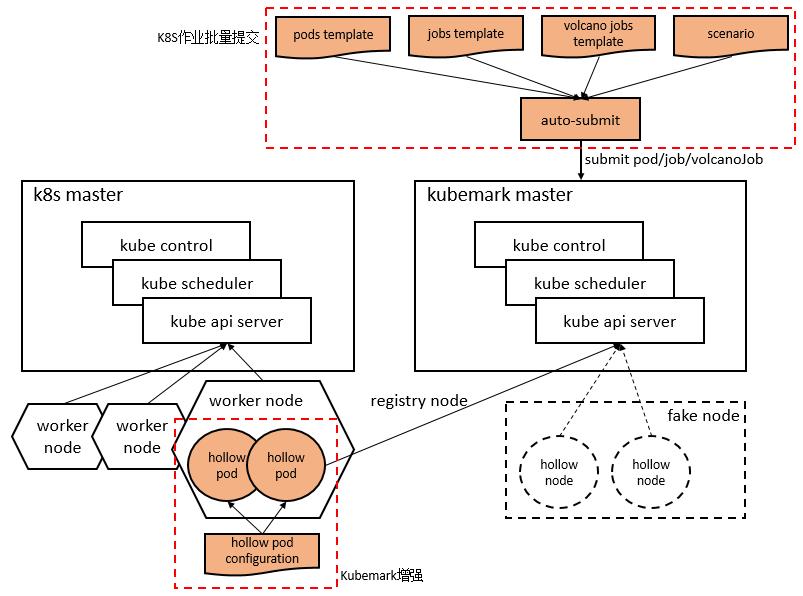
简介:
- 集群进行性能测试及调度的描述工具
- 不受资源限制,模拟大规模K8S集群
- 完整的K8S API调用,不会真正创建pod
- 已经支持产品侧大规模专项及调度专项的模拟工作
总体结构:
- Worker cluster:承载kubemark虚拟节点,hollow pod
- Master cluster:管理kubemark虚拟节点,hollow node
- Hollow pod = hollow kubelet + hollow proxy
参考链接
Github: http://github.com/volcano-sh/volcano
Website: https://volcano.sh
Slack: http://volcano-sh.slack.com
Email: volcano-sh@googlegroups.com
以上是关于1-Volcano火山:容器与批量计算的碰撞的主要内容,如果未能解决你的问题,请参考以下文章