探秘HDFS —— 发展历史核心概念架构工作机制 (上)
Posted Mr-Bruce
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了探秘HDFS —— 发展历史核心概念架构工作机制 (上)相关的知识,希望对你有一定的参考价值。
1 前言
几周前,笔者做了一个与HDFS有关的技术分享,以知识普及为目的,主要分享了Hadoop发展历史、HDFS核心概念、整体架构、工作机制等内容。本文大部分内容来自于当时的Slides,分上下两篇阐述。
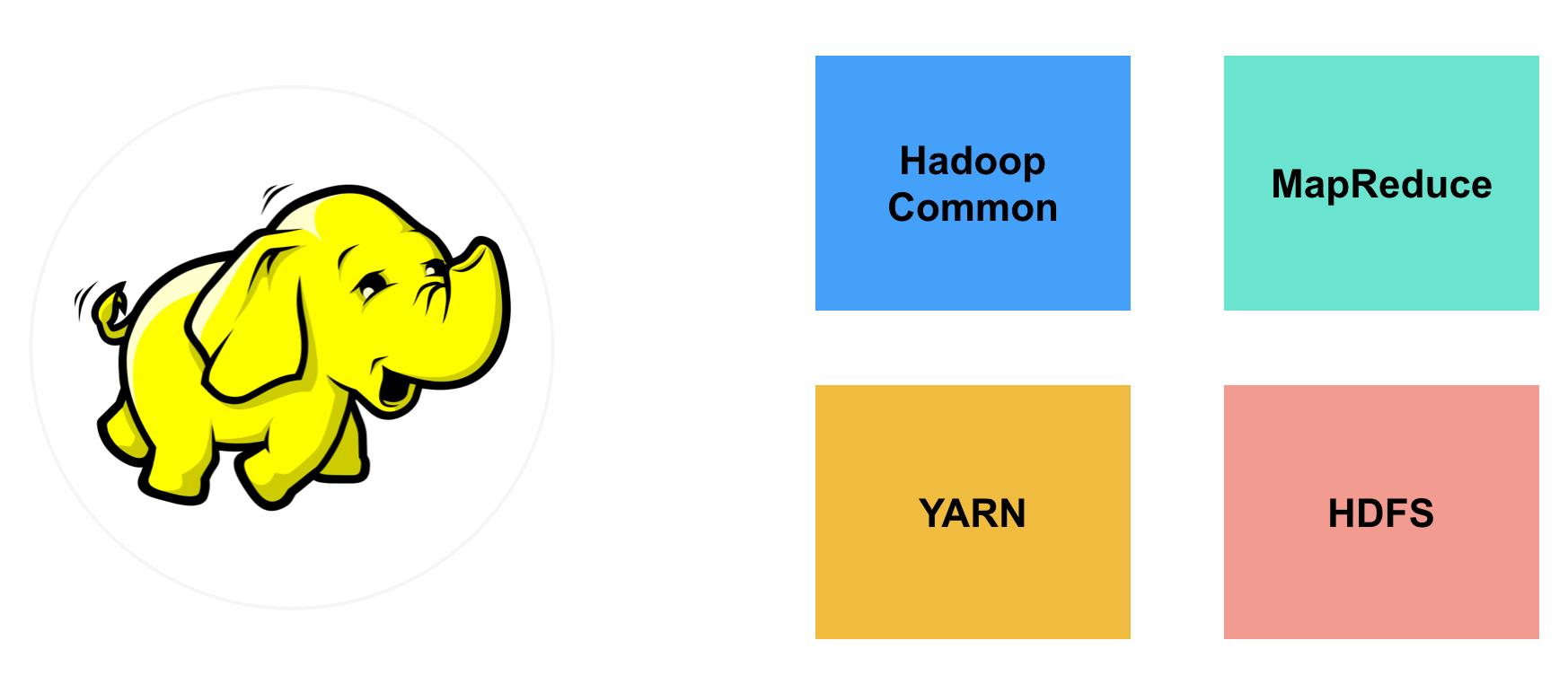
HDFS,全称Hadoop Distributed File System,顾名思义,是Hadoop里面的分布式文件系统。在诸多大数据架构设计中,都能看到最底层是HDFS,用于数据的持久化。在Hadoop系统中(以2.7.3版本为例),HDFS只是其中一个组件,另外三个组件分别是:YARN,负责集群的资源管理;MapReduce,大数据计算引擎;Hadoop Common,相关公共库。从架构拆分和接口通用化的角度来看,这四个组件都设计的很好,尽管最近几年MapReduce逐渐被Spark、Flink这样综合型的内存型计算引擎替代,但是其他三个组件依然被广泛使用在各种业务场景。
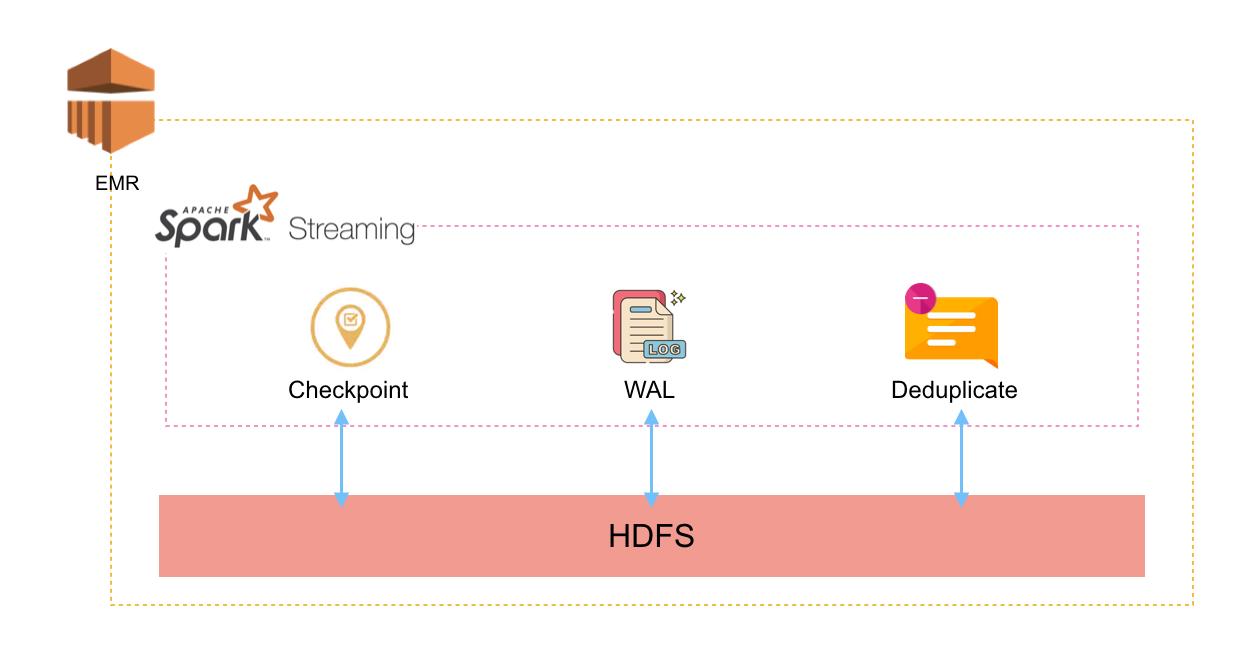
笔者所在的大数据项目主要使用Spark作为计算引擎,数据存放在AWS S3中,HDFS并没有被重度使用,主要用在以下三个场景,用来保证Spark Streaming处理过程中的数据完整性(不多、不少)。
- 为了保证在处理过程中Crash后,程序能恢复起来继续处理,需要记录Spark Streaming Checkpoint数据
- 为了保证已经接收、尚未处理的数据不丢失,需要依靠Spark Streaming WAL机制,即将接收的数据持久化
- 为了保证一段时间内没有重复数据,需要记录历史数据的Hash值
因为HDFS并不是整个项目的核心,所以参照业界用法就去用了,也没有详细的研究。上线后一年半时间内,陆续发生了5个与HDFS相关的CASE,占了近一半。且不论是否应该在上述场景去用HDFS,就发生的问题来看,主要是因为我们当时对HDFS的认知不够。因此,这里跟大家分享些笔者当前对HDFS的部分认识,期望能帮助到同道中人。
2 Hadoop发展历史
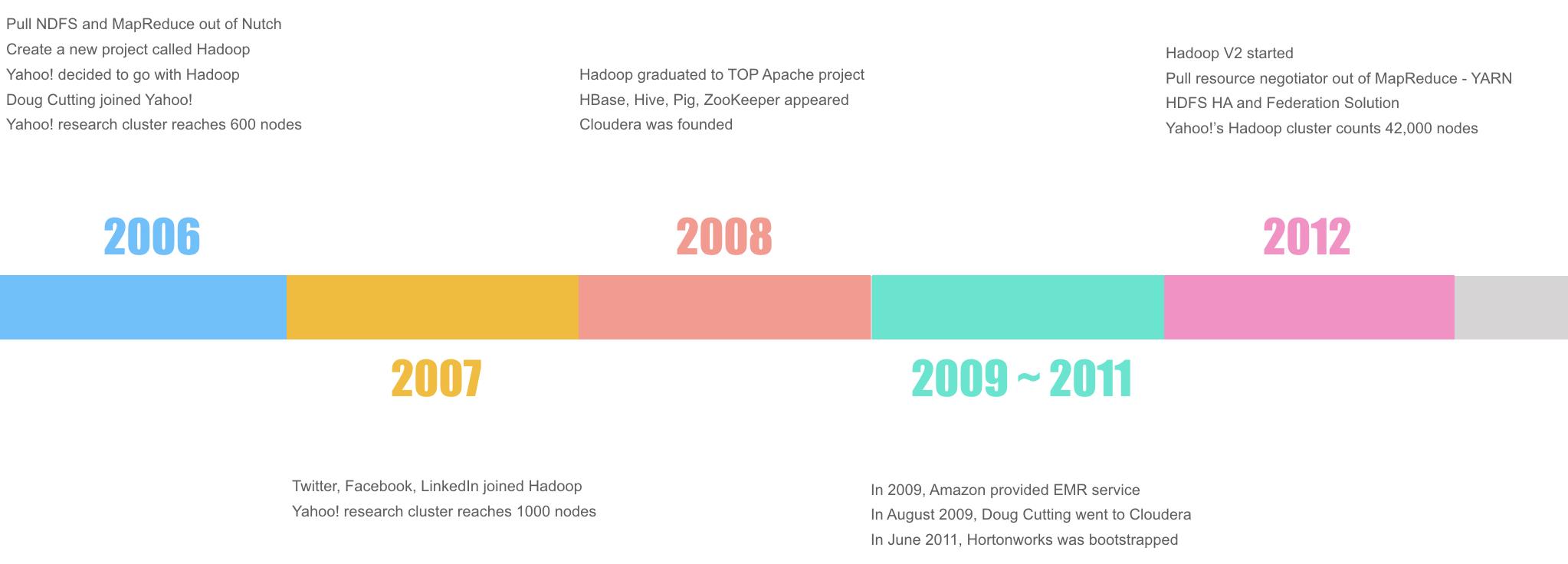
在了解HDFS是什么、怎么工作之前,先来看看HDFS是在什么样的业务场景下被创造出来的。笔者这里整理了2012年之前Hadoop的发展历史,这一时间段也是Hadoop从萌生到飞速发展的阶段。要谈Hadoop的发展历史,就不得不提到一个人:Doug Cutting,他是Apache Lucene、Nutch、Hadoop、Avro的创始人,为Apache社区作出了重要贡献,目前在Cloudera担任首席架构师。有意思的是,Hadoop的名字,就是他以自己儿子的一个玩具名来命名的。
阶段一:孵化
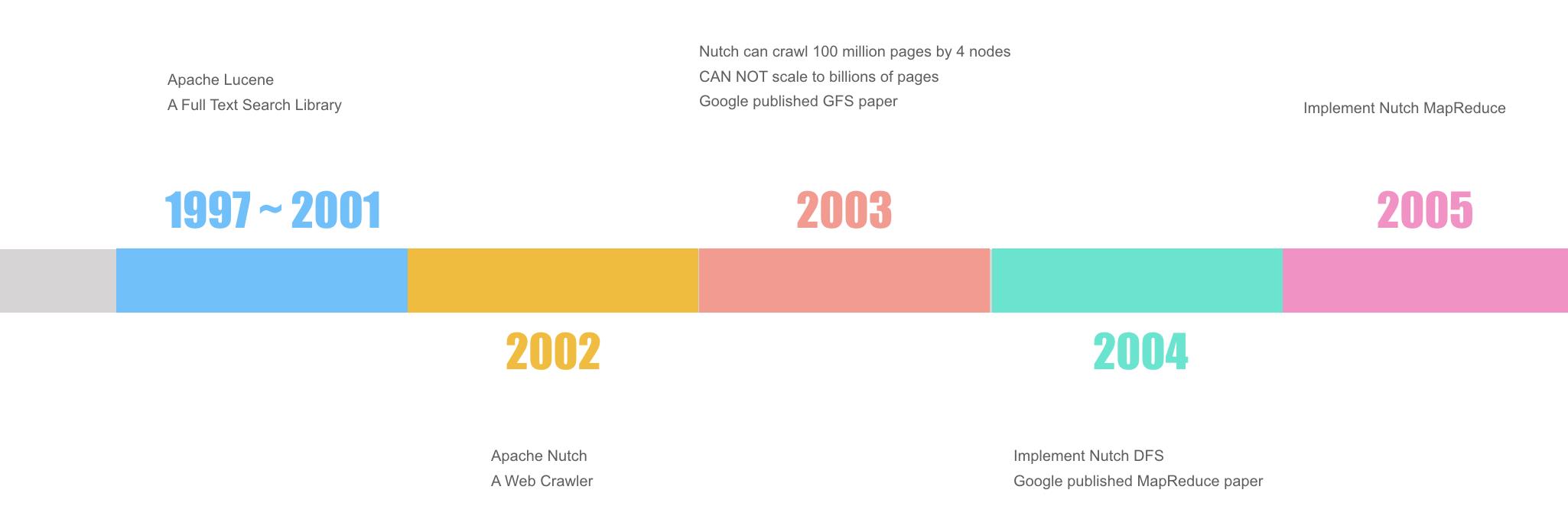
上个世纪90年代,互联网信息开始呈现爆炸式增长,“搜索”成为一个热门方向。1997年,Doug开始研发Lucene项目,一个全文搜索引擎库。比如,有100篇文章,给一个关键词“飞机”,从中搜索出包含关键词的文章。要实现这个功能,需要先将每篇文章分词,建立倒排索引,然后根据关键词来匹配打分,从而找出相关的文章。目前如日中天的Elasticsearch技术,便是基于Lucene来实现的,可见该项目的前瞻性与实用性。2001年,Doug将Lucene开源到Apache,之后很快成长为TOP项目。
2002年,Doug开始研发Nutch项目,用于爬取全网信息,然后用Lucene建立索引,从而提供互联网搜索。但是,单靠一台机器是无法处理全网信息的。于是,Doug开始研究如何利用多台机器协调起来同时处理,即分布式存储与计算技术。到2003年底,他实现了用四台机器来处理信息。但是,面对爆炸式的全网信息,四台机器还是太少了,而他的架构已经无法支持进一步扩展。就在Doug一筹莫展时,Google发表了论文Google File System,阐述了Google内部对分布式文件系统的理解和实现方式。
2004年,Doug根据GFS论文的指导,在Nutch项目中实现了DFS系统,这就是最早版的HDFS,只是当时叫NDFS。有了分布式存储系统后,Doug开始思考如何在这样的底层存储上来重构之前的计算引擎,而就在年底,Google又发表了MapReduce论文。2005年,Doug实现了Nutch MapReduce,并基于MapReduce对Nutch进行了重构。
阶段二:出世与成长
2006年,是Hadoop正式面世的一年。这一年,Doug将DFS和MapReduce从Nutch项目中剥离,组建了Hadoop项目。同年,Yahoo!开始全面转移到Hadoop阵地,并聘请Doug作为项目转型的架构师。到年底,Yahoo!的Hadoop集群达到了600台机器。
2007年,Twitter、Facebook、LinkedIn相继加入Hadoop阵营。同年底,Yahoo!的集群达到1000台机器。
2008年,是Hadoop发展很重要的一年。这一年,Hadoop成长为Apache Top项目,HBase、Hive、Pig、Zookepper等基于Hadoop的项目相继诞生,并贡献给开源社区,整个Hadoop的生态体系构成。同年,一个新兴的公司Cloudera成立,基于Hadoop提供专业的解决方案。
2009年,Amazon提供EMR云服务,用户不用担心机器的维护、扩展,只需要关注自己的业务(PS:笔者当前的大数据服务都是跑在EMR中的)。同年8月,Doug加入Cloudera。2011年,另一家公司Hortoworks成立,跟Cloudera一样,提供大数据解决方案。
阶段三:飞升
2012年,Hadoop迎来了一次大的改动,成为Hadoop v2。除了很多接口、内部实现的优化外,最重要的是两点:
- 将YARN分拆出来,作为独立的资源管理模块
- 构建HDFS的HA和Federation解决方案,提高HDFS的高可用和扩展性
到这一年底,Yahoo!的集群达到了42000台机器。2012年之后,到2016年,Hadoop平稳发展,被越来越多的公司引入使用。
总结来说,Hadoop是由Doug创建,最初是为了解决全网信息爬取与处理的问题,后来被Yahoo!发扬光大,在全社区的贡献下迅速构建了自己的生态体系,对大数据处理的发展影响深远。值得一提的是,随着云存储和诸如Spark、Flink这样内存型计算引擎的快速发展,2016年之后,Hadoop开始逐渐走下坡路。
3 核心概念
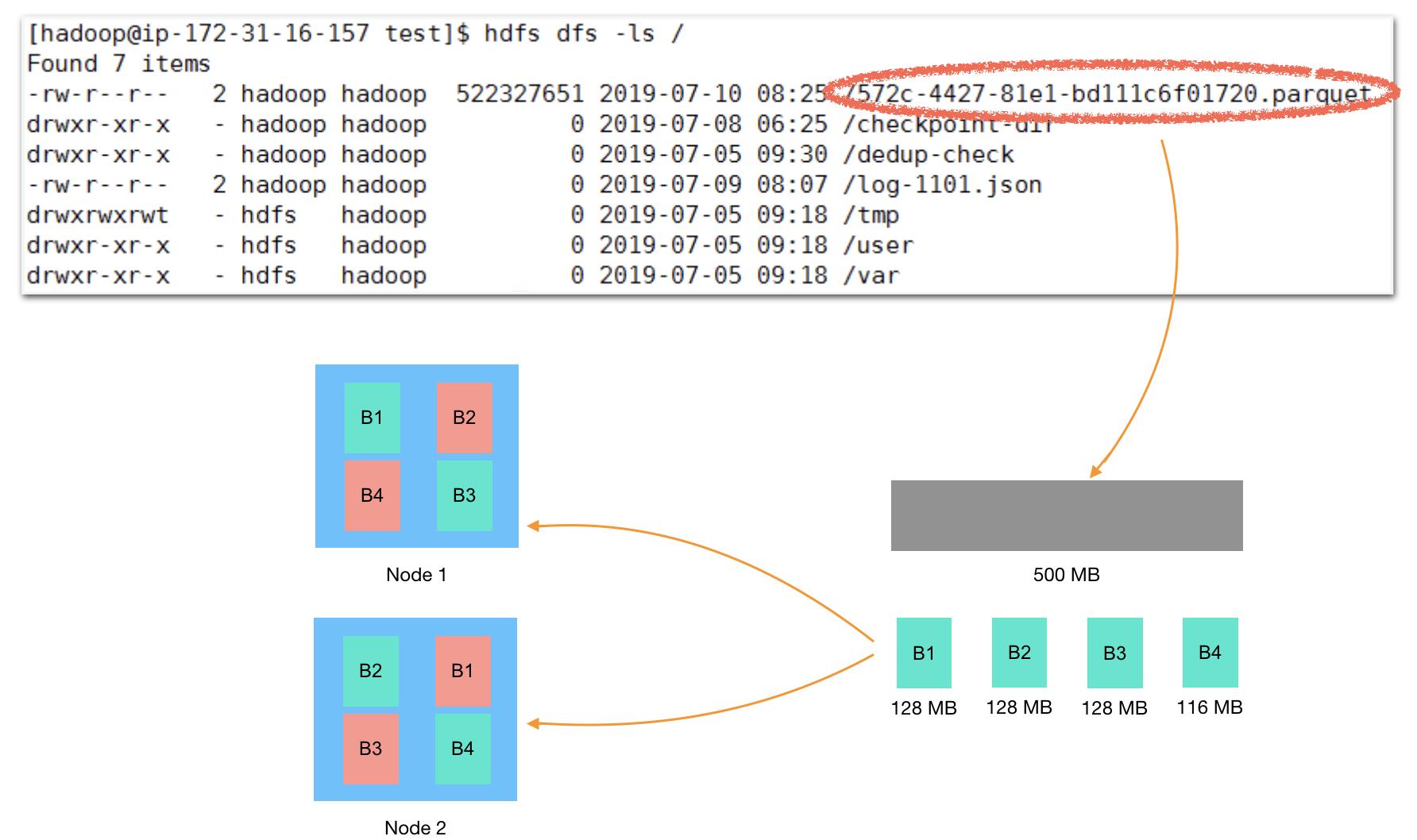
HDFS有两个核心特征:分布式、文件系统。从文件系统的角度来看,HDFS提供了一个统一的命名空间——目录树来组织文件,其操作命令的形式跟Linux操作系统基本保持一致,比如下图中的"hdfs dfs -ls /"命令。目录树,是逻辑上的概念,用来屏蔽底层复杂的存储和相关操作的细节,让用户感觉像在操作本地文件系统一样。
从分布式的角度来看,一个文件可能会被切割成多个数据块,分散存储到多台机器上。数据块,是物理上的概念,决定了文件的具体存储形式。以下图为例,文件"7572c-4427-81e1-bd111c6f01720.parquet" 大约500MB,会被分割为4个Block(默认一个Block的大小为128MB),假设集群有2台机器,就会每台机器分配两个Block。另一方面,Hadoop在设计和使用上,有一个前提:允许集群中少量机器在某个时刻发生故障。为了达到这个目的,需要将文件拷贝多份放在不同的机器上,即Replica。比如,这里的2台机器,会分别备份另一台机器上的数据块(Replica设置为2)。
为什么需要引入数据块?其实是我们常说的“分而治之”的思想。假设没有数据块,直接以整体的形式存储一个文件,就容易出现下面问题:
- 集群中的机器使用不均匀。比如将一个20GB的文件完整存放到机器A上,势必会导致机器A的负载更重。
- 故障恢复慢。对于一个20GB文件,如果所在的某台机器故障了,整个系统需要重新搬移数据,保持足够的Replica时,需要一次性移动20GB的数据,会带来较高的负载。
- 无法并行加载文件。文件作为整体存储时,很难利用并行计算的优势来并行加载文件。
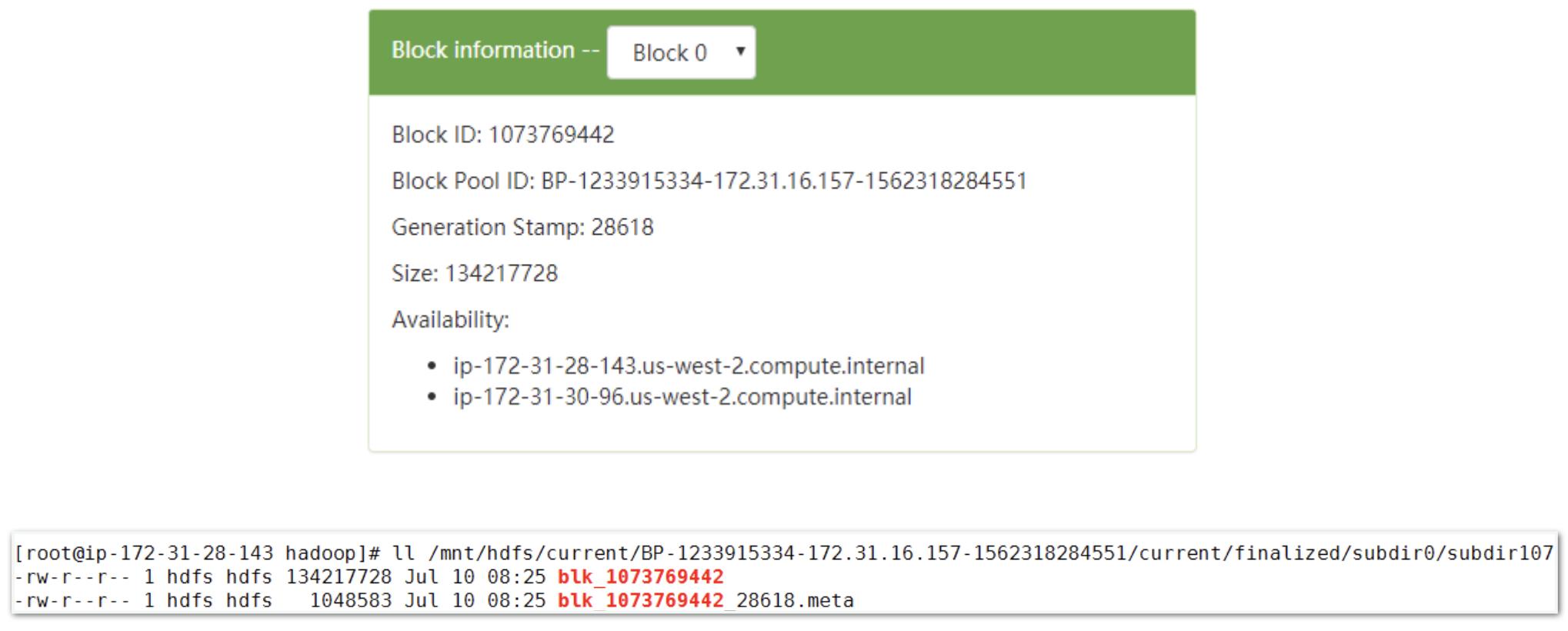
下图所示为一个数据块(Block)的相关信息,上面部分是在WebHDFS UI上看到的信息,下面部分是该数据块具体所在的机器上的信息。对于每一个数据块,都有一个映射关系:文件名称(包括路径) -> Block Id -> Block所在机器,这个关系对数据块的维护至关重要。
4 架构
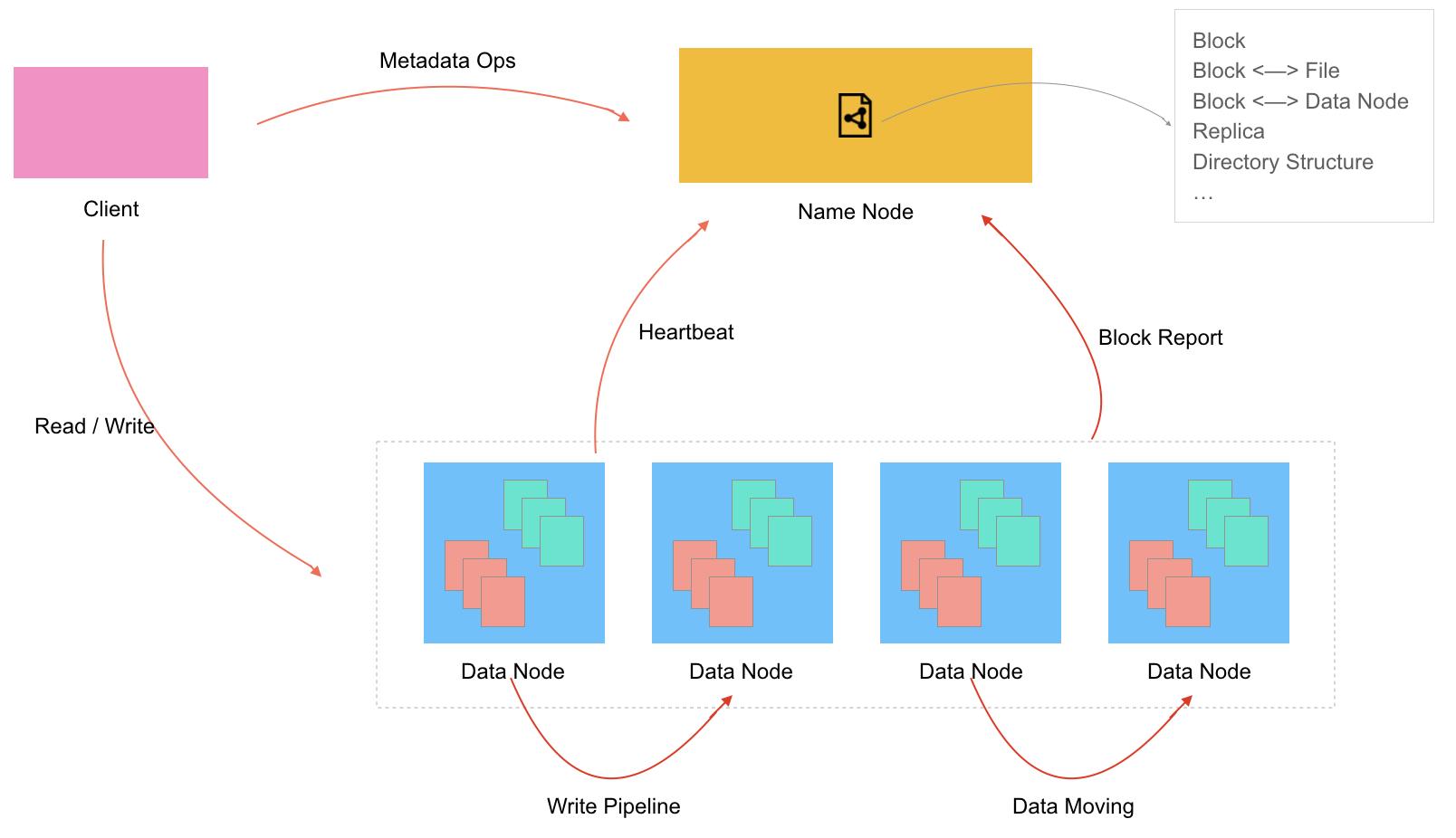
HDFS的架构,可以从两个角度来看:一个是由哪些组件构成,一个是组件之间如何通信。整个HDFS系统包含Client和Server两部分:Client是发起操作的一方,可以是HDFS自带的工具,也可以是通过API调用的程序(第三方库、业务程序等);Server是提供存储服务的一方,包括一个Name Node和多个Data Node。Name Node负责维护文件目录树、Block映射关系等元信息,Data Node负责具体的数据存储。综合来看,系统由三部分组成:Client、Name Node、Data Node。
这三个组件之间的通信关系,可以归纳为三方面:
- Client向Name Node、Data Node发起通信。Client发起的文件操作主要为读、写、修改属性,这些操作都会先跟Name Node交互,拿到返回信息后根据情况向相应的Data Node发起交互。
- Data Node向Name Node发起通信。Data Node会定期向Name Node发送Heartbeat、Block Report信息,Name Node收到后作出判断,并返回相关指令给Data Node,Data Node收到返回结果后,会根据情况做出进一步操作。Name Node不会主动向Data Node发起通信,只是被动地响应Data Node的通信。
- Data Node之间的通信。Data Node之间在某些特定场景下会相互交互,比如写操作时的数据复制、节点均衡时的数据移动。
这些通信关系是整个HDFS工作的核心,下一节笔者将进一步阐述在其之上的各种工作机制。
(未完待续)
(全文完,本文地址:https://bruce.blog.csdn.net/article/details/98178866 )
(版权声明:本人拒绝不规范转载,所有转载需征得本人同意,并且不得更改文字与图片内容。大家相互尊重,谢谢!)
Bruce
2019/09/01 下午
以上是关于探秘HDFS —— 发展历史核心概念架构工作机制 (上)的主要内容,如果未能解决你的问题,请参考以下文章