简单模拟添加并合并通讯录~python+
Posted lxw-pro
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了简单模拟添加并合并通讯录~python+相关的知识,希望对你有一定的参考价值。
目录
- 添加并合并通讯录
- Pandas 每日一练:
个人昵称:lxw-pro
个人主页:欢迎关注 我的主页
个人感悟: “失败乃成功之母”,这是不变的道理,在失败中总结,在失败中成长,才能成为IT界的一代宗师。
添加并合并通讯录
无论是之前的按键机还是如今的智能机,通讯录都是大家最为熟知、最为经常使用的一个功能,现在我们就简单来模拟模拟用python来添加并合并通讯录叭!
相关程序代码如下:
n = int(input("请输入要添加通讯录的人数:"))
a = []
for i in range(n):
con_dict =
name = input('请输入添加的联系人姓名:')
telephone = input('请输入11位电话号码:')
email = input('请输入邮件:')
address = input('请输入地址:')
info = f"tele:telephone, email:email, add:address"
con_dict[name] = info
print('第', i+1, '本通信录中的联系人信息为', con_dict)
set1 = set(con_dict)
a.append(set1)
print('通信录现加的联系人:', set1)
print('通信录合并后的联系人有', a)
运行效果如下:
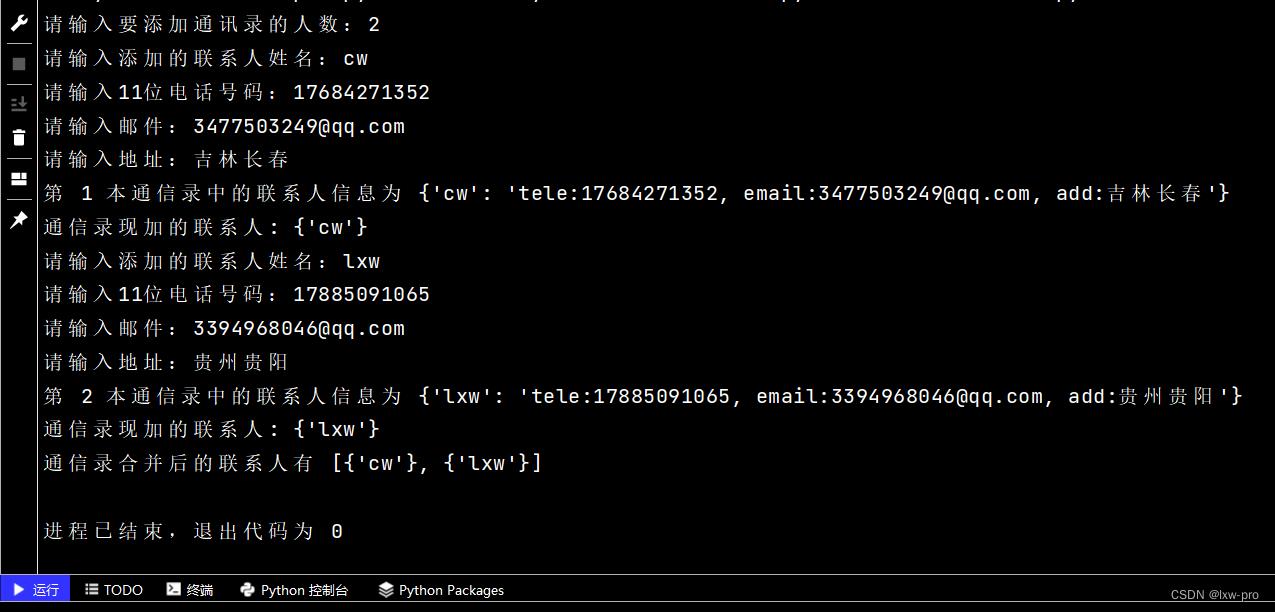
————————————————————————————————————————————
Pandas 每日一练:
# -*- coding = utf-8 -*-
# @Time : 2022/8/24 14:03
# @Author : lxw_pro
# @File : pandas-13 练习.py
# @Software : PyCharm
import pandas as pd
import numpy as np
81、导入并查看pandas与numpy版本
print("此时电脑所拥有pandas的版本号为:", pd.__version__)
print("此时电脑所拥有numpy的版本号为:", np.__version__)
运行结果如下:
此时电脑所拥有pandas的版本号为: 1.3.5
此时电脑所拥有numpy的版本号为: 1.21.4
82、从Numpy数组创建DataFrame
tmp1 = np.random.randint(1, 100, 10)
df1 = pd.DataFrame(tmp1)
print(df1)
运行结果如下:
0
0 82
1 35
2 40
3 35
4 84
5 83
6 27
7 39
8 89
9 13
83、从Numpy数组创建DataFrame
tmp2 = np.arange(0, 100, 5)
df2 = pd.DataFrame(tmp2)
print(df2)
运行结果如下:
0
0 0
1 5
2 10
3 15
4 20
5 25
6 30
7 35
8 40
9 45
10 50
11 55
12 60
13 65
14 70
15 75
16 80
17 85
18 90
19 95
84、从Numpy数组创建DataFrame
tmp3 = np.random.normal(0, 1, 20)
df3 = pd.DataFrame(tmp3)
print(df3)
运行结果如下:
0
0 1.191570
1 -1.393687
2 -1.854633
3 -1.357408
4 0.106885
5 -0.807733
6 2.423144
7 0.618467
8 0.331969
9 -1.113270
10 -0.431672
11 0.333612
12 0.390207
13 -0.305119
14 -1.105575
15 1.005282
16 1.285347
17 -1.111543
18 1.628867
19 -0.833661
85、将df1、df2、df3按照行合并为新DataFrame
df = pd.concat([df1, df2, df3], axis=0, ignore_index=True)
print(df)
运行结果如下:
0
0 82.000000
1 35.000000
2 40.000000
3 35.000000
4 84.000000
5 83.000000
6 27.000000
7 39.000000
8 89.000000
9 13.000000
10 0.000000
11 5.000000
12 10.000000
13 15.000000
14 20.000000
15 25.000000
16 30.000000
17 35.000000
18 40.000000
19 45.000000
20 50.000000
21 55.000000
22 60.000000
23 65.000000
24 70.000000
25 75.000000
26 80.000000
27 85.000000
28 90.000000
29 95.000000
30 1.191570
31 -1.393687
32 -1.854633
33 -1.357408
34 0.106885
35 -0.807733
36 2.423144
37 0.618467
38 0.331969
39 -1.113270
40 -0.431672
41 0.333612
42 0.390207
43 -0.305119
44 -1.105575
45 1.005282
46 1.285347
47 -1.111543
48 1.628867
49 -0.833661
86、将df1、df2、df3按照列合并为新DataFrame
df = pd.concat([df1, df2, df3], axis=1, ignore_index=True)
print(df)
运行结果如下:
0 1 2
0 82.0 0 1.191570
1 35.0 5 -1.393687
2 40.0 10 -1.854633
3 35.0 15 -1.357408
4 84.0 20 0.106885
5 83.0 25 -0.807733
6 27.0 30 2.423144
7 39.0 35 0.618467
8 89.0 40 0.331969
9 13.0 45 -1.113270
10 NaN 50 -0.431672
11 NaN 55 0.333612
12 NaN 60 0.390207
13 NaN 65 -0.305119
14 NaN 70 -1.105575
15 NaN 75 1.005282
16 NaN 80 1.285347
17 NaN 85 -1.111543
18 NaN 90 1.628867
19 NaN 95 -0.833661
87、查找df所有数据的最小值、25%分位数、中位数、75%分位数、最大值
ms = df.describe()
print(ms)
运行结果如下:
0 1 2
count 10.000000 20.000000 20.000000
mean 52.700000 47.500000 -0.049948
std 28.452885 29.580399 1.166953
min 13.000000 0.000000 -1.854633
25% 35.000000 23.750000 -1.107067
50% 39.500000 47.500000 -0.099117
75% 82.750000 71.250000 0.715171
max 89.000000 95.000000 2.423144
88、修改列名为col1、col2、col3
df.columns = ['col1', 'col2', 'col3']
print(df)
运行结果如下:
col1 col2 col3
0 82.0 0 1.191570
1 35.0 5 -1.393687
2 40.0 10 -1.854633
3 35.0 15 -1.357408
4 84.0 20 0.106885
5 83.0 25 -0.807733
6 27.0 30 2.423144
7 39.0 35 0.618467
8 89.0 40 0.331969
9 13.0 45 -1.113270
10 NaN 50 -0.431672
11 NaN 55 0.333612
12 NaN 60 0.390207
13 NaN 65 -0.305119
14 NaN 70 -1.105575
15 NaN 75 1.005282
16 NaN 80 1.285347
17 NaN 85 -1.111543
18 NaN 90 1.628867
19 NaN 95 -0.833661
89、提取第一列中不在第二列出现的数字
print(df['col1'][df['col1'].isin(df['col2'])])
运行结果如下:
1 35.0
2 40.0
3 35.0
Name: col1, dtype: float64
90、提取第一列和第二列出现频率最高的三个数字
tmp = df['col1'].append(df['col2'])
print(tmp.value_counts().index[:3])
运行结果如下:
Float64Index([35.0, 40.0, 82.0], dtype='float64')
每日一言:
你必须按所想去生活,否则你只能按生活去想!!!
持续更新中…
点赞,你的认可是我创作的
动力!
收藏,你的青睐是我努力的方向!
评论,你的意见是我进步的财富!
关注,你的喜欢是我长久的坚持!

欢迎关注微信公众号【程序人生6】,一起探讨学习哦!!!
以上是关于简单模拟添加并合并通讯录~python+的主要内容,如果未能解决你的问题,请参考以下文章