爬虫过程和反爬
Posted simple_daytime
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫过程和反爬相关的知识,希望对你有一定的参考价值。
文章目录
爬虫过程
爬虫:获取网络数据(公开的网络)
网络数据来源:网站对应的网页、手机APP
一、获取网络数据(requests、selenium)
1.requests
-
定义
Python获取网络数据的第三方库(基于http或https协议的网络请求) -
应用场景
1)直接请求网页地址 2)对提供网页数据的数据接口发送请求 -
基本用法
1)对目标网页直接发送请求: requests.get(网页地址):获取指定页面的数据返回一个响应对象 2)获取响应的状态码:response.status_code 3)获取响应头:response.headers 4)请求内容(返回的有效数据): a.response.content: 二进制类型的数据(图片、视频、音频等,例如:图片下载) b.response.text: 字符串类型的数据(网页) c.response.json(): 对请求内容做完json解析后的数据(json数据接口)response = requests.get('https://cd.zu.ke.com/zufang') print(response) # 200表示请求成功 -
设置cookie
自动登录原理:人工在浏览器上完成登录操作,获取登录后的cookie信息(登录信息),再通过代码发送请求的时候携带登录后的cookie。
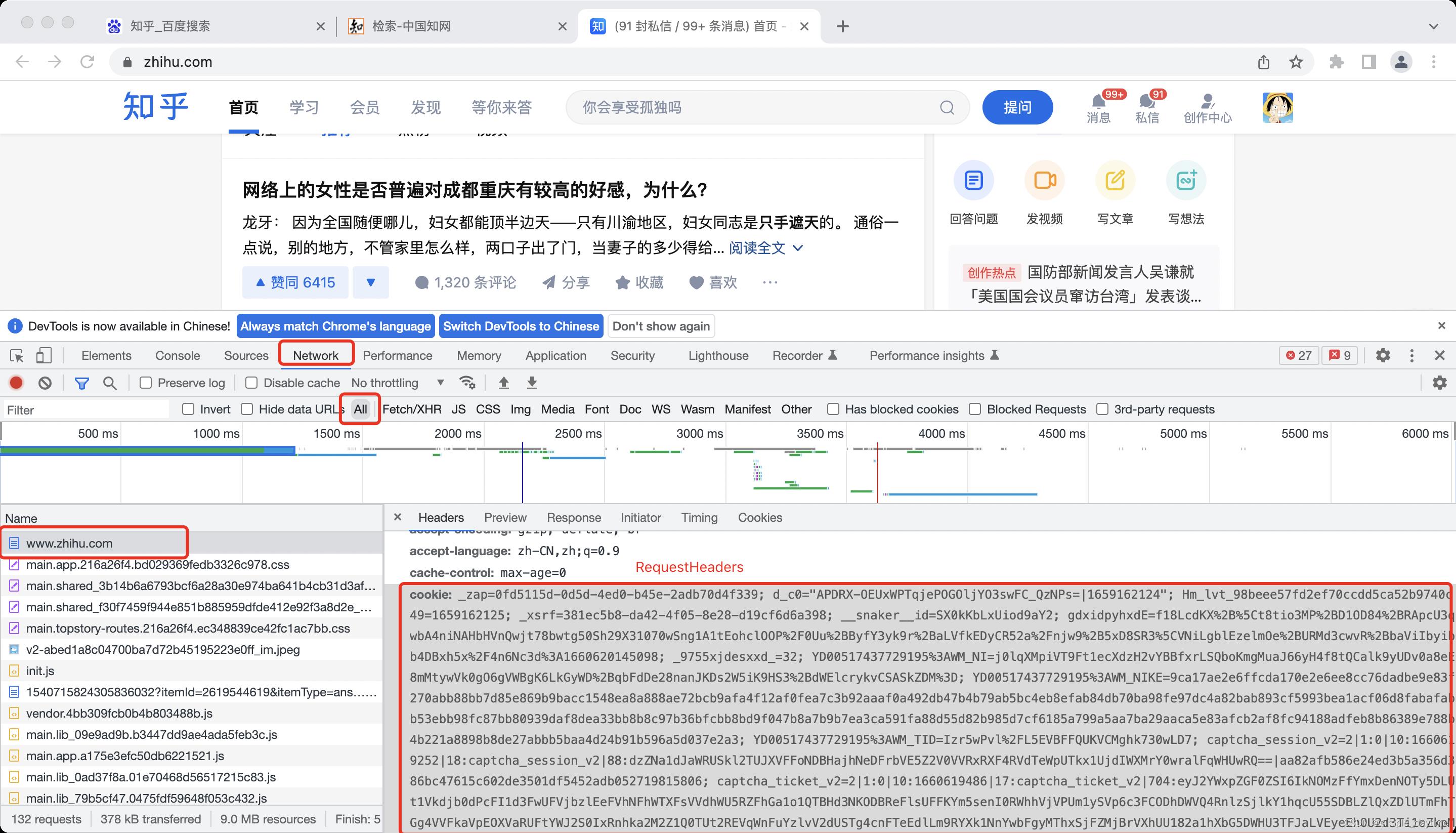
import requests headers = 'cookie': '复制到的cookie值', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/104.0.0.0 Safari/537.36' response = requests.get('https://www.zhihu.com/', headers=headers) print(response.text) -
代理IP
❀获取代理IP(可能需要花钱买)首先需要去代理IP网页获取一个代理IP:极光代理IP- https://www.jghttp.com/❀使用代理IP的语法:
1.创建代理对应的字典 # 方法1 proxies = 'http': '221.10.105.215:4531', 'https': '221.10.105.215:4531' # 方法2 proxies = 'http': 'http://221.10.105.215:4531', 'https': 'http://221.10.105.215:4531' response = requests.get(需要获取信息的网址, headers=headers, proxies=proxies) print(response.text)完整代码:
import requests headers = 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36' # 1.创建代理对应的字典 # 方法1 proxies = 'http': '221.10.105.215:4531', 'https': '221.10.105.215:4531' # 方法2 # proxies = # 'http': 'http://221.10.105.215:4531', # 'https': 'http://221.10.105.215:4531' # response = requests.get('https://movie.douban.com/top250', headers=headers, proxies=proxies) print(response.text)
2.selenium
-
安装第三方模块:selenium
❀使用pycharm安装,file->settings->project->点击里面模块右边的加号安装
❀或者直接在teiminal里输入 pip(3) install requests -
下载驱动器
1)查看浏览器版本:chrome://version/
2)chromedriver国内镜像:https://registry.npmmirror.com/binary.html?path=chromedriver/0
3)到与浏览器最接近的文件夹进去下载,最新的是104.0.5112.81
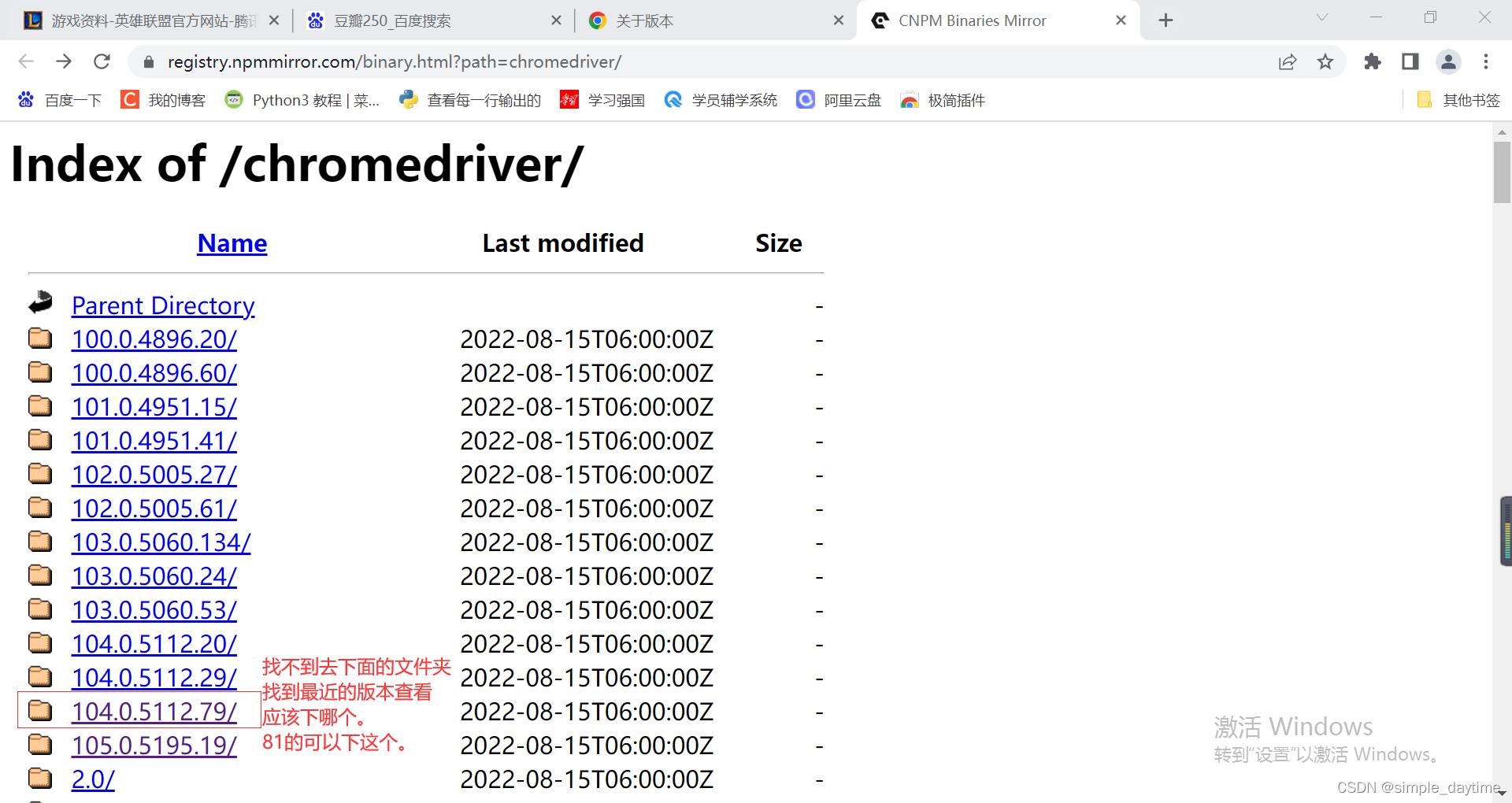

4)将下载好压缩包解压移动到python环境安装目录里。
在pycharm里面的settings里面查找环境目录,将解压好的chromedriver.exe放在python.exe同一目录。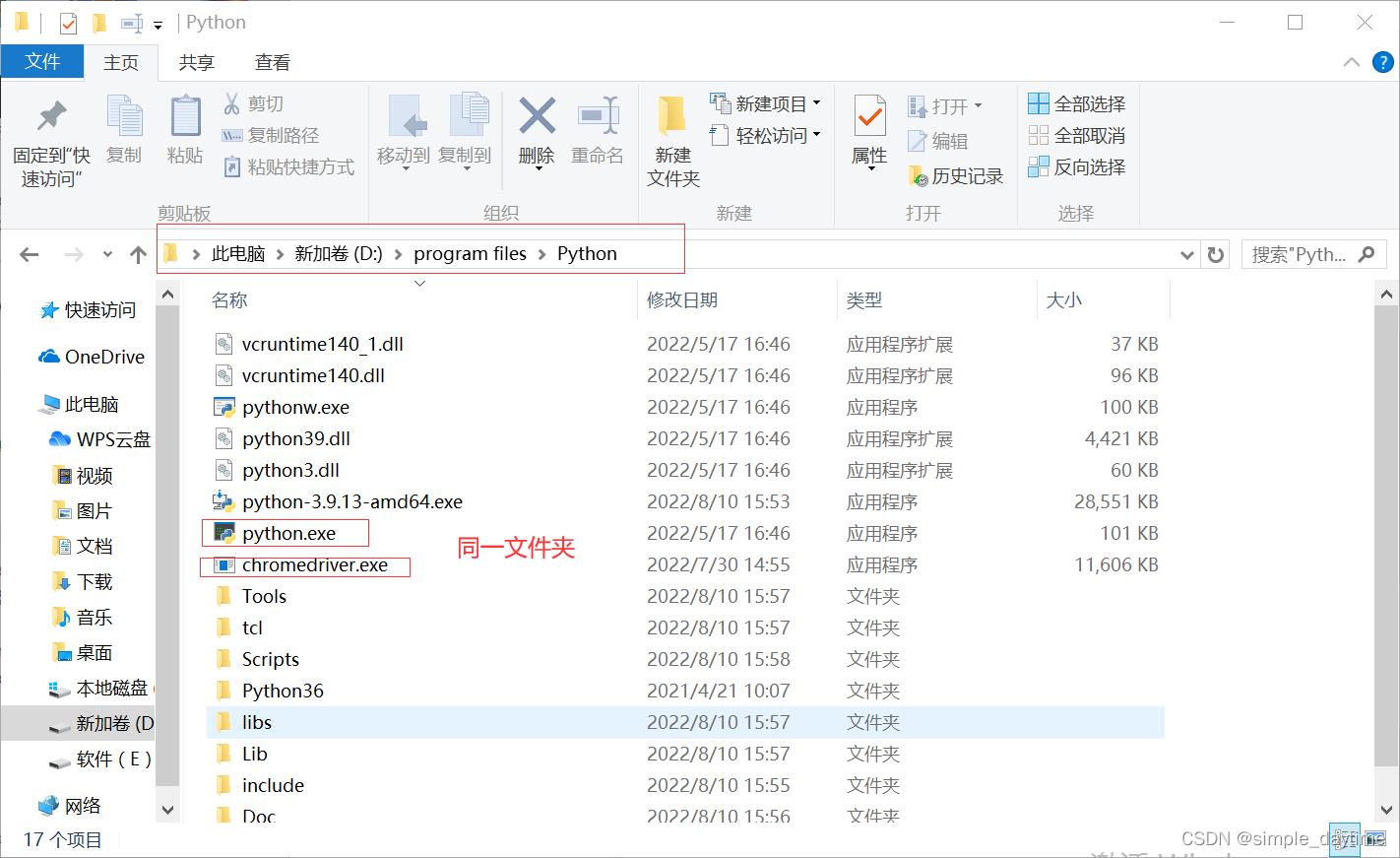
-
获取网页数据
1.创建浏览器对象(浏览器对象如果是全局变量,浏览器不会自动关闭) 2.打开网页 3.获取网页源代码 4.关闭浏览器# 导入模块 from selenium.webdriver import Chrome # 1.创建浏览器对象 b = Chrome() # 2.打开网页 b.get('https://movie.douban.com/top250') # 3.获取网页源代码: b.page_source print(b.page_source) # 4.关闭浏览器 b.close() -
控制浏览器基础操作
1.输入框输入内容 第一步:找到输入框 第二步:输入框输入内容-传值(标签.send_keys) 2.点击按钮 第一步:找到需要点击的标签 第二步:点击(标签.click()) 3.切换选项卡 1)获取当前浏览器上所有的窗口(选项卡):b.window_handles 2)切换选项卡:b.switch_to.window(切换到的窗口) 注意:selenium中,浏览器对象默认指向一开始打开的选项卡。除非用代码切换,否则浏览器对象指向的选项卡不会切换# 1.输入框输入内容 # 1)找到输入框 input_tag = b.find_element_by_id('key') # 2)输入框输入内容 input_tag.send_keys('电脑\\n')# 2.点击按钮 # 1)找到需要点击的标签 btn = b.find_element_by_css_selector('#navitems-group2 .b') # 2)点击标签 btn.click()# 3.切换选项卡 # 进入中国知网输入‘数据分析’之后利用切换选项卡获取每篇论文的摘要 from selenium.webdriver import Chrome from time import sleep from bs4 import BeautifulSoup # 1.基本操作 b = Chrome() # 创建浏览器对象 b.get('https://www.cnki.net/') # 打开中国知网 # 获取输入框并输入内容 search_tag = b.find_element_by_id('txt_SearchText') search_tag.send_keys('数据分析\\n') sleep(4) # 切换界面等待一会 # 获取需要点击的所有标签:如果拿到标签后需要点击或者输入,必须通过浏览器对象获取标签 results = b.find_elements_by_css_selector('.result-table-list .name>a') for i in range(len(results)): # 点击第一个结果(这会打开新的选项卡) results[i].click() b.switch_to.window(b.window_handles[-1]) # 切换选项卡到点开的论文窗口 # 解析内容 soup = BeautifulSoup(b.page_source, 'lxml') result = soup.select_one('#ChDivSummary') # 获取摘要 # 没有摘要输出无 if not result: print('无') else: print(result.text) b.close() # 关闭当前指向的窗口(最后一个窗口),窗口关闭后,浏览器对象的指向不会改变。 sleep(2) # 回到第一个窗口点击下一个搜索结果 b.switch_to.window(b.window_handles[0]) # 切换到第一个页面 b.close() # 关闭浏览器 -
页面滚动
语法: window.scrollBy(x方向偏移量,y方向偏移量) 执行滚动操作 - 执行js中的滚动代码:for x in range(10): b.execute_script('window.scrollBy(0,800)') sleep(1)需要等页面滚动之后把信息加载完才能解析数据,否则数据可能不完整。
-
设置cookie
❀获取cookie
第一步:打开需要完成自动登录的网站(需要获取cookie的网站) 第二步:给足够长的时间让人工完成自动登录并且刷新出登录后的页面 注意:一定要将第一个页面刷新出登录后的状态!!! 第三步:获取登陆后的cookie并将其保存在本地文件中 get_cookies()from selenium.webdriver import Chrome from json import dumps b = Chrome() # 1.打开需要完成自动登录的网站(需要获取cookie的网站) b.get('https://www.taobao.com/') # 2.给足够长的时间让人工完成自动登录并且刷新出登录后的页面 # 一定要将第一个页面刷新出登录后的状态。 input('已经完成登录:') # 3.获取登陆后的cookie并将其保存在本地文件中 cookies = b.get_cookies() print(cookies) with open('files/taobao.txt', 'w', encoding='utf-8') as f: f.write(dumps(cookies)) # 将获取的cookie转换成json写入文件。 print('写入完成!') b.close()❀使用cookie
第一步:打开需要完成自动登录的网站(需要获取cookie的网站) 第二步:从文件读出数据添加cookie 第三步:重新打开需要登录的网页from selenium.webdriver import Chrome from json import loads b = Chrome() # 1.打开需要完成自动登录的网站(需要获取cookie的网站) b.get('https://www.taobao.com/') # 2.从文件读出数据添加cookie with open('files/taobao.txt', encoding='utf-8') as f: content = f.read() cookies = loads(content) # 将json数据转换成python格式 for x in cookies: b.add_cookie(x) # 3.重新打开需要登录的网页 b.get('https://www.taobao.com/') input('结束') b.close() -
代理IP
❀导入相关模块
from selenium.webdriver import Chrome, ChromeOptions❀创建配置对象
options = ChromeOptions❀添加配置
options.add_argument('--proxy-server=http://ip')❀通过指定配置创建浏览器对象
b = Chrome(options=options)❀通过浏览器对象获取网页
b.get('https://movie.douban.com/topp250')❀完整代码
from selenium.webdriver import Chrome, ChromeOptions # 1.创建配置对象 options = ChromeOptions # 2.添加配置 options.add_argument('--proxy-server=http://ip') # 3.通过指定配置创建浏览器对象 b = Chrome(options=options) b.get('https://movie.douban.com/topp250') # 网址是被封了的 -
基本配置
❀配置前需要自己创建配置对象
from selenium.webdriver import ChromeOptions, Chrome options = ChromeOptions()❀取消设置环境提示
# 固定写法,有需要可添加快捷导入 options.add_experimental_option('excludeSwitches', ['enable-automation'])❀设置取消图片加载—加快运行速度
# 固定写法,需要添加快捷导入 options.add_experimental_option("prefs", "profile.managed_default_content_settings.images": 2)❀通过浏览器对象获取网页
b = Chrome(options=options) b.get('https://www.jd.com')❀完整代码
from selenium.webdriver import ChromeOptions, Chrome options = ChromeOptions() # 1.取消设置环境提示 options.add_experimental_option('excludeSwitches', ['enable-automation']) # 2.设置取消图片加载 options.add_experimental_option("prefs", "profile.managed_default_content_settings.images": 2) b = Chrome(options=options) b.get('https://www.jd.com') -
等待
❀隐式等待: implicitly_wait(时间(秒))
a.没有设置隐式等待:在通过浏览器获取标签时,如果标签不存在会直接报错; b.设置了隐式等待:在通过浏览器获取标签时,如果标签不存在不会直接报错,不会马上报错,而是在指定时间范围内不断尝试重新获取标签,直到获取到标签或者超时为止(超时会报错); c.一个浏览器只需设置一次隐式等待时间,它会作用于这个浏览器每次获取标签的时候。from selenium.webdriver import ChromeOptions, Chrome options = ChromeOptions() # 1.取消设置环境提示 options.add_experimental_option('excludeSwitches', ['enable-automation']) # 2.设置取消图片加载 options.add_experimental_option("prefs", "profile.managed_default_content_settings.images": 2) b = Chrome(options=options) b.get('https://www.jd.com') # 设置隐式等待时间,获取标签时才有效 b.implicitly_wait(5) print('------') input_tag = b.find_element_by_id('key') input_tag.send_keys('钱包\\n') b.close()❀显式等待:等待某个条件成立或者不成立为止
1)创建等待对象:WebDriverWait(浏览器对象,超时时间) 2)添加等待条件: 等待对象.until(条件) - 等到条件成立为止 等待对象.until_not(条件) - 等到条件不成立为止 条件写法: presence_of_element_located(标签) - 指定标签出现 text_to_be_present_in_element(标签, 值) - 指定标签的value属性中包含指定值 text_to_be_present_in_element_value(标签, 值) - 指定标签的标签内容中包含指定值 注意:条件中提供标签的方式 By.xxx(xxx)from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By options = ChromeOptions() # 1.取消设置环境提示 options.add_experimental_option('excludeSwitches', ['enable-automation']) # 2.设置取消图片加载 options.add_experimental_option("prefs", "profile.managed_default_content_settings.images": 2) b = Chrome(options=options) b.get('https://www.jd.com') wait = WebDriverWait(b, 10) # 创建 wait.until(EC.text_to_be_present_in_element_value(By.ID, 'key'), '电脑') print(b.page_source)
3.常见反爬
-
浏览器伪装
import requests headers = 'user-agent': 自己电脑浏览器信息 response = requests.get('https://movie.douban.com/top250', headers=headers) -
登录反爬
解决办法: 设置cookie requests和selenium里分别写了 -
代理
IPrequests和selenium里分别写了
4.找数据接口
-
第一步:打开控制台
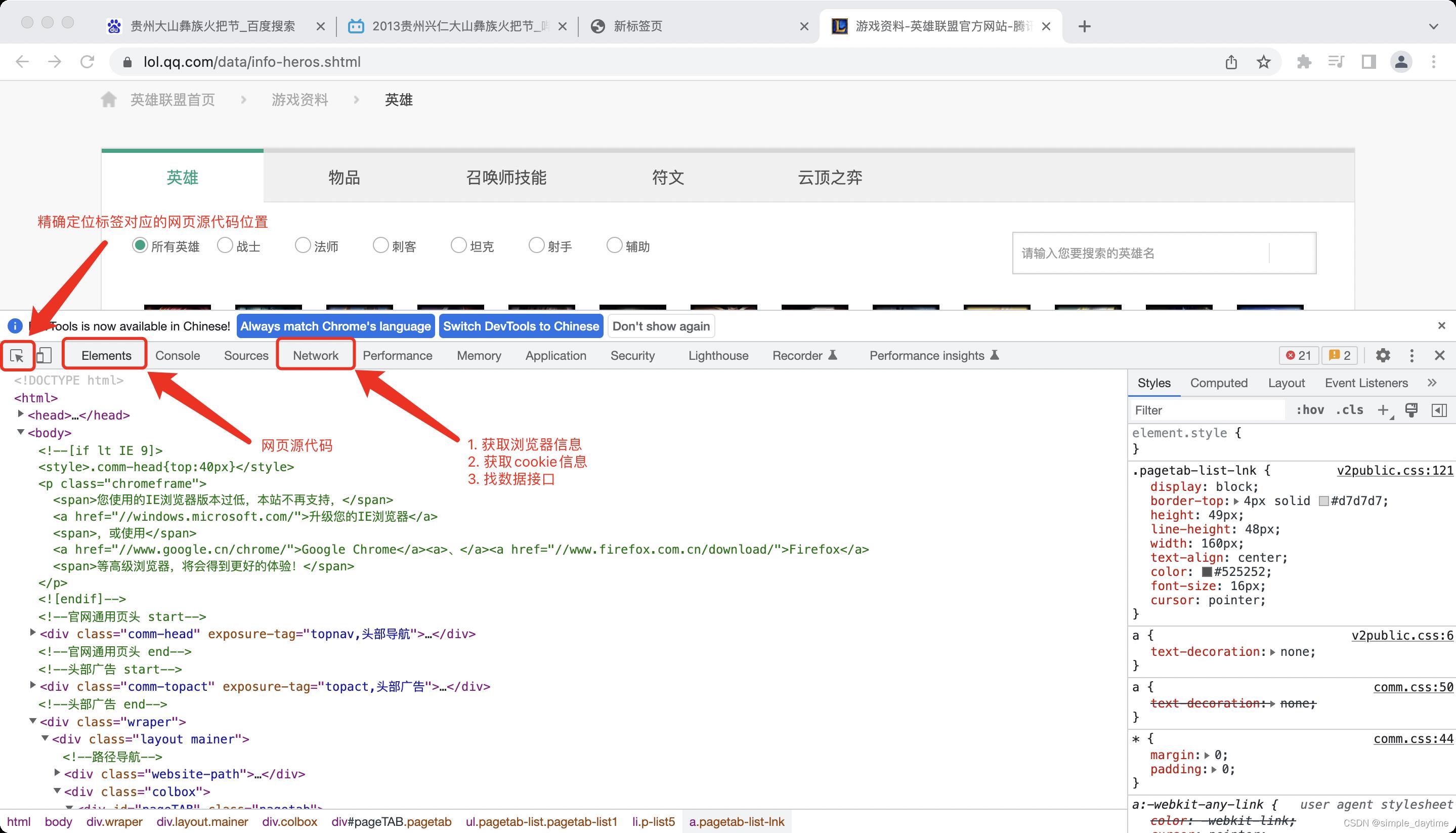
-
第二步:
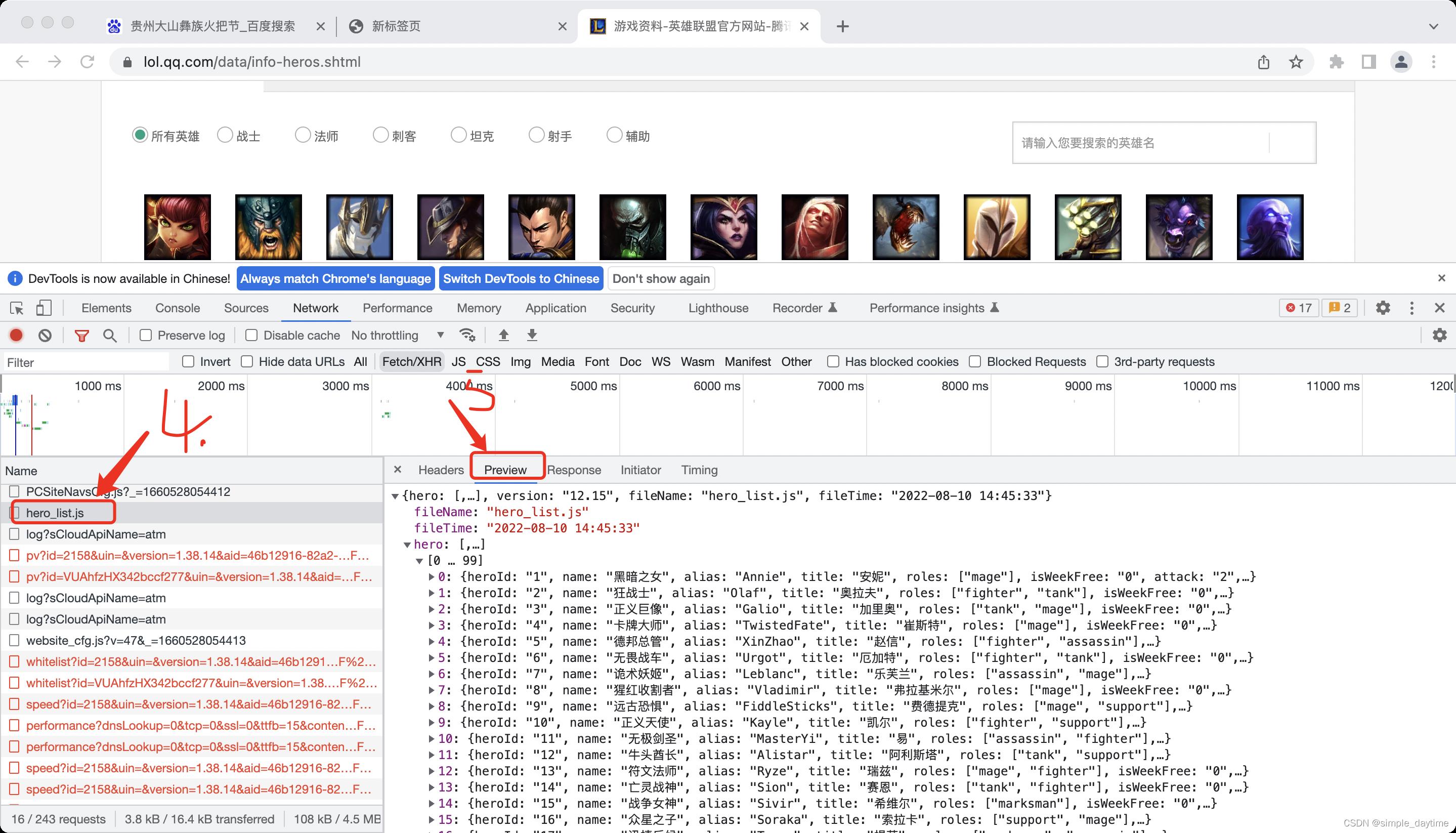
-
第三步:
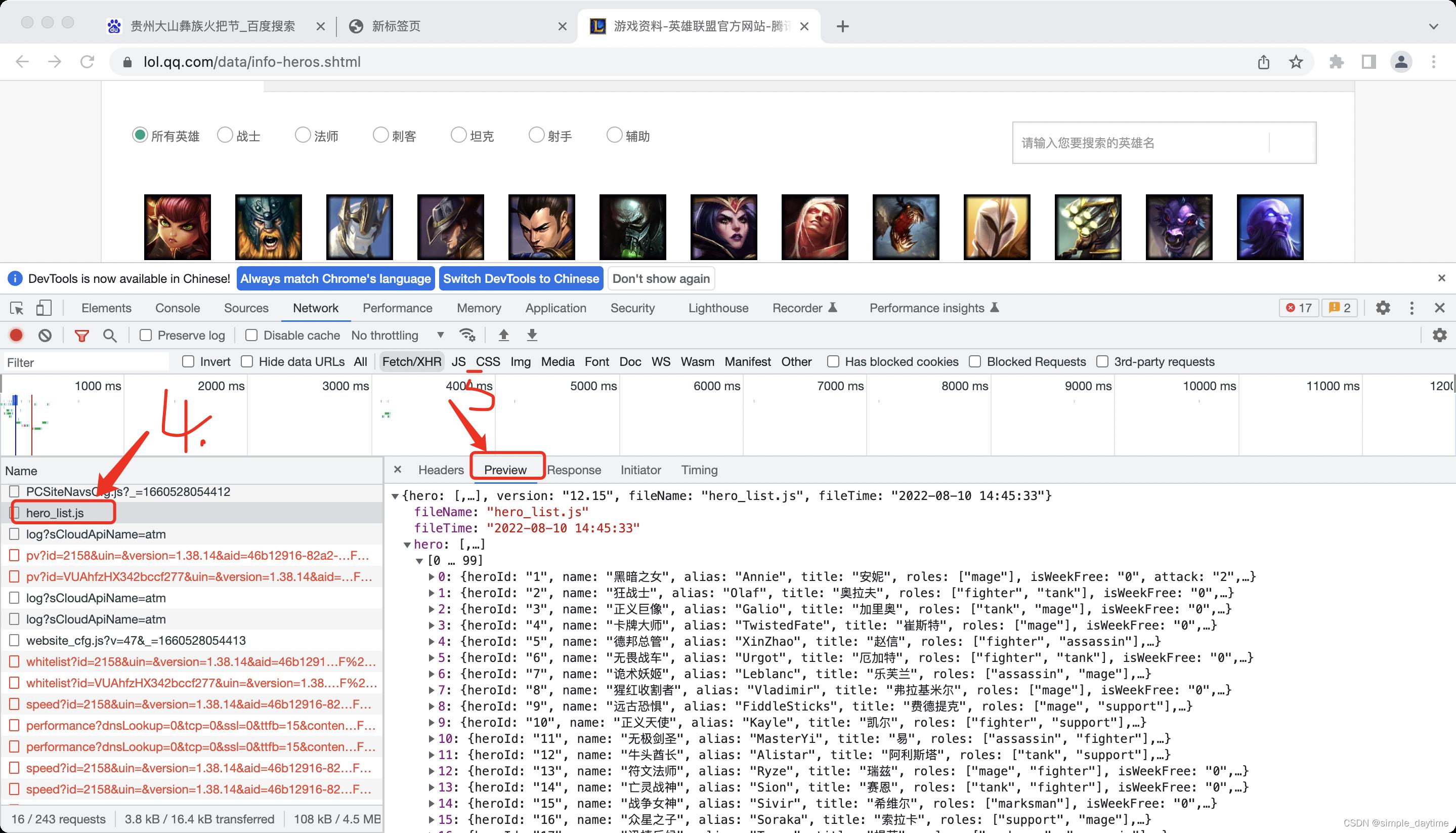
二、解析数据(从获取到的网络数据中提取有效数据)
1.正则表达式
# 例子
# 名字里面有换行,用单行匹配(?s)
names = findall(r'(?s)<a class="twoline".+?>(.+?)</a>', result)
2.基于css选择器的解析器(bs4)
-
bs4的作用
专门用来解析网页数据的第三方库。(基于css选择器解析网页数据) 这个库下载时用'beautifulsoup4', 使用的时候用'bs4' 注:使用bs4做数据解析时需要依赖'lxml'这个第三方库 -
导入模块
from bs4 import BeautifulSoup -
bs4的用法
1)准备需要解析的数据(获取网页数据) 2)基于网页源代码创建BeautifulSoup对象 3)获取标签 soup.select(css选择器):获取css选择器选中的所有标签,返回值是一个列表,列表中的元素是标签对象。 soup.select_one(css选择器):获取css选择器选中的第一个标签,返回值是一个标签对象。 标签对象.select(css选择器):在指定标签中获取css选择器选中的所有标签,返回值是一个列表,列表中的元素是标签对象。 标签对象.select_one(css选择器):在指定标签中获取css选择器选中的第一个标签,返回值是一个标签对象。 4)获取标签内容和标签属性 a.获取标签内容:标签对象.text b.获取标签属性:标签对象.attr[属性名]# 一个bs4使用的完整代码 # 导入解析相关类 from bs4 import BeautifulSoup # bs4的用法 # 1)准备需要解析的数据(获取网页数据) html = open('files/test.html', encoding='utf-8').read() # 2)基于网页源代码创建BeautifulSoup对象:soup对象代表网页对应的html标签(整个网页) soup = BeautifulSoup(html, 'lxml') # 3)获取标签 # soup.select(css选择器):获取css选择器选中的所有标签,返回值是一个列表,列表中的元素是标签对象。 # soup.select_one(css选择器):获取css选择器选中的第一个标签,返回值是一个标签对象。 result = soup.select('p') print(result) # [<p>你是大笨蛋</p>] result = soup.select_one('p') print(result) # <p>你是大笨蛋</p> # 标签对象.select(css选择器):在指定标签中获取css选择器选中的所有标签,返回值是一个列表,列表中的元素是标签对象。 # 标签对象.select_one(css选择器):在指定标签中获取css选择器选中的第一个标签,返回值是一个标签对象。 # 4)获取标签内容和标签属性 p = soup.select_one('p') img = soup.select_one('img') # a.获取标签内容:标签对象.text print(p.text) # 你是大笨蛋 # b.获取标签属性:标签对象.attr[属性名] print(img.attrs['src']) # 123
3.基于xpath的解析器(lxml)
html的树结构:
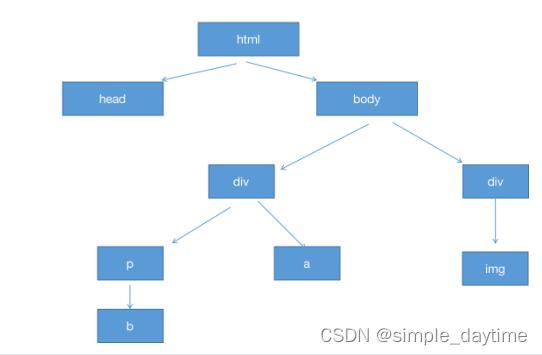
-
xpath基本概念
❀树:整个html(xml)代码结构是一个树结构
❀节点:树结构中的每一个元素(标签)就是一个节点
❀根节点(根元素):html或者xml最外面的那个标签(元素)
❀节点内容:标签内容
❀节点属性:标签属性
-
xml数据格式
xml和json一样,是一种通用的数据格式(大部分编程语言都支持的数据格式)
xml是通过标签(元素)的标签内容和标签属性来保存数据的。
<supermarket name="永辉超市" address="肖家河大厦"> <staffs> <staff id="s001" class="c1"> <name>小明</name> <position>收营员</position> <salary>4000</salary> </staff> <staff id="s002" class="c2"> <name>小花</name> <position>促销员</position> <salary>3500</salary> </staff> <staff id="s003" class="c1"> <name>张三</name> <position>保洁</position> <salary>3000</salary> </staff> <staff id="s004" class="c2"> <name>李四</name> <position>收营员</position> <salary>4000</salary> </staff> <staff id="s005" class="c1"> <name>王五</name> <position>售货员</position> <salary>3800</salary> </staff> </staffs> <goodsList> <goods discount="0.9"> <name>泡面</name> <price>3.5</price> <count>120</count> </goods> <goods class="c1"> <name>火腿肠</name> <price>1.5</price> <count>332</count> </goods> <goods> <name>矿泉水</name> <price>2</price> <count>549</count> </goods> <goods discount="8.5"> <name>面包</name> <price>5.5</price> <count>29</count> </goods> </goodsList> </supermarket> -
导入lxml模块
第一步:安装lxml模块 -
点击pycharm的Terminal输入
pip install lxml第二步:在项目里面导入
from lxml import etree -
xpath语法
❀创建树结构获取树的根节点
html.etree.XML(xml数据) # 需要解析的是xml数据 html.etree.HTML(html数据) # 需要解析的是html数据❀根据xpath获取指定标签
节点对象.xpath(路径): 返回路径对应的所有的标签,返回值是列表,列表中的元素是标签对象(节点对象)1.绝对路径:
/标签在树结构中的全路径 (路径必须从根节点开始写)。
2.相对路径:
路径开头用 “.” 标签当前节点(xpath前面是谁,'.'就代表谁),“…” 表示当前节点的上层节点。
3.全路径:
用**‘//’**开头的路径 - 在整个树中获取节点。
获取上面xml数据的一些实例:
# 绝对路径 res = root.xpath('/supermarket/staffs/staff/name/text()')以上是关于爬虫过程和反爬的主要内容,如果未能解决你的问题,请参考以下文章