如何可视化编写和编排你的 K8s 任务
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何可视化编写和编排你的 K8s 任务相关的知识,希望对你有一定的参考价值。
简介
K8s Job 是 Kubernetes 中的一种资源,用来处理短周期的 Pod,相当于一次性任务,跑完就会把 Pod 销毁,不会一直占用资源,可以节省成本,提高资源利用率。
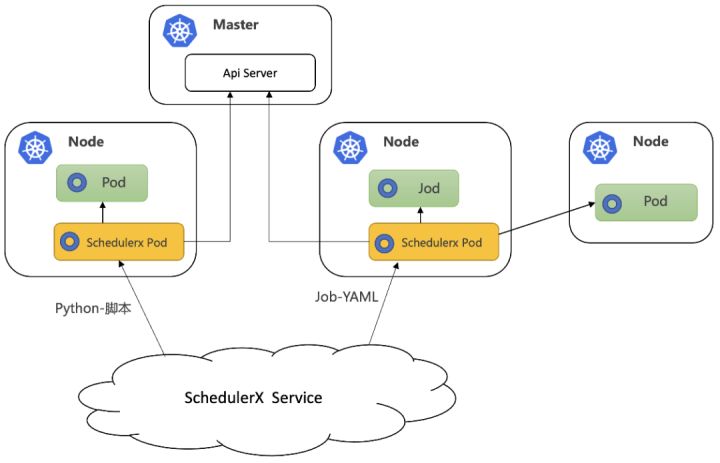
阿里任务调度 SchedulerX 和云原生结合,重磅推出可视化 K8s 任务,针对脚本使用者,屏蔽了容器服务的细节,不用构建镜像就可以让不熟悉容器的同学(比如运维和运营同学)玩转K8s Job,受益容器服务带来的降本增效福利。针对容器使用者,SchedulerX 不但完全兼容原生的 K8s Job,还能支持历史执行记录、日志服务、重跑任务、报警监控、可视化任务编排等能力,为企业级应用保驾护航。架构图如下:
特性一:快速开发 K8s 可视化脚本任务
Kubernetes 的 Job,常见用来做离线数据处理和运维工作(比如每天凌晨 2 点把 mysql 数据同步到大数据平台,每隔 1 小时更新一次 redis 缓存等),一般以脚本实现居多。这里以一个简单的场景举例子,来对比两种方案的差异。
Kubernetes 原生解决方案
K8s 调度的最小单位是 Pod,想跑脚本任务,需要提前把脚本打包到镜像里,然后在 YAML 文件中配置脚本命令,下面以通过 python 脚本查询数据库为例子:
- 编写 python 脚本 demo.py
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import MySQLdb
# 打开数据库连接
db = MySQLdb.connect("localhost", "testuser", "test123", "TESTDB", charset='utf8' )
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# SQL 查询语句
sql = "SELECT * FROM EMPLOYEE \\
WHERE INCOME > %s" % (1000)
try:
# 执行SQL语句
cursor.execute(sql)
# 获取所有记录列表
results = cursor.fetchall()
for row in results:
fname = row[0]
lname = row[1]
age = row[2]
sex = row[3]
income = row[4]
# 打印结果
print "fname=%s,lname=%s,age=%s,sex=%s,income=%s" % \\
(fname, lname, age, sex, income )
except:
print "Error: unable to fetch data"
# 关闭数据库连接
db.close()- 编写 Dockerfile
FROM python:3
WORKDIR /usr/src/app
COPY requirements.txt ./
RUN pip install --no-cache-dir -r requirements.txt
COPY demo.py /root/demo.py
CMD [ "python", "/root/demo.py" ]- 制作 docker 镜像,推到镜像仓库中
docker build -t registry.cn-beijing.aliyuncs.com/demo/python:1.0.0 .
docker push registry.cn-beijing.aliyuncs.com/demo/python:1.0.0- 编写 K8s Job 的 YAML 文件,image 选择第 3 步制作的镜像,command 的命令为执行脚本
apiVersion: batch/v1
kind: Job
metadata:
name: demo-python
spec:
template:
spec:
containers:
- name: demo-python
image: registry.cn-beijing.aliyuncs.com/demo/python:1.0.0
command: ["python", "/root/demo.py"]
restartPolicy: Never
backoffLimit: 4我们看到要在容器服务中跑脚本,需要这么多步骤,如果要修改脚本,还需要重新构建镜像和重新发布 K8s Job,非常麻烦。
阿里云解决方案
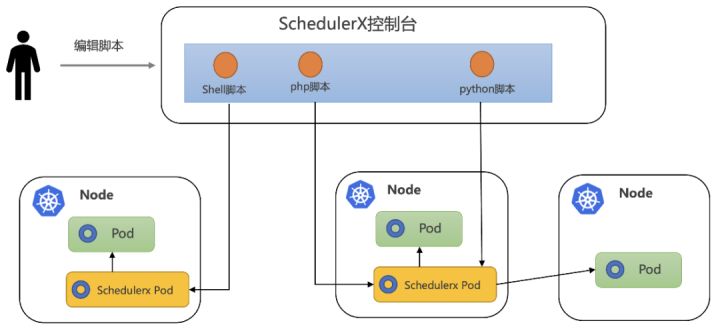
阿里任务调度 SchedulerX 结合云原生技术,提出了一套可视化的脚本任务解决方案,通过任务调度系统来管理脚本,直接在线编写脚本,不需要构建镜像,就可以将脚本以 Pod 的方式在用户的 K8s 集群当中运行起来,使用非常方便,如下图:
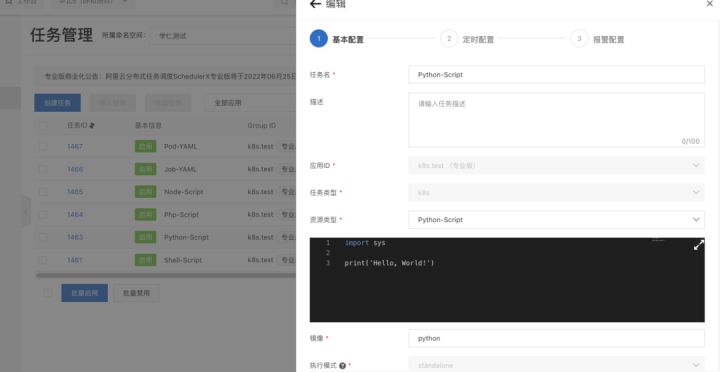
1. 在 SchedulerX 任务管理新建一个 K8s 任务,资源类型选择 Python-Script(当前支持shell/python/php/nodejs 四种脚本类型)
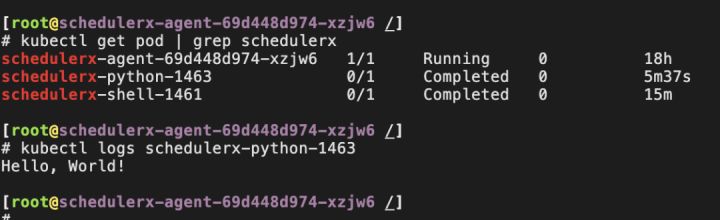
2. 点击运行一次,在 Kubernetes 集群中可以看到 pod 启动,pod 名称为 schedulerx-python-JobId
3. 在 SchedulerX 控制台也可以看到历史执行记录
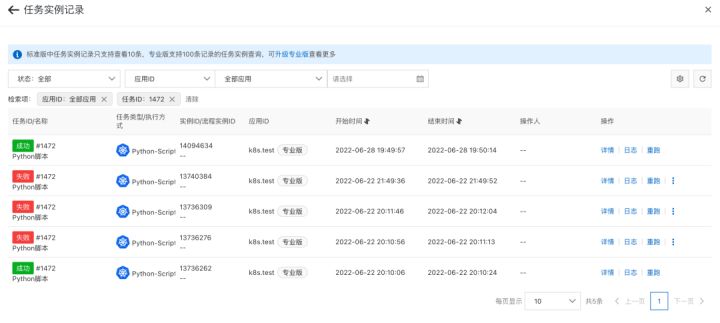
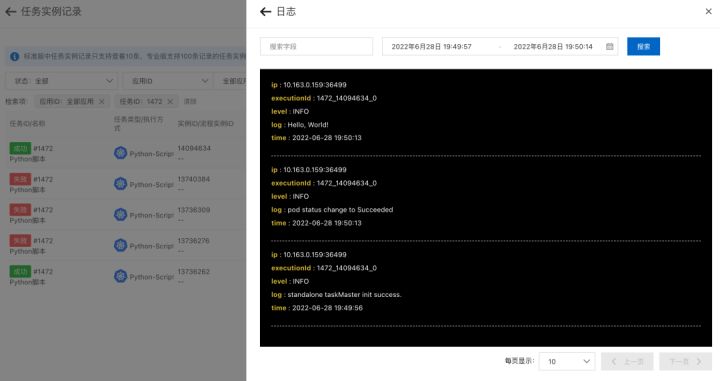
4. 在 SchedulerX 控制台可以看到 Pod 运行的日志
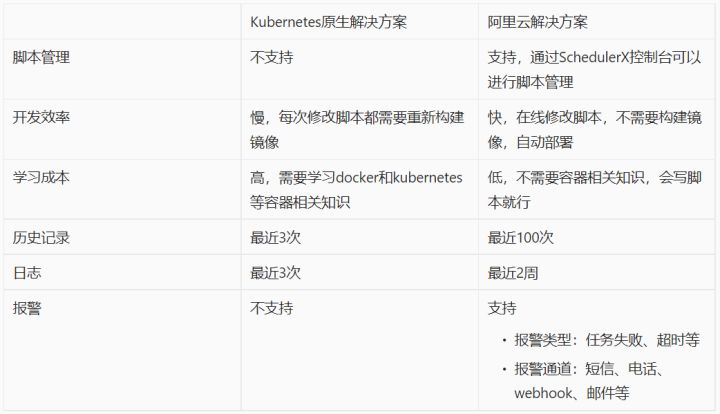
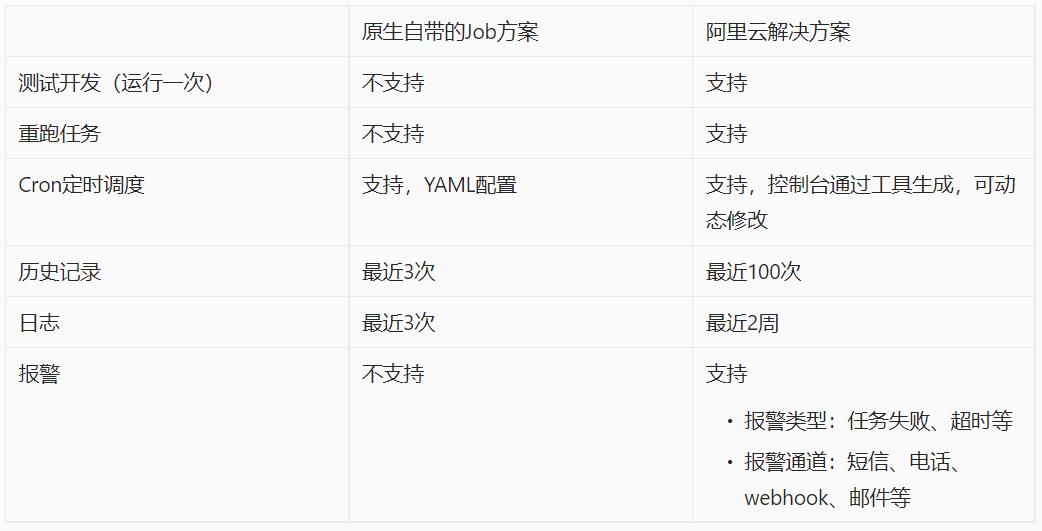
下面通过一个表格更方便的看到两个方案的差异:
特性二:完全兼容原生 K8s Job
SchedulerX 不但能够快速开发 K8s 脚本任务,屏蔽容器服务的细节,给不熟悉容器服务的同学带来福音,同时还能托管原生 K8s Job。
原生自带的Job方案
- Job
以官方提供的 Job 为例:
1. 编写 YAML 文件 pi.yaml,故意写一个错误,bpi(-1)是非法的
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl:5.34
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(-1)"]
restartPolicy: Never
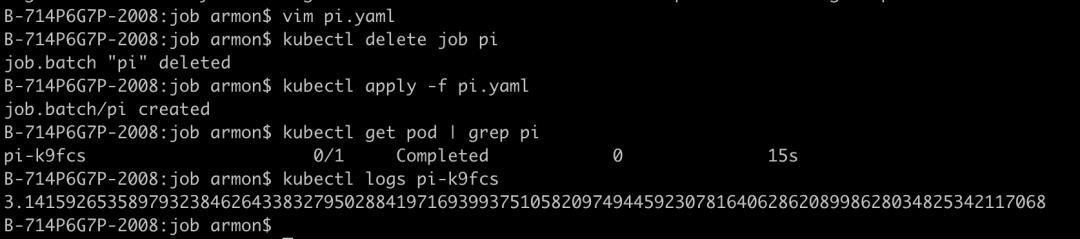
backoffLimit: 42. 在 K8s 集群中运行该 Job,并查看 Pod 的状态和日志:
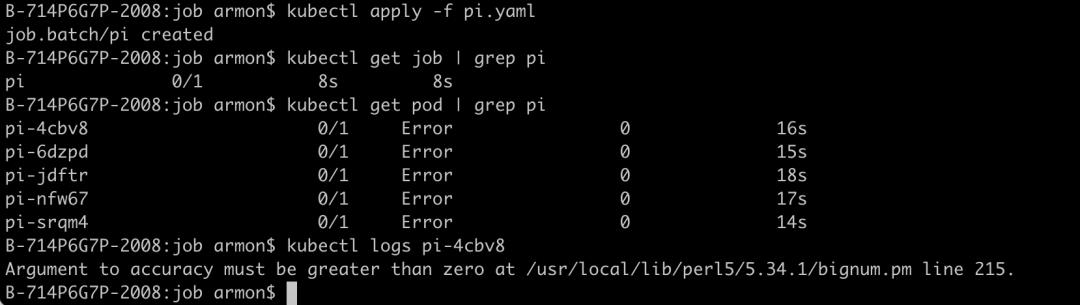
K8s 原生的 Job 不支持重跑,修改完 Job 后想要重跑,需要先删除,再重新 apply,非常麻烦。
- CronJob
以官方提供的 CronJob 为例:
1. 编写 hello.yaml
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: perl:5.34
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(100)"]
restartPolicy: OnFailure2. 在 K8s 集群中运行该 CronJob,查看 pod 历史记录和日志
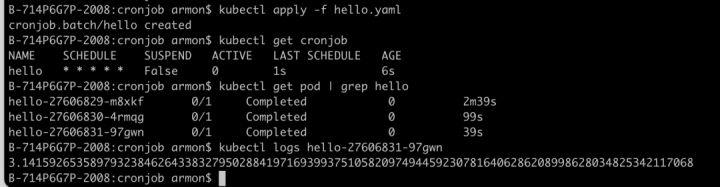
发现原生的 CronJob 只能查看最近3条执行记录,想要查看更久之前的记录无法看到,这在业务出现问题想排查的时候就变得尤为困难。
阿里云解决方案
阿里任务调度 SchedulerX 可以托管原生 K8s 任务,方便移植,使用 SchedulerX 托管,可以享有任务调度的特性,比如任务重跑、历史记录、日志服务、报警监控等。
1. 新建 K8s 任务,任务类型选择 K8s,资源类型选择 Job-YAML,打印 bpi(-1)
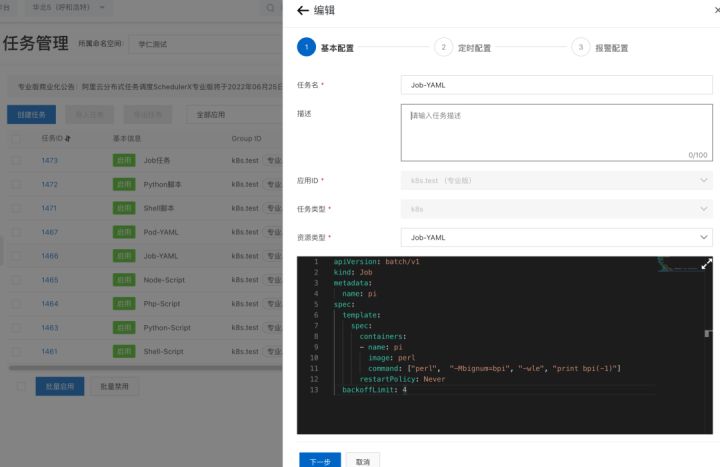
2. 通过工具来生成 cron 表达式,比如每小时第 8 分钟跑
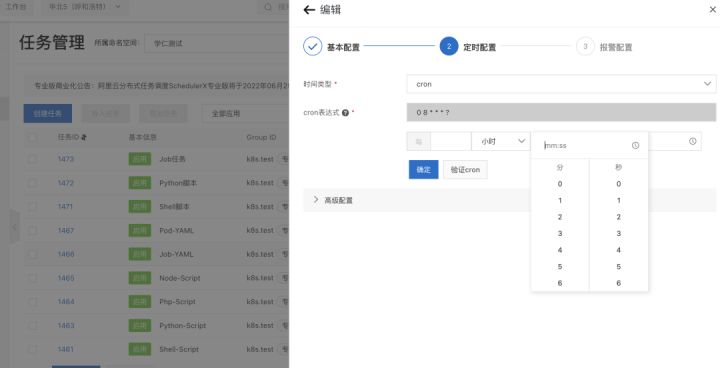
3. 调度时间还没到,也可以手动点击“运行一次”来进行测试
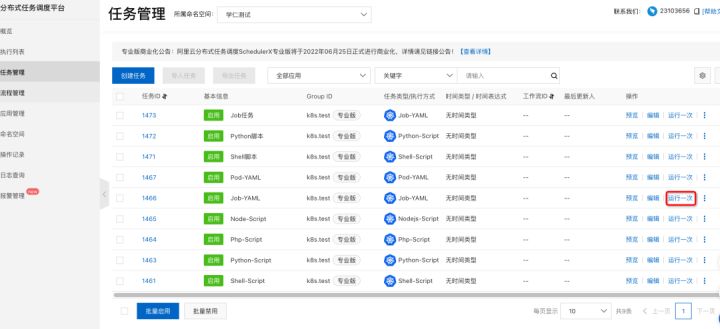
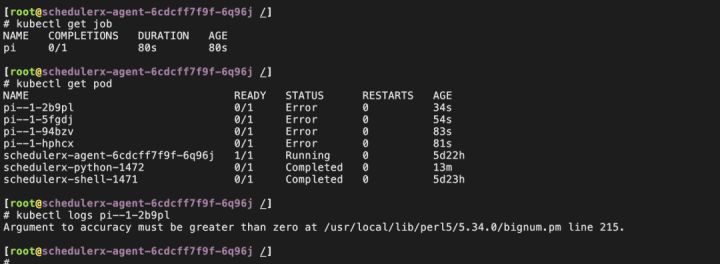
4. 在 K8s 集群中可以看到 Job 和 Pod 启动成功
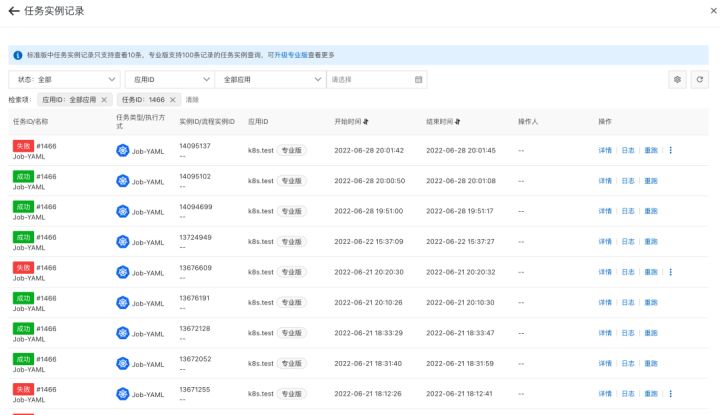
5. 在 SchedulerX 控制台也可以看到历史执行记录
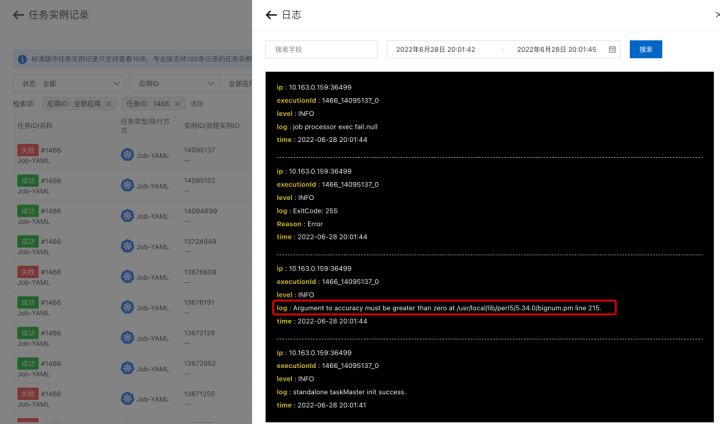
6. 在 SchedulerX 控制台可以看到任务运行日志
7. 在线修改任务的 YAML,打印 bpi(100)
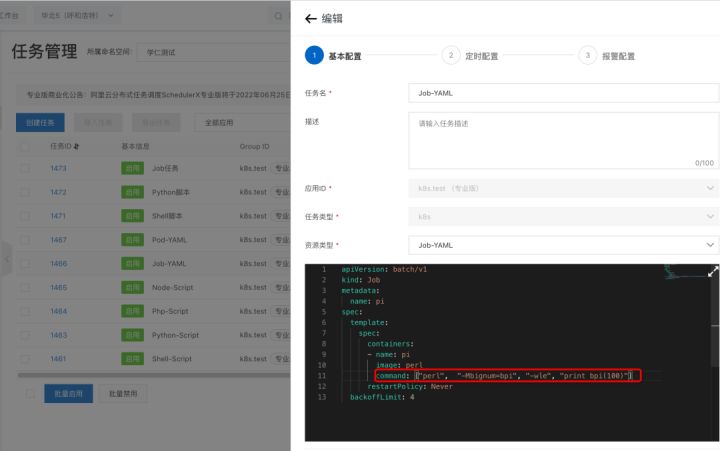
8. 不需要删除 Job,通过控制台来重跑任务
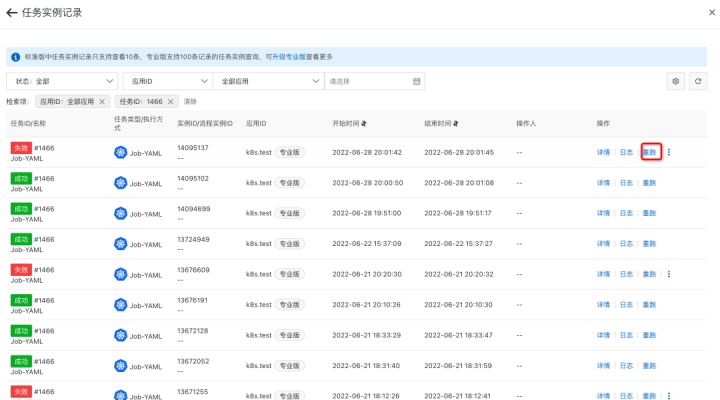
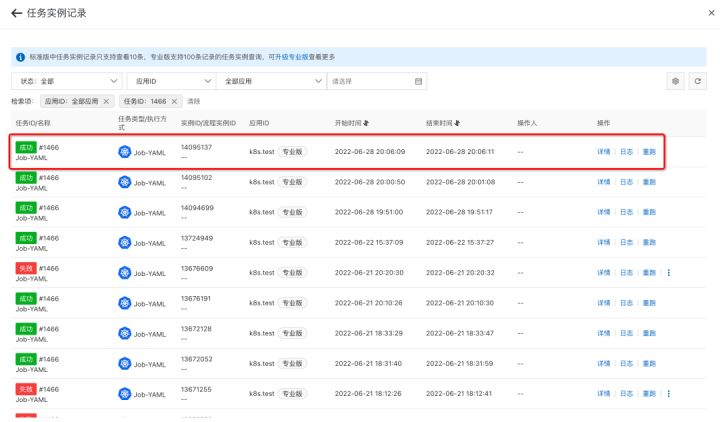
9. 任务重跑成功,且能看到新的日志
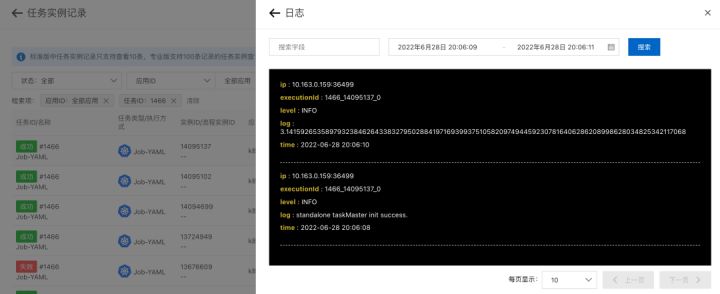
下面通过一个表格来对比两个方案的差异
特性三:增强原生 Job,支持可视化任务编排
在数据处理场景下,任务之间往往有依赖关系,比如 A 任务依赖 B 任务的完成才能开始执行。
Kubernetes 原生解决方案
当前 K8s 中主流的解决方案是使用 argo 进行工作流编排,比如定义一个 DAG 如下:
# The following workflow executes a diamond workflow
#
# A
# / \\
# B C
# \\ /
# D
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: dag-diamond
spec:
entrypoint: diamond
templates:
- name: diamond
dag:
tasks:
- name: A
template: echo
arguments:
parameters: [name: message, value: A]
- name: B
depends: "A"
template: echo
arguments:
parameters: [name: message, value: B]
- name: C
depends: "A"
template: echo
arguments:
parameters: [name: message, value: C]
- name: D
depends: "B && C"
template: echo
arguments:
parameters: [name: message, value: D]
- name: echo
inputs:
parameters:
- name: message
container:
image: alpine:3.7
command: [echo, "inputs.parameters.message"]我们看到构建这么简单的一个 DAG,就需要写这么多 YAML,如果依赖关系复杂,则 YAML 就变得非常难维护。
阿里云解决方案
阿里任务调度 SchedulerX 支持通过可视化的工作流进行任务编排
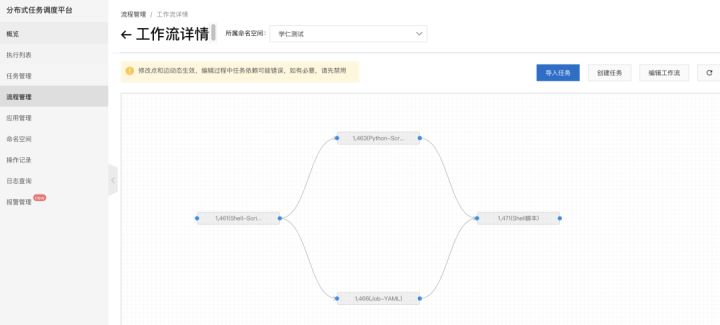
1. 创建一个工作流,可以导入任务,也可以在当前画布新建任务,通过拖拽构建一个工作流
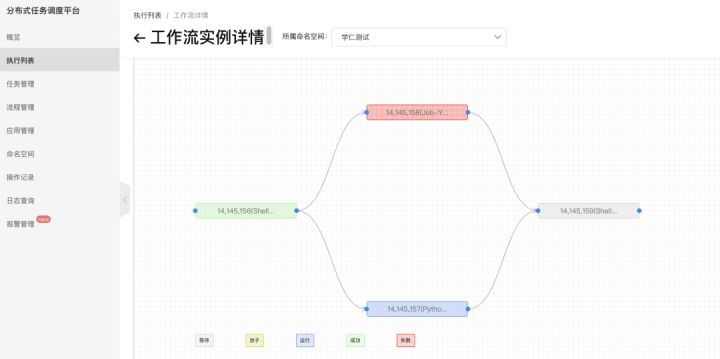
2. 点击运行一次,可以实时看到工作流的运行情况,方便排查任务卡在哪个环节:
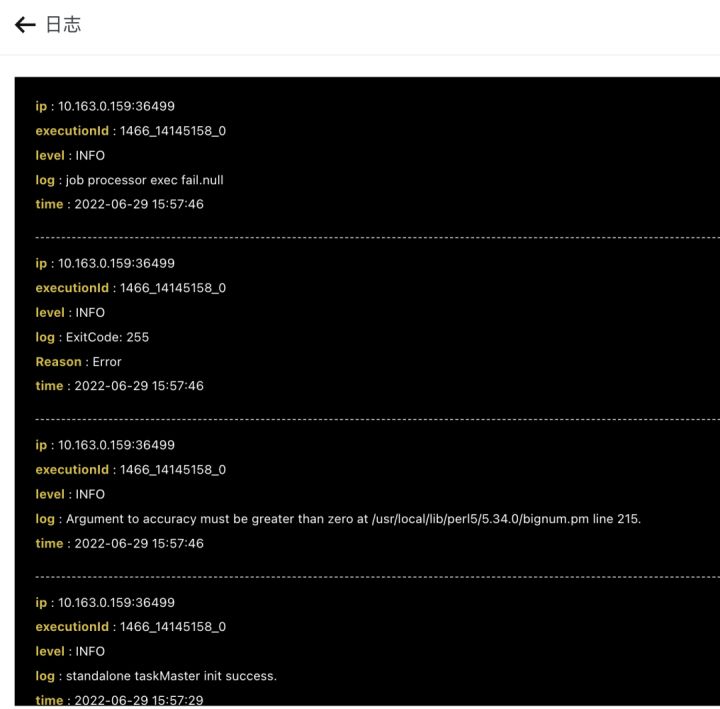
3. 如果有任务失败了,通过控制台查看日志
4. 把任务修改正确,在工作流实例图上,原地重跑失败的节点
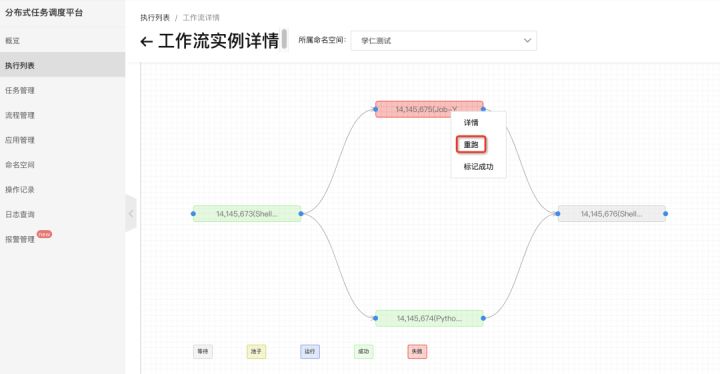
5. 失败的任务会重新按照最新的内容执行
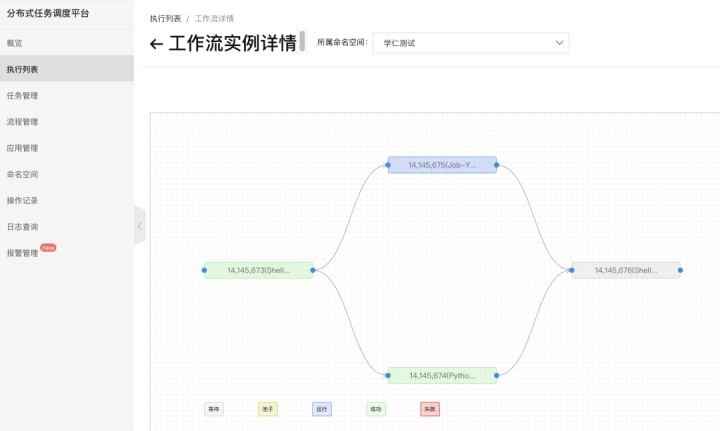
6. 当上游都执行成功,下游就可以继续执行了
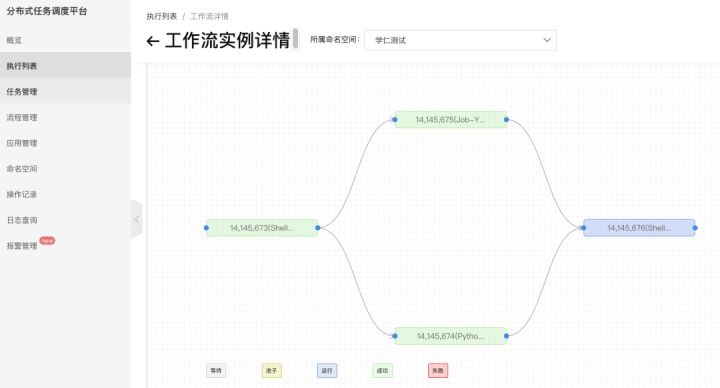
总结
通过任务调度 SchedulerX 来调度你的 K8s 任务,能够降低学习成本,加快开发效率,让你的任务失败可报警,出问题可排查,打造云原生可观测体系下的可视化 K8s 任务。
本文为阿里云原创内容,未经允许不得转载。
以上是关于如何可视化编写和编排你的 K8s 任务的主要内容,如果未能解决你的问题,请参考以下文章
k8s Jenkins pipeline 声明式语法和脚本式语法