HTTP -- HTTP内容协商HTTP认证HTTP缓存
Posted CodeJiao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HTTP -- HTTP内容协商HTTP认证HTTP缓存相关的知识,希望对你有一定的参考价值。
文章目录
1. HTTP内容协商
1.1 什么是内容协商
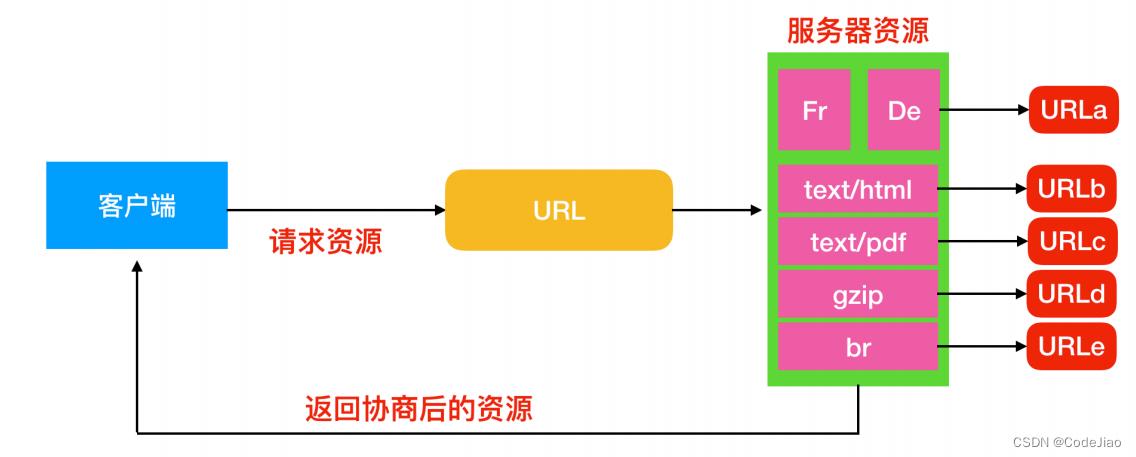
在HTTP中,内容协商是一种用于在同一URL上提供资源的不同表示形式的机制。内容协商机制是指客户端和服务器端就响应的资源内容进行交涉,然后提供给客户端最为适合的资源。内容协商会以响应资源的语言、字符集、编码方式等作为判断的标准。
1.2 内容协商的分类
- 服务器驱动协商(Server-driven Negotiation):这种协商方式是由服务器端进行内容协商。服务器端会根据请求首部字段进行自动处理。
- 客户端驱动协商(Agent-driven Negotiation):这种协商方式是由客户端来进行内容协商。
- 透明协商(Transparent Negotiation):是服务器驱动和客户端驱动的结合体,是由服务器端和客户端各自进行内容协商的一种方法。
内容协商的分类有很多种,主要的几种类型是Accept、Accept-Charset、Accept-Encoding、Accept-Language、Content-Language。
客户端用Accept头告诉服务器希望接收什么样的数据,而服务器用Content 头告诉客户端实际发送了什么样的数据。
1.3 为什么需要内容协商
在TCP/ IlP协议栈里,传输数据基本上都是header+body的格式。但TCP、UDP因为是传输层的协议,它们不会关心 body数据是什么,只要把数据发送到对方就算是完成了任务。
而HTTP协议则不同,它是应用层的协议,数据到达之后需要告诉应用程序这是什么格式数据。这就需要浏览器和服务器需要就数据的传输达成一致,浏览器需要告诉服务器自己希望能够接收什么样的数据,需要什么样的压缩格式,什么语言,哪种字符集等;而服务器需要告诉客户端自己能够提供的服务是什么。
1.4 内容协商标头
1.4.1 Accept(客户端能够接收的MIME类型)
HTTP请求标头会告知客户端能够接收的MIME类型是什么
MIME: MIME (Multipurpose Internet Mail Extensions)是描述消息内容类型的因特网标准。MIME消息能包含文本、图像、音频、视频以及其他应用程序专用的数据。
MIME类型其实就是一系列消息内容类型的集合。那么MIME类型都有哪些呢?
- 文本文件:text/html、text/plain、text/css、application/xhtml+xml、application/xml
- 图片文件:image/jpeg、image/gif、image/png
- 视频文件:video/mpeg、video/quicktime
- 应用程序二进制文件:application/octet-stream、application/zip
比如,如果浏览器不支持 PNG 图片的显示,那Accept 就不指定image/png,而指定可处理的image/gif 和 image/jpeg 等图片类型。
一般MIME类型也会和q这个属性一起使用,q是什么? q表示的是权重,来看一个例子。
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
这是什么意思呢?若想要给显示的媒体类型增加优先级,则使用q=来额外表示权重值,没有显示权重的时候默认值是1.0。
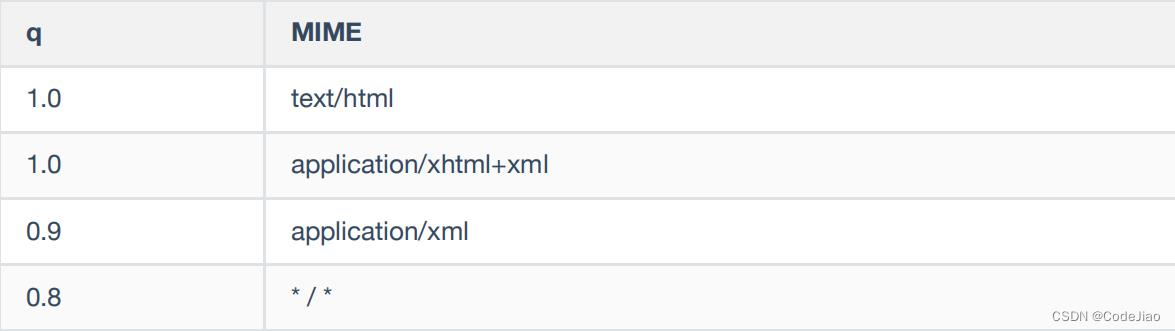
也就是说,这是一个放置顺序,权重高的在前,低的在后,application/xml;q=0.9是不可分割的整体。
1.4.2 Accept-Charset(客户端能够接受的字符编码)
Accept-Charset表示客户端能够接受的字符编码。Accept-Charset也是属于内容协商的一部分,它和Accept一样,也可以用q来表示字符集,用逗号进行分割,例如:
Accept-Charset: iso-8859-1
Accept-Charset: utf-8, iso-8859-1;q=0.5
Accept-Charset: utf-8, iso-8859-1;q=0.5, *;q=0.1
很多以Accept-*开头的标头,都是属于内容协商的范畴。
1.4.3 Accept-Encoding(客户端希望服务端返回的内容编码)
表示HTTP标头会标明客户端希望服务端返回的内容编码,这通常是一种压缩算法。Accept-Encoding也是属于内容协商的一部分,使用并通过客户端选择Content-Encoding内容进行返回。
下面是Accept-Encoding的使用方式:
Accept-Encoding: gzip
Accept-Encoding: compress
Accept-Encoding: deflate
Accept-Encoding: br
Accept-Encoding: identity
Accept-Encoding: *
Accept-Encoding: deflate, gzip;q=1.0, *;q=0.5
上面的几种表述方式就已经把 Accept-Encoding的属性列全了
- gzip:由文件压缩程序 gzip 生成的编码格式。
- compress :使用
Lempel-Ziv-Welch (LZW)算法的压缩格式 - deflate:使用zlib 结构和deflate压缩算法的压缩格式
- br:使用Brotli算法的压缩格式
- identity :使用身份功能(即无压缩或修改)。
*:匹配标头中未列出的任何内容编码,如果没有列出Accept-Encoding ,这就是默认值,并不意味着支持任何算法,只是表示没有偏好。;q=采用权重q值来表示相对优先级,这点与首部字段Accept相同。
1.4.4 Accept-Language
Accept-Language请求表示客户端需要服务端返回的语言类型,Accept-Language 也属于内容协商的范畴。服务端通过Content-Language进行响应,和Accept首部字段一样,按权重值q来表示相对优先级。例如:
Accept-Language: de
Accept-Language: de-CH
Accept-Language: en-US,en;q=0.5
1.4.5 Content-Encoding
我们上面讲过Accept-Encoding是客户端希望服务端返回的内容编码,但是实际上服务端返回给客户端的内容编码实际上是通过Content-Encoding返回的。内容编码是指在不丢失实体信息的前提下所进行的压缩。主要也是四种,和Accept-Encoding 相同,它们是 gzip、compress、deflate、identity。下面是一组请求/响应内容压缩编码:
Accept-Encoding: gzip, deflate
Content-Encoding: gzip
1.4.6 Content-Language
首部字段Content-Language 会告知客户端,服务器使用的自然语言是什么,它与 Accept-Language相对,下面是一组请求/响应使用的语言类型:
Content-Language: zh-CN

1.4.7 Content-Type
HTTP响应标头Content-Type说明了实体内对象的媒体类型,和首部字段Accept一样使用表示服务器能够响应的媒体类型。
Content-Type: text/ html; charset=UTF一8
2. HTTP认证
HTTP提供了用于访问控制和身份认证的功能。
2.1 通用HTTP认证框架
RFC 7235定义了HTTP身份认证框架,服务器可以根据其文档的定义来检查客户端请求。客户端也可以根据其文档定义来提供身份验证信息。
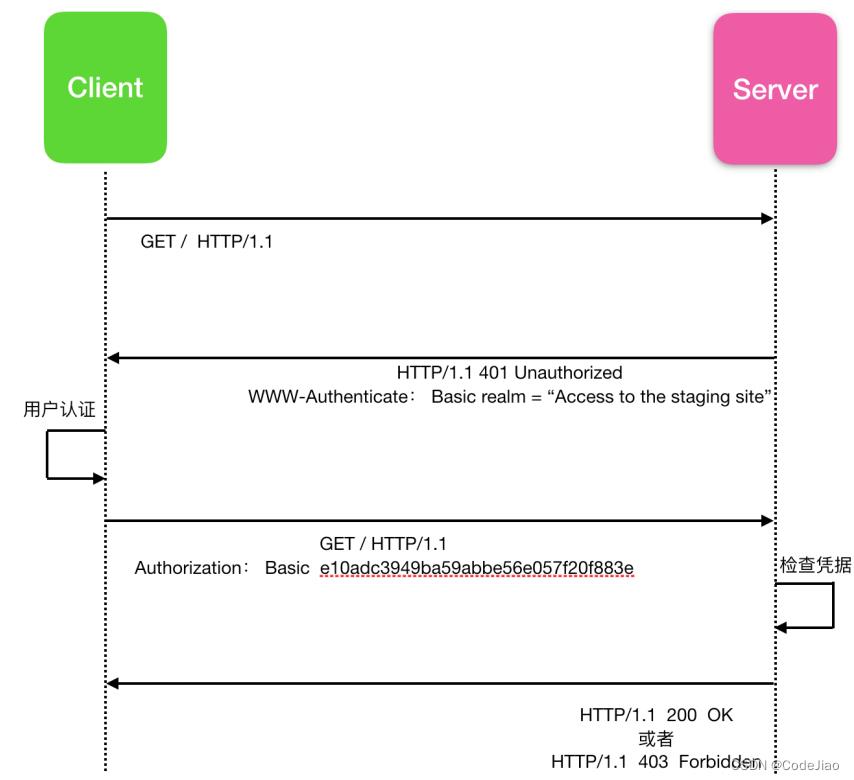
请求/响应的工作流程如下:服务器以401(未授权)的状态响应客户端告诉客户端服务器需要认证信息,客户端提供至少一个 www-Authenticate 的响应标头进行授权信息的认证。想要通过服务器进行身份认证的客户端可以在请求标头字段中添加认证标头进行身份认证,一般的认证过程如下:
首先客户端发起一个HTTP请求,不带有任何认证标头,服务器对此HTTP请求作出响应发现此HTTP信息未带有认证凭据,服务器通过www-Authenticate标头返回401告诉客户端此请求未通过认证。然后客户端进行用户认证,认证完毕后重新发起HTTP请求,这次HTTP请求带有用户认证凭据(注意,整个身份认证的过程必须通过HTTPS连接保证安全),到达服务器后服务器会检查认证信息:
- 如果不符合服务器认证信息,会返回 403 Forbidden表示用户认证失败。
- 如果满足认证信息,则返回200 OK。
2.2 代理认证
由于资源认证和代理认证可以共存,因此需要不同的头和状态码,在代理的情况下,会返回状态码407(需要代理认证),Proxy-Authenticate响应头包含至少一个适用于代理的情况,Proxy-Authorization请求头用于将证书提供给代理服务器。
2.2.1 Proxy-Authenticate
HTTP Proxy-Authenticate响应标头定义了身份验证方法,应使用该身份验证方法来访问代理服务器后面的资源。它将请求认证到代理服务器,从而允许它进一步发送请求。例如:
Proxy-Authenticate: Basic
Proxy-Authenticate: Basic realm="Access to the internal site"
2.2.2 Proxy-Authorization
Proxy-Authorization发生在代理服务器和客户端之间。它表示接收到从代理服务器发来的认证时,客户端会发送包含首部字段Proxy-Authorization的请求,以告知服务器认证所需要的信息。
2.3 禁止访问
如果代理服务器收到的有效凭据不足以获取对给定资源的访问权限,则服务器应使用 403 Forbidden 状态代码进行响应。与401 Unauthorized和407 Proxy AuthorizationRequired不同,该用户无法进行身份验证。
2.3.1 WWW-Authenticate 和 Proxy-Authenticate 头
WWW-Authenticate和 Proxy-Authenticate响应头定义了获得对资源访问权限的身份验证方法。他们需要指定使用哪种身份验证方案,以便希望授权的客户端知道如何提供凭据。它们的一般表示形式如下:
WWW-Authenticate: <type> realm=<realm>
Proxy-Authenticate: <type> realm=<realm>
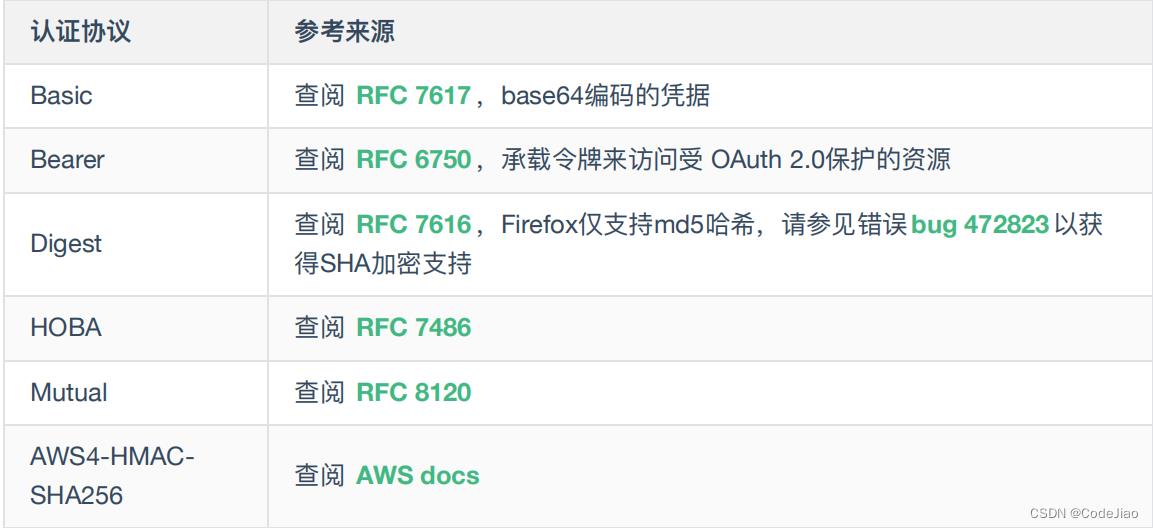
type是认证协议,Basic 是下面协议中最普遍使用的
realm用于描述保护区或指示保护范围,这可能是诸如Access to the staging site(访问登陆站点)或者类似的,这样用户就可以知道他们要访问哪个区域。
2.3.2 Authorization和 Proxy-Authorization标头
Authorization和 Proxy-Authorization请求标头包含用于通过代理服务器对用户代理进行身份验证的凭据。在此,再次需要类型,其后是凭据,取决于使用哪种身份验证方案,可以对凭据进行编码或加密。一般表示如下:
Authorization: Basic YWxhZGRpbjpvcGVuc2VzYW1l
Proxy-Authorization: Basic YWxhZGRpbjpvcGVuc2VzYW1l
3. HTTP缓存
通过把请求/响应缓存起来有助于提升系统的性能, Web 缓存减少了延迟和网络传输量因此减少资源获取锁需要的时间。由于链路漫长,网络时延不可控,浏览器使用HTTP获取资源的成本较高。所以,非常有必要把数据缓存起来,下次再请求的时候尽可能地复用。当Web 缓存在其存储中具有请求的资源时,它将拦截该请求并直接返回资源,而不是到达源服务器重新下载并获取。
HTTP缓存可以:
- 减轻服务器负载
- 提升系统性能
3.1 缓存分类
HTTP缓存有几种不同的类型,这些可以分为两个主要类别:私有缓存和共享缓存。
- 共享缓存:共享缓存是一种缓存,它可以存储多个用户重复使用的请求/响应。
- 私有缓存:私有缓存也称为专用缓存,它只适用于单个用户。
- 不缓存过期资源(可以是共享缓存也可是私有缓存):所有的请求都会直接到达服务器,由服务器来下载资源并返回。
3.1.1 不缓存过期资源
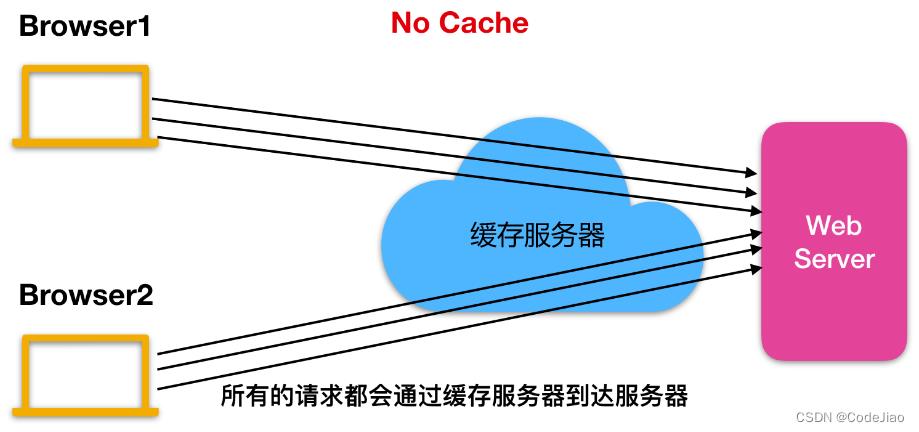
不缓存过期资源即浏览器和代理不会缓存过期资源,客户端发起的请求会直接到达服务器,可以使用no-cache标头代表不缓存过期资源。
使用no-cache 指令是为了防止从缓存中返回过期的资源(每次拿到资源后都与服务器的资源进行匹配,如果一致则返回该资源),例如下图所示
Cache-Control: no-cache
max-age可以用在请求或者响应中,当客户端发送带有max-age 的指令时,缓存服务器会判断自己缓存时间的数值和 max-age 的大小(max-age 的值是相对于请求时间的)。
- 如果比
max-age小,那么缓存有效,可以继续给客户端返回缓存的数据。 - 如果比
max-age大,那么缓存服务器将不能返回给客户端缓存的数据。
如果max-age = 0,那么缓存服务器将会直接把请求转发到服务器。因此也可以使用 max-age = 0来实现不缓存的效果。
Cache-Control: max-age = 0
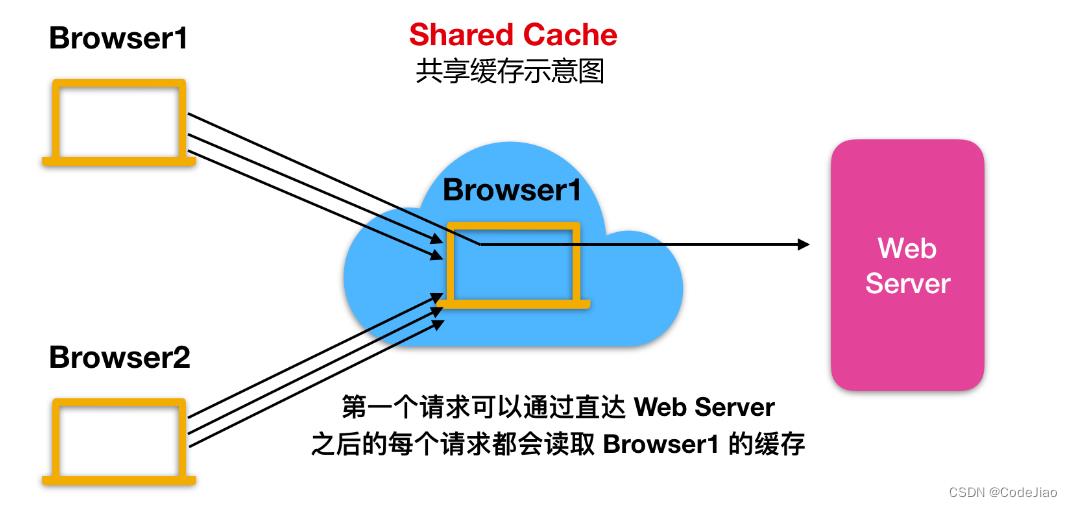
3.1.2 共享缓存和私有缓存
public属性只出现在客户端响应中,表示响应可以被任何缓存所缓存。在计算机网络中,分为两种缓存,共享缓存(public)和私有缓存(private),如下所示:
Cache-Control: public
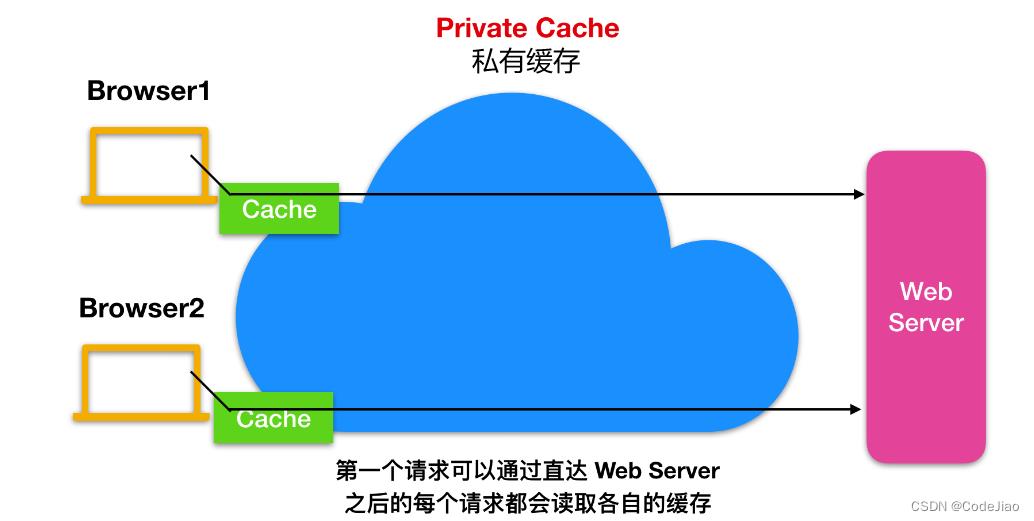
当指定private指令后,响应只以特定的用户作为对象,这与public 的用法相反,缓存服务器只对特定的客户端进行缓存,其他客户端发送过来的请求,缓存服务器则不会返回缓存。
Cache-Control: private
3.2 缓存控制
no-cache:
no-cache很容易和no-store 混淆,一般都会把no-cache 认为是不缓存,其实不是这样。no-store才是真正意义上的不缓存,每次服务器接受到客户端的请求后,都会返回最新的资源给客户端。
Cache-Control: no-store
must-revalidate:
表示一旦资源过期,缓存就必须在原始服务器上成功验证的情况下才使用其过期的数据。
Cache-Control: must-revalidate
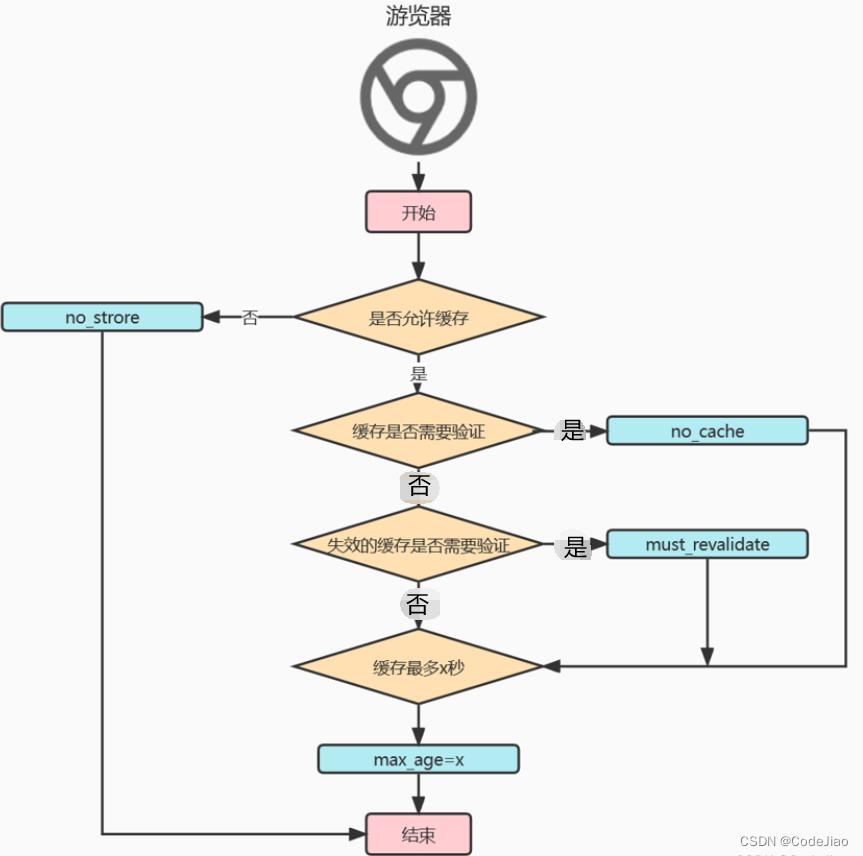
no-store 、no_cache 、must-revalidate和max-age可以一起看,下面是一个这四个标头的流程图:
3.4 缓存验证
3.4.1 ETag
ETag对于条件请求来说真是太重要了。因为条件请求就是根据ETag 的值进行匹配的。
ETag响应头是特定版本的标识,它能够使缓存变得更高效并能够节省带宽,因为如果缓存内容未发生变更,Web服务器则不需要重新发送完整的响应。除此之外,ETag能够防止资源同时更新互相覆盖。
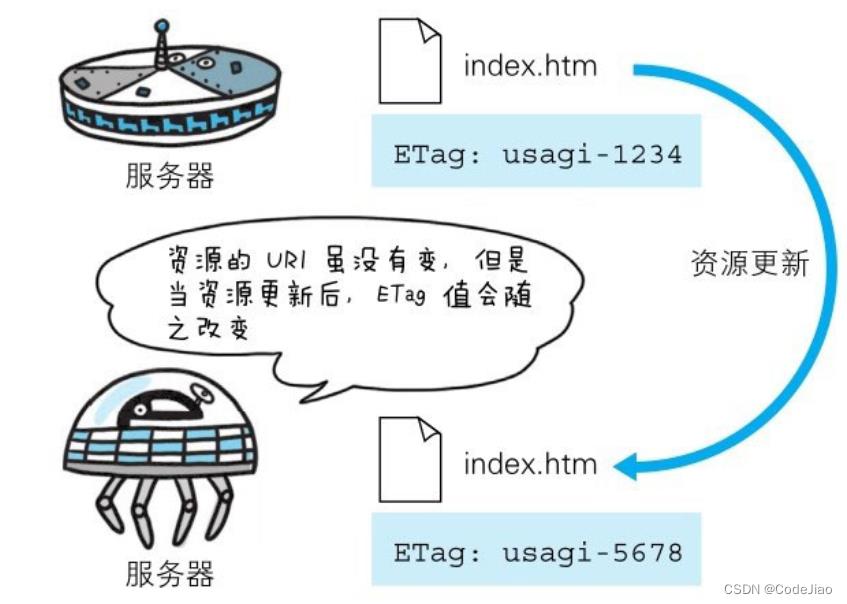
如果给定URL上的资源发生变更,必须生成一个新的ETag值,通过比较它们可以确定资源的两个表示形式是否相同。
ETag值有两种,一种是强ETag,一种是弱ETag:
- 强ETag值,无论实体发生多么细微的变化都会改变其值,一般的表示如下
ETag: "33a64df551425fcc55e4d42a148795d9f25f89d4"
- 弱ETag值,弱ETag值只用于提示资源是否相同。只有资源发生了根本改变,产生差异时才会改变ETag 值。这时,会在字段值最开始处附加
W/。
ETag: W/"0815"
3.4.2 If-Match
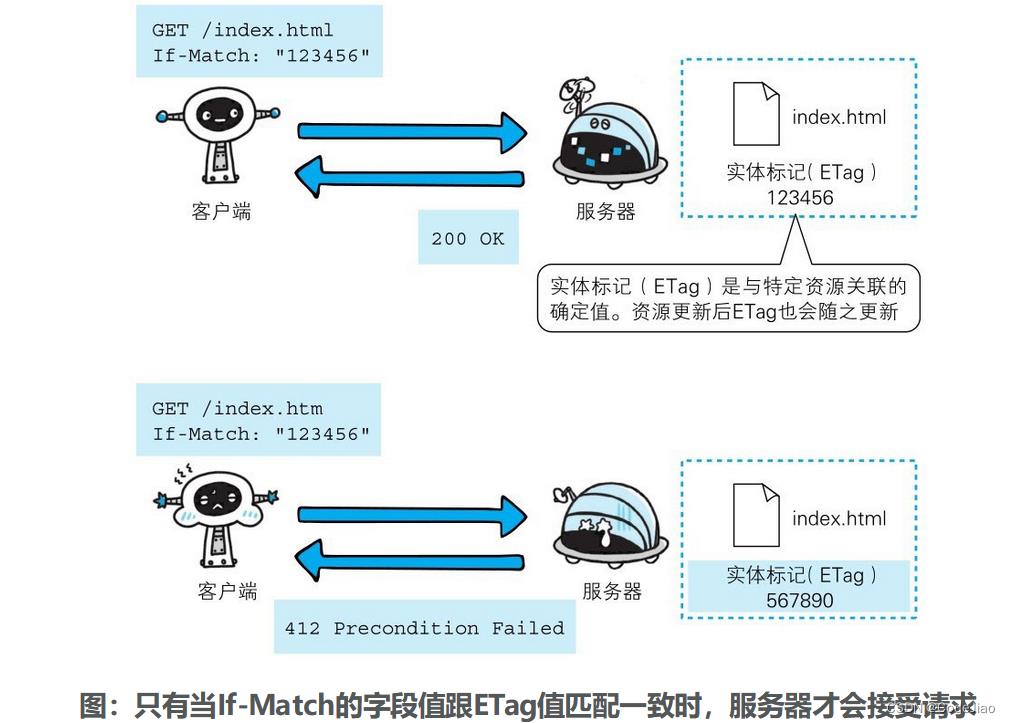
- 服务器会比对If-Match的字段值和资源的ETag值,仅当两者一致时,才会执行请求。
- 反之,则返回状态码412 Precondition Failed的响应。还可以使用星号(*)指定If-Match的字段值。针对这种情况,服务器将会忽略ETag的值,只要资源存在就处理请求。
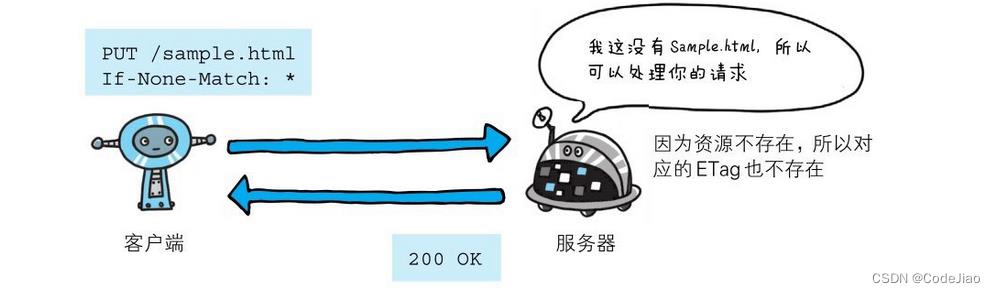
4.2.3 lf-None-Match
只有在If-None-Match的字段值与ETag值不一致时,可处理该请求。与If-Match首部字段的作用相反
以上是关于HTTP -- HTTP内容协商HTTP认证HTTP缓存的主要内容,如果未能解决你的问题,请参考以下文章