Python Http请求和HTML的解析
Posted qifengdao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python Http请求和HTML的解析相关的知识,希望对你有一定的参考价值。
日常中我们经常会遇到用代码去HTTP请求一些地址或者返回的是html,然后解析一些其中的数据。今天我们来聊一聊。
Http请求模块requests和解析html的BeautifulSoup。
基本用法
-
如果没有安装requests 请安装
pip install requests
import requests
x = requests.get('https://www.baidu.com/')
# 返回 http 的状态码,200
print(x.status_code)
# 响应状态的描述,ok
print(x.reason)
# 返回编码,utf-8
print(x.apparent_encoding)
# 返回页面内容
print(x.content)
-
如果没有安装BeautifulSoup请安装
pip install bs4
pip install lxml
应用可参考https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
from bs4 import BeautifulSoup
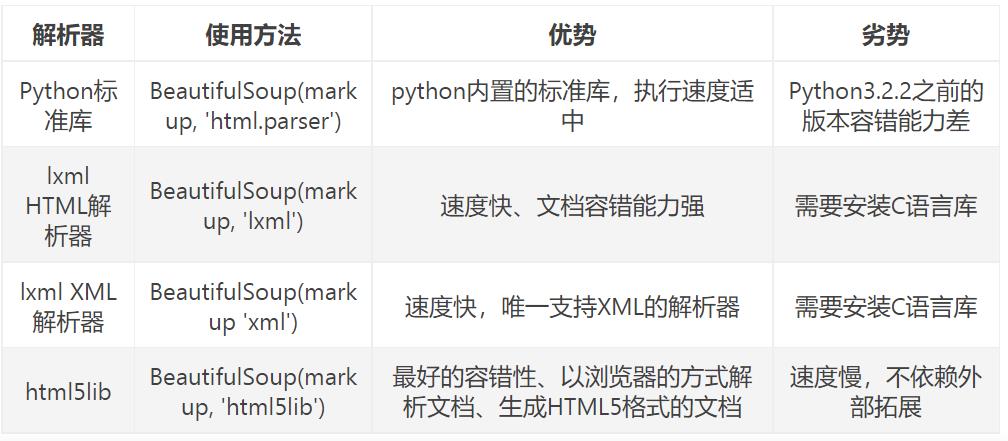
#创建一个对象
soup = BeautifulSoup(con, "html.parser")
#我们需要的用户名在<div class="auth">标签下,利用BeautifulSoup获取内容
name = soup.find("div", class_="auth").text
#通过 id 选择器查找
print(soup.select('#link1'))
#层级选择器 查找
print(soup.select('p #link1'))
#标签选择器查找
print(soup.select('title'))
#通过类选择器查找
print(soup.select('.sister'))
#通过属性选择器查找
print(soup.select('a[class="sister"]'))
#获取文本内容 get_text()
print(soup.select('title')[0].get_text())
#获取属性 get('属性的名字')
print(soup.select('a')[0].get('href'))
GET用法实例
#post请求某http页面,获得累计销售额:
headerss = 'Accept': '*/*', 'Accept-Language': 'zh-CN,zh;q=0.9'
,'Connection': 'keep-alive'
,'Cookie': 'uab_collina=16557834343430'
,'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
,'X-Requested-With': 'XMLHttpRequest'
url= "http://www.sample.test.com/search?sortNew=0&period=30"
r = requests.get(url = url, timeout=10, headers=headerss)
con = r.content.decode('utf-8')
soup = BeautifulSoup(con, "html.parser")
# 解析获取tr元素列表
tr_items = soup.tbody.select("tr")
for child in tr_items:
mon = child.select("td")[1].get_text().replace(",", "")
if (mon.find("亿")>=0):
mon = float(mon.replace("w", "")) * 10000 * 10000
elif (mon.find("w")>=0) :
mon = float(mon.replace("w", "")) * 10000
else :
mon = float(mon.replace("w", ""))
amount = amount + monPOST用法实例
header1= 'Accept': '*/*', 'Accept-Language': 'zh-CN,zh;q=0.9'
,'Connection': 'keep-alive'
,'Cookie': 'uab_collina=165578057852259411739609;85881271'
,'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
,'X-Requested-With': 'XMLHttpRequest'
, 'Origin': 'http://www.sample.test.com'
,'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8'
store_url= "http://www.sample.test.com/promotion"
#注意header中的Content-Type传值
datas="SendFrom=&hasCoupon=-1&page="
datas = datas.format(province, page)
r = requests.post(url=store_url, data=datas.encode('utf-8'), headers=header1)
con = r.content.decode('utf-8')
soup = BeautifulSoup(con, "html.parser")
item=[]
#查找所有符合class的table元素并获取第一个,然后筛选其中的所有tr元素
for each in soup.find_all('table','class':'location-table')[1].select("tr"):
item..append(each.select("td")[0].select("a")[1].get_text().strip())学习更多技术,可以关注gongzhong号,早起的码农
以上是关于Python Http请求和HTML的解析的主要内容,如果未能解决你的问题,请参考以下文章