PointNeXt:个人阅读笔记(WZS的博客)
Posted Zongshun Wang的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PointNeXt:个人阅读笔记(WZS的博客)相关的知识,希望对你有一定的参考价值。
## 标题PointNeXt:个人阅读笔记(WZS)
1. Abstract
我们发现,性能提高的很大一部分是由于改进了培训策略,即数据扩充和优化技术,以及增加了模型大小,而非架构创新。
贡献 :
1.我们发现,性能提高的很大一部分是由于改进了培训策略,即数据扩充和优化技术,以及增加了模型大小,而非架构创新。
2.我们将倒残差瓶颈设计和可分离的MLP引入pointnet++,以实现高效的模型缩放,并提出了point net的下一个版本PointNeXt。PointNeXt可以灵活扩展,在3D分类和分割任务上都优于最先进的方法。
2.简介
在这项工作中,我们重新审视了经典且广泛使用的网络PointNet++,并发现其全部潜力尚待挖掘,主要是由于在PointNet++时代还没有出现两个因素:
(1)先进的训练策略

2)有效的模型缩放策略架构的更改。**
例如:
1.在训练过程中随机dropping color会意外地将PointNet++的测试性能提高5.9%的平均IoU(mIoU)
2.采用标签平滑[43]可以将ScanObjectNN[48]的总体精度(OA)提高1.3%。
3.我们在PointNet++中引入了残差连接、反向瓶颈设计和可分离的MLP。
3.方法论:从PointNet++到PointNeXt
我们的探索主要集中在两个方面:
(1)训练更新,以改进数据扩充和优化技术;
(2)架构更新,以探索感受野缩放和模型缩放。这两个方面对模型的性能都有重要影响,但之前的研究对其探索不足。
3.1.1数据扩充数据
扩充是提高神经网络性能的最重要策略之一:
我们以PointNet++为基线开始研究,并使用原始数据扩充和优化技术进行训练。我们删除每个数据扩充以检查它是否必要。我们添加了有用的增强,但删除了不必要的增强。然后,我们系统地研究了代表性作品中使用的所有
数据增强: 数据缩放,如点重采样[60]和加载整个场景作为输入[15]、随机旋转、随机缩放、平移点云、抖动以向每个点添加独立噪声,高度附加[47](即,沿物体重力方向附加每个点的测量值作为附加输入特征)、自动调整颜色对比度的颜色自动对比度[62]和随机用零值替换颜色的颜色下降。
3.1.2****优化技术优化
优化技术包括: ==损失函数、优化器、学习率调度器和超参数,==对神经网络的性能也至关重要。
我们发现了一组改进的优化技术,通过可观的差额。标签平滑、AdamW和余弦衰减的交叉熵通常可以提高各种任务的性能。
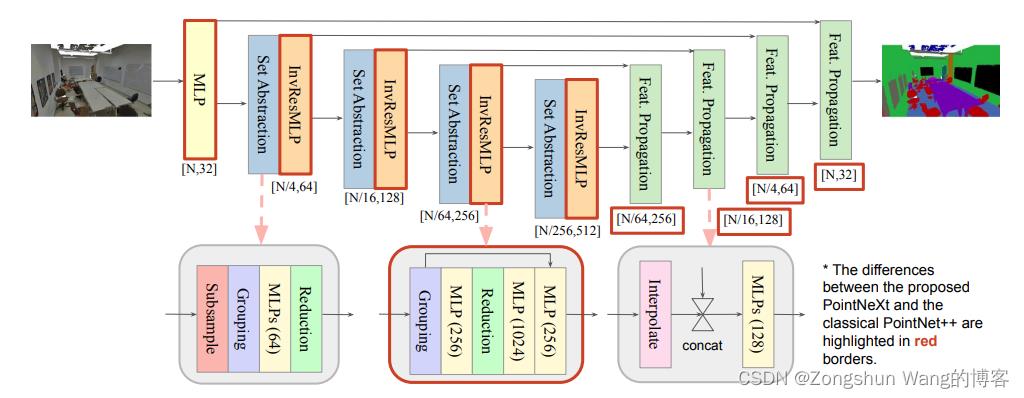
图2:PointNeXt架构。PointNeXt与PointNet++[32]共享相同的集合抽象和特征传播块,同时在开始时添加额外的MLP层,并使用建议的反向剩余MLP(InvResMLP反向残差mlp)块扩展架构。这里,我们以PointNeXt为例进行分段。有关分类架构,请参阅附录。
3.2架构现代化:小修改→ 重大改进
将PointNet++[32]现代化为拟议的PointNeXt。现代化包括两个方面:
(1)感受野标度
(2)模型标度。
3.2.1感受野标度
感受野是神经网络设计空间中的一个重要因素[42,8]。在点云处理中,至少有两种方法可以缩放感受野:
(1)采用更大的半径查询邻域。
(2)采用层次结构。
3.2.2模型缩放
我们发现,添加更多SA块或使用更多通道都不会显著提高精度,同时导致吞吐量显著下降(参见第4.4.2节),主要原因是梯度消失和过度拟合。因此,在本小节中,我们将研究如何以有效的方式扩展PointNet++。==我们建议在每个阶段的第一个SA块之后附加一个反向残差MLP(InvResMLP)块,以实现有效的模型缩放。==InvResMLP构建在SA块上如图2中下部所示。
一、InvResMLP和SA之间有三个区别。
(1) 在输入和输出之间添加一个残差网络连接,以缓解消失梯度问题,尤其是当网络更深时。
(2) 为了减少计算量和加强逐点特征提取,引入了可分离的MLP。虽然原始SA块中的所有3层MLP都是基于邻域特征计算的,但InvResMLP将MLP分为一个基于邻域特征计算的层(分组层和缩减层之间)和两个用于点特征的层(缩减后),这是受ASSANet[34]和ConvNeXt[27]启发的。
(3) 利用反向瓶颈设计将第二个MLP的输出通道扩展了4倍,以丰富特征提取。与附加原始SA块相比,附加InvResMLP块可显著提高性能(见第4.4.2节)。
二、体系结构中的三个变化。
(1)将用于分类的SA块的数量从2个缩放到4个,同时在每个阶段保持用于分割的原始数量(4个块)。
(2)我们使用了一个对称解码器,其中它的通道大小被改变用来以匹配编码器。
(3)我们添加了一个stem MLP,即在体系结构开始处插入的附加MLP层,以将输入点云映射到更高的维度。
4 Experiments
(所有方法的吞吐量都是使用NVIDIA Tesla V100 32GB GPU和32核Intel Xeon@2.80GHz CPU测量的。)
**实验设置。**我们使用==交叉熵损失和标签平滑来训练PointNeXt[43],AdamW优化器[28],初始学习率lr=0.002,权重衰减10−4,具有余弦衰减,批大小为32,==用于所有任务,除非另有规定。
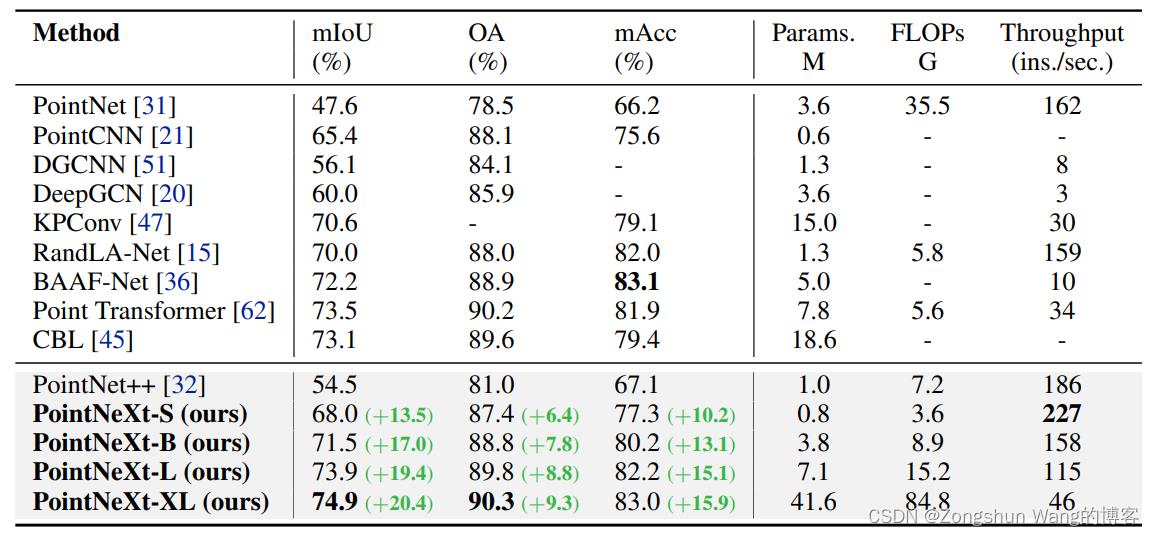
4.1 S3DIS上的三维语义分割
S3DIS[1](斯坦福大学大型3D室内空间)是一个具有挑战性的基准,由6个大型室内区域、271个房间和13个语义类别组成。
关于PointNeXt在S3DIS 5区的结果,以及与SOTA进行比较:
stem MLP的通道大小表示为C,InvResMLP块的数量表示为B。C越大,网络的宽度越大(即宽度缩放),而B越大,网络的深度越大(即深度缩放)。请注意,当B=0时,每个阶段仅使用一个SA块。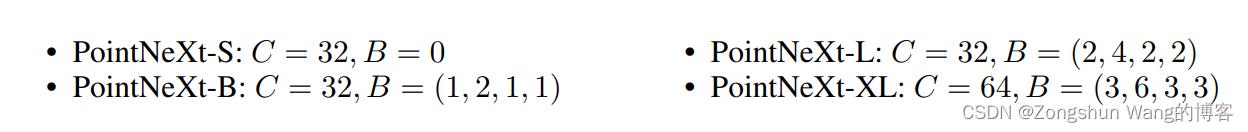
4.2 ScanObjectNN上的3D对象分类
ScanObjectNN[49]包含约15000个实际扫描对象,这些对象分为15个类,有2902个唯一的对象实例。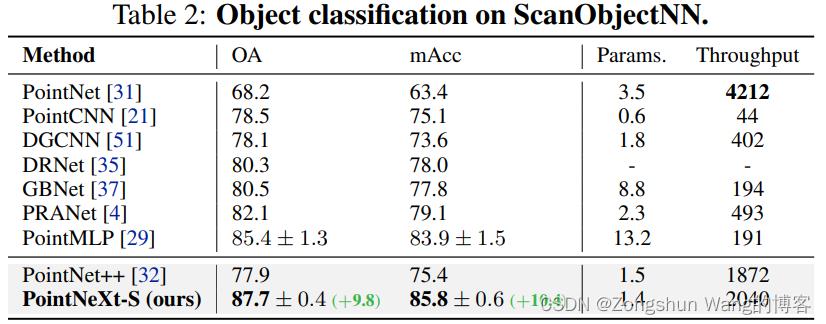
有在这个基准测试中使用升级的PointNeXt变体,因为我们发现使用PointNeXt-S的性能已经饱和,这主要是由于数据集的规模有限。
4.3 ShapeNet零件上的三维对象零件分割
####### ShapeNet part[59]是一个用于零件分割的对象级数据集。它由16个不同形状类别的16880个模型组成,每个类别有2-6个零件,总共有50个零件标签。
###4.4训练策略
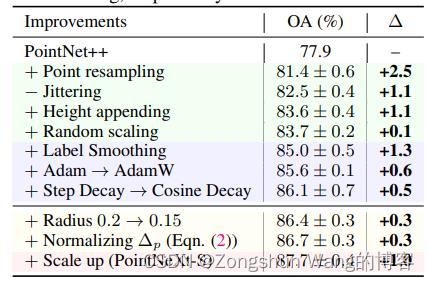
数据扩充是我们为使PointNet++现代化而研究的第一个方面。根据表中的观察结果,我们得出四个结论。
(1)数据缩放:可提高分类和分割任务的性能。例如,在ScanObjectNN上,点的重采样可以将性能提高2.5%。将整个场景作为输入,而不是像PointNet++[32]和其他以前的工作[47、20、34]那样使用块或球体子采样输入,可以将分割结果提高1.1个百万像素。
(2)高度附加提高了性能,尤其是在对象分类方面。高度附加使网络了解实际大小从而提高了精确度(+1.1%OA)。
(3)颜色下降是一种强大的增强,可以显著提高有颜色的任务的性能。在S3DIS区域5上,仅采用颜色下降即可增加5.9%的mIoU。我们假设,颜色下降会迫使网络更加关注点之间的几何关系,从而提高性能。
(4)更大的模型支持更强的数据扩充。虽然随机旋转会使S3DIS上的PointNet++性能降低0.3%mIoU(表5数据扩充部分的第二行),但它对更大规模的模型是有益的(例如,在PointNeXt-B上提高1.5%mIoU)。ScanObjectNN上的另一个示例显示,消除随机抖动也会增加1.1%的OA。总的来说,随着数据的增强,ScanObjectNN上的PointNet++的OA和S3DIS区域5上的mIoU分别增加了5.8%和9.5%。
4.5优化技术
包括损失函数、优化器、学习率调度器和超参数。如表所示。4和5、标签平滑、AdamW[28]优化器和余弦衰减始终可以提高分类和分割任务的性能。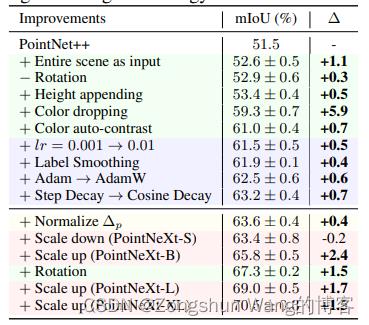
4.6 模型缩放
感受野缩放包括半径缩放和归一化
在ScanObjectNN上,使用stem MLP、对称解码器和SA块中的残差连接的PointNeXt-S将OA提高了1.0%。通过使用建议的InvResMLP的更多块来放大PointNeXt-S,可以进一步展示大规模S3DIS数据集的性能(从63.8%到70.5%mIoU)
5 相关工作
基于体素的方法和基于多视图的方法相比,基于点的方法直接使用非结构化格式处理点云。PointNet[31]是基于点的方法的先驱,它提出通过将特征提取限制为逐点的方式,用共享MLP对点的置换不变性进行建模。PointNet++[32]通过捕获局部几何结构来改进PointNet。目前,大多数基于点的方法侧重于局部模块的设计。依赖于图形神经网络。将点云投影到伪网格上,以允许进行规则卷积。通过局部结构确定的权重自适应聚合邻域特征。此外,最近的方法利用transformer式网络通过自我关注提取局部信息。我们的工作并没有遵循局部模块设计的这一趋势。相比之下,我们将注意力转移到另一个重要但基本上未得到充分探索的方面,即培训和扩展策略。
最近关于图像分类的文献研究了训练策略。在点云领域,SimpleView首次表明训练策略对神经网络的性能有很大影响。然而,SimpleView只是采用了与DGCNN相同的训练策略。相反,我们进行了系统研究,量化了每种数据增强和优化技术的效果,并提出了一套改进的培训策略,以提高PointNet++和其他代表性作品的性能。
模型缩放可以显著提高网络的性能,如各领域的开创性工作所示。与使用参数小于2M的PointNet++相比,当前大多数主流网络由大于10m的参数组成,如KPConv(15M)和PointMLP(13M)。在我们的工作中,我们探索了能够以有效的方式扩展PointNet++的模型扩展策略。我们提供了有关可提高性能的扩展技术的实用建议,即使用剩余连接和反向瓶颈设计,同时使用可分离的MLP保持吞吐量。
以上是关于PointNeXt:个人阅读笔记(WZS的博客)的主要内容,如果未能解决你的问题,请参考以下文章