Tensorflow:可视化学习TensorBoard
Posted -柚子皮-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tensorflow:可视化学习TensorBoard相关的知识,希望对你有一定的参考价值。
用 TensorBoard 来展现 TensorFlow 图,绘制图像生成的定量指标图以及显示附加数据(如其中传递的图像)。
tensorflow.summary
scalar一般用于数值的显示
如
tf.summary.scalar(softmax_cross_entropy)
tf.summary.scalar(loss)
histogram一般用于向量的分布显示
tf.summary.histogram('histogram', var)
多个histogram合并到一起
variance_shrinking_normal = tf.random_normal(shape=[1000], mean=0, stddev=1-(k)) tf.summary.histogram("normal/shrinking_variance", variance_shrinking_normal) # Let's combine both of those distributions into one dataset
normal_combined = tf.concat([mean_moving_normal, variance_shrinking_normal], 0)
# We add another histogram summary to record the combined distribution
tf.summary.histogram("normal/bimodal", normal_combined)[TensorBoard Histogram Dashboard]
tensorflow封装好的rnn/lstm等层weight/bias的summary
通过层参数.weight或者.variables查看,两者区别暂时不清楚。
lstm_cell_fw = rnn.LSTMBlockFusedCell(params['lstm_size'])
output_fw, _ = lstm_cell_fw(embeddings_t, dtype=tf.float32, sequence_length=nwords)
lstm_cell_fw_kernel, lstm_cell_fw_bias = lstm_cell_fw.weights
tf.summary.histogram('lstm_cell_fw_kernel', lstm_cell_fw_kernel)
tf.summary.histogram('lstm_cell_fw_bias', lstm_cell_fw_bias)
[Tensorboard - visualize weights of LSTM]
[How to get summary information on tensorflow RNN]
tensorflow获取tf.layers.dense中的参数权重weight
l=tf.layers.dense(input_tf_xxx,300,name='layer_name')
with tf.variable_scope("layer_name", reuse=True):
weights = tf.get_variable("kernel")
[How to get weights in tf.layers.dense?]
启动 TensorBoard
要运行 TensorBoard,请使用以下命令
python3 -m tensorboard.main --logdir=path/to/log-directory
tensorboard --logdir=path/to/log-directory
Note: 1 logdir 指向 FileWriter 将数据序列化的目录(如果使用的是estimator则是MODELDIR:estimator = tf.estimator.Estimator(model_fn, MODELDIR, cfg, params))。如果此 logdir 目录下有子目录,而子目录包含基于各个运行的序列化数据,则 TensorBoard 会将所有这些运行涉及的数据都可视化。
2 指定端口 --port=8008。
3 命令出错:ImportError: No module named _multiarray_umath...F...Check failed: PyBfloat16_Type.tp_base != nullptr ...[1] 1889 abort python -m tensorboard.main --logdir=results/model,可能是因为python版本不对试试:python3 -m tensorboard.main --logdir=results/model
TensorBoard 运行后,请在您的网络浏览器中转到 localhost:6006 以查看 TensorBoard。
tensorboard图解析
Estimator中使用TensorBoard
所有预创建的 Estimator 都会自动将大量信息记录到 TensorBoard 上。不过,对于自定义 Estimator,TensorBoard 只提供一个默认日志(损失图)以及您明确告知 TensorBoard 要记录的信息(如将所有的metrics写入summary绘图
metrics = 'accuracy': accuracy
for metric_name, op in metrics.items():
tf.summary.scalar(metric_name, op[1]))。
Note: estimator不需要显式地将logdir传给tf.summary.FileWriter,它自动默认为MODELDIR。其中MODELDIR为train的,而MODELDIR/eval为eval的信息。
图说明如下:
- global_step/sec:一个性能指示器,展示了随着模型训练,每秒处理多少batches(gradient updates)
- loss:上报的loss。当你的loss呈下降的趋势,说明你的神经网络训练是有效果的。
- accuracy: 通过以下两行所记录的accuracy
- eval_metric_ops=‘my_accuracy’: accuracy),evaluation期
- tf.summary.scalar(‘accuracy’, accuracy[1]),training期
对于传输一个global_step到你的optimizer的minimize方法中很重要,如果没有它,该模型不能为这些图记录x坐标。在训练期,summaries(橙色线)会随着batches的处理被周期性记录,这就是为什么它会变成一个x轴。相反的,对于evaluate的每次调要,evaluation过程只会在图中有一个点。该点包含了整个evaluation调用的平均。在该图中没有width,因为它会被在特定training step(单个checkpoint)的某个模型态下整个进行评估。你可以使用左侧的控制面板来选择性地disable/enable。
在my_accuracy和loss图中,要注意以下事项:
- 橙色线表示training,其中浅色线代表Smoothing=0时的值
- 蓝色点表示evaluation
[官网:在 TensorBoard 中查看自定义 Estimator 的训练结果]
DISTRIBUTIONS
DISTRIBUTIONS 主要用来展示网络中各参数随训练步数的增加的变化情况,可以说是 多分位数折线图 的堆叠。下面我就下面这张图来解释下。

权重分布
这张图表示的是第二个卷积层的权重变化。横轴表示训练步数,纵轴表示权重值。而从上到下的折现分别表示权重分布的不同分位数:[maximum, 93%, 84%, 69%, 50%, 31%, 16%, 7%, minimum]。对应于我的代码,部分如下:
with tf.name_scope(name):
W = tf.Variable(tf.truncated_normal(
[k, k, channels_in, channels_out], stddev=0.1), name='W')
b = tf.Variable(tf.constant(0.1, shape=[channels_out]), name='b')
conv = tf.nn.conv2d(inpt, W, strides=[1, s, s, 1], padding='SAME')
act = tf.nn.relu(conv)
tf.summary.histogram('weights', W)
tf.summary.histogram('biases', b)
tf.summary.histogram('activations', act)HISTOGRAMS
HISTOGRAMS 和 DISTRIBUTIONS 是对同一数据不同方式的展现。与 DISTRIBUTIONS 不同的是,HISTOGRAMS 可以说是 频数分布直方图 的堆叠。
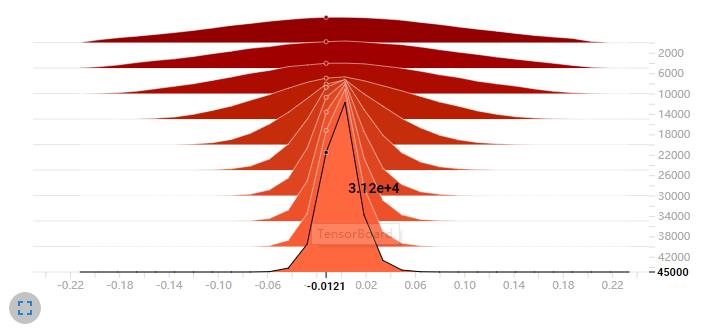
权重分布
横轴表示权重值,纵轴表示训练步数。颜色越深表示时间越早,越浅表示时间越晚(越接近训练结束)。除此之外,HISTOGRAMS 还有个 Histogram mode,有两个选项:OVERLAY 和 OFFSET。选择 OVERLAY 时横轴为权重值,纵轴为频数,每一条折线为训练步数。颜色深浅与上面同理。默认为 OFFSET 模式。
Projector
使用T-SNE方式显示高维向量,这是一个动态的过程,其中随着iteration的增加,会发现结果向量会逐渐分开。相同类别的会聚拢在一起,我们可以选择不同颜色作为区分,发现不同颜色的预测结果的区分度逐渐拉大。
使用tensorflow.summary时报错
1 运行
tf.summary.histogram('histogram', var)Nan in summary histogram for
原因可能有好多种
lz的原因是:在神经网络前向传播时使用了传入参数的转换就出这个错误了:beta = tf.Variable(beta0, name='beta')
其它原因有:
First, I was working with float16 type data which has been documented to cause problems in tensorflow (can't remember where I found this ...I think some stackoverflow post from 2016)
Second (and probably more importantly) my training data was not properly normalized and included a whole batch worth of images without any data. If you're getting Nan's this means training has diverged, likely indicating a problem with training data.
还有可能是学习没有收敛而是发散了。
2 运行
summary_op = tf.summary.merge_all()...
summary_str = sess.run([summary_op], feed_dict=feed_dict)
TypeError: Fetch argument None has invalid type <class 'NoneType'>
1)re-assigning the train_step variable to the second element of the result of sess.run() (which happens to be None).
numpy_state, train_step = sess.run([final_state, train_step], feed_dict=)numpy_state, _ = sess.run([final_state, train_step], feed_dict=...)2)主要原因是run中某个op为none,这里summary_op为none ,原因是没有任何summaries 被收集merge_all就会返回none.
3 运行
summary_str = sess.run([summary_op], feed_dict=feed_dict)TypeError: Parameter to MergeFrom() must be instance of same class: expected Summary got list. for field Event.summary
去掉[]就可以了,居然。。。
summary_str = sess.run(summary_op, feed_dict=feed_dict)还有可能是没有run summary_op,而直接运行了writer.add_summary(summary_str, step)
from: -柚子皮-
ref: [TensorBoard:可视化学习]
官方学习视频[TensorBoard实践介绍(2017年TensorFlow开发大会)]视频文档[详解 TensorBoard-如何调参]
[理解 TensorBoard][理解 TensorBoard]
以上是关于Tensorflow:可视化学习TensorBoard的主要内容,如果未能解决你的问题,请参考以下文章